2023年,当大模型的上下文窗口从4K扩展到128K甚至更长时,一个看似不可逾越的技术障碍横亘在研究者和工程师面前:注意力机制的计算复杂度随序列长度呈二次方增长。处理一个16K token的序列,光是注意力矩阵就要占用近1GB显存;64K序列的注意力矩阵更是超过16GB,直接撑爆了当时最顶级GPU的内存容量。
然而仅仅两年后,128K上下文已成为标配,甚至百万级token的超长上下文模型也开始涌现。这背后的技术突围,源于一个反直觉的发现:注意力计算慢的瓶颈不在运算能力,而在数据读写。Flash Attention正是基于这一洞察,通过重新设计算法来"绕开"GPU内存墙,在不牺牲任何计算精度的前提下,将注意力计算的速度提升了数倍。
GPU内存层级:被忽视的性能瓶颈
要理解Flash Attention的设计逻辑,必须先了解GPU内存架构的一个关键特性:带宽的不对称性。
以NVIDIA A100 GPU为例,其内存系统由两个主要层级构成:
- HBM(High Bandwidth Memory,高带宽内存):即通常所说的"显存",容量为40-80GB,带宽约1.5-2.0TB/s
- SRAM(静态随机存取存储器):位于GPU芯片内部的片上缓存,每个流式多处理器(SM)拥有约192KB,带宽高达约19TB/s
这意味着SRAM的带宽是HBM的近10倍,但容量却只有HBM的十万分之一。当GPU执行计算时,数据必须从HBM加载到SRAM,计算完成后再写回HBM。这个看似简单的数据搬运过程,实际上构成了深度学习工作负载的主要时间开销。
斯坦福大学的研究团队在分析Transformer训练性能时发现了一个令人意外的事实:在注意力计算中,softmax、dropout、masking等逐元素操作占据了大部分执行时间,而非理论上计算量最大的矩阵乘法。原因正是这些操作需要频繁地在HBM和SRAM之间搬运数据。
GPU计算性能的增长速度远超内存带宽的提升速度。从2016年到2024年,GPU的浮点运算能力提升了约100倍,而内存带宽仅提升了约10倍。这种增长的不平衡导致了一个被称为"内存墙"的现象:GPU有足够的计算能力,却经常处于"等数据"的空闲状态。
标准注意力机制的内存困局
标准注意力机制的计算过程可以分解为以下几个步骤:
S = Q @ K^T # 计算注意力分数,得到N×N矩阵
P = softmax(S) # 归一化
O = P @ V # 加权求和得到输出
这里N是序列长度,d是每个token的向量维度。在GPT-3这类大模型中,d通常为128或更大,而N可能高达数千甚至数万。
问题出在中间矩阵S和P上。它们的大小都是N×N,意味着:
- 序列长度N=4K时,S和P各占约128MB(假设FP16精度)
- 序列长度N=16K时,S和P各占约2GB
- 序列长度N=64K时,S和P各占约16GB
更糟糕的是,标准实现需要将这些巨大的中间矩阵写入HBM,再重新读回进行下一步计算。这种"写回-重读"的模式造成了极大的带宽浪费。以N=4K为例,一次完整的注意力计算需要进行:
- 从HBM读取Q、K矩阵,计算S后写回HBM
- 从HBM读取S,计算softmax得到P后写回HBM
- 从HBM读取P、V矩阵,计算O后写回HBM
总HBM访问量约为$O(N^2)$量级。当N增大时,这个数字呈爆炸式增长,直接导致训练速度急剧下降甚至因显存不足而无法运行。
从Roofline模型的角度分析,标准注意力机制是典型的"内存受限"操作。其计算强度(每字节内存访问对应的浮点运算次数)远低于GPU的平衡点,意味着GPU大部分时间都在等待数据传输,而非实际计算。
Flash Attention的核心创新:分块计算与核函数融合
Flash Attention的设计哲学可以用一句话概括:既然瓶颈在内存访问,那就减少访问次数。
分块计算(Tiling)
分块计算是Flash Attention最核心的技术创新。其基本思路是:将Q、K、V矩阵切分成能放入SRAM的小块,在SRAM内完成所有中间计算,只将最终结果写回HBM。
假设SRAM的可用容量为M字节,每个向量维度为d,则块大小可以设为$B_c = B_r = \lfloor M / 4d \rfloor$(考虑同时存储Q、K、V和输出O四个矩阵)。以A100为例,每个SM的SRAM约192KB,当d=128时,块大小约为384个token。
算法采用双重循环结构:
# 外层循环:遍历K、V的块
for j in range(T_c):
# 从HBM加载K_j、V_j到SRAM
K_j, V_j = load_from_HBM(K, V, j)
# 内层循环:遍历Q的块
for i in range(T_r):
# 从HBM加载Q_i、当前累积输出O_i、统计量l_i、m_i到SRAM
Q_i, O_i, l_i, m_i = load_from_HBM(Q, O, l, m, i)
# 在SRAM内计算注意力块
S_ij = Q_i @ K_j.T
m_ij = rowmax(S_ij)
P_ij = exp(S_ij - m_ij)
l_ij = rowsum(P_ij)
# 更新全局统计量和输出
m_new = max(m_i, m_ij)
l_new = exp(m_i - m_new) * l_i + exp(m_ij - m_new) * l_ij
O_i = (exp(m_i - m_new) * l_i * O_i + P_ij @ V_j) / l_new
# 写回统计量和输出
write_to_HBM(O_i, l_i, m_i)
关键在于,整个计算过程中,大小为$N \times N$的注意力矩阵S和P从未被完整地写入HBM。它们只在SRAM中以小块形式存在,计算完成后立即丢弃。只有最终输出O和少量的统计量(m和l,大小均为N)被写回HBM。
这使得HBM访问量从$O(N^2)$降到了$O(N^2 d^2 / M)$。由于M远大于d(典型值M100KB,d128),实际访问量减少了接近一个数量级。
在线Softmax技巧
分块计算面临一个技术挑战:softmax需要对整行数据进行归一化,但分块后每次只能看到部分数据。如何在分块计算的同时保证结果正确?
