梯度下降优化器:从SGD到AdamW,为什么这个选择能决定模型的命运
2014年,Diederik Kingma和Jimmy Ba在ICLR上发表了一篇论文,标题平淡无奇——《Adam: A Method for Stochastic Optimization》。没有人预料到,这篇论文中的算法会在接下来的十年里统治深度学习训练领域。时至今日,无论是GPT、LLaMA还是Stable Diffusion,几乎所有大模型的训练日志里都能看到"optimizer=AdamW"的字样。 ...
2014年,Diederik Kingma和Jimmy Ba在ICLR上发表了一篇论文,标题平淡无奇——《Adam: A Method for Stochastic Optimization》。没有人预料到,这篇论文中的算法会在接下来的十年里统治深度学习训练领域。时至今日,无论是GPT、LLaMA还是Stable Diffusion,几乎所有大模型的训练日志里都能看到"optimizer=AdamW"的字样。 ...
在深度学习的众多超参数中,batch size(批次大小)可能是最容易被忽视的一个。相比于学习率的精细调节、模型架构的反复打磨,batch size的选择往往只遵循一个简单的规则:在显存允许的范围内,尽量设大。 ...
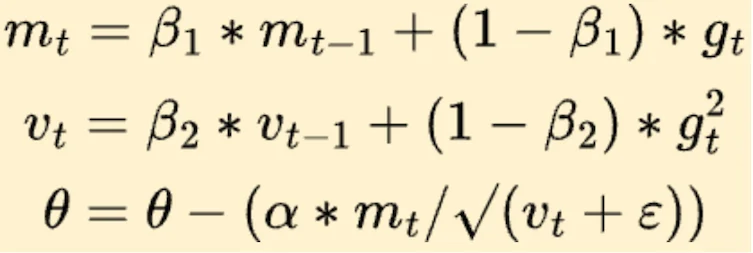
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...