训练过大模型的人都知道,学习率是最关键的超参数之一。设置得太小,训练几个月也收敛不了;设置得太大,模型直接发散。但即使找到了一个看似合适的初始值,直接从头到尾使用恒定学习率,效果往往也不尽如人意。
这就引出了一个核心问题:学习率应该在训练过程中如何变化?
这个看似简单的问题,背后涉及深刻的优化理论、损失景观几何性质,以及大量工程实践经验的积累。从GPT系列的Cosine Decay到LLaMA的配置,再到最新模型采用的WSD(Warmup-Stable-Decay)策略,学习率调度的选择一直在演进。
为什么需要学习率调度
要理解学习率调度的必要性,首先需要理解深度学习优化过程的特点。
神经网络的损失函数通常具有高度非凸的特性,存在大量的局部极小值、鞍点和平坦区域。在训练的不同阶段,模型所处的位置和面临的最优策略是完全不同的。
训练初期,模型参数通常是随机初始化的,距离任何合理的解都很远。此时如果学习率过大,梯度更新可能过于剧烈,导致参数在损失景观中"跳跃",甚至直接发散。但学习率过小,又会导致训练效率极低。
训练中期,模型已经找到了大致正确的方向,此时可以用较大的学习率快速前进,探索参数空间。
训练后期,模型已经接近某个局部极小值或平坦区域,此时需要用较小的学习率进行精细调整,避免在最优点附近震荡或跳过。
这种不同阶段对学习率的不同需求,就是学习率调度策略存在的根本原因。
损失景观视角:锐度与平坦度
2024年发表在NeurIPS上的论文《Why Warmup the Learning Rate? Underlying Mechanisms and Improvements》揭示了一个重要发现:学习率预热的核心作用是让网络能够容忍更大的学习率,通过将网络引导到损失景观中更良态(well-conditioned)的区域。
损失景观的"锐度"(sharpness)是理解这一机制的关键概念。锐度描述的是损失函数在某个点附近的曲率:锐利的极小值意味着参数稍有变化损失就急剧上升,而平坦的极小值则意味着参数在一定范围内变化时损失变化较小。
研究表明,平坦的极小值通常具有更好的泛化能力。而学习率预热,正是通过在训练初期逐渐增加学习率,帮助模型"软化"损失景观,避免一开始就陷入锐利的极小值。
学习率调度的核心策略
经过多年的研究和实践,几种主要的学习率调度策略已经形成,每种都有其独特的数学形式和适用场景。
Constant(恒定学习率)
最简单的策略是使用恒定的学习率,不做任何调整:
$$\eta_t = \eta_0$$虽然简单,但这种策略在深度学习中很少使用。问题在于它无法适应训练的不同阶段:初期可能因为学习率过大而发散,后期又因为学习率过大而无法精细收敛。
理论研究表明,对于凸优化问题,恒定学习率只能达到 $O(1/\sqrt{T})$ 的收敛速率,而合适的衰减策略可以达到 $O(1/T)$ 甚至更好的收敛速率。
Step Decay(阶梯衰减)
Step Decay是最早被广泛使用的学习率调度策略之一:
$$\eta_t = \eta_0 \cdot \gamma^{\lfloor t / T_{step} \rfloor}$$其中 $\gamma$ 是衰减因子(通常为0.1或0.5),$T_{step}$ 是衰减周期。这种策略在图像分类任务中非常流行,典型的做法是在训练到50%、75%、90%时分别将学习率降低。
这种策略的优点是简单可控,缺点是衰减时机是预设的,无法根据训练实际情况调整。
Exponential Decay(指数衰减)
指数衰减提供了更平滑的学习率变化:
$$\eta_t = \eta_0 \cdot \gamma^t$$或等价地:
