2020年2月,微软研究院发布了一个名为DeepSpeed的深度学习优化库,其中最引人注目的组件是ZeRO(Zero Redundancy Optimizer)。这项技术声称可以在1024块GPU上训练万亿参数模型。当时最大的语言模型GPT-2仅有15亿参数,Megatron-LM也不过83亿参数。ZeRO究竟做了什么,能让模型规模提升百倍以上?
答案在于一个被忽视已久的问题:数据并行中的内存冗余。
一个1.5B模型为何需要24GB内存
在讨论解决方案之前,需要先理解问题的本质。以GPT-2为例,这个拥有15亿参数的模型,参数本身只需要3GB内存(FP16精度下,每个参数2字节)。然而,在PyTorch中使用Adam优化器进行混合精度训练时,它却无法在单块32GB显存的GPU上运行。
内存都去哪了?
混合精度训练的核心思想是:前向和反向传播使用FP16计算以利用Tensor Core的高吞吐量,但参数更新使用FP32以保持数值稳定性。这意味着除了FP16的参数和梯度外,还需要存储:
- FP32参数副本:$4\psi$ 字节
- FP32动量(momentum):$4\psi$ 字节
- FP32方差(variance):$4\psi$ 字节
- FP16参数:$2\psi$ 字节
- FP16梯度:$2\psi$ 字节
其中 $\psi$ 是参数数量。对于Adam优化器,优化器状态的内存乘数 $K=12$(FP32参数、动量、方差各占4字节,共12字节)。总内存需求为:
$$\text{Memory} = 2\psi + 2\psi + 12\psi = 16\psi$$对于15亿参数的GPT-2,这相当于 $16 \times 1.5 \times 10^9 = 24\text{GB}$。
这还没完。激活值、临时缓冲区和内存碎片还会进一步消耗显存。微软在ZeRO论文中指出,一个15亿参数的GPT-2模型,在序列长度1024、批大小32的情况下,仅激活值就需要约60GB内存。即使使用激活检查点技术将其压缩到约8GB,总内存需求仍然惊人。
数据并行的内存陷阱
数据并行(Data Parallelism, DP)是最直观的分布式训练策略:每个GPU持有完整的模型副本,处理不同的数据分片,然后通过AllReduce同步梯度。这种方式实现简单、扩展性好,但有一个致命缺陷——每个GPU都存储了完全相同的模型状态。
假设有 $N_d$ 个GPU进行数据并行训练,模型状态的内存需求为 $16\psi$ 字节。无论 $N_d$ 是1还是1024,每个GPU上的内存消耗都是 $16\psi$ 字节。增加GPU数量只能加快训练速度,完全无法降低单卡内存需求。
这就是为什么数据并行无法训练超过一定规模的模型:当模型状态的内存需求超过单卡显存时,再多的GPU也无济于事。2020年,PyTorch DistributedDataParallel在32GB显存的GPU上,最多只能训练约14亿参数的模型。
模型并行的通信噩梦
当模型无法放入单卡时,自然会想到拆分模型本身。模型并行(Model Parallelism, MP)将模型的各层分配到不同GPU上,每个GPU只存储部分参数。这确实解决了内存问题,但引入了新的麻烦。
以Megatron-LM为例,它采用张量并行(Tensor Parallelism),将Transformer中的矩阵乘法沿列或行切分到多个GPU上并行计算。这种方式在单节点内效果很好,因为NVLink提供了高达300GB/s的互联带宽。但跨节点时,带宽骤降至12.5GB/s(InfiniBand EDR)。
微软的实验数据很能说明问题:使用Megatron-LM训练40亿参数模型,跨两台DGX-2节点时,每块V100 GPU只能达到约5 TFlops的性能——不到硬件峰值性能的5%。而在单节点内,同样规模的模型可以达到近30 TFlops。
问题在于,模型并行需要频繁的层间通信。Transformer模型的每个Transformer块在前后向传播中需要进行多次AllReduce操作,通信量与批大小、序列长度和隐藏维度成正比。当跨节点带宽成为瓶颈时,大部分时间都在等待数据传输,GPU利用率极低。
ZeRO的核心洞察
ZeRO的出发点是两个关键观察:
第一,数据并行之所以内存效率低下,是因为模型状态在所有GPU上被完整复制。如果这些状态可以被分片存储,内存需求将随GPU数量线性下降。
