2012年9月30日,ImageNet图像识别挑战赛的结果震惊了整个计算机视觉领域。一个名为AlexNet的卷积神经网络以15.3%的错误率夺冠,比第二名整整低了十个百分点。这个数字本身已经足够惊人,但更关键的是AlexNet的训练方式:它使用了两个GTX 580显卡并行训练,耗时仅五到六天。如果用当时的CPU完成同样的训练,需要数十年。
这不是个例。今天训练一个GPT-3规模的大语言模型,在单张H100 GPU上大约需要数月时间。换算成CPU集群,即便拥有上千个核心,训练周期也会拉长到无法承受的程度。为什么一张显卡能做到整个CPU集群都难以企及的计算能力?答案藏在GPU与CPU截然不同的设计哲学中。
两种芯片,两个世界
打开任何一本计算机体系结构教材,CPU被描述为"通用处理器",能够高效处理各种类型的任务。这种通用性的代价是复杂性:现代CPU需要支持数百种指令、处理复杂的分支预测、管理多层缓存一致性、维护操作系统的安全隔离。为了在单线程中获得极致的执行速度,CPU将大量晶体管投入到控制逻辑和缓存上。
根据公开的架构分析,现代CPU约70%到80%的晶体管用于缓存和分支预测等控制逻辑,真正执行计算的算术逻辑单元(ALU)只占很小一部分。以Intel的x86处理器为例,一颗拥有24核心的高端CPU,其实际计算核心占比并不高。CPU的设计目标是让单个线程跑得尽可能快——这是延迟优化的思路。
GPU走的是完全不同的路线。图形渲染从诞生之初就是典型的"尴尬并行"问题:屏幕上的两百万个像素需要执行相同的着色计算,但彼此之间几乎不需要通信。既然每个像素的计算逻辑相同,何必为每个计算单元配备复杂的控制电路?
GPU的架构图揭示了这一设计哲学的极端化:一颗现代GPU拥有数千到上万个简单的计算核心,每个核心都是精简的算术单元,几乎没有分支预测,缓存也相当有限。以H100为例,它拥有超过16000个FP32 CUDA核心。这些核心虽然单个计算能力远不如CPU核心,但胜在数量庞大——就像用一万辆小货车运输货物,虽然每辆车装载量有限,但总运力远超一架大型运输机。