$$\eta_t = \eta_0 \cdot e^{-\lambda t}$$指数衰减的特点是学习率下降速度逐渐变慢,这意味着训练初期变化较快,后期变化较慢。这种特性使其适合那些需要在训练后期进行精细调整的任务。
Cosine Decay(余弦衰减)
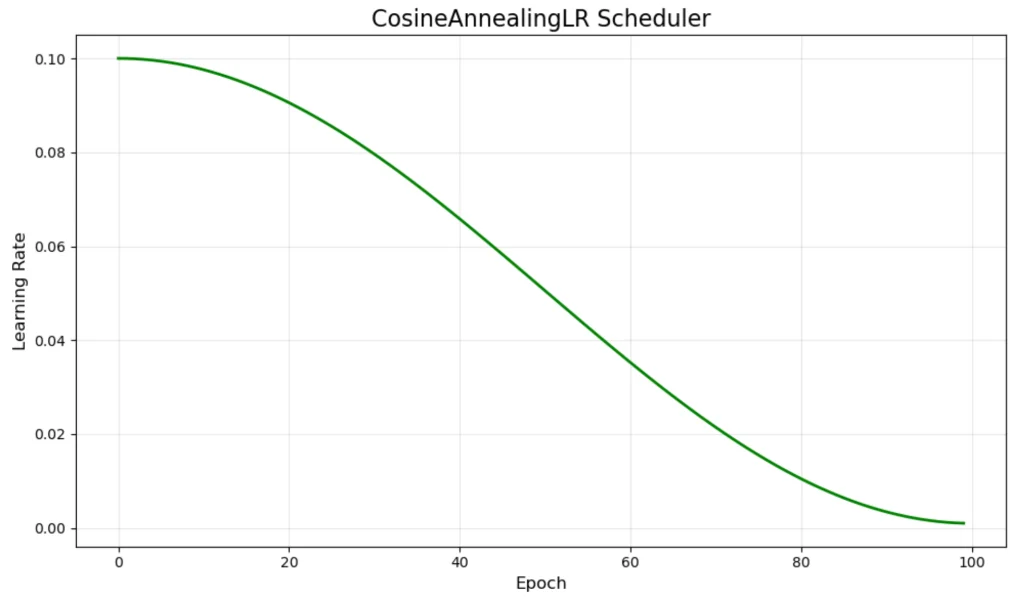
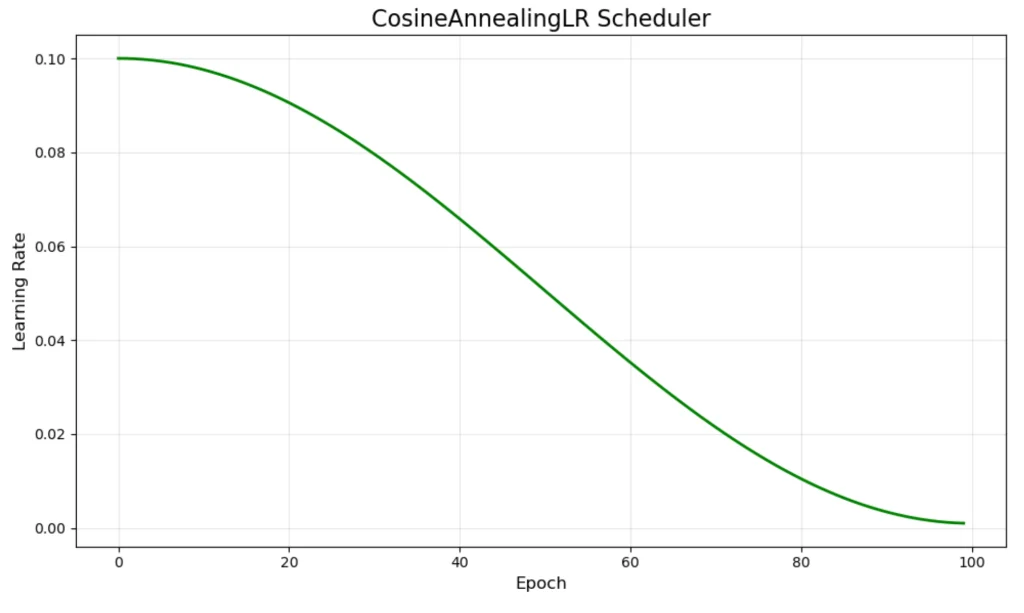
余弦衰减是大模型训练中最主流的策略之一:
$$\eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})(1 + \cos(\frac{t}{T}\pi))$$其中 $\eta_{max}$ 是最大学习率,$\eta_{min}$ 是最小学习率,$T$ 是总训练步数。
图片来源: MachineLearningMastery
余弦衰减的魅力在于其数学优雅性。它提供了几个关键特性:
- 平滑过渡:学习率在整个训练过程中平滑变化,没有突变
- 早期探索:训练初期保持较高学习率的时间较长,有利于参数空间的探索
- 后期精调:训练后期学习率下降速度加快,有助于精细收敛
这种策略可以追溯到模拟退火的思想——学习率类似于温度参数,需要平滑地冷却到零,避免突发的"相变"可能让优化器困在较差的极小值中。
Linear Decay(线性衰减)
线性衰减可能是最被低估的策略:
$$\eta_t = \eta_0 \cdot (1 - \frac{t}{T})$$2024年的论文《Optimal Linear Decay Learning Rate Schedules and Further Refinements》给出了一个重要结论:在最坏情况分析下,线性衰减是理论上最优的学习率调度策略。
论文进行了当时最大规模的学习率调度对比实验,涵盖10个深度学习任务、多个大语言模型,以及一系列逻辑回归问题。结果显示,线性衰减在所有非自适应调度中表现最好,整体上甚至超越了余弦衰减。
更令人惊讶的是,论文提出的"精炼调度"(Refined Schedule)方法——利用之前的训练运行中的梯度信息来生成改进的调度——进一步提升了性能。这种方法自动产生学习率预热和训练末期的快速衰减,与经验最佳实践高度一致。
WSD(Warmup-Stable-Decay)
WSD是近年来大模型训练中兴起的新策略,它将训练过程明确分为三个阶段:
- Warmup阶段:学习率从接近零线性增加到峰值
- Stable阶段:学习率保持在峰值恒定
- Decay阶段:学习率从峰值衰减到某个小值
graph LR
A[Warmup阶段] --> B[Stable阶段]
B --> C[Decay阶段]
subgraph 学习率变化
D[线性增加] --> E[保持恒定]
E --> F[逐步衰减]
end
WSD策略的优势在于其灵活性。与传统的Cosine Decay需要预先知道总训练步数不同,WSD允许在Stable阶段随时停止,然后进入Decay阶段。这对于那些可能需要增加训练数据或调整训练计划的场景特别有用。
DeepSeek-V3的训练就采用了WSD策略,学习率在前2000步线性增加到2.2e-4,然后在训练过程中保持恒定,最后在训练末期的10%token上进行衰减。
Warmup:为什么必不可少
对于Transformer和大模型训练,Warmup几乎是标配。但为什么需要Warmup?
传统解释
传统的解释主要有两点:
- 避免梯度爆炸:训练初期模型参数随机,梯度可能非常大。直接使用大学习率可能导致参数更新过于剧烈
- Adam优化器的特殊性:Adam的二阶矩估计在初期不准确,需要时间积累
