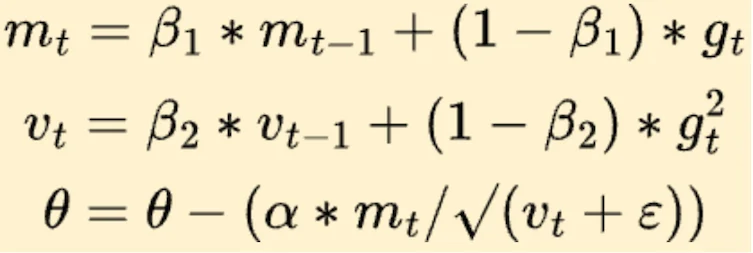
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。
这并非巧合。在计算机视觉领域,SGD至今仍是许多模型的首选;但在自然语言处理和Transformer架构上,Adam及其变体几乎统治了整个领域。这种分化背后,隐藏着深刻的数学原理和工程考量。
一个优化器要解决什么问题
在深入比较之前,我们需要理解优化器在训练神经网络时面临的核心挑战。
神经网络的训练本质上是一个高维优化问题。假设一个拥有70亿参数的模型,我们需要在70亿维的空间中找到一个点,使得损失函数最小化。问题在于,这个损失函数的"地形"极其复杂——有的方向陡峭,有的方向平缓;有的区域梯度稳定,有的区域梯度剧烈波动。
传统的SGD采用最朴素的策略:计算当前梯度,沿着梯度的反方向走一步。
$$\theta_{t+1} = \theta_t - \eta \cdot g_t$$其中 $\theta$ 是参数,$\eta$ 是学习率,$g_t$ 是当前梯度。这个公式简洁优雅,但存在一个致命缺陷:所有参数共用同一个学习率。
想象你在山地中寻找最低点。有些方向坡度很大,走一小步就够;有些方向坡度很缓,需要大步前进。SGD却强迫你在所有方向上使用相同的步长——要么在某些方向走得太急而越过山谷,要么在某些方向走得太慢而停滞不前。
这就是为什么SGD需要精心的学习率调度:先用较大的学习率快速下降,再逐渐减小以精调位置。但即便如此,单一学习率的局限依然存在。
Adam的核心洞察:每个参数都有自己的节奏
2014年,Diederik Kingma和Jimmy Ba提出了Adam优化器,名字来自"Adaptive Moment Estimation"(自适应矩估计)。其核心思想简单而深刻:为每个参数维护一个独立的学习率。
Adam的做法是同时追踪两个"记忆":
一阶矩估计——梯度的移动平均:
$$m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t$$这相当于"记住"过去的梯度方向。如果过去几步的梯度都指向同一个方向,说明这条路值得继续走下去;如果梯度方向来回摇摆,说明应该谨慎行事。
二阶矩估计——梯度平方的移动平均:
$$v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2$$这衡量的是梯度的"波动程度"。如果某个参数的梯度经常剧烈变化,说明这个方向很"颠簸",应该走小步;如果梯度一直很稳定,说明这个方向很"平坦",可以大步前进。
最终的参数更新公式:
$$\theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t$$其中 $\hat{m}_t$ 和 $\hat{v}_t$ 是偏差校正后的估计值。注意分母中的 $\sqrt{\hat{v}_t}$:它为每个参数提供了一个自适应的"步长调节因子"。梯度波动大的参数,分母大,步长小;梯度稳定的参数,分母小,步长大。
这正是我们需要的:不同参数按照自己的"节奏"前进。
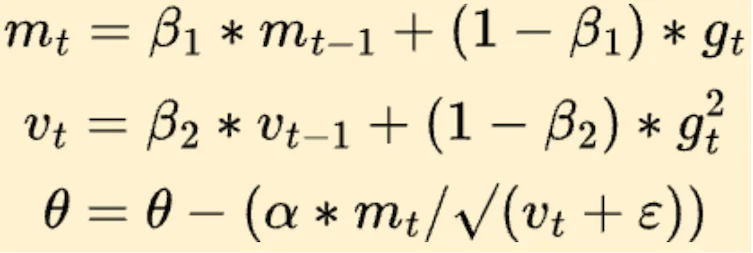
偏差校正:为什么不能直接用原始的矩估计
Adam论文中有一个容易被忽视的细节:偏差校正。由于 $m_0$ 和 $v_0$ 初始化为0,在训练初期,移动平均会严重偏向0,导致估计有偏。
论文给出了校正公式:
$$\hat{m}_t = \frac{m_t}{1-\beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1-\beta_2^t}$$这个校正很重要。在训练初期($t$ 很小),$1-\beta^t$ 接近0,会将原始估计放大,补偿初始化偏差;随着 $t$ 增大,校正因子趋近于1,估计逐渐无偏。
从Adam到AdamW:一个小改动带来的巨大差异
Adam在实践中表现出色,但研究者们发现了一个微妙的问题:Adam中的权重衰减实现与SGD不等价。
L2正则化 ≠ 权重衰减
在SGD中,我们通常通过在损失函数中添加L2正则项来实现权重衰减:
