梯度裁剪:为什么这个"简单"技巧能拯救你的深度学习模型
训练大语言模型时,你是否遇到过这样的情况:损失函数曲线突然出现莫名其妙的尖峰,模型仿佛"失忆"了一般,之前学到的知识瞬间消失?或者在训练循环神经网络时,梯度变成了NaN,整个训练过程直接崩溃?这些问题的背后,往往隐藏着一个共同的罪魁祸首——梯度爆炸。 ...
训练大语言模型时,你是否遇到过这样的情况:损失函数曲线突然出现莫名其妙的尖峰,模型仿佛"失忆"了一般,之前学到的知识瞬间消失?或者在训练循环神经网络时,梯度变成了NaN,整个训练过程直接崩溃?这些问题的背后,往往隐藏着一个共同的罪魁祸首——梯度爆炸。 ...
2015年,Sergey Ioffe和Christian Szegedy在ICML上发表了一篇论文,提出了Batch Normalization。这篇论文后来成为深度学习领域被引用最多的工作之一。但很少有人注意到,这项最初为计算机视觉设计的技术,在自然语言处理领域却"水土不服"——Transformer选择了完全不同的Layer Normalization。 ...
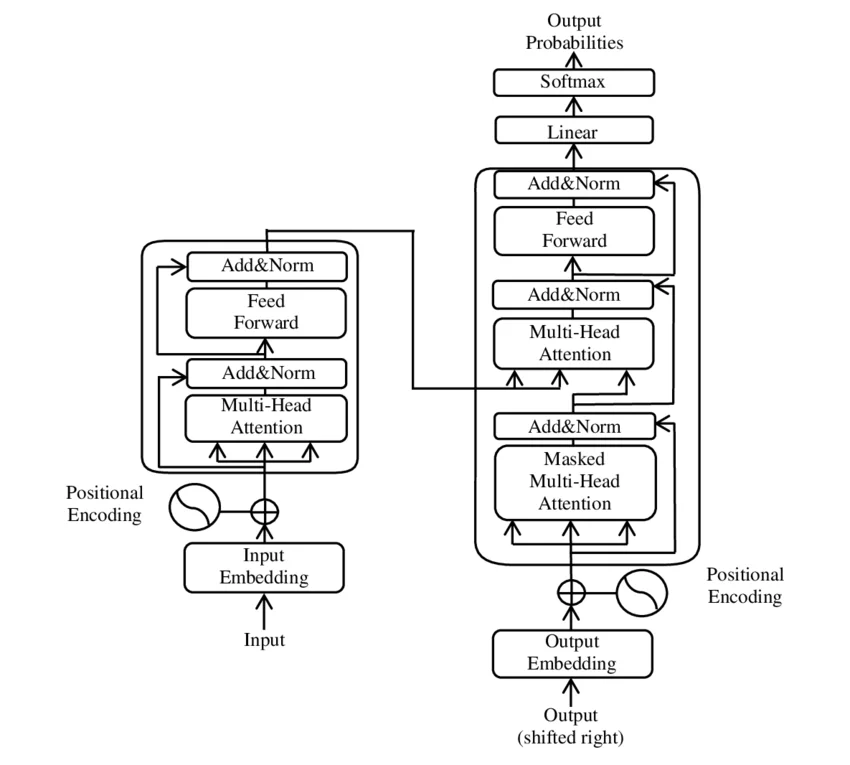
2017年,Google在论文《Attention Is All You Need》中提出了Transformer架构。在这篇开创性论文中,设计者在每个子层之后放置了层归一化(Layer Normalization),这种设计被称为Post-LN。然而,当研究者们尝试将Transformer堆叠得更深时,发现这种设计会带来严重的训练不稳定问题。 ...
当你的显卡显存不足以容纳更大的batch size时,梯度累积似乎是唯一的救星。这个技术在几乎所有大模型训练框架中都有支持,从Hugging Face Transformers到PyTorch Lightning,再到各种分布式训练框架。只需一行配置,你就能在有限的显存下"模拟"更大的batch size——至少文档是这么说的。 ...
同样的文本内容,在一个模型中可能只需要100个token,在另一个模型中却可能膨胀到300个。这背后的差异源于一个经常被忽视但至关重要的设计决策:词表大小的选择。 ...
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...
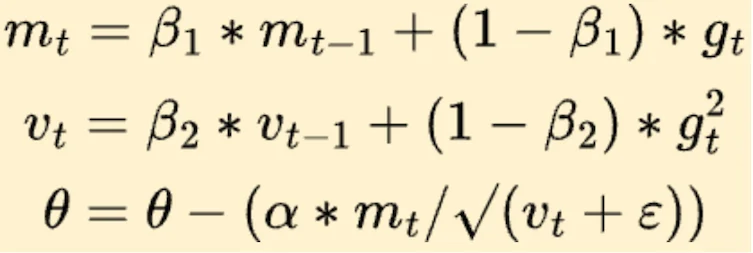
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...