2020年,当OpenAI训练拥有1750亿参数的GPT-3模型时,他们面临一个令人绝望的现实:即使使用当时最先进的NVIDIA A100 GPU(80GB显存),单张显卡连模型都无法加载,更不用说训练了。
问题远不止模型参数本身。按照FP16精度计算,GPT-3的模型权重需要350GB存储空间,优化器状态(Adam的动量和方差)需要1.4TB,梯度需要350GB——这些加起来已经接近2.1TB。但这还不是全部,训练过程中最容易被忽视却占据大量显存的,是前向传播产生的中间激活值。
当模型规模突破千亿参数时,一个残酷的事实浮出水面:激活值占用的显存可能超过模型参数、优化器状态和梯度的总和。这就是为什么即便使用ZeRO优化器切分参数和优化器状态,训练长上下文的大模型仍然会遭遇显存瓶颈。
解决这个问题的核心技术,叫做梯度检查点(Gradient Checkpointing),也被称为激活重计算(Activation Recomputation)。这项技术的核心思想极其简单:用时间换空间——不保存所有中间激活值,而是在需要时重新计算。但真正理解它为何有效、如何优化,需要深入神经网络的训练机制。
显存到底去哪了
理解梯度检查点之前,必须先理解训练过程中显存的去向。以一个标准的Transformer模型为例,显存消耗可以分为四个部分:
模型参数:这是最直观的部分。一个拥有$L$层、隐藏维度为$h$的Transformer模型,参数量约为$12Lh^2$。以FP16存储,每个参数占2字节。
优化器状态:Adam优化器需要维护一阶动量和二阶动量,通常以FP32精度存储。这意味着优化器状态是模型参数的2倍(权重本身的FP32副本)+ 2倍(动量+方差)= 4倍参数量,存储为FP32即8倍字节。
梯度:与模型参数规模相同,FP16存储。
激活值:这是最容易被低估的部分。前向传播过程中,每一层的输出都需要保存,因为反向传播计算梯度时需要这些中间结果。
为什么激活值如此重要?考虑一个简单的矩阵乘法$Y = XW$,反向传播时需要计算:
- 对$W$的梯度:$\frac{\partial L}{\partial W} = X^T \frac{\partial L}{\partial Y}$
- 对$X$的梯度:$\frac{\partial L}{\partial X} = \frac{\partial L}{\partial Y} W^T$
两个梯度计算都需要输入$X$。这意味着前向传播时必须保存$X$,否则反向传播就无法进行。
NVIDIA在2022年发表的论文《Reducing Activation Recomputation in Large Transformer Models》中给出了精确的激活内存公式。对于单个Transformer层,激活内存约为:
$$\text{Activation Memory} = sbh\left(34 + 5\frac{as}{h}\right) \text{ bytes}$$其中$s$是序列长度,$b$是批大小,$h$是隐藏维度,$a$是注意力头数。这个公式揭示了两个关键事实:
第一,激活内存与批大小和隐藏维度成线性关系,这部分的增长是可控的。
第二,激活内存与序列长度的平方成正比(公式中的$as^2b$项)。这意味着将序列长度从2048扩展到8192,激活内存会增加16倍——这正是长上下文模型训练的核心挑战。
论文中的实验数据显示,对于22B到1T参数的模型,激活内存占据了总显存需求的30%到60%。在某些配置下,激活内存甚至超过了模型参数、优化器状态和梯度的总和。
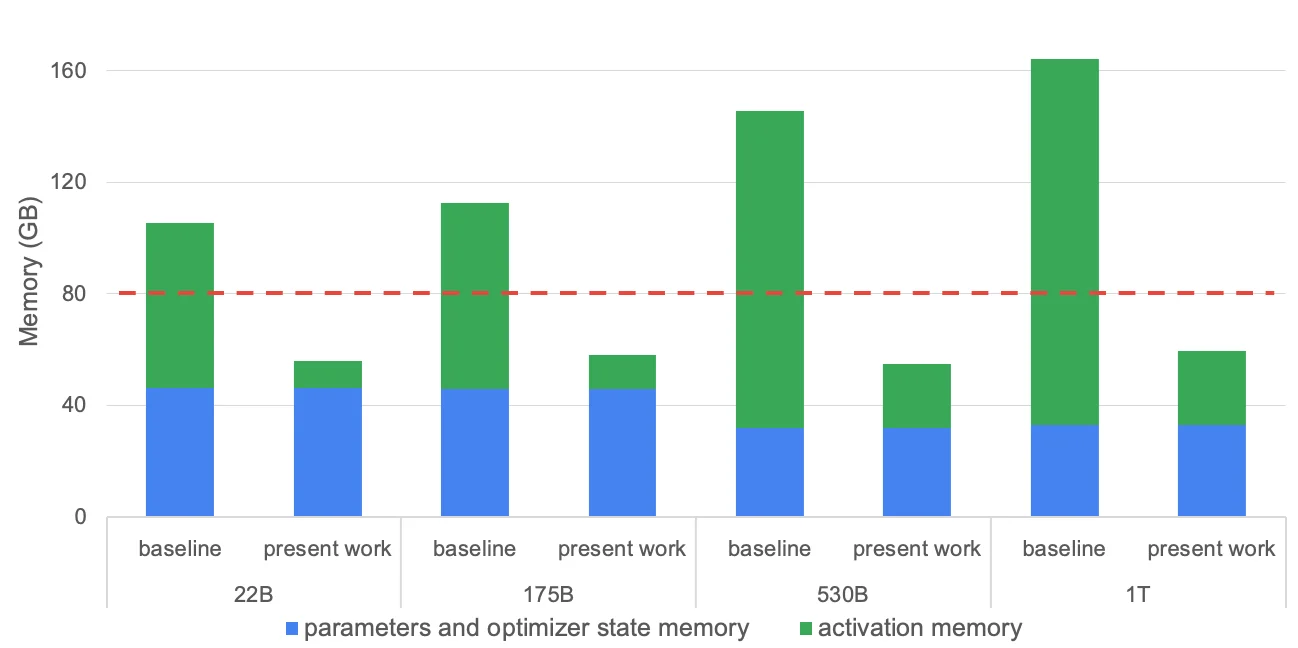
图片来源: NVIDIA, Reducing Activation Recomputation in Large Transformer Models, MLSys 2023
这张图展示了四种不同规模模型(22B到1T参数)的内存分布。橙色部分代表激活内存,可以看到在所有配置下都占据显著比例。红色虚线表示NVIDIA A100的80GB显存容量,基准配置(无优化)全部超出这个限制。
时间换空间:梯度检查点的核心思想
面对激活内存的爆炸式增长,一个直观的想法浮现:能不能不保存这些中间激活值?
答案是可以,但需要付出代价。如果在反向传播时需要某个激活值,可以从最近的"检查点"重新执行前向计算来获得。这就是梯度检查点的核心思想。
2016年,Tianqi Chen(陈天奇)等人在论文《Training Deep Nets with Sublinear Memory Cost》中系统性地阐述了这一技术。论文的核心贡献是证明:对于$n$层的深度网络,可以通过只保存$O(\sqrt{n})$个检查点,将内存复杂度从$O(n)$降低到$O(\sqrt{n})$,代价是额外执行一次前向传播。
算法的核心逻辑如下:
假设网络有$n$层,我们可以将层划分为$\sqrt{n}$个块,每个块包含$\sqrt{n}$层。前向传播时,只保存每个块的输入(即$\sqrt{n}$个检查点),块内的中间激活值全部丢弃。
反向传播时,当需要某个块内的激活值时,从该块的输入检查点开始,重新执行该块的前向计算。由于每个块只有$\sqrt{n}$层,重计算的开销是可接受的。
具体分析:
- 内存消耗:保存$\sqrt{n}$个检查点,每个检查点的大小是单层激活值,总内存$O(\sqrt{n})$。
- 计算开销:每个块需要重计算一次,总共$\sqrt{n}$个块,每个块$\sqrt{n}$层,额外计算量为$\sqrt{n} \times \sqrt{n} = n$层的前向计算,即一次完整的前向传播。
论文还给出了一个更极端的情况:通过嵌套检查点,可以将内存复杂度降低到$O(\log n)$,代价是$O(n \log n)$的额外计算。这个结果展示了时间-空间权衡的边界。
实验中,论文作者在ImageNet上训练一个1000层的残差网络,将显存占用从48GB降低到7GB,代价是30%的额外运行时间。这个结果在当时引起了广泛关注,因为它证明了训练极深网络的可能性。
