2023年,一个令人震惊的数据在AI基础设施领域引发了震动:现有的大模型推理系统正在浪费60-80%的GPU计算资源。这些昂贵的计算硬件并非因模型不够先进而闲置,而是被一种看不见的"幽灵"吞噬——批处理策略的低效。
当用户向ChatGPT发送问题时,背后发生的事情远比想象的复杂。一个看似简单的对话,可能需要数千次GPU运算。而问题在于:当多个用户同时提问时,传统的批处理方式要求所有请求必须等待最慢的那个完成。这就像公交车必须等所有座位坐满才肯发车——即使车上已经有人等了半小时。
这种低效的根源可以追溯到2022年OSDI会议上发表的一篇论文。来自首尔大学和FriendliAI的研究团队发现,现有推理系统的调度粒度根本不适用于自回归生成模型。他们提出的解决方案——迭代级调度,后来被称为连续批处理(Continuous Batching),彻底改变了LLM推理的游戏规则。
大模型推理的特殊性:为什么传统批处理会失灵
要理解连续批处理的价值,首先需要理解大模型推理与传统深度学习推理的根本区别。
传统的深度学习模型(如图像分类的ResNet)处理一次请求只需要一次前向传播。输入一张图片,模型给出分类结果,任务完成。批处理在这种情况下非常直观:将多张图片打包成一个批次,GPU并行处理,效率拉满。
但大语言模型完全不同。它们采用自回归生成方式:每次前向传播只产生一个token,然后这个token又成为下一次生成的输入。用户问"法国首都是哪里",模型需要依次生成"巴"、“黎"两个token,每个token都需要一次完整的模型前向传播。
更关键的是,LLM推理分为两个截然不同的阶段:
Prefill阶段(预填充):模型处理完整的输入提示词,计算所有输入token的键值对(Key-Value pairs),并生成第一个输出token。这个阶段是一个高度并行的矩阵-矩阵运算,能够充分利用GPU的计算能力。
Decode阶段(解码):模型逐个生成后续token。每生成一个新token,都需要与之前所有token的KV缓存进行注意力计算。这是一个内存带宽受限的操作——数据传输速度远比计算速度更关键。
这种两阶段特性带来了一个棘手问题:不同用户的请求生成速度截然不同。有人问"1+1=?",模型可能两个token就结束;有人要求"详细解释量子力学”,可能需要数百个token。当这些请求被放入同一个批次时,问题就出现了。
静态批处理的困境:GPU上的"等车人"
传统批处理策略假设批次中的所有请求会同时完成。在图像分类任务中,这个假设成立——所有请求的处理时间相同。但在LLM推理中,这个假设完全不成立。
假设批次中有4个请求:
- 请求A需要生成5个token
- 请求B需要生成20个token
- 请求C需要生成3个token
- 请求D需要生成50个token
在静态批处理下,当请求A在第5次迭代完成后,它不能立即返回给用户。它必须"坐等"请求D完成全部50次迭代。这45次迭代的计算资源中,请求A对应的GPU核心实际上在执行空操作——虽然还在跑,但产出的token毫无意义。

图中白色方块代表已结束但仍在等待的请求——这正是GPU资源的浪费。研究表明,在实际工作负载下,这种浪费可能高达60%甚至更多。
更糟糕的是,当一个新请求到达时,它必须等待当前批次中的所有请求完成才能开始处理。即使批次中只有一个长请求在拖后腿,新来的短请求也只能干等。这就像公交车上的乘客必须等最后一波人全部上车才能出发——而那波人可能还在几公里外慢悠悠地走。
ORCA的突破:把调度粒度从"请求"降到"迭代"
2022年OSDI会议上,ORCA论文提出了一个根本性的创新:迭代级调度(Iteration-level Scheduling)。
核心思想非常直观:既然每次迭代只生成一个token,为什么不把调度粒度从"处理完整个请求"降到"完成一次迭代"?