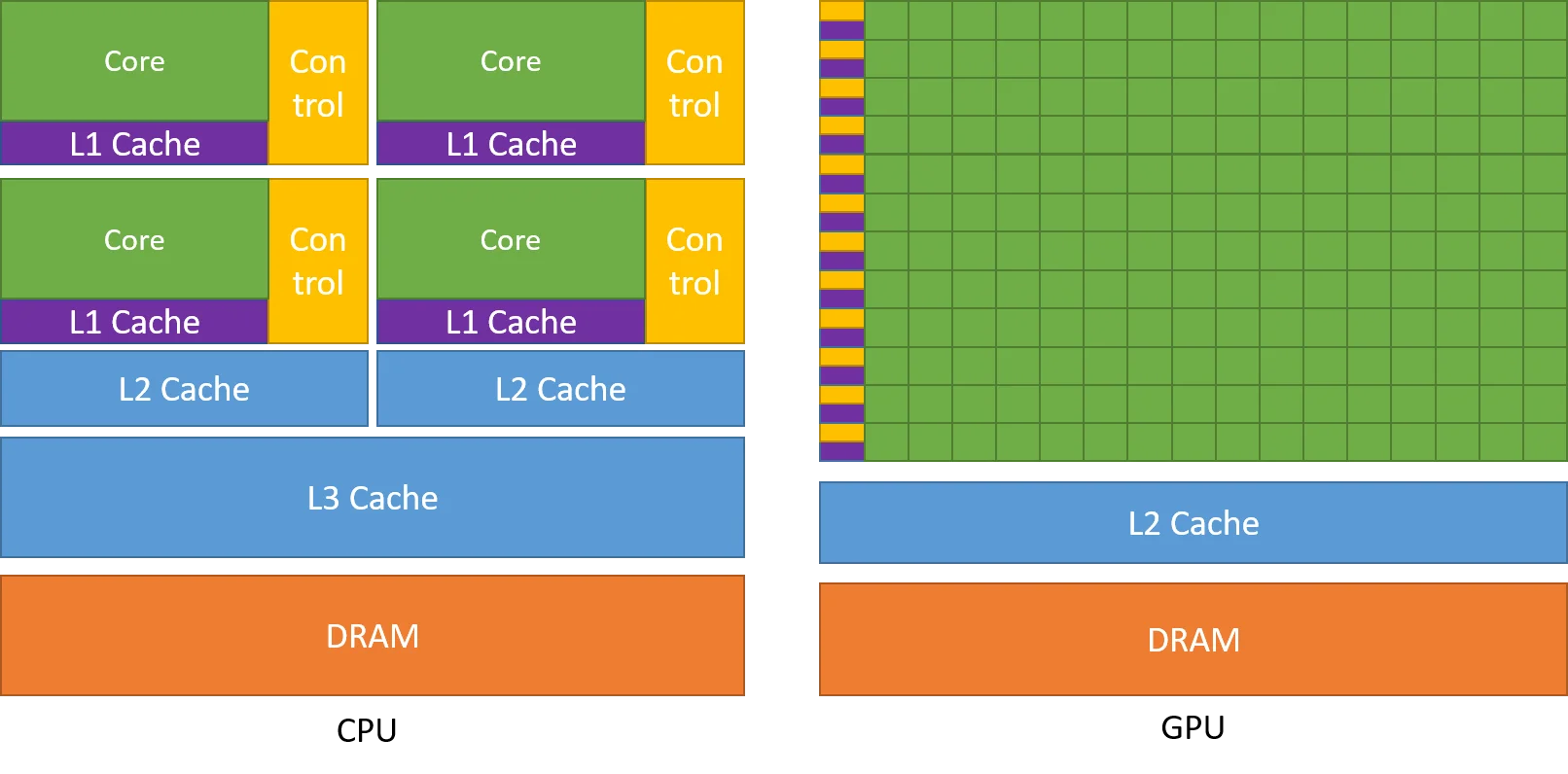
这张来自NVIDIA官方文档的示意图清晰地展示了CPU与GPU在晶体管分配上的根本差异。GPU将更多晶体管用于数据处理(绿色区域),而CPU则将大量资源投入缓存和流控制(橙色区域)。
深度学习的计算本质
理解GPU为何适合深度学习,首先要理解深度学习的计算本质。神经网络的训练过程可以简化为三个核心操作:前向传播计算预测值、反向传播计算梯度、参数更新。无论多么复杂的网络架构,这三个步骤最终都归结为大规模的矩阵运算。
以一个简单的全连接层为例。假设输入向量 $\mathbf{x}$ 有4096个元素,权重矩阵 $\mathbf{W}$ 是 $4096 \times 4096$ 的方阵,输出向量 $\mathbf{y} = \mathbf{W}\mathbf{x}$。这个矩阵乘法需要 $4096 \times 4096 \approx 1600$ 万次乘加运算。一个深度网络可能包含数百层,每层都是类似的矩阵运算,训练一次迭代可能需要数十亿次浮点运算。
关键洞察在于:矩阵乘法天然适合并行。计算输出向量 $\mathbf{y}$ 的第 $i$ 个元素时,只需要权重矩阵的第 $i$ 行与输入向量做点积。这些点积运算相互独立,完全可以同时进行。这正是GPU擅长的"尴尬并行"模式。
更深入地看,深度学习训练的计算强度可以用算术强度(Arithmetic Intensity)来衡量,即每字节数据对应的浮点运算次数。对于典型的Transformer模型,算术强度大约在50到500 FLOPs/Byte之间。这意味着GPU需要在每个内存访问周期内执行足够多的计算,才能充分利用其计算能力。
SIMT:让并行变得实用
GPU如何管理数千个核心同时工作?答案在于SIMT(Single Instruction, Multiple Threads)执行模型,这是NVIDIA在2006年推出CUDA时确立的核心创新。