最新研究:锐度控制
2024年NeurIPS论文提供了更深入的理解。研究发现,Warmup的主要作用是通过渐进式增加学习率,帮助模型进入损失景观中更平坦的区域。
实验表明,有Warmup的训练最终能达到更大的学习率而不发散。这是因为在Warmup期间,模型有机会在低学习率下先找到一个"温和"的起点,然后逐渐适应更大的更新步长。
论文还发现了一个有趣的现象:Warmup期间存在两种不同的运行模式:
- 锐度降低阶段:当初始化位于损失景观的锐利区域时,Warmup会引导模型进入更平坦的区域
- 锐度增加阶段:当初始化已经位于相对平坦的区域时,模型可能在初期经历锐度增加
这意味着Warmup的必要性和最佳长度可能取决于初始化方式和模型参数化。
Warmup长度的选择
主流模型的Warmup长度差异很大:
| 模型 | 峰值学习率 | Warmup步数 | 总训练步数 | Warmup占比 |
|---|---|---|---|---|
| GPT-3 | 6e-5 | 375M | 300B | 0.125% |
| LLaMA-65B | 3e-4 | 2000 | 1.5T | 0.00013% |
| DeepSeek-V3 | 2.2e-4 | 2000 | - | - |
一个经验法则是:更大的模型和更大的批量大小通常需要更长的Warmup。
学习率与批量大小的缩放定律
当改变批量大小时,学习率应该如何调整?这是分布式训练中的关键问题。
Linear Scaling Rule
线性缩放规则是最常用的启发式方法:
$$\eta_{new} = \eta_{base} \times \frac{B_{new}}{B_{base}}$$即批量大小增大$k$倍,学习率也增大$k$倍。这个规则的直觉是:更大的批量意味着梯度估计更准确,因此可以用更大的步长。
Square Root Scaling Rule
平方根缩放规则提供了另一种思路:
$$\eta_{new} = \eta_{base} \times \sqrt{\frac{B_{new}}{B_{base}}}$$这个规则源于理论分析,考虑了梯度噪声对方差的影响。对于Adam优化器,研究表明平方根缩放可能更合适。
2024年NeurIPS的论文《Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling》发现,最优学习率与批量大小的关系并非单调,而是存在一个"激增"现象——在某个临界批量大小附近,最优学习率会出现突然的跳跃。
不同策略的对比分析
Cosine vs Linear Decay
在LLM训练社区,Cosine Decay长期占据主导地位。但最新研究正在挑战这一共识。
2024年的大规模对比实验表明,Linear Decay在大多数任务上匹配或超越Cosine Decay。特别是在训练时间较短(少于30个epoch)的情况下,Linear Decay的优势更加明显。
Cosine Decay的一个潜在问题是它对总训练步数的依赖——你必须预先知道要训练多久。如果中途决定继续训练,Cosine Decay需要重新调整,而WSD策略则更加灵活。
WSD vs Cosine Decay
WSD策略近年来的崛起源于其独特的优势:
- 训练灵活性:不需要预先确定总训练步数
- 续训友好:只需要从Stable阶段的检查点继续训练即可
- 消融实验便利:不同的训练长度可以共享同一个Stable阶段的检查点
但WSD也有其复杂性:Decay阶段何时开始?持续多久?用哪种衰减曲线?这些都是需要调优的超参数。
最新的WSM策略