这需要用到"在线softmax"技巧。核心观察是:如果我们知道每块的最大值$m_{ij}$和指数和$l_{ij}$,就可以在后续迭代中正确地合并结果。
对于向量$x = [x_1, x_2, ..., x_n]$,softmax定义为:
$$\text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_j}}$$为避免数值溢出,实际使用"安全softmax",即先减去最大值:
$$\text{softmax}(x_i) = \frac{e^{x_i - m(x)}}{\sum_{j=1}^{n} e^{x_j - m(x)}}$$其中$m(x) = \max_j x_j$。
现在假设向量被分成两块$x^{(1)}$和$x^{(2)}$,我们分别计算:
- $m^{(1)} = \max(x^{(1)})$,$l^{(1)} = \sum e^{x^{(1)} - m^{(1)}}$
- $m^{(2)} = \max(x^{(2)})$,$l^{(2)} = \sum e^{x^{(2)} - m^{(2)}}$
全局最大值为$m = \max(m^{(1)}, m^{(2)})$,全局指数和可以通过以下公式合并:
$$l = e^{m^{(1)} - m} \cdot l^{(1)} + e^{m^{(2)} - m} \cdot l^{(2)}$$最终,分块计算的输出只需要根据新的全局最大值进行缩放校正:
$$O = \frac{e^{m^{old} - m^{new}} \cdot l^{old} \cdot O^{old} + P^{new} \cdot V}{l^{new}}$$这个技巧使得softmax可以分块计算,同时保证最终结果与标准实现完全一致——这就是Flash Attention所谓的"精确注意力"。
核函数融合(Kernel Fusion)
核函数融合是另一项关键优化。在标准实现中,矩阵乘法、softmax、dropout等操作被实现为独立的GPU核函数(kernel),每个核函数执行完毕后都将结果写回HBM。
Flash Attention将所有这些操作合并到单一核函数中执行:
- 从HBM加载Q、K、V块到SRAM(一次读取)
- 在SRAM内依次执行:矩阵乘法 → softmax → dropout(可选)→ 与V相乘
- 将最终输出O写回HBM(一次写入)
这种融合将多次HBM读写缩减为一次读取和一次写入,大幅降低了内存访问开销。更重要的是,中间结果无需存储,使得内存占用从$O(N^2)$降到$O(N)$。
反向传播中的重计算策略
在训练的反向传播阶段,通常需要前向传播的中间激活值来计算梯度。但Flash Attention在前向传播中并未保存巨大的注意力矩阵S和P,这如何处理?