SIMT的核心概念是warp——32个线程组成的执行单位。同一个warp中的所有线程在同一时刻执行完全相同的指令,但各自操作不同的数据。这种设计大幅简化了控制逻辑:不需要为每个线程维护独立的指令取指单元,只需要一套指令发射电路,就能驱动32个计算单元。
想象一个简化版的矩阵乘法场景。假设要计算 $\mathbf{C} = \mathbf{A} \times \mathbf{B}$,其中 $\mathbf{A}$、$\mathbf{B}$ 都是 $32 \times 32$ 的矩阵。在GPU上,可以启动一个warp,让第 $i$ 个线程计算输出矩阵第 $i$ 行的所有元素。每个线程执行相同的指令序列——加载数据、执行乘法、累加结果——但各自处理不同的数据片段。
warp机制带来了一个关键的权衡:分支分歧。当warp中的线程遇到条件分支时,比如if-else语句,不同线程可能选择不同的执行路径。由于所有线程必须执行相同指令,GPU不得不串行执行两个分支:先让选择if的线程执行,其他线程等待;再让选择else的线程执行,前者等待。这会导致性能下降。
幸运的是,深度学习中的分支分歧问题并不严重。神经网络的计算主要是矩阵运算,几乎没有复杂的条件分支。ReLU激活函数虽然在数学上涉及条件判断($\max(0, x)$),但在GPU上通常被编译为单个max指令,不存在分歧问题。
内存带宽:真正的瓶颈
深入理解GPU深度学习性能,会发现一个反直觉的现象:限制GPU性能的往往不是计算能力,而是内存带宽。
Tensor Core是现代GPU中专门加速矩阵运算的硬件单元。以H100为例,其FP16 Tensor Core的峰值算力达到1000 TFLOPS(使用稀疏优化可达2000 TFLOPS)。这意味着每秒能执行千万亿次浮点运算。但Tensor Core需要持续的数据供给才能发挥全部算力。
计算一下理论带宽需求。假设每次浮点运算需要读取两个操作数、写入一个结果,那么1 TFLOPS的算力需要3 TB/s的内存带宽才能充分供给。H100的Tensor Core算力是1000 TFLOPS,理论带宽需求高达3000 TB/s——这远超任何内存技术的极限。