$$L_{reg} = L + \frac{\lambda}{2}\|\theta\|^2$$此时梯度变为:
$$g_t = \nabla L + \lambda \theta$$参数更新:
$$\theta_{t+1} = \theta_t - \eta(\nabla L + \lambda\theta) = (1-\eta\lambda)\theta_t - \eta\nabla L$$这等价于先对参数进行衰减,再沿梯度方向更新。衰减系数 $(1-\eta\lambda)$ 同时受到学习率 $\eta$ 和正则化系数 $\lambda$ 的影响。
但在Adam中,情况变得复杂。由于自适应学习率的存在,L2正则项会被"扭曲":
$$\theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}(\nabla L + \lambda\theta)$$这里的衰减系数变成了 $\frac{\eta\lambda}{\sqrt{\hat{v}_t}+\epsilon}$,它不再是常数,而是依赖于梯度历史 $\hat{v}_t$。对于那些梯度波动大的参数,分母大,实际衰减效果反而变弱了——这与权重衰减的初衷相悖。
AdamW的修正:解耦权重衰减
2019年,Ilya Loshchilov和Frank Hutter在ICLR上发表了论文《Decoupled Weight Decay Regularization》,提出了AdamW。核心修改非常简单:将权重衰减与梯度更新解耦。
AdamW的更新公式:
$$\theta_{t+1} = \theta_t - \eta\left(\frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} + \lambda\theta_t\right)$$权重衰减项 $\lambda\theta_t$ 不再经过自适应学习率的调整,而是直接作用于参数。这保证了所有参数都受到相同程度的正则化,与SGD的行为一致。
论文中的实验结果令人印象深刻:在图像分类任务上,AdamW使Adam的泛化性能显著提升,能够与SGD+momentum竞争。更重要的是,解耦后学习率和权重衰减成为独立的超参数,调参变得更加简单。
为什么Transformer特别需要Adam
到此为止,我们讨论的是Adam的一般优势。但为什么Transformer架构对Adam的依赖如此之深?2024年发表在NeurIPS上的一篇论文《Why Transformers Need Adam: A Hessian Perspective》给出了深入的答案。
重尾类别不平衡
语言模型的训练面临一个独特挑战:词汇表中不同token的出现频率差异极大。在典型的语料库中,少数高频词占据了大部分出现次数,而大量低频词只出现寥寥几次。
2024年的一篇论文《Heavy-Tailed Class Imbalance and Why Adam Outperforms Gradient Descent on Language Models》揭示了这个问题的数学本质。研究者发现,在重尾分布下,不同类别的Hessian矩阵特征值差异巨大:
$$\lambda_{max}(\nabla^2_{w_k} L) \propto \pi_k$$其中 $\pi_k$ 是第 $k$ 类的出现频率。高频类的Hessian最大特征值远大于低频类。
这意味着什么?对于高频词,损失曲面在这些方向上非常"陡峭";对于低频词,损失曲面则相对"平缓"。如果使用统一的学频率,SGD会陷入两难:
- 学习率太大:在低频词方向上发散
- 学习率太小:在高频词方向上收敛极慢
Adam的自适应机制完美解决了这个问题:它自动为陡峭方向分配小步长,为平缓方向分配大步长。
梯度异质性
另一篇2023年的论文《Toward Understanding Why Adam Converges Faster Than SGD for Transformers》提出了"方向锐度"(directional sharpness)的概念。