选择性重计算:不是所有激活值都值得重算
Tianqi Chen的工作给出了通用的理论框架,但对于Transformer这一特定架构,还有更大的优化空间。
NVIDIA的研究团队在2022年的论文中提出了一个关键观察:不是所有激活值的重计算代价都相同。
回顾前面提到的激活内存公式:$sbh(34 + 5\frac{as}{h})$。这个公式可以拆分为两部分:
- $34sbh$:来自MLP层、LayerNorm、Dropout等操作
- $5as^2b$:来自注意力计算中的$QK^T$、Softmax、Attention over V等操作
第二部分的激活值有特殊性质:它们占用的内存很大(与序列长度平方成正比),但重计算的计算量却很小。
原因在于矩阵乘法的计算复杂度。计算$QK^T$需要$O(s^2h)$次浮点运算,产生$s^2$个元素的输出。每个输出元素对应的计算量是$O(h)$次浮点运算。当$h$很大(比如12288)时,这是一个计算密集的操作。
但Softmax、Dropout这些操作不同。Softmax对每一行执行指数运算和归一化,每个元素只需要常数次运算。这意味着产生同样数量的输出,这些操作的计算量要小得多。
NVIDIA的论文用具体数据说明了这一点。对于GPT-3模型($a=96, s=2048, h=12288$),注意力部分的激活内存系数是$5 \times 96 \times 2048 / 12288 = 80$,而其余部分是34。这意味着注意力激活占总激活内存的$80/(34+80) \approx 70\%$。
但重计算这部分激活的开销是多少?论文计算了FLOPs比例:重计算注意力部分只需要额外约2.7%的计算量,却可以节省70%的激活内存。这是一个极其划算的交换。
这就是**选择性重计算(Selective Activation Recomputation)**的核心思想:只重计算那些"内存占用大但计算代价小"的激活值,保存那些"计算代价大"的激活值。
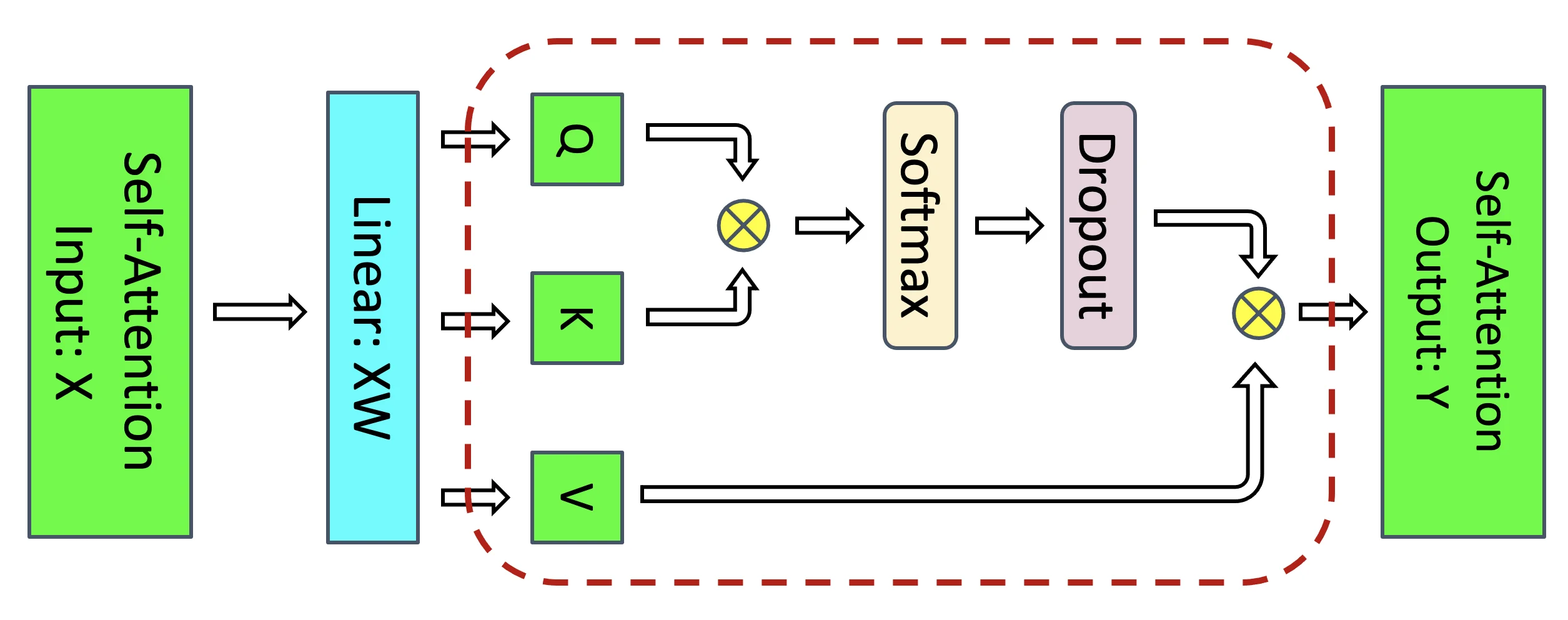
图片来源: NVIDIA, Reducing Activation Recomputation in Large Transformer Models, MLSys 2023
图中红色虚线框标出了选择性重计算应用的区域——注意力计算的核心部分,包括$QK^T$矩阵乘法、Softmax、Softmax Dropout和Attention over Values。这些操作产生的激活值占用大量内存,但重计算的计算开销很小。
论文中的实验结果令人印象深刻。对于530B参数的MT-NLG模型,使用选择性重计算可以将激活内存降低65%,而计算开销仅增加1.6%。相比全量重计算30-40%的计算开销,这是一个巨大的改进。
Sequence Parallelism:从切分模型到切分序列
选择性重计算解决了"重计算什么"的问题,但还有一个更基础的问题:能否从根本上减少需要存储的激活值?