现实情况是,H100配备的HBM3内存提供约3.35 TB/s的带宽。这就是为什么在实际训练中,Tensor Core的利用率通常只有45%到65%——大部分时间它们在等待数据从内存加载。
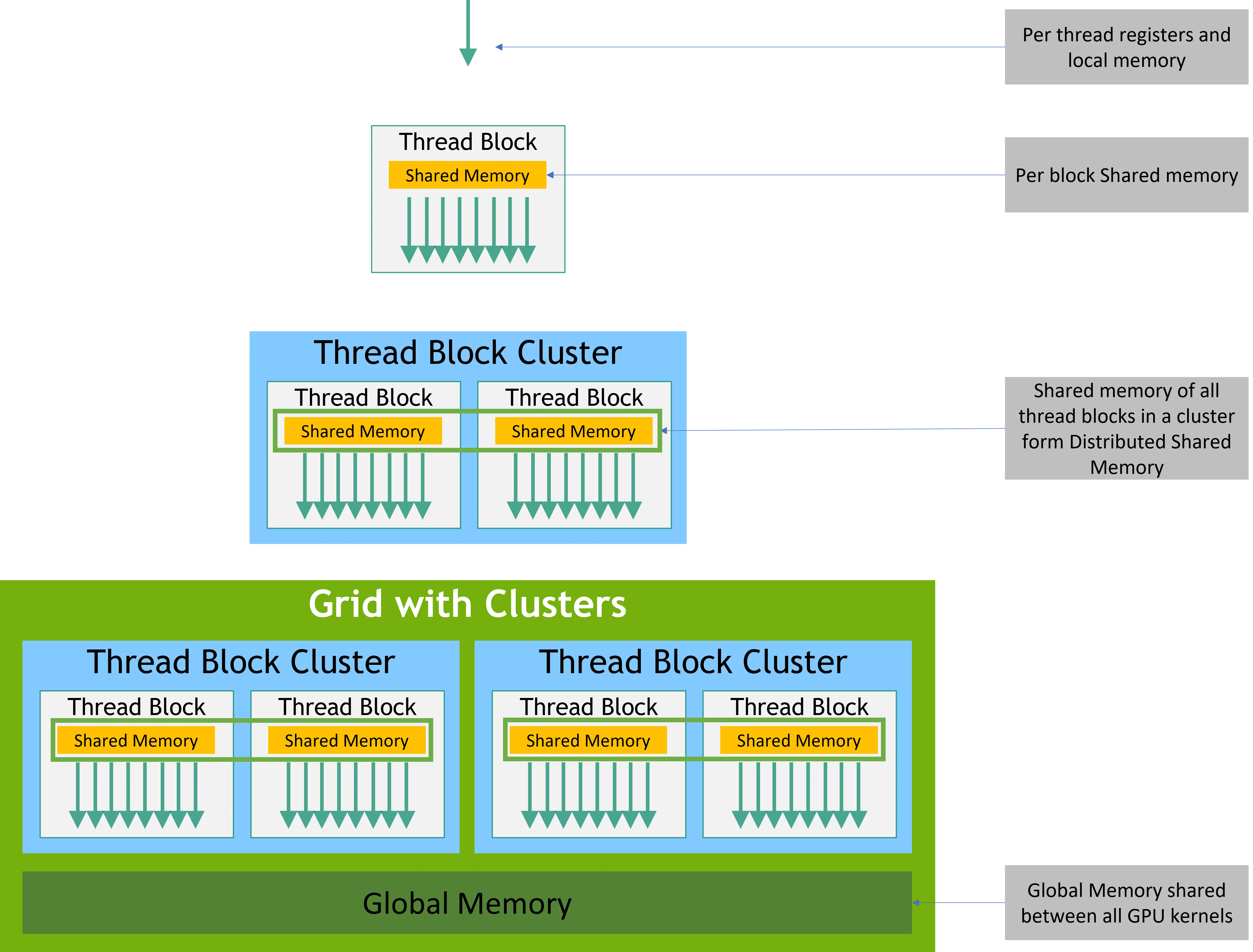
这张图展示了GPU的内存层次结构。从最快的寄存器到最慢的全局内存,速度和容量呈反比关系。高效的深度学习计算依赖于在内存层次间合理组织数据访问。
GPU通过多级内存层次缓解带宽瓶颈。H100的每个SM(Streaming Multiprocessor)拥有256KB的共享内存/L1缓存,全局还有50MB的L2缓存。聪明的算法会将频繁访问的数据保留在这些高速缓存中,减少对全局内存的访问。经典的矩阵乘法优化就是将大矩阵分块(tiling),让每个小块在共享内存中完成计算后再写回全局内存。
与CPU相比,GPU的内存带宽优势极为显著。高端桌面CPU配备DDR5内存,带宽约60-100 GB/s。H100的3.35 TB/s带宽是CPU的30倍以上。这种差异源于两个设计选择:更宽的总线和更快的内存颗粒。H100使用HBM3内存,通过3D堆叠技术实现了极宽的总线(每个堆栈1024位)和极高的数据传输率。
Tensor Core:为深度学习量身定制的硬件
2017年,NVIDIA在Volta架构中首次引入Tensor Core,这是GPU深度学习发展史上的里程碑。Tensor Core是专门执行矩阵乘累加(MMA,Matrix Multiply-Accumulate)运算的硬件单元,能够在单个时钟周期内完成一个小型矩阵乘法。
以A100的Tensor Core为例,它可以在一个周期内完成 $4 \times 4 \times 4$ 的矩阵乘累加操作:计算 $\mathbf{D} = \mathbf{A} \times \mathbf{B} + \mathbf{C}$,其中 $\mathbf{A}$、$\mathbf{B}$、$\mathbf{C}$、$\mathbf{D}$ 都是 $4 \times 4$ 矩阵。这相当于在单个周期内完成64次乘法和64次加法。
