2020年,OpenAI发布了拥有1750亿参数的GPT-3模型。按照FP16精度计算,仅存储模型权重就需要350GB显存——而当时最先进的NVIDIA A100 GPU只有80GB显存。这意味着,即使不考虑训练过程中额外的梯度、优化器状态和激活值,单张GPU连加载模型都做不到。
问题的本质是物理限制:显存容量增长的速度远落后于模型规模膨胀的速度。2017年的V100有32GB显存,2020年的A100提升到80GB,增长约2.5倍;同期,最大的语言模型参数量从GPT-2的15亿增长到GPT-3的1750亿,增长超过100倍。
面对这个数量级的差距,唯一的出路是把模型拆开,分到多张GPU上。但怎么拆?拆完之后如何保证训练的正确性和效率?这个问题的答案,构成了现代大模型训练的技术基石。
数据并行:简单方案的内存陷阱
最直观的想法是数据并行(Data Parallelism,DP):每张GPU复制一份完整的模型,各自处理不同的数据批次,最后同步梯度。
这个方案的优势在于实现简单。PyTorch的DistributedDataParallel(DDP)只需要几行代码就能启用,而且对于小模型效果很好——理论上,N张GPU可以获得接近N倍的加速。
但对于大模型,数据并行会撞上一堵墙。以GPT-3为例:
- 模型权重(FP16):175B × 2字节 = 350GB
- 优化器状态(Adam,FP32):175B × 8字节(权重+动量+方差)= 1.4TB
- 梯度(FP16):175B × 2字节 = 350GB
单张GPU需要存储约2TB的数据——这在物理上是不可能的。更糟糕的是,数据并行的核心假设正是"每张GPU能存下完整模型",一旦这个假设不成立,整个方案就失效了。
这就是数据并行的内存墙问题:模型太大,单卡存不下,而数据并行要求每张卡都有完整副本。
模型并行:切分模型的两种哲学
既然数据并行行不通,那就只能把模型本身拆开。这就是模型并行(Model Parallelism)的核心思想:不再复制模型,而是让每张GPU只存储模型的一部分。
模型并行有两种截然不同的切分方式:张量并行(Tensor Parallelism,TP)和流水线并行(Pipeline Parallelism,PP)。前者"垂直"切分——把一层内的矩阵运算拆开;后者"水平"切分——把不同层分配给不同GPU。
张量并行:让单个矩阵运算跨越多张GPU
张量并行的核心问题看起来很抽象:如何把一个矩阵乘法拆到多张GPU上执行?
考虑Transformer中最常见的操作:$\mathbf{Y} = \mathbf{X}\mathbf{W}$,其中$\mathbf{X} \in \mathbb{R}^{B \times S \times H}$是输入激活,$\mathbf{W} \in \mathbb{R}^{H \times H}$是权重矩阵。假设我们要把计算分配到2张GPU上。
方案一:按列切分权重矩阵
将$\mathbf{W}$沿列方向切成两半:$\mathbf{W} = [\mathbf{W}_1, \mathbf{W}_2]$。每张GPU存储一半权重,执行各自的矩阵乘法:
- GPU1:$\mathbf{Y}_1 = \mathbf{X}\mathbf{W}_1$
- GPU2:$\mathbf{Y}_2 = \mathbf{X}\mathbf{W}_2$
