权重衰减与L2正则化:为什么这个看似微小的区别让AdamW成为大模型训练的标配
一个困扰深度学习社区多年的困惑 2015年,Diederik Kingma和Jimmy Ba在ICLR上发表了Adam优化器论文(该论文于2014年12月提交arXiv)。这个结合了动量和自适应学习率的优化器迅速成为深度学习社区的最爱。然而,一个奇怪的现象开始困扰研究者们:使用Adam训练的模型,其泛化能力似乎总是不如使用普通SGD加权重衰减训练的模型。 ...
一个困扰深度学习社区多年的困惑 2015年,Diederik Kingma和Jimmy Ba在ICLR上发表了Adam优化器论文(该论文于2014年12月提交arXiv)。这个结合了动量和自适应学习率的优化器迅速成为深度学习社区的最爱。然而,一个奇怪的现象开始困扰研究者们:使用Adam训练的模型,其泛化能力似乎总是不如使用普通SGD加权重衰减训练的模型。 ...
2014年,Diederik Kingma和Jimmy Ba在ICLR上发表了一篇论文,标题平淡无奇——《Adam: A Method for Stochastic Optimization》。没有人预料到,这篇论文中的算法会在接下来的十年里统治深度学习训练领域。时至今日,无论是GPT、LLaMA还是Stable Diffusion,几乎所有大模型的训练日志里都能看到"optimizer=AdamW"的字样。 ...
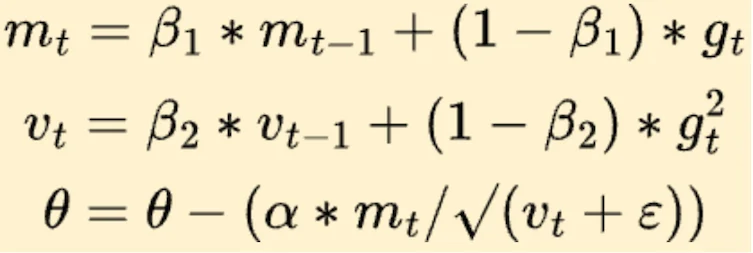
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...