NVIDIA论文的另一项贡献是序列并行(Sequence Parallelism)。这项技术与张量并行(Tensor Parallelism)协同工作,进一步降低激活内存。
回顾张量并行的原理:将Transformer层中的矩阵乘法沿隐藏维度切分到多个GPU上。比如一个$h \times h$的权重矩阵,可以切分为两个$h \times h/2$的矩阵,分别放在两张GPU上计算。
张量并行有一个盲点:LayerNorm和Dropout这些操作没有矩阵乘法,无法沿隐藏维度切分。在标准的张量并行实现中,这些操作在每张GPU上完整复制,产生的激活值也随之复制。
但这些操作有一个特点:它们在序列维度上是独立的。LayerNorm对每个位置独立计算均值和方差,Dropout对每个位置独立应用掩码。这意味着可以将输入沿序列维度切分,每张GPU只处理一部分序列。
序列并行正是利用了这一点。具体实现中,LayerNorm和Dropout的输入沿序列维度切分到各GPU,计算完成后,在进入需要完整输入的操作(如矩阵乘法)前,通过All-Gather操作收集完整输入。
关键的技术洞察是:All-Gather + Reduce-Scatter的组合,与All-Reduce的通信量相同。这是因为Ring All-Reduce算法本质上就是先执行Reduce-Scatter,再执行All-Gather。因此,将原本的All-Reduce替换为All-Gather和Reduce-Scatter,不会增加通信开销。
使用序列并行后,激活内存公式变为:
$$\text{Activation Memory} = \frac{sbh}{t}\left(34 + 5\frac{as}{h}\right)$$其中$t$是张量并行的大小。这意味着激活内存被均匀分配到各个GPU上。
NVIDIA的论文展示了两种技术的协同效果。单独使用序列并行或选择性重计算,都可以将激活内存降低约50%。两者结合,可以实现5倍的激活内存降低。

图片来源: NVIDIA, Reducing Activation Recomputation in Large Transformer Models, MLSys 2023
这张图比较了不同技术的激活内存占比(相对于张量并行基准)。可以看到,序列并行和选择性重计算各自都能将内存降低到50%左右,两者结合可以进一步降低到约20%。
权衡的艺术:内存与计算的最优平衡
梯度检查点技术的核心是权衡:在内存和计算之间寻找最优平衡点。理解这个权衡,需要从两个维度思考。
第一个维度是硬件约束。GPU显存是硬性限制,无法突破。当模型无法放入显存时,唯一的办法就是减少存储需求。这时候,梯度检查点不是可选项,而是必选项。
第二个维度是训练效率。额外的重计算会降低训练吞吐量。一个需要权衡的问题是:在显存允许的范围内,应该保存多少激活值?