结果是$\mathbf{Y} = [\mathbf{Y}_1, \mathbf{Y}_2]$,两个输出在列方向上拼接。这里的关键是:输入$\mathbf{X}$在两张GPU上完全相同,但权重和输出各存一半。
这种切分方式称为Column Parallel,适用于MLP块中的第一个线性层。切分后的输出可以直接通过GeLU等非线性激活函数——因为每个位置的激活函数是独立计算的,不需要跨GPU通信。
方案二:按行切分权重矩阵
如果输入已经被按列切分,下一步就需要按行切分权重。设输入$\mathbf{Y} = [\mathbf{Y}_1, \mathbf{Y}_2]$(来自上一步的列切分输出),权重$\mathbf{V}$按行切分为$\mathbf{V} = \begin{bmatrix} \mathbf{V}_1 \\ \mathbf{V}_2 \end{bmatrix}$:
- GPU1:$\mathbf{Z}_1 = \mathbf{Y}_1\mathbf{V}_1$
- GPU2:$\mathbf{Z}_2 = \mathbf{Y}_2\mathbf{V}_2$
根据矩阵乘法的性质,$\mathbf{Z} = \mathbf{Y}\mathbf{V} = \mathbf{Y}_1\mathbf{V}_1 + \mathbf{Y}_2\mathbf{V}_2$。这意味着最终结果需要跨GPU求和——即All-Reduce操作。
这种切分方式称为Row Parallel,适用于MLP块中的第二个线性层。

图片来源: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-LM论文中的这张图清晰展示了MLP块的切分策略:第一个线性层使用Column Parallel(权重按列切分),第二个线性层使用Row Parallel(权重按行切分),中间只需要一次All-Reduce同步。
注意力层的切分
注意力层的切分更加自然。多头注意力本身就是多个独立的头,可以把不同的头分配给不同的GPU。假设有8个注意力头、2张GPU:
- GPU1:处理头1-4,计算$\mathbf{Q}_1, \mathbf{K}_1, \mathbf{V}_1$和注意力输出
- GPU2:处理头5-8,计算$\mathbf{Q}_2, \mathbf{K}_2, \mathbf{V}_2$和注意力输出
每个头的计算完全独立,不需要任何通信。最后输出投影层使用Row Parallel,通过All-Reduce汇总结果。
张量并行的优势在于通信模式简单:每个Transformer层只需要两次All-Reduce(一次在MLP块末尾,一次在注意力块末尾)。但缺点也很明显:All-Reduce需要同步所有参与张量并行的GPU,通信延迟会随GPU数量增加而增长。因此,张量并行通常只在单机内部使用——单机内的GPU通过NVLink互联,带宽可达数百GB/s;跨机通信的带宽则低一个数量级。
流水线并行:把层串联成流水线
张量并行把一层"横向"拆开,流水线并行则把模型"纵向"切分——把不同层分配给不同的GPU。
假设一个24层的Transformer模型,分配到4张GPU上:
- GPU0:第1-6层
- GPU1:第7-12层
- GPU2:第13-18层
- GPU3:第19-24层
前向传播时,数据依次流经GPU0→GPU1→GPU2→GPU3;反向传播时,梯度反向流动。
朴素流水线的问题