这意味着:
- 每次迭代结束后,调度器检查是否有请求完成
- 完成的请求立即从批次中移除,结果返回给用户
- 新到达的请求可以立即加入批次
sequenceDiagram
participant S as Scheduler
participant E as Engine
participant R as Request Pool
loop 每次迭代
S->>R: 选择请求组成批次
S->>E: 执行一次迭代
E->>S: 返回生成的token
S->>S: 检查是否有请求完成
Note over S: 完成的请求立即返回
Note over S: 新请求可加入下一批次
end
论文中有一个形象的描述:在传统调度下,调度器与执行引擎只在"开始处理一个批次"和"批次完成"两个时刻交互。而在迭代级调度下,调度器与执行引擎在每次迭代后都进行交互,能够实时调整批次组成。
但这带来了一个技术挑战:当批次中的请求处于不同的生成阶段时,如何进行批处理?
选择性批处理:解决Attention的特殊性
LLM的Transformer层包含多种操作,其中Attention操作最为特殊。它需要访问之前所有token的KV缓存,而不同请求的已生成token数量不同,导致Attention操作的输入形状各异。
传统批处理要求批次中所有请求的输入形状相同。但当请求A处于第10个token、请求B处于第50个token、新加入的请求C还在prefill阶段时,它们的Attention输入形状完全不同——这怎么批处理?
ORCA提出了选择性批处理(Selective Batching):
观察发现,Transformer层中的操作可以分为两类:
- 可批处理操作:如LayerNorm、线性变换、GeLU等,这些操作是逐token进行的,不需要token之间的交互
- 不可批处理操作:主要是Attention操作,需要访问所有历史token
对于可批处理操作,可以将所有请求的token拼接成一个长序列,统一处理。对于Attention操作,则拆分成多个独立的Attention计算,每个请求单独计算,最后再合并结果。
关键洞察是:Attention操作不涉及模型参数。因此不对其进行批处理不会损失"参数重用"的好处——因为本来就没有参数需要重用。
这种设计使得调度器可以在同一批次中混合处理:
- 正在prefill阶段的新请求(处理全部输入token)