H100的第四代Tensor Core进一步提升了性能。在FP16精度下,每个SM的Tensor Core吞吐量是A100的两倍;在使用新的FP8精度时,吞吐量再翻倍。这意味着H100在FP8精度下的峰值算力可达4000 TFLOPS(使用稀疏优化)。
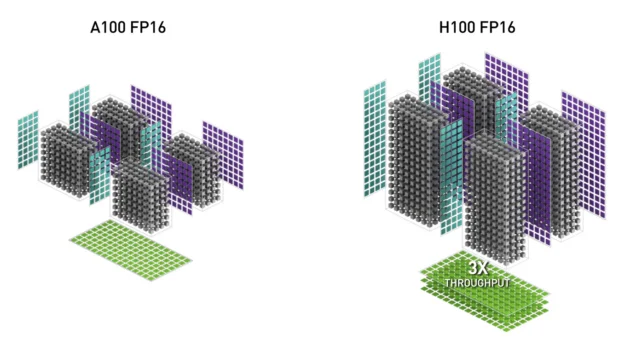
图片来源: NVIDIA Developer Blog
这张对比图展示了H100与A100在FP16 Tensor Core上的性能差异。H100的FP16 Tensor Core吞吐量达到A100的三倍。
FP8精度是Hopper架构引入的重要创新。它定义了两种格式:E4M3(4位指数,3位尾数)和E5M2(5位指数,2位尾数)。相比FP16,FP8将存储需求减半、计算吞吐翻倍,同时通过精心设计的格式保持足够的数值范围和精度。配合Transformer Engine自动选择FP8和FP16精度,训练大语言模型的效率可提升数倍。
从图形渲染到通用计算
GPU并非生来就是深度学习的利器。它的演化历程反映了计算范式的历史性转变。
最早的GPU是纯粹的图形渲染引擎,硬件逻辑固定,只能执行特定的图形操作。1999年NVIDIA提出"GPU"这个术语时,它指的就是GeForce 256这样的固定功能图形处理器。
转折点出现在可编程着色器的引入。2001年,GeForce 3支持顶点着色器和像素着色器,程序员开始能够编写自定义的图形处理程序。研究者很快意识到,如果能让GPU执行非图形的计算,它的并行能力将带来巨大加速。这就是GPGPU(General-Purpose computing on GPU)时代的开始。
早期的GPGPU编程极其痛苦。研究者必须把科学计算问题伪装成图形渲染问题,数据被编码为纹理图像,计算结果作为像素颜色读出。这种方式效率低下且容易出错。