最直接的实现是等一个批次在所有GPU上完成前向和反向传播后,再处理下一个批次。但这种朴素方案有一个致命问题:GPU利用率极低。
当GPU3在计算最后几层的输出时,GPU0处于空闲状态;当GPU0在计算梯度时,GPU3又处于空闲状态。在任何时刻,只有一张GPU在工作——这相当于串行执行,完全没有利用并行的优势。
GPipe:微批次与流水线
Google在2019年提出的GPipe算法引入了微批次(Micro-batch)的概念:把一个大批次切分成多个微批次,让不同GPU同时处理不同微批次的不同阶段。
假设批次大小为64,切分成4个微批次(每个大小16),在4张GPU上的执行时序如下:
| 时刻 | GPU0 | GPU1 | GPU2 | GPU3 |
|---|---|---|---|---|
| 0 | F(mb1) | |||
| 1 | F(mb2) | F(mb1) | ||
| 2 | F(mb3) | F(mb2) | F(mb1) | |
| 3 | F(mb4) | F(mb3) | F(mb2) | F(mb1) |
| 4 | F(mb4) | F(mb3) | F(mb2) | |
| 5 | F(mb4) | F(mb3) | ||
| 6 | B(mb4) | F(mb4) | ||
| … | … | … | … | … |
F代表前向传播,B代表反向传播,mb代表微批次。
这样,多张GPU可以同时工作,大大提高了利用率。但GPipe仍有一个问题:流水线气泡(Pipeline Bubble)。
流水线气泡:无法消除的等待时间
在流水线的开始阶段,GPU3必须等待GPU0-GPU2完成前向传播才能开始计算;在流水线的结束阶段,GPU0必须等待GPU1-GPU3完成反向传播才能开始计算。这些等待时间就是"气泡"。
气泡占总时间的比例可以近似计算:
$$\text{气泡比例} \approx \frac{p-1}{m}$$其中$p$是流水线深度(GPU数量),$m$是微批次数量。要降低气泡比例,需要增加微批次数量$m$。但微批次越多,每个微批次越小,计算效率越低(GPU kernel launch开销占比增加),而且需要缓存的激活值越多(每个微批次的激活值都要保留到反向传播)。
PipeDream与1F1B调度
2019年提出的PipeDream算法采用了不同的调度策略:1F1B(One Forward One Backward)。核心思想是,一旦最后一个GPU完成某个微批次的前向传播,立即开始它的反向传播,而不是等所有微批次都完成前向传播。
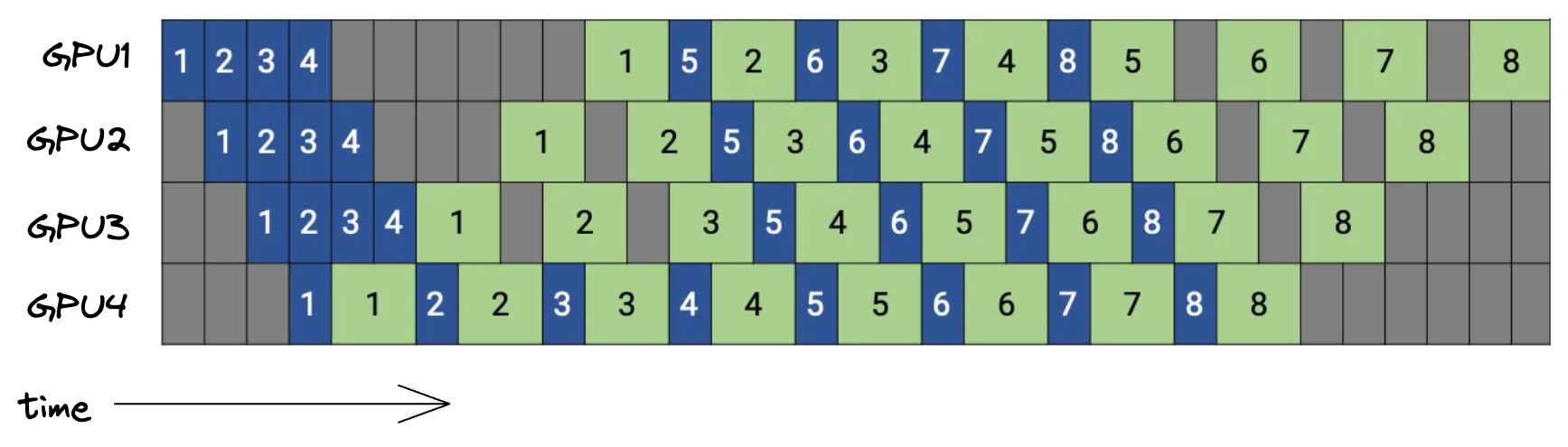
图片来源: Pipeline-Parallelism: Distributed Training via Model Partitioning
从图中可以看到,在稳态阶段,每张GPU交替执行前向和反向传播,内存中只需要保存有限数量的激活值(约等于流水线深度),而不是GPipe中的全部微批次激活值。
2023年,DeepSpeed团队提出了Zero Bubble Pipeline Parallelism,通过重新设计调度策略,理论上可以将流水线气泡降低到接近零。这需要更复杂的调度和更多的内存,但在大规模训练中已经得到应用。
ZeRO:数据并行的革命性优化
模型并行解决了"单卡存不下"的问题,但引入了新的复杂性:张量并行需要高频通信,流水线并行存在气泡。有没有一种方法既能享受数据并行的简单性,又能突破内存限制?