2025年,Ling团队提出了WSM(Warmup-Stable-Merge)策略,进一步简化了训练流程。WSM完全放弃了Decay阶段,转而使用检查点合并来实现类似的效果。
理论分析表明,通过精心设计的检查点加权合并,可以模拟任意的学习率衰减策略。这意味着:
- 训练时使用恒定学习率一路到底
- 训练结束后,离线地对检查点进行加权平均
- 不同的合并权重对应不同的"虚拟衰减曲线"
WSM的优势在于将所有关于Decay的决策后置到模型交付阶段,可以用最小的计算成本尝试多种"衰减策略"。
训练动态与学习率的深层联系
损失曲线的演变
不同的学习率调度策略会产生截然不同的损失曲线。WSD策略产生一种独特的训练动态:
- Warmup阶段:损失快速下降
- Stable阶段:损失相对平稳,可能有轻微震荡
- Decay阶段:损失出现明显的下降
这种"平坦高原+陡峭下降"的模式与Cosine Decay的平滑下降形成鲜明对比。
梯度范数的演变
论文《Optimal Linear Decay Learning Rate Schedules》提出了一个重要洞见:最优的学习率调度应该考虑整个梯度范数序列。
精炼调度方法利用这一洞见,从之前的训练运行中提取梯度信息,生成针对特定问题优化的学习率调度。这种自适应调度通常呈现"预热+稳定+快速衰减"的模式,与经验最佳实践高度一致。
实践指南:如何选择学习率调度
预训练阶段
对于大模型预训练,当前的推荐做法是:
- 必须使用Warmup:通常占总训练步数的0.1%-1%
- 主流选择:Cosine Decay(成熟稳定)或WSD(灵活可续)
- 学习率范围:峰值学习率通常在1e-4到3e-4之间
- 衰减终点:通常衰减到峰值学习率的10%(即10倍衰减)
微调阶段
微调阶段的策略与预训练有所不同:
- 较小的峰值学习率:通常比预训练低1-2个数量级
- 可选的Warmup:如果微调数据与预训练数据分布差异大,建议使用Warmup
- 较短的训练周期:可能不需要复杂的衰减策略
不同场景的策略选择
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| 标准预训练 | Cosine Decay + Warmup | 成熟、稳定、社区经验丰富 |
| 需要续训 | WSD | 灵活性高,续训方便 |
| 快速实验 | Linear Decay + Warmup | 在短训练周期表现更好 |
| 不确定训练长度 | WSD或WSM | 将决策后置 |
数学细节:主要调度策略的公式
带预热的余弦衰减
完整的带预热的余弦衰减可以表示为:
$$\eta_t = \begin{cases} \frac{t}{T_{warmup}} \eta_{max} & t < T_{warmup} \\ \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})(1 + \cos(\frac{t - T_{warmup}}{T - T_{warmup}}\pi)) & t \geq T_{warmup} \end{cases}$$WSD策略
WSD策略的数学表示:
$$\eta_t = \begin{cases} \frac{t}{T_{warmup}} \eta_{max} & t < T_{warmup} \\ \eta_{max} & T_{warmup} \leq t < T_{decay} \\ f(t - T_{decay}) & t \geq T_{decay} \end{cases}$$其中 $f(\cdot)$ 可以是线性衰减、余弦衰减或其他形式。
精炼调度