Flash Attention采用了"重计算"策略:在反向传播时,从已保存的Q、K、V块重新计算S和P。这看起来似乎增加了计算量,但论文证明,由于这些计算都在SRAM内完成,重计算的时间开销反而小于从HBM读取存储的中间结果的时间。
这是一种"以计算换内存"的策略,而且由于GPU的计算能力相对于内存带宽的富余,这笔交易是划算的。最终结果是:反向传播既没有增加内存占用,也没有显著增加计算时间。
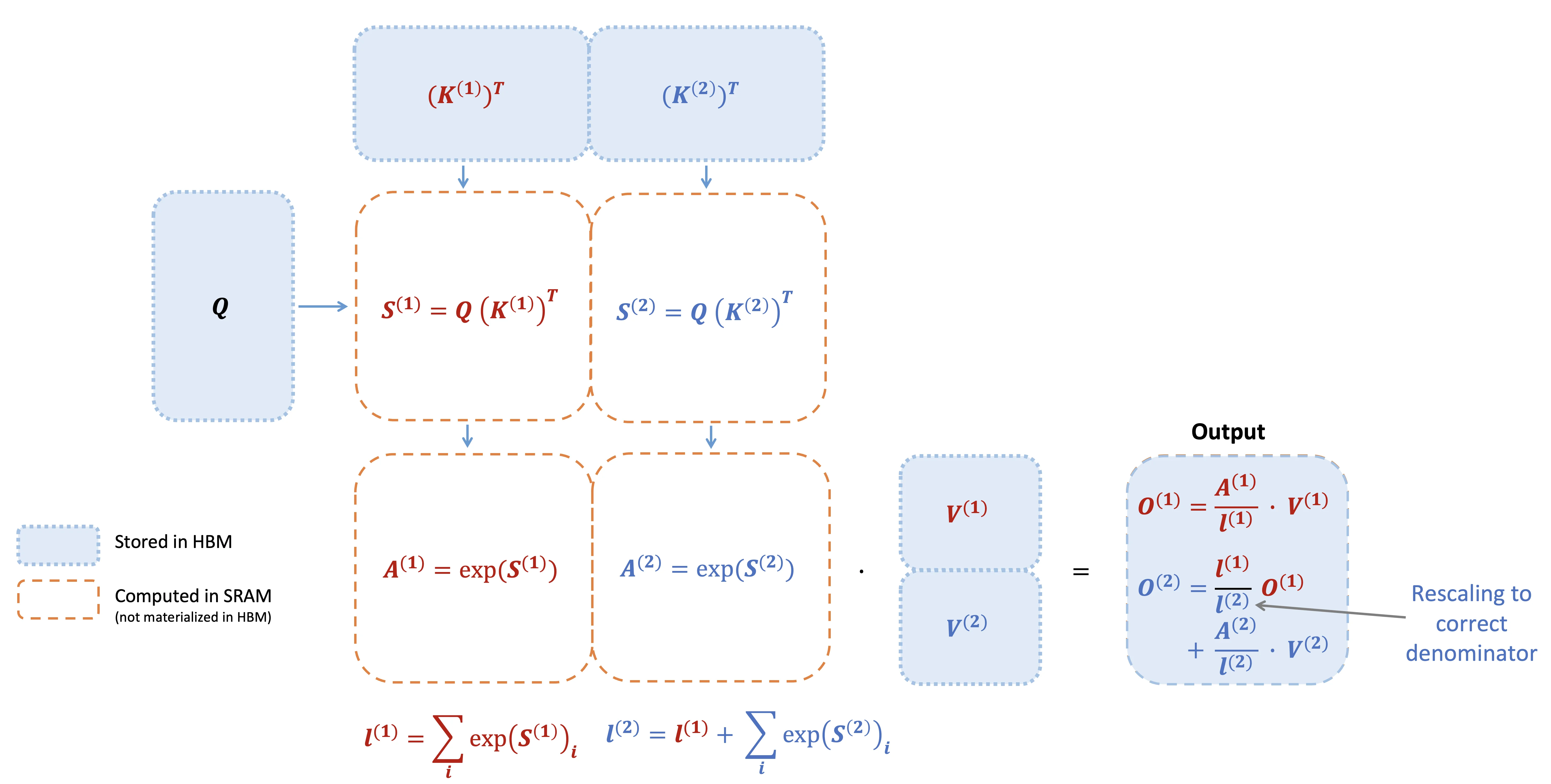
图片来源:FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
上图展示了Flash Attention的分块计算流程。Q、K、V被切分成小块后,依次加载到SRAM中进行计算,通过在线softmax技巧累积正确结果,最终输出只包含O和少量统计量。
性能飞跃:从Flash Attention到Flash Attention 3
自2022年Flash Attention首次发表以来,研究团队持续优化,相继推出了Flash Attention 2和Flash Attention 3。
Flash Attention 2:更好的并行性
Flash Attention 2主要解决了第一版本在GPU线程调度上的效率问题。原版Flash Attention只能并行处理不同的注意力头,当batch size较小(常见于长序列训练)时,GPU利用率不足。
Flash Attention 2引入了两个关键改进:
-
序列维度并行:除了在batch和head维度并行外,还在序列长度维度上并行,即使单个注意力头也能利用多个SM同时计算。
-
优化线程块内工作分配:调整了线程束(warp)之间的数据分配方式,减少了线程同步和共享内存读写的开销。
在A100 GPU上,Flash Attention 2达到约230 TFLOPS/s(FP16/BF16),约为理论峰值的72%。相比第一版本,速度提升约2倍;相比PyTorch标准实现,提升高达9倍。
Flash Attention 3:拥抱Hopper架构
2024年发布的Flash Attention 3针对NVIDIA Hopper架构(H100 GPU)的新特性进行了深度优化:
-
异步Tensor Core与TMA:利用H100的Tensor Memory Accelerator(TMA)和异步Tensor Core,实现计算与数据传输的流水线重叠。
-
交错执行:通过"ping-pong"调度,让一部分线程执行GEMM计算时,另一部分线程执行softmax,充分隐藏softmax的计算延迟。
-
FP8低精度支持:利用H100的FP8 Tensor Core,带宽提升一倍。同时采用"非相干处理"技术降低量化误差。
在H100 GPU上,Flash Attention 3(FP16)达到约740 TFLOPS/s,约为理论峰值的75%;使用FP8时更是接近1.2 PFLOPS/s。
| 版本 | GPU | 峰值性能 | 相对标准实现 |
|---|---|---|---|
| Flash Attention | A100 | ~125 TFLOPS/s | 2-4x |
| Flash Attention 2 | A100 | ~230 TFLOPS/s | ~9x |
| Flash Attention 2 | H100 | ~335 TFLOPS/s | - |
| Flash Attention 3 | H100 | ~740 TFLOPS/s (FP16) | 1.5-2x vs FA2 |
对AI行业的深远影响
Flash Attention的意义远超一个优化算法本身,它从根本上改变了训练大模型的可行边界。
长上下文成为可能
在Flash Attention出现之前,训练一个64K上下文的模型几乎是不可能的——光是注意力矩阵就会占用所有显存。Flash Attention将内存占用从$O(N^2)$降到$O(N)$后,128K甚至更长的上下文窗口变得可行。