- 正在decode阶段的旧请求(生成下一个token)
从理论到实践:连续批处理的完整工作流程
将上述技术整合起来,就形成了完整的连续批处理系统。以vLLM为代表的现代推理框架采用如下工作流程:
调度器的核心循环:
while True:
# 1. 从请求池选择要处理的请求
batch = select_requests(request_pool, max_batch_size, memory_budget)
# 2. 执行一次迭代
output_tokens = engine.run_one_iteration(batch)
# 3. 更新请求状态
for request, token in zip(batch, output_tokens):
request.append_token(token)
if token == EOS or len(request) >= max_tokens:
request_pool.remove(request)
return_result(request)
# 4. 接受新到达的请求
accept_new_requests()
Ragged Batching消除填充浪费:
传统的批处理需要将所有请求填充到相同长度。但在连续批处理中,采用了一种更聪明的方式:将批次维度消除,用注意力掩码控制token间的交互。
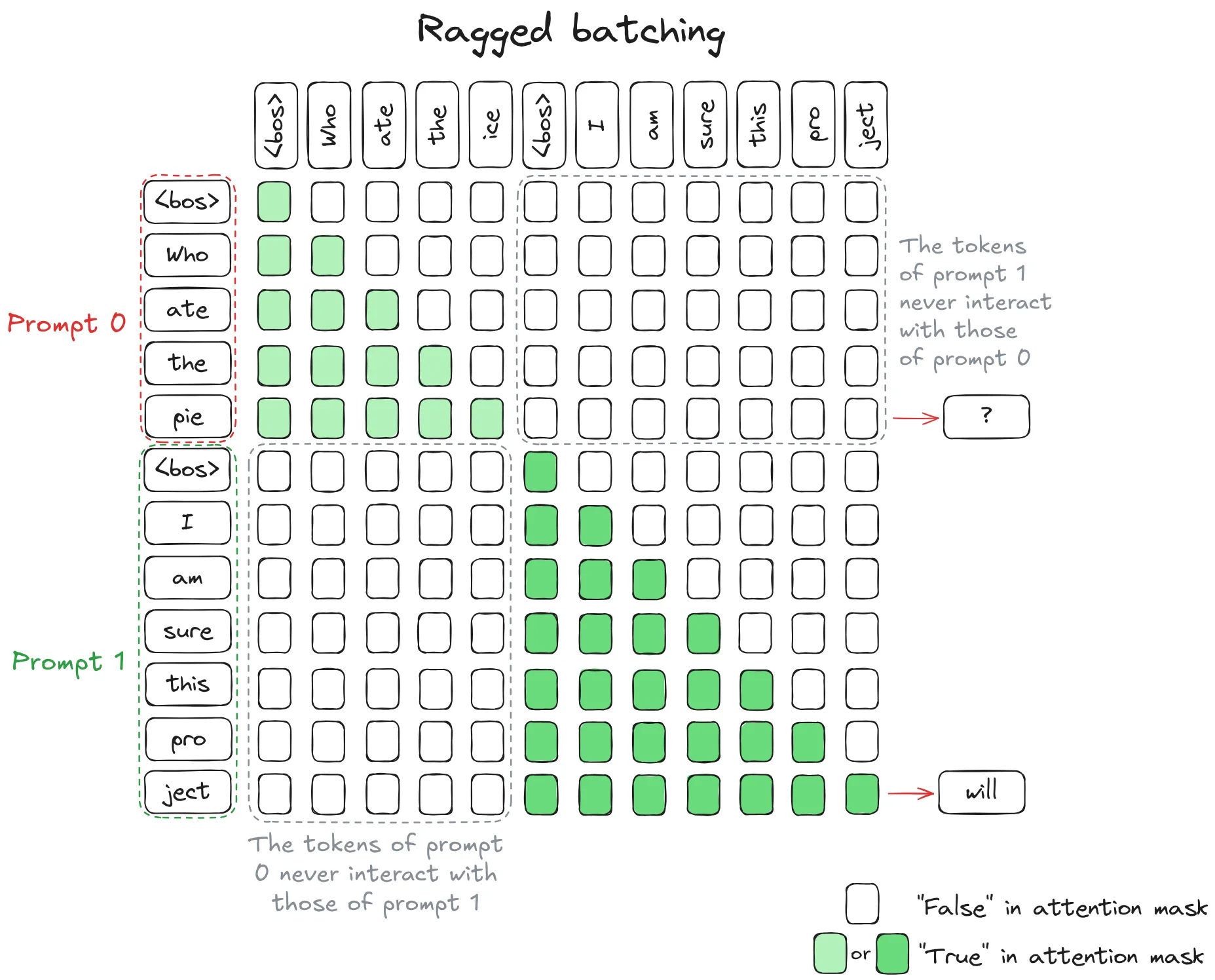
图中,不同请求的token被拼接在一起,通过注意力掩码确保:
- 同一请求内的token可以相互attention
- 不同请求的token完全隔离
这种方式完全消除了填充token的需求,无论请求长度如何差异,都不会浪费计算资源。
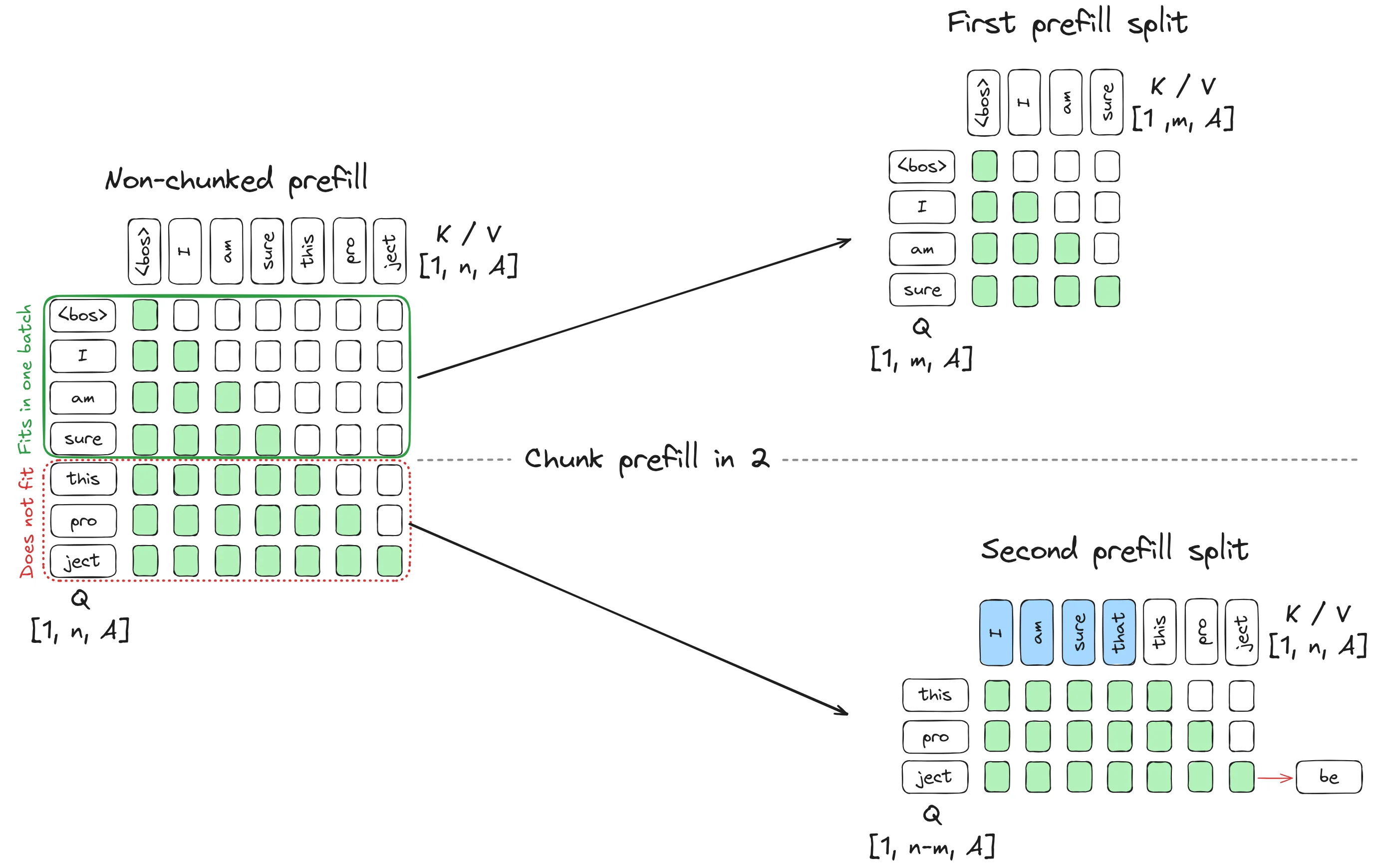
Chunked Prefill:解决内存瓶颈
当输入提示词非常长时(比如将整个代码库作为上下文),prefill阶段可能需要处理数千个token。这不仅需要大量GPU内存,还会导致长时间的计算阻塞。
Chunked Prefill将长prefill分割成固定大小的块,每块只处理少量token。这样可以:
- 控制内存峰值使用
- 将prefill与decode混合执行