Microsoft在2020年提出的ZeRO(Zero Redundancy Optimizer)正是这样一个方案。它的核心洞察是:数据并行的内存冗余主要来自优化器状态,而不是模型权重本身。
考虑一个175B参数的模型,使用Adam优化器:
| 状态 | 每参数占用 | 总大小 |
|---|---|---|
| 模型权重(FP16) | 2字节 | 350GB |
| 梯度(FP16) | 2字节 | 350GB |
| Adam动量(FP32) | 4字节 | 700GB |
| Adam方差(FP32) | 4字节 | 700GB |
| 总计 | 12字节 | 2.1TB |
可以看到,优化器状态(动量+方差)占了总内存的2/3!而在数据并行中,这部分状态在每张GPU上完全相同——这是巨大的冗余。
ZeRO的核心思想是:把这些状态切分到不同GPU上,需要时再聚合。
ZeRO的三个阶段
ZeRO-1:切分优化器状态
只切分优化器状态(动量和方差),模型权重和梯度仍然在每张GPU上完整复制。更新权重时,每张GPU只更新自己负责的那部分参数的优化器状态。
内存节省:假设使用$N_d$张GPU做数据并行,优化器状态的内存占用降为原来的$1/N_d$。对于175B模型,从700GB+700GB降到$1400/N_d$ GB。
ZeRO-2:切分优化器状态和梯度
在ZeRO-1基础上,进一步切分梯度。反向传播时,每张GPU只保留自己负责的那部分参数的梯度。
内存节省:优化器状态+梯度的总内存占用降为原来的$1/N_d$。
ZeRO-3:切分所有状态
在ZeRO-2基础上,进一步切分模型权重。前向传播时,通过All-Gather操作临时获取需要的权重;使用完后立即释放。
内存节省:模型权重+梯度+优化器状态的总内存占用都降为原来的$1/N_d$。
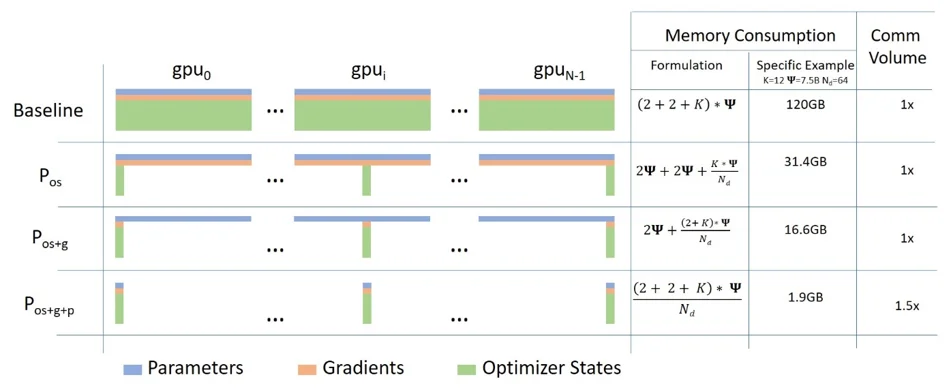
这张图直观展示了ZeRO三个阶段的内存节省效果。ZeRO-3可以将单GPU内存占用降低到原来的$1/N_d$,理论上使用1024张GPU就可以训练万亿参数模型。
ZeRO-Infinity:突破显存限制
ZeRO-3已经大大降低了GPU内存需求,但对于更大的模型,仍然可能超出单GPU显存。ZeRO-Infinity进一步引入了CPU卸载(CPU Offload)和NVMe卸载:把暂时不需要的数据放到CPU内存或NVMe SSD上,需要时再加载回GPU。
这种方法虽然增加了数据传输延迟,但突破了GPU显存的物理限制。结合NVMe的高速读写(数GB/s),可以在可接受的开销下训练万亿级参数模型。
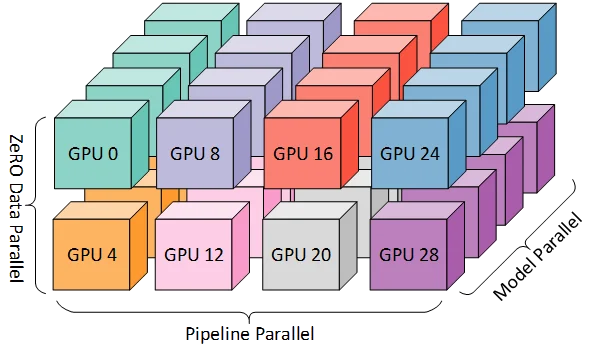
3D并行:终极方案
对于千亿乃至万亿参数的大模型,单一的并行策略往往不足以同时解决内存和效率问题。实际生产中,通常采用3D并行:数据并行(DP)+ 张量并行(TP)+ 流水线并行(PP)的组合。
并行维度的正交性
这三种并行策略是正交的,可以在不同维度上独立配置:
- 张量并行(TP):在单机内部使用,利用NVLink的高带宽实现低延迟通信
- 流水线并行(PP):跨机器使用,减少跨机器通信的频率
- 数据并行(DP):在TP和PP的基础上进一步扩展规模
一个典型的配置示例:假设有128张GPU,分布在16台机器上(每台8张GPU),训练一个530B参数的模型:
- 张量并行度 TP = 8(单机内8张GPU)
- 流水线并行度 PP = 4(16台机器分为4个流水线阶段,每个阶段4台机器)
- 数据并行度 DP = 4(4个完整的模型副本并行处理不同数据)
验证:8 × 4 × 4 = 128,正好使用全部GPU。
通信模式的复杂化
3D并行带来了复杂的通信拓扑:
- TP通信:同一机器内的GPU通过All-Reduce同步张量切分的结果
- PP通信:相邻流水线阶段之间通过点对点通信传递激活值和梯度
- DP通信:同一数据并行组内的GPU通过All-Reduce同步梯度
这些通信需要精心设计的网络拓扑来优化。例如,Megatron-LM采用如下原则:
- TP只在单机内使用,避免跨机的高延迟通信
- PP阶段之间的通信使用InfiniBand,充分利用高带宽
- DP的梯度同步与PP的反向传播重叠,隐藏通信延迟
实践中的选择策略
面对具体的训练任务,如何选择并行策略?以下是一个实践指南:
单GPU能存下模型吗?
