神经网络是如何学习的:从前向传播到反向传播的完整训练过程解析
当你点击"训练"按钮时,神经网络内部发生了什么? 想象你正在训练一个图像分类模型。你准备了数据集,设置了超参数,点击了"开始训练"按钮。屏幕上开始显示loss值不断下降,准确率不断上升。但在这些数字背后,究竟发生了什么?模型是如何从"一无所知"变成"精准识别"的? ...
当你点击"训练"按钮时,神经网络内部发生了什么? 想象你正在训练一个图像分类模型。你准备了数据集,设置了超参数,点击了"开始训练"按钮。屏幕上开始显示loss值不断下降,准确率不断上升。但在这些数字背后,究竟发生了什么?模型是如何从"一无所知"变成"精准识别"的? ...
一个困扰深度学习社区多年的困惑 2015年,Diederik Kingma和Jimmy Ba在ICLR上发表了Adam优化器论文(该论文于2014年12月提交arXiv)。这个结合了动量和自适应学习率的优化器迅速成为深度学习社区的最爱。然而,一个奇怪的现象开始困扰研究者们:使用Adam训练的模型,其泛化能力似乎总是不如使用普通SGD加权重衰减训练的模型。 ...
2014年,Diederik Kingma和Jimmy Ba在ICLR上发表了一篇论文,标题平淡无奇——《Adam: A Method for Stochastic Optimization》。没有人预料到,这篇论文中的算法会在接下来的十年里统治深度学习训练领域。时至今日,无论是GPT、LLaMA还是Stable Diffusion,几乎所有大模型的训练日志里都能看到"optimizer=AdamW"的字样。 ...
训练大语言模型时,你是否遇到过这样的情况:损失函数曲线突然出现莫名其妙的尖峰,模型仿佛"失忆"了一般,之前学到的知识瞬间消失?或者在训练循环神经网络时,梯度变成了NaN,整个训练过程直接崩溃?这些问题的背后,往往隐藏着一个共同的罪魁祸首——梯度爆炸。 ...
在深度学习的众多超参数中,batch size(批次大小)可能是最容易被忽视的一个。相比于学习率的精细调节、模型架构的反复打磨,batch size的选择往往只遵循一个简单的规则:在显存允许的范围内,尽量设大。 ...
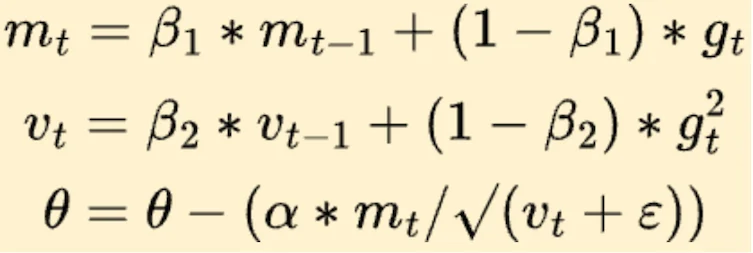
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...