PyTorch在2025年3月的博客中介绍了**选择性激活检查点(Selective Activation Checkpointing, SAC)**的最新进展。这项功能允许开发者精细控制哪些操作需要重计算,哪些操作需要保存激活值。
核心思路是根据操作的计算强度(FLOPs per byte)来决定策略:
- 计算密集型操作(如矩阵乘法、Flash Attention):保存激活值,避免昂贵的重计算
- 内存密集型操作(如逐元素运算、LayerNorm):重计算激活值,节省内存
PyTorch提供了策略函数接口,开发者可以自定义保存规则:
from torch.utils.checkpoint import checkpoint, CheckpointPolicy
aten = torch.ops.aten
compute_intensive_ops = [
aten.mm, aten.bmm, aten.addmm,
aten._scaled_dot_product_flash_attention,
]
def policy_fn(ctx, op, *args, **kwargs):
if op in compute_intensive_ops:
return CheckpointPolicy.MUST_SAVE
else:
return CheckpointPolicy.PREFER_RECOMPUTE
更进一步,PyTorch 2.4引入了内存预算API,开发者只需指定一个0到1之间的预算值,框架会自动寻找帕累托最优策略:
torch._dynamo.config.activation_memory_budget = 0.5
output = torch.compile(model)(input)
预算值为0表示像标准检查点一样重计算所有内容;预算值为1表示像默认模式一样保存所有内容。实验显示,设置预算值为0.5(只重计算逐元素操作),可以获得50%的内存节省,同时几乎不损失计算效率。
框架支持与最佳实践
主流的深度学习框架都对梯度检查点提供了良好支持,但在使用方式和优化策略上各有特点。
PyTorch提供了torch.utils.checkpoint.checkpoint函数,可以包装任意模块:
from torch.utils.checkpoint import checkpoint
class CheckpointedTransformerBlock(nn.Module):
def __init__(self, block):
super().__init__()
self.block = block
def forward(self, x):
return checkpoint(self.block, x, use_reentrant=False)
PyTorch 2.1之后推荐使用use_reentrant=False,这是新的非重入实现,支持嵌套检查点和更复杂的梯度计算场景。
DeepSpeed通过配置文件启用检查点,支持更细粒度的控制:
{
"activation_checkpointing": {
"partition_activations": true,
"contiguous_memory_optimization": true,
"number_checkpoints": 4
}
}
partition_activations选项会自动识别Transformer层并插入检查点,number_checkpoints控制每多少层插入一个检查点。
Megatron-LM提供了三种重计算粒度:
- 无重计算:保存所有激活值,内存最高,计算最快
- 选择性重计算:只重计算注意力部分,内存适中,计算开销小(约30%)
- 全量重计算:重计算整个Transformer层,内存最低,计算开销大(约30-40%)
配置示例:
from megatron.bridge.models import GPTModelProvider
# 选择性重计算
model_config = GPTModelProvider(
recompute_granularity="selective",
recompute_modules=["core_attn"],
)
# 全量重计算
model_config = GPTModelProvider(
recompute_granularity="full",
recompute_method="uniform",
recompute_num_layers=8,
)
实际使用中,建议遵循以下原则:
- 显存充足时:优先使用选择性重计算,以最小的计算代价换取内存节省
- 显存紧张时:使用全量重计算,接受30-40%的训练时间增加
- 与分布式训练结合:梯度检查点可以与ZeRO、张量并行、流水线并行等技术组合使用,实现最大程度的显存优化
- 长序列训练:序列并行是必选项,否则激活内存会随序列长度平方增长
NVIDIA论文的实验数据显示,在训练530B参数的MT-NLG模型时,结合序列并行和选择性重计算,相比全量重计算可以实现29%的吞吐量提升。这个提升直接转化为训练时间的节省——原本需要数月的训练任务可以提前数周完成。
结语
梯度检查点技术从2016年Tianqi Chen的理论框架,发展到今天的选择性重计算和序列并行,已经成为了大模型训练的基础设施。它的本质是一个关于权衡的故事:在内存和计算之间寻找最优解。
这项技术的发展也反映了深度学习系统工程的一个核心主题:从通用优化走向架构感知优化。最早的理论框架适用于任何深度网络,但真正的性能突破来自于对Transformer架构特性的深入理解——注意力计算的内存/计算不对称性、LayerNorm在序列维度的独立性,这些洞察驱动了选择性重计算和序列并行的诞生。
当模型的规模继续扩展、序列长度不断突破,激活内存的优化将变得更加关键。理解梯度检查点的原理和最佳实践,是每一位大模型工程师的必备技能。
参考文献
-
Chen, T., Xu, B., Zhang, C., & Guestrin, C. (2016). Training Deep Nets with Sublinear Memory Cost. arXiv:1604.06174.
-
Korthikanti, V., Casper, J., Lym, S., McAfee, L., Andersch, M., Shoeybi, M., & Catanzaro, B. (2023). Reducing Activation Recomputation in Large Transformer Models. MLSys 2023.
-
PyTorch Blog. (2025). Current and New Activation Checkpointing Techniques in PyTorch.
-
NVIDIA. Activation Recomputation — Megatron Bridge Documentation.