首先计算模型所需内存。一个经验公式:
$$\text{单GPU内存需求} \approx 20 \times \text{参数量}$$这个系数考虑了:
- FP16权重:2字节/参数
- FP16梯度:2字节/参数
- FP32优化器状态(权重+动量+方差):12字节/参数
- 激活值:约4字节/参数(取决于批次大小和序列长度)
例如,7B参数模型大约需要140GB内存——单张A100 80GB不够,但可以用ZeRO-2配合激活重计算。
如果单GPU不够
场景1:模型稍大(如7B-13B),GPU间通信带宽高
优先使用ZeRO-2或ZeRO-3。实现简单,不需要修改模型代码,适合大多数场景。
场景2:模型很大(如70B+),需要充分利用多GPU内存
使用张量并行。适合单机多卡场景,通信延迟低。可以与ZeRO结合使用。
场景3:超大规模模型(如175B+),需要跨机器训练
使用3D并行:
- 单机内使用TP
- 跨机器使用PP
- 整体使用ZeRO-DP
性能调优要点
- TP度数不要超过单机GPU数:跨机器的TP通信延迟太高
- PP阶段数与微批次数的平衡:微批次数至少是PP阶段数的4倍,才能有效减少气泡
- 激活重计算:对于内存受限的场景,牺牲约30%计算时间换取显著内存节省
- 混合精度训练:使用BF16或FP16,将内存需求减半
技术演进的前沿
大模型并行训练技术仍在快速发展。几个值得关注的方向:
序列并行(Sequence Parallelism):针对超长序列训练(如100K+ tokens),将序列维度切分到多个GPU上。Ring Attention是代表性技术,通过环形通信模式实现近乎无限序列长度的训练。
专家并行(Expert Parallelism):针对MoE(Mixture of Experts)模型,将不同的专家网络分配到不同GPU上。Switch Transformer和Mixtral等模型采用了这种策略。
自动化并行策略搜索:手动配置3D并行参数需要大量经验。Alpa等框架可以根据模型结构和硬件拓扑,自动搜索最优的并行策略组合。
结语
从数据并行到模型并行,从张量并行到流水线并行,再到ZeRO和3D并行,大模型训练技术的发展史本质上是一部与物理限制博弈的历史。显存有限,就用切分把问题变小;通信有延迟,就用调度把等待藏起来。
这些技术的背后,是同一个核心思想:把大问题拆解成小问题,让多个计算单元并行处理,最后汇总结果。听起来简单,但如何在拆分后保证数学等价性、如何平衡计算与通信、如何最小化内存峰值——每一个细节都是工程与算法的精妙结合。
当GPT-3在数千张GPU上完成训练时,它不仅是一个语言模型的诞生,更是分布式训练技术成熟的标志。今天,这些技术已经开源并被广泛采用,让更多研究者和工程师能够训练自己的大模型。技术的民主化,正在推动AI领域向前迈进。
参考文献
- Shoeybi, M., et al. (2019). Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053.
- Huang, Y., et al. (2019). GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. NeurIPS 2019.
- Harlap, A., et al. (2018). PipeDream: Fast and Efficient Pipeline Parallel DNN Training. SOSP 2019.
- Rajbhandari, S., et al. (2020). ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. SC 2020.
- Narayanan, D., et al. (2021). Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. SC 2021.
- Korthikanti, V., et al. (2022). Reducing Activation Recomputation in Large Transformer Models. arXiv:2205.05198.
- Li, J., et al. (2021). Sequence Parallelism: Long Sequence Training from System Perspective. ACL 2021.
- NVIDIA. Megatron-LM Documentation. https://docs.nvidia.com/nemo/megatron-bridge/latest/
- Microsoft. DeepSpeed Documentation. https://www.deepspeed.ai/docs/
- Hugging Face. Parallelism Methods. https://huggingface.co/docs/transformers/perf_train_gpu_many