精炼调度的学习率由梯度范数序列决定:
$$\eta_t \propto \sqrt{\sum_{s=t}^{T} \frac{1}{\|g_s\|^2}}$$这种方法自动产生预热和快速衰减的效果,因为:
- 训练初期梯度范数通常较大,导致学习率较小(预热效果)
- 训练末期梯度范数通常较小,导致学习率进一步下降
未来展望
学习率调度领域仍在快速发展。几个值得关注的趋势:
- 自适应调度:基于训练动态自动调整学习率的策略越来越受到重视
- 调度与架构的协同设计:不同架构可能需要不同的调度策略
- 理论上界分析:优化理论正在为实践提供更坚实的指导
2025年的研究已经开始探索"无限学习率调度"(Infinite Learning Rate Schedule)等新概念,这些方法可能在未来取代当前的主流策略。
总结
学习率调度是大模型训练的核心技术之一。从恒定学习率到Step Decay,从Cosine Decay到WSD,策略的演进反映了对训练动态理解的深化。
核心要点:
- Warmup不可或缺:帮助模型进入良态区域,允许使用更大的峰值学习率
- 没有万能策略:Linear Decay在理论上最优,Cosine Decay在实践中稳健,WSD在灵活性上领先
- 匹配训练需求:已知训练长度用Cosine,不确定用WSD,短训练周期用Linear
- 关注训练动态:损失曲线、梯度范数都是调整学习率的重要信号
学习率调度的选择,归根结底是在训练效率、最终性能和工程便利性之间寻找平衡。理解每种策略背后的原理,才能在面对具体问题时做出明智的决策。
参考文献
- Kalra, D. S., et al. “Why Warmup the Learning Rate? Underlying Mechanisms and Improvements.” NeurIPS 2024.
- Defazio, A., et al. “Optimal Linear Decay Learning Rate Schedules and Further Refinements.” arXiv 2024.
- Hu, E., et al. “Understanding Warmup-Stable-Decay Learning Rates.” arXiv 2024.
- Hoffmann, J., et al. “Training Compute-Optimal Large Language Models.” (Chinchilla) 2022.
- Brown, T., et al. “Language Models are Few-Shot Learners.” (GPT-3) NeurIPS 2020.
- Touvron, H., et al. “LLaMA: Open and Efficient Foundation Language Models.” 2023.
- DeepSeek-AI. “DeepSeek-V3 Technical Report.” 2024.
- Ling Team. “WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training.” arXiv 2025.
- Smith, L. N. “Cyclical Learning Rates for Training Neural Networks.” WACV 2017.
- Loshchilov, I., & Hutter, F. “SGDR: Stochastic Gradient Descent with Warm Restarts.” ICLR 2017.