第二,模型状态在训练过程中并非始终需要。例如,参数 $w_i$ 只在前向传播计算第 $i$ 层输出和反向传播计算梯度时才被使用,其他时间完全可以释放。
基于这两个观察,ZeRO提出了一个精妙的设计:保持数据并行的通信效率,同时获得模型并行的内存效率。
ZeRO的三阶段优化
ZeRO-DP(ZeRO Data Parallelism)将模型状态分为三类:优化器状态、梯度和参数。三个优化阶段依次对这些状态进行分片。
Stage 1:优化器状态分片
最容易被忽视的优化器状态,恰恰是内存消耗最大的部分。在混合精度训练中,优化器状态占用了 $12\psi$ 字节,是参数本身的6倍。
ZeRO Stage 1将优化器状态均匀切分到 $N_d$ 个数据并行进程中。进程 $i$ 只存储和更新第 $i$ 个分区的优化器状态,以及对应的参数分区。训练结束时,通过AllGather收集所有进程更新的参数。
内存消耗变为:
$$\text{Memory}_{P_{os}} = 4\psi + \frac{12\psi}{N_d}$$当 $N_d$ 很大时,这趋近于 $4\psi$,相比标准数据并行的 $16\psi$ 减少了4倍。
以一个75亿参数的模型为例,使用标准数据并行需要120GB内存;使用ZeRO Stage 1配合64路数据并行,每个GPU只需要31.4GB。这正好可以放入32GB显存的V100 GPU。
Stage 2:梯度分片
进一步观察发现,每个数据并行进程只更新其对应的参数分区,因此只需要该分区对应的梯度。
ZeRO Stage 2在反向传播过程中,使用Reduce-Scatter操作将梯度归约到对应的进程。每个进程只保留自己负责更新的参数分区所对应的梯度,其余梯度立即释放。
内存消耗变为:
$$\text{Memory}_{P_{os+g}} = 2\psi + \frac{14\psi}{N_d}$$当 $N_d$ 很大时,这趋近于 $2\psi$,相比标准数据并行减少了8倍。
继续上面的例子,75亿参数模型在64路数据并行下,每个GPU只需要16.6GB内存。
Stage 3:参数分片
最激进的优化是将参数本身也分片。每个进程只存储其分区的参数,在前向和反向传播时按需从其他进程获取。
这需要更复杂的通信调度。在前向传播第 $i$ 层之前,进程需要通过AllGather获取第 $i$ 层的所有参数;计算完成后,这些参数可以被释放。反向传播同理。
内存消耗变为:
$$\text{Memory}_{P_{os+g+p}} = \frac{16\psi}{N_d}$$这实现了与模型并行相同的内存效率——内存需求随GPU数量线性下降。75亿参数模型在64路数据并行下,每个GPU只需要1.9GB用于存储模型状态。
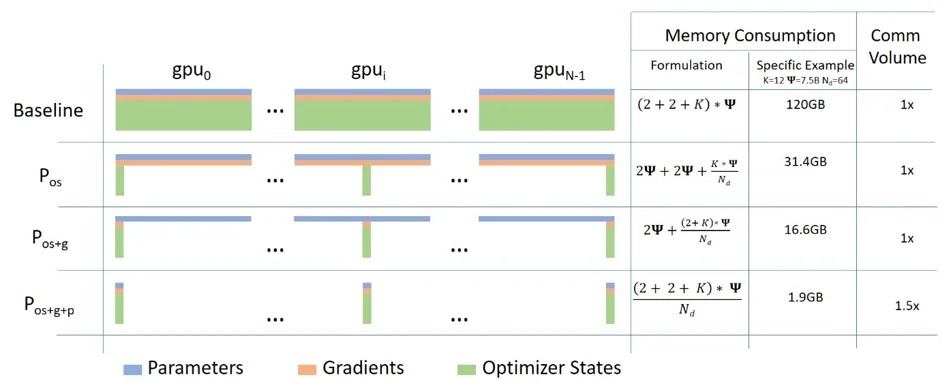
图中展示了三个阶段的内存节省效果。以7.5B参数模型为例,假设 $K=12$(Adam优化器),$N_d=64$。标准数据并行需要120GB,而ZeRO Stage 3只需1.88GB。
通信开销:代价是什么
分片必然带来额外的通信开销,关键在于这个开销是否可接受。
Stage 1和Stage 2的通信量
标准数据并行在每次迭代结束时使用AllReduce同步梯度。高效的AllReduce实现分为两步:Reduce-Scatter和AllGather,每步的通信量都是 $\psi$(对于大模型,与 $N_d$ 无关),总通信量为 $2\psi$。
ZeRO Stage 2使用Reduce-Scatter归约梯度,通信量为 $\psi$;参数更新后使用AllGather收集所有更新后的参数,通信量也是 $\psi$。总通信量 $2\psi$,与标准数据并行完全相同。
这是一个令人惊讶的结果:ZeRO Stage 2实现了8倍内存节省,却没有增加任何通信开销。
Stage 3的通信量
Stage 3需要在前向和反向传播时AllGather参数,加上梯度的Reduce-Scatter,总通信量为 $3\psi$。相比标准数据并行增加了50%。
这个代价是否值得?微软的分析指出,对于Transformer模型,即使批大小只有几十,模型并行的通信量也比ZeRO Stage 3高一个数量级。原因在于,模型并行的通信量与批大小、序列长度和隐藏维度成正比:
$$\text{Comm}_{MP} = 12 \times \text{batch} \times \text{seq\_len} \times \text{hidden\_dim} \times \text{num\_layers}$$而ZeRO Stage 3的通信量只与参数数量相关:
$$\text{Comm}_{ZeRO-3} = 3 \times 12 \times \text{hidden\_dim}^2 \times \text{num\_layers}$$当批大小超过几十时(大模型训练的常见情况),ZeRO Stage 3的通信量远低于模型并行。
ZeRO-Offload:利用CPU内存
当GPU内存仍然不够时,ZeRO-Offload提供了一个选项:将优化器状态和梯度卸载到CPU内存。
这是基于一个有趣的观察:优化器状态的更新(Adam的一阶和二阶动量更新)计算量相对较小,但内存占用巨大。将这些状态卸载到CPU,虽然PCIe带宽只有约12GB/s,但由于更新频率低(每个迭代只执行一次),对整体性能影响有限。
ZeRO-Offload的实现需要精细的异步调度。在GPU执行前向传播时,CPU并行地从内存读取优化器状态;反向传播完成后,梯度通过PCIe传输到CPU,CPU执行优化器更新,然后将更新后的状态写回内存。
微软的实验表明,使用ZeRO-Offload,在单台DGX-2服务器(16块V100 GPU)上可以训练超过130亿参数的模型,而标准数据并行只能训练14亿参数。
ZeRO-Infinity:突破GPU内存墙
2021年,微软进一步提出了ZeRO-Infinity,将卸载扩展到NVMe固态硬盘。这背后的动机是:即使CPU内存也可能不够用。
训练一个万亿参数模型需要约16TB内存来存储模型状态。即使是最强大的服务器,CPU内存通常也只有几TB。NVMe固态硬盘提供了海量存储空间,单台服务器可以轻松配置数十TB的NVMe容量。
但NVMe的带宽比GPU内存低了两个数量级,直接卸载会导致严重的性能下降。ZeRO-Infinity通过三项关键技术解决了这个问题:
带宽中心分片(Bandwidth-Centric Partitioning):传统方法中,参数从NVMe读取到某个"拥有者"GPU,然后广播给其他GPU。这种方式只利用了一条PCIe链路的带宽。ZeRO-Infinity将参数切分到所有GPU,每个GPU只从NVMe读取自己那部分,然后通过AllGather组装。这样,所有PCIe链路并行工作,有效带宽随GPU数量线性增长。
通信重叠(Overlap-Centric Design):动态预取器会提前调度NVMe到CPU、CPU到GPU、GPU之间的数据传输,使这些传输与GPU计算重叠执行。在计算第 $i$ 层时,第 $i+1$、$i+2$、$i+3$ 层的数据已经在并行传输。
内存中心分块(Memory-Centric Tiling):对于超大线性层(如隐藏维度从18K扩展到72K的投影层),即使分片后的单层参数也可能超出GPU内存。ZeRO-Infinity将这种大算子拆分为多个小块顺序执行,每块的参数和梯度可以即时获取和释放。
ZeRO-Infinity的实验结果令人印象深刻:在512块V100 GPU上,它可以训练32万亿参数的模型——这是当时3D并行方案的50倍。更重要的是,在单台DGX-2服务器上,它可以训练万亿参数模型,使大模型微调对普通研究团队成为可能。
与PyTorch FSDP的关系
2022年,PyTorch引入了Fully Sharded Data Parallel(FSDP),其设计理念与ZeRO Stage 3基本相同:分片存储参数、梯度和优化器状态,按需AllGather获取完整参数。
两者的主要区别在于实现细节:
- DeepSpeed ZeRO提供了更丰富的配置选项,如CPU/NVMe卸载、梯度检查点、通信重叠策略等
- PyTorch FSDP作为PyTorch原生组件,与PyTorch生态系统集成更紧密
- FSDP在某些场景下的性能表现与ZeRO-3相当,但在极端大规模模型上,ZeRO-Infinity仍然是更成熟的选择
对于大多数用户,选择建议是:如果已经使用PyTorch且模型规模在百亿参数级别,FSDP是一个简洁的选择;如果需要训练更大模型或需要更精细的性能调优,DeepSpeed ZeRO仍然是首选。
技术权衡:什么时候使用ZeRO
ZeRO并非万能药,选择是否使用它需要考虑具体场景:
适合使用ZeRO的情况:
- 模型参数量超过单卡显存容量,需要跨卡存储
- 训练集群的节点间带宽有限,模型并行效率低下
- 希望保持数据并行的代码简洁性,避免模型重写