2006年,NVIDIA推出CUDA(Compute Unified Device Architecture),彻底改变了局面。CUDA允许程序员用类似C语言的语法直接编写GPU程序,无需了解图形API。更重要的是,G80架构引入了统一着色器模型,所有计算单元可以执行相同类型的程序,不再区分顶点和像素处理。
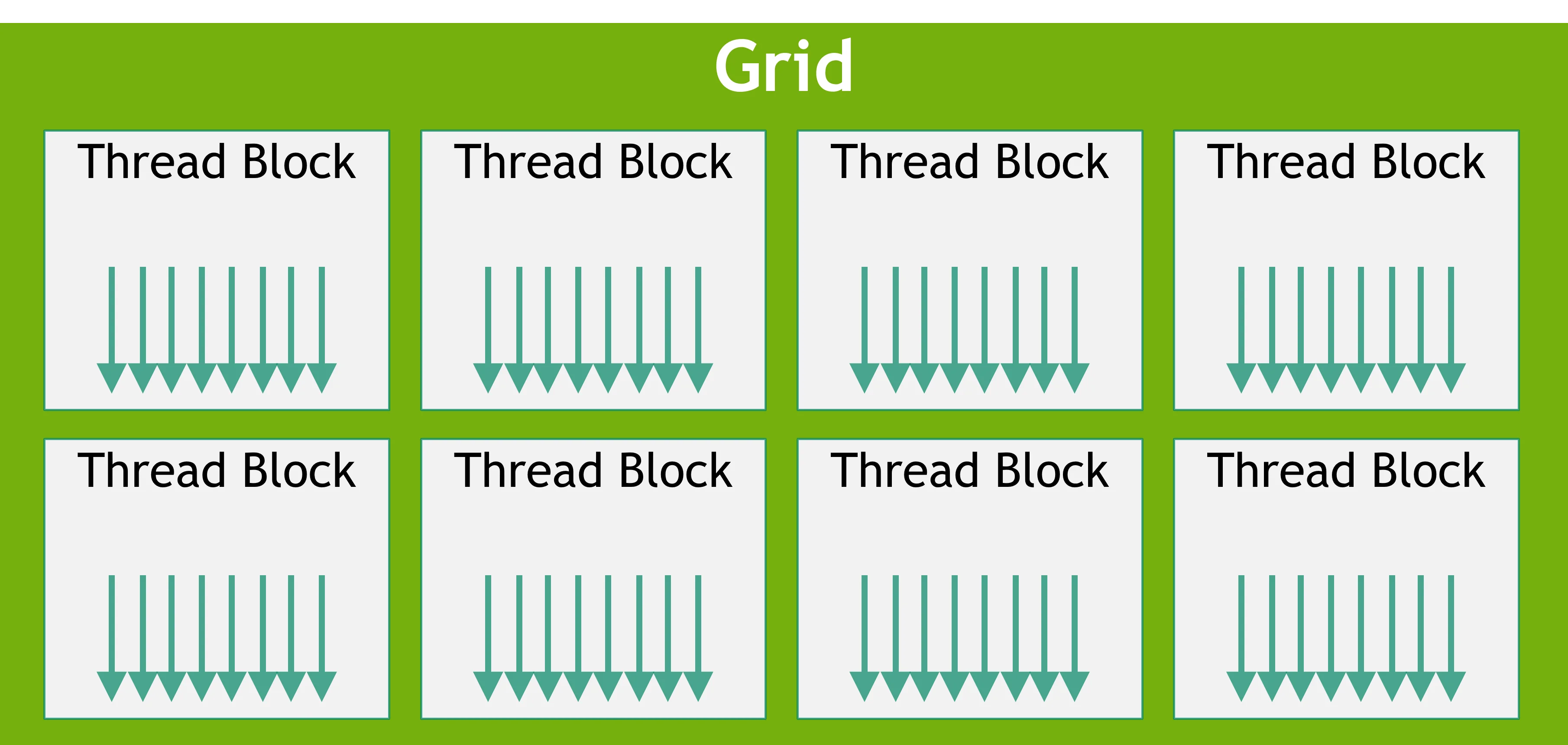
这张图展示了CUDA的线程层次结构:Grid包含多个Block,Block包含多个Thread。这种层次化的组织方式使得程序能够自然地映射到GPU硬件架构上。
CUDA的成功不仅在于技术上的创新,更在于生态系统的构建。NVIDIA投入大量资源开发cuBLAS、cuDNN等基础库,让深度学习框架能够方便地调用GPU算力。当AlexNet在2012年证明GPU训练的巨大优势时,CUDA已经是一个相对成熟的平台。
架构演进的二十年
从G80到今天的Blackwell,GPU架构经历了多次重大迭代。每一代都在计算能力、内存带宽、编程灵活性上取得突破。
Tesla/G80 (2006):首个统一着色器架构,引入CUDA。拥有128个处理器核心,峰值算力约0.5 TFLOPS。
Fermi (2010):首次支持ECC内存和双精度浮点,将GPU带入高性能计算领域。引入了真正的缓存层次结构。
Kepler (2012):引入动态并行,允许GPU内核启动新内核。能耗效率大幅提升。
Maxwell (2014):大幅优化能耗效率,引入统一内存简化编程。
Pascal (2016):首次采用HBM2内存,带宽达到720 GB/s,是前代的两倍。这是第一个真正意义上的AI训练GPU(P100)。
Volta (2017):引入Tensor Core,深度学习性能飞跃。V100的Tensor Core FP16算力达到125 TFLOPS。
Ampere (2020):第三代Tensor Core,支持稀疏矩阵加速。A100的Tensor Core算力达到312 TFLOPS,引入了多实例GPU(MIG)技术。