vLLM的调度策略通常采用"decode优先"原则:优先处理decode阶段的请求,剩余的token预算用于prefill块。这确保了正在生成的请求不会被长prefill请求阻塞。
性能数据:数十倍的吞吐量提升
连续批处理带来的性能提升是惊人的。根据Anyscale的基准测试,在OPT-13B模型上:
| 框架 | 相对于静态批处理的吞吐量提升 |
|---|---|
| 静态批处理(Hugging Face Pipelines) | 1x(基准) |
| 优化的静态批处理(FasterTransformer) | 4x |
| 连续批处理(TGI) | 8x |
| 连续批处理 + PagedAttention(vLLM) | 23x |
关键观察:
- 连续批处理本身带来8x提升,主要来自消除"早完成请求的等待时间"
- PagedAttention结合连续批处理可达23x,因为连续批处理使动态内存分配成为可能
更重要的是,连续批处理不仅提升了吞吐量,还降低了延迟。因为新请求可以立即加入正在运行的批次,不需要等待整个批次完成。在测试中,连续批处理在各个延迟百分位上都有改善,包括P50、P90和P99延迟。
从ORCA到产业标准
ORCA论文发表后,连续批处理迅速成为行业标配:
- vLLM(UC Berkeley):将连续批处理与PagedAttention结合,成为最流行的开源推理框架
- TensorRT-LLM(NVIDIA):以"In-flight Batching"命名实现该技术
- TGI(Hugging Face):Text Generation Inference内置连续批处理
- SGLang:进一步优化调度策略
- LMDeploy:以"Persistent Batching"命名
有趣的是,这些框架虽然名称各异,核心原理都来自ORCA的迭代级调度思想。正如FriendliAI团队在LinkedIn上所说:“自从我们在ORCA(OSDI 2022)中开创连续批处理以来,认真思考批处理策略一直是推理系统设计的核心。”
连续批处理的代价与权衡
没有完美的解决方案,连续批处理也有其代价:
实现复杂度:相比静态批处理,连续批处理需要精细的内存管理、动态的注意力掩码生成、以及复杂的调度逻辑。vLLM的核心代码超过数万行,大部分都在处理这些复杂性。