- 需要灵活调整模型规模,不想预先决定并行策略
不适合使用ZeRO的情况:
- 模型能够放入单卡,数据并行已经足够
- 单节点内的高速互联(如NVLink/NVSwitch)充足,模型并行表现良好
- 需要极低延迟的推理场景(ZeRO在推理时需要AllGather参数)
ZeRO各阶段的选择建议:
- Stage 1:最安全的选择,4倍内存节省且无额外通信开销
- Stage 2:当Stage 1仍然不够时使用,8倍内存节省且无额外通信开销
- Stage 3:当需要突破单卡极限时使用,内存节省与GPU数量成正比
超线性加速的秘密
ZeRO论文中报告了一个有趣的现象:在扩展GPU数量时,训练吞吐量的增长超过了线性。例如,从64块GPU扩展到400块GPU,性能提升超过6倍。
这听起来违反直觉——理论上,增加GPU数量不应该提高单GPU的性能。原因在于,ZeRO Stage 2和Stage 3的内存效率随GPU数量增加而提高。更多的GPU意味着每个GPU需要存储的模型状态更少,从而可以容纳更大的批大小。更大的批大小提高了算术强度,使GPU能够更接近其峰值性能运行。
这种超线性加速在大模型训练中尤为明显,因为大模型的内存压力更大,增加GPU带来的批大小提升空间也更显著。
从理论到实践:配置示例
在DeepSpeed中使用ZeRO只需要修改配置文件:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"overlap_comm": true,
"contiguous_gradients": true
}
}
关键配置项包括:
stage:选择ZeRO阶段(1、2或3)offload_optimizer:启用CPU卸载overlap_comm:启用通信与计算重叠contiguous_gradients:减少内存碎片
对于ZeRO-3,还可以配置参数卸载:
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme"
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme"
}
}
}
大模型训练的新范式
ZeRO的真正价值不仅在于技术本身,更在于它改变了大模型训练的方式。
在ZeRO之前,训练百亿参数模型需要复杂的模型并行和流水线并行组合,开发者需要重写模型代码、调整并行策略、处理跨节点通信问题。ZeRO使得数据并行——这种最简单、最成熟的并行方式——能够扩展到万亿参数规模。
更重要的是,ZeRO降低了大模型训练的门槛。研究团队不再需要大规模GPU集群才能训练大模型;使用ZeRO-Infinity,在单台服务器上微调万亿参数模型已经成为可能。
从系统设计的角度看,ZeRO展示了一个重要原则:有时候,优化存储方式比优化计算方式更有效。通过仔细分析模型状态的生命周期和依赖关系,ZeRO找到了一种既不牺牲通信效率又能大幅降低内存需求的方案。这种思路值得在更多场景中借鉴。
ZeRO的后续发展,如与Flash Attention的结合、与序列并行的融合,正在进一步推动大模型训练的边界。当模型规模从百亿增长到万亿、乃至更大时,ZeRO所代表的分片思想,可能仍然是解决内存瓶颈的关键路径。
参考文献
- Rajbhandari, S., et al. “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.” SC20, 2020.
- Ren, J., et al. “ZeRO-Offload: Democratizing Billion-Scale Model Training.” 2021.
- Rajbhandari, S., et al. “ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning.” SC21, 2021.
- PyTorch Documentation. “Fully Sharded Data Parallel (FSDP).”
- Hugging Face Documentation. “Parallelism methods for distributed training.”
- Microsoft Research Blog. “ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters.”