研究者发现,Transformer的梯度具有高度的异质性:不同参数的梯度方向和幅度差异极大。在这种场景下,SGD的单一学习率会导致某些方向更新过激,某些方向更新不足。
Adam通过追踪每个参数的梯度历史,能够:
- 识别哪些方向需要谨慎(高方差梯度)
- 识别哪些方向可以大步前进(稳定梯度)
- 自动平衡不同方向的更新幅度
为什么计算机视觉偏好SGD
有趣的是,计算机视觉领域至今仍广泛使用SGD+momentum。原因在于图像数据的特性与文本有本质区别:
- 数据分布:图像数据经过数据增强后,各类别的样本数量相对均衡
- 梯度特性:卷积网络的梯度相对均匀,异质性不如Transformer明显
- 泛化优势:大量研究表明,SGD倾向于找到"平坦极小值"(flat minima),泛化性能更好
平坦极小值的概念很直观:如果损失函数在某个极小值附近很平坦,即使测试数据有轻微偏移,损失也不会剧烈变化;而陡峭极小值对数据扰动非常敏感。
Adam由于自适应特性,更容易"冲进"陡峭的谷底;SGD的噪声则有助于逃离这些尖锐区域,停留在更平坦的位置。这解释了为什么Adam训练快但有时泛化差,SGD训练慢但泛化好。
AdamW的代价:内存开销
既然AdamW这么好,为什么不是所有任务都用它?一个直接的原因是内存开销。
内存计算
Adam需要为每个参数维护两个状态向量:一阶矩 $m$ 和二阶矩 $v$。这两个向量通常以FP32精度存储,以确保数值稳定性。
对于一个有 $N$ 个参数的模型:
- 参数本身:$N \times 4$ 字节(FP32)或 $N \times 2$ 字节(FP16)
- 一阶矩:$N \times 4$ 字节
- 二阶矩:$N \times 4$ 字节
- 梯度:$N \times 4$ 字节
以70亿参数的模型为例:
- 参数(FP16):14 GB
- Adam状态:$7 \times 10^9 \times 4 \times 2 = 56$ GB
- 梯度:28 GB
- 总计:约98 GB
这就是为什么大模型训练需要如此多的显存,也是ZeRO等技术专注于优化优化器状态存储的原因。
对比之下,SGD只需要存储一个动量向量:
- SGD状态:$N \times 4$ 字节 = 28 GB
- 总内存节省约28 GB
新的替代方案:Lion
2023年,Google Research提出了Lion优化器(EvoLved Sign Momentum),它只维护一个状态向量,比Adam节省50%的内存。
Lion的核心创新是用符号函数替代Adam的二阶矩:
$$\theta_{t+1} = \theta_t - \eta \cdot \text{sign}(\hat{m}_t)$$这个看似简单的改动,在多项实验中展现出与AdamW相当甚至更好的性能,同时内存占用减半。不过Lion需要不同的超参数配置(学习率通常要小3-10倍),迁移成本较高。
训练大模型的完整优化策略
选择AdamW只是开始。在实际训练大模型时,还需要配合一系列技巧:
学习率Warmup
Transformer训练几乎都需要学习率warmup:在训练开始时使用很小的学习率,逐渐增加到目标值。
2024年的论文《Why Warmup the Learning Rate? Underlying Mechanisms and Improvements》给出了理论解释:warmup的主要作用是让网络在早期阶段"适应"高学习率,将优化引导到损失曲面上更"良态"的区域。
典型配置:
- Warmup步数:总训练步数的1-10%
- 起始学习率:目标学习率的1/10到1/100
- 调度方式:线性增长
梯度裁剪
Adam虽然能自适应调整学习率,但仍可能遇到梯度爆炸问题。梯度裁剪是常用的防护措施:
$$g_t = \min\left(1, \frac{C}{\|g_t\|}\right) g_t$$其中 $C$ 是裁剪阈值。这确保了每次更新的梯度范数不超过 $C$,防止偶发的梯度尖峰破坏训练稳定性。
权重衰减配置
AdamW的权重衰减系数需要根据模型规模调整。论文《How to set AdamW’s weight decay as you scale model and dataset》建议将AdamW理解为指数移动平均模型,给出了缩放公式:
$$\lambda_{new} = \lambda_{base} \times \frac{B_{new}}{B_{base}} \times \frac{T_{base}}{T_{new}}$$其中 $B$ 是批次大小,$T$ 是训练步数。
典型配置:
- 预训练:weight_decay = 0.01 ~ 0.1
- 微调:weight_decay = 0.01 ~ 0.05
- 注意:bias和LayerNorm参数通常不应用权重衰减
没有万能的优化器
AdamW在Transformer训练中的统治地位并非偶然。它针对语言模型的独特挑战——重尾分布、梯度异质性、高维稀疏特征——提供了有效的解决方案。解耦权重衰减进一步提升了其泛化能力。
但这种优势伴随着代价:更高的内存开销、可能更差的平坦极小值特性、对warmup等技巧的依赖。在某些场景下(如计算机视觉),SGD+momentum仍然是更优的选择。
优化器的选择,归根结底是一个权衡问题:
| 优化器 | 收敛速度 | 内存占用 | 泛化性能 | 调参难度 | 适用场景 |
|---|---|---|---|---|---|
| SGD | 慢 | 低 | 好 | 高 | 计算机视觉 |
| SGD+momentum | 中 | 低 | 好 | 中 | 计算机视觉 |
| Adam | 快 | 高 | 中 | 低 | NLP, 稀疏数据 |
| AdamW | 快 | 高 | 较好 | 低 | 大模型预训练 |
| Lion | 快 | 中 | 好 | 中 | 内存受限场景 |
理解这些权衡,才能在特定任务上做出正确的选择。大模型训练是一个系统工程,优化器只是其中一个环节。与模型架构、数据管道、分布式策略协同配合,才能最终训练出高质量的模型。
参考文献
- Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv:1412.6980.
- Loshchilov, I., & Hutter, F. (2019). Decoupled Weight Decay Regularization. ICLR 2019.
- Chen, X., et al. (2024). Why Transformers Need Adam: A Hessian Perspective. NeurIPS 2024.
- Kang, D., et al. (2024). Heavy-Tailed Class Imbalance and Why Adam Outperforms Gradient Descent on Language Models. arXiv:2402.19449.
- Kalra, D. S., et al. (2024). Why Warmup the Learning Rate? Underlying Mechanisms and Improvements. arXiv:2406.09405.
- Chen, X., et al. (2023). Toward Understanding Why Adam Converges Faster Than SGD for Transformers. arXiv:2306.00204.
- Chen, X., & Liang, P. (2023). Symbolic Discovery of Optimization Algorithms. arXiv:2302.06675.
- Ruder, S. (2016). An overview of gradient descent optimization algorithms. arXiv:1609.04747.
- Keskar, N. S., et al. (2016). On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv:1609.04836.
- Zhang, J., et al. (2025). How to set AdamW’s weight decay as you scale model and dataset. arXiv:2405.13698.