Hopper (2022):第四代Tensor Core,支持FP8精度。H100的FP8 Tensor Core算力达到2000 TFLOPS,引入了Transformer Engine和线程块集群。
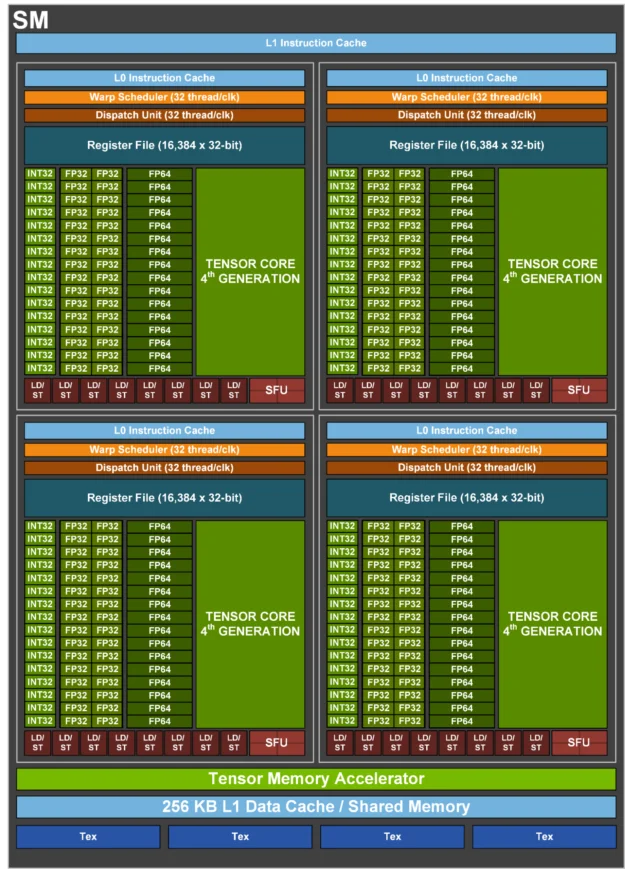
图片来源: NVIDIA Developer Blog
这张图详细展示了H100 SM的内部结构,包括CUDA核心、Tensor Core、L1缓存/共享内存等关键组件。
值得注意的是,GPU的内存带宽增长速度远超算力增长。从P100的720 GB/s到H100的3.35 TB/s,带宽增长了约4.7倍。这是因为深度学习训练的瓶颈从计算转向了内存访问,架构演进的重点也随之调整。
能效与成本的权衡
GPU在深度学习上的优势不仅是速度,还有能效。根据公开数据,现代GPU在深度学习训练中的能效比约为CPU的2-4倍。这意味着完成相同的训练任务,GPU消耗的电力更少。
能效优势源于GPU的并行架构。CPU为了追求单线程性能,采用了复杂的超标量、乱序执行、分支预测等技术,这些技术的开销很高。GPU的SIMT模型虽然单线程性能较低,但通过大规模并行弥补了差距,同时避免了复杂的控制开销。
另一个重要因素是数据移动的能耗。在芯片上,移动数据比计算消耗更多的能量。CPU的多级缓存虽然提高了命中率,但数据在不同缓存层级间移动的开销可观。GPU通过共享内存和warp级同步减少了数据移动,能效更高。
当然,GPU并非在所有场景下都优于CPU。对于串行性强、分支复杂的任务,CPU仍然是更好的选择。数据库查询、Web服务、操作系统内核等负载在CPU上执行效率更高。深度学习的特殊性——大规模矩阵运算、极高的并行度、相对简单的控制流——恰好匹配GPU的架构特点。
展望:专用化还是通用化
GPU在深度学习领域的成功引发了关于未来计算架构的思考:未来的AI计算会继续依赖通用GPU,还是转向更专用的加速器?