2023年后发布的旗舰大模型几乎都采用了超长上下文设计:GPT-4 Turbo支持128K,Claude 3支持200K,Gemini 1.5 Pro更是达到了100万token。这些突破的背后,Flash Attention提供了关键的基础设施支撑。
端到端训练加速
除了支持更长的上下文,Flash Attention也显著加速了常规训练。在BERT-large(序列长度512)上,Flash Attention比MLPerf 1.1的训练速度记录快15%;在GPT-2(序列长度1K)上,比HuggingFace和Megatron-LM的实现快3倍。
这种加速意味着更低的训练成本和更快的迭代周期。当全球每天有数万张GPU在训练大模型时,15%的速度提升转化的经济效益是天文数字。
工业界的广泛采用
Flash Attention已被主流深度学习框架原生支持:
- PyTorch 2.0起原生集成了
F.scaled_dot_product_attention,自动使用Flash Attention后端 - HuggingFace Transformers默认启用Flash Attention加速
- 主流推理框架如vLLM、TensorRT-LLM都将Flash Attention作为核心优化
这种"开箱即用"的集成,使得开发者和研究人员无需修改代码即可享受性能红利。
为什么是IO感知?一个范式转移
Flash Attention的成功揭示了一个更深层的技术趋势:在当前硬件架构下,算法设计不能再将硬件视为黑盒。
过去二十年的算法研究,主要关注如何降低计算复杂度(FLOPs)。但在GPU内存墙日益严峻的今天,仅仅关注计算量可能导致方向性错误。Flash Attention证明了:在某些场景下,减少内存访问比减少计算量更能带来性能提升。
这种"IO感知"的设计思想正在向更广泛的领域延伸。从Flash Attention到Flash Decoding,从PagedAttention到各种显存优化技术,新一代系统级优化都在遵循相同的范式:理解硬件,适配硬件,利用硬件。
论文作者Tri Dao在一次演讲中提到,Flash Attention的核心洞察其实很简单——只是大多数人(包括NVIDIA的工程师)长期忽略了一个事实:GPU计算很快,但数据搬运很慢。一旦意识到这一点,解决方案就变得清晰了:尽量让数据留在高速缓存里,减少与慢速显存的交互。
这个故事的启示是:在摩尔定律放缓、专用加速器崛起的时代,真正理解硬件特性的算法工程师,将拥有创造"免费午餐"的能力——在不牺牲任何功能的前提下,获得数量级的性能提升。Flash Attention就是这份免费午餐的典范。
参考文献
-
Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv preprint arXiv:2205.14135.
-
Dao, T. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv preprint arXiv:2307.08691.
-
Dao, T., & Gu, A. (2024). FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. arXiv preprint arXiv:2407.08608.
-
NVIDIA. (2022). NVIDIA Hopper Architecture In-Depth. NVIDIA Technical Blog.
-
Williams, S., Waterman, A., & Patterson, D. (2009). Roofline: an insightful visual performance model for multicore architectures. Communications of the ACM, 52(4), 65-76.
-
Milakov, M., & Gimelshein, N. (2018). Online normalizer calculation for softmax. arXiv preprint arXiv:1805.02867.