CUDA Graph兼容性:CUDA Graph可以显著减少内核启动开销,但它要求计算图的形状固定。连续批处理的动态特性与这一优化存在冲突。现代框架通过精心设计,在保持动态性的同时尽量利用CUDA Graph。
Prefill与Decode的平衡:如果批次中prefill请求过多,会挤占decode请求的计算资源,导致生成延迟增加。反之,如果过于保守地限制prefill,又可能降低吞吐量。这需要根据具体工作负载调整调度策略。
技术演进的启示
连续批处理的成功揭示了一个深刻的技术洞察:对于新兴的工作负载,系统层面的优化往往比模型层面的优化更有价值。
在ORCA之前,很多人认为提升LLM推理效率的主要途径是量化、蒸馏、更高效的CUDA内核。但ORCA证明,仅仅是改变调度策略,就能带来数十倍的提升。这个提升幅度,可能需要模型层面多年的技术积累才能达到。
更重要的是,连续批处理与其他优化技术完全正交。它可以与量化结合,与Flash Attention结合,与PagedAttention结合——每一项优化都能叠加效果。
这也解释了为什么短短两年内,连续批处理从一篇学术论文变成了产业标准。它不是在"优化"现有系统,而是在重新定义问题本身。
参考文献:
- Yu, Gyeong-In, et al. “Orca: A Distributed Serving System for Transformer-Based Generative Models.” OSDI 2022.
- Kwon, Woosuk, et al. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” SOSP 2023.
- NVIDIA. “Mastering LLM Techniques: Inference Optimization.” NVIDIA Technical Blog, 2023.
- Anyscale. “Achieve 23x LLM Inference Throughput & Reduce p50 Latency.” 2023.
- Hugging Face. “Continuous batching from first principles.” 2025.
- Agrawal, Amey, et al. “SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills.” arXiv 2024.