TPU(Tensor Processing Unit)提供了一个参照。TPU是专门为神经网络推理设计的芯片,采用大规模的脉动阵列执行矩阵运算。在特定负载下,TPU的效率高于GPU,但灵活性较低。
GPU的应对策略是不断增强专用加速单元,同时保持通用计算能力。Tensor Core就是这样一种"混合"设计:它专门优化矩阵运算,但仍然在GPU的统一架构下运行。Hopper架构引入的Transformer Engine更是将硬件与软件紧密耦合,自动在不同精度间切换以最大化性能。
未来的GPU可能会进一步集成专用加速器。神经网络训练中的梯度计算、参数更新、通信等步骤都可能获得硬件加速。但GPU的核心优势——大规模并行、灵活的编程模型、成熟的生态系统——将继续保持其作为深度学习主力的地位。
结语
回顾GPU与深度学习的结合,这并非偶然,而是架构设计与计算需求的深层契合。CPU追求单线程极致性能的设计,使它成为通用计算的王者;GPU追求吞吐量的架构,则让它在并行计算领域独占鳌头。深度学习恰好是一种高度并行的计算负载,其核心操作——矩阵运算——天然适合GPU的SIMT执行模型。
从AlexNet到GPT-4,从V100到H100,GPU见证了深度学习从实验室走向产业化的全过程。在这个过程中,GPU不仅是工具,更是推动者。Tensor Core的引入加速了模型训练,HBM内存的采用缓解了带宽瓶颈,CUDA生态降低了开发门槛。这些技术和生态的积累,使得GPU成为深度学习不可替代的基础设施。
理解GPU为什么适合深度学习,有助于我们更好地利用这一强大的计算平台,也有助于我们思考下一代计算架构的方向。当深度学习模型的规模持续增长,当新的计算需求不断涌现,计算架构的创新将继续演进。
参考资料
- Nickolls, J., Buck, I., Garland, M., & Skadron, K. (2008). Scalable Parallel Programming with CUDA. ACM Queue, 6(2), 40-53.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS.
- NVIDIA. (2022). NVIDIA Hopper Architecture In-Depth. NVIDIA Technical Blog.
- Dettmers, T. (2023). Which GPU for Deep Learning? Tim Dettmers Blog.
- NVIDIA. (2024). CUDA C++ Programming Guide.
- Jia, Z. (2022). Dissecting the NVIDIA Hopper Architecture. Microprocessors and Microsystems.
- Jouppi, N. P., et al. (2017). In-Datacenter Performance Analysis of a Tensor Processing Unit. ISCA.
- Williams, S., Waterman, A., & Patterson, D. (2009). Roofline: An Insightful Visual Performance Model for Multicore Architectures. CACM.
- NVIDIA. (2020). NVIDIA A100 Tensor Core GPU Architecture Whitepaper.
- Fowers, J., et al. (2018). A Configurable Cloud-Scale DNN Processor for Real-Time AI. ISCA.