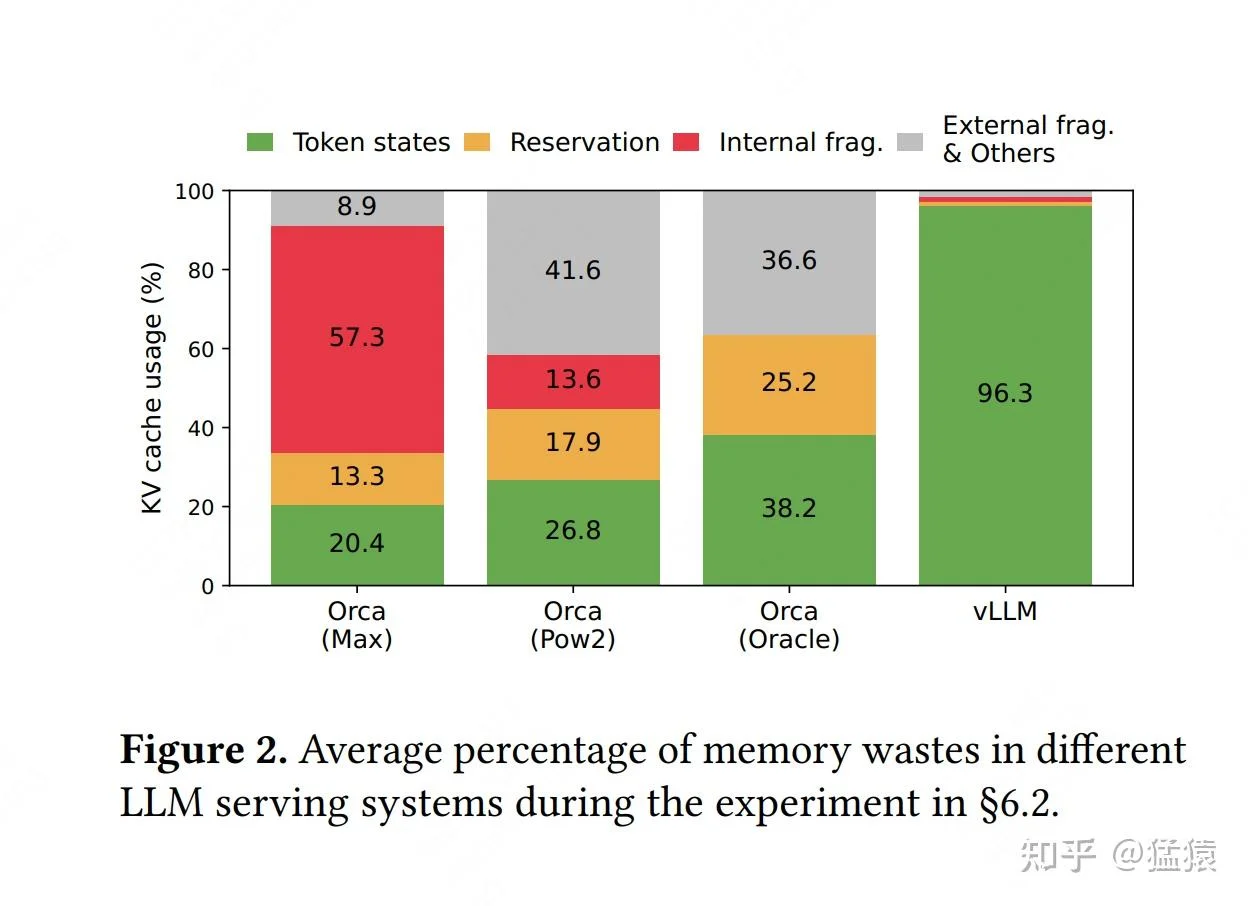
2023年,加州大学伯克利分校的研究团队发表了一篇论文,揭示了一个令人震惊的数据:现有的大模型推理系统正在浪费60-80%的GPU显存。这些昂贵的计算资源并非用于实际的模型计算,而是被一种看不见的"幽灵"吞噬——内存碎片。
仅仅一年后,基于这篇论文开发的vLLM框架已成为业界标配,被Google、Amazon、Microsoft等公司广泛采用。这项名为PagedAttention的技术,将推理吞吐量提升了2-4倍,而其核心思想竟源自五十多年前操作系统领域的一项经典发明——虚拟内存分页。
一个价值百万美元的问题:KV Cache为何如此"吃"显存
要理解内存碎片问题,首先需要理解大模型推理的两个阶段。
当用户向语言模型发送一条请求时,推理过程分为prefill(预填充) 和decode(生成) 两个阶段。在prefill阶段,模型处理完整的输入提示词(prompt),计算出每个token对应的key和value向量,并将它们缓存起来。这个缓存就是KV Cache——它的存在使得后续生成每个新token时,无需重新计算所有历史token的注意力表示。
KV Cache的大小与序列长度成正比。以LLaMA-13B模型为例,每个token需要约800KB的KV Cache存储空间。如果最大序列长度设为2048,单个请求的KV Cache就可能占用高达1.6GB显存。
问题在于:我们无法预知每个请求最终会生成多长的回复。一个简单的问答可能只生成几十个token,而一次复杂对话可能需要数千个token。传统推理框架采用的策略是:为每个请求预分配最大序列长度所需的连续显存空间。
这种"一刀切"的预分配策略导致了严重的内存浪费。研究团队识别出了三种类型的内存碎片:
内部碎片(Internal Fragmentation):请求A可能只需生成50个token,但系统却为其预留了2048个token的空间。那1998个未使用的槽位就是内部碎片。
预留碎片(Reservation Fragmentation):即使某个请求最终会用满预分配的空间,但在生成过程中,大部分时间那些"未来才会用到"的槽位都是空闲的。这些暂时空闲但已被占用的空间构成了预留碎片。
外部碎片(External Fragmentation):当多个请求并发处理时,每个请求都需要一块连续的显存。即使GPU上还有足够的总空闲空间,如果这些空间是分散的碎片,新请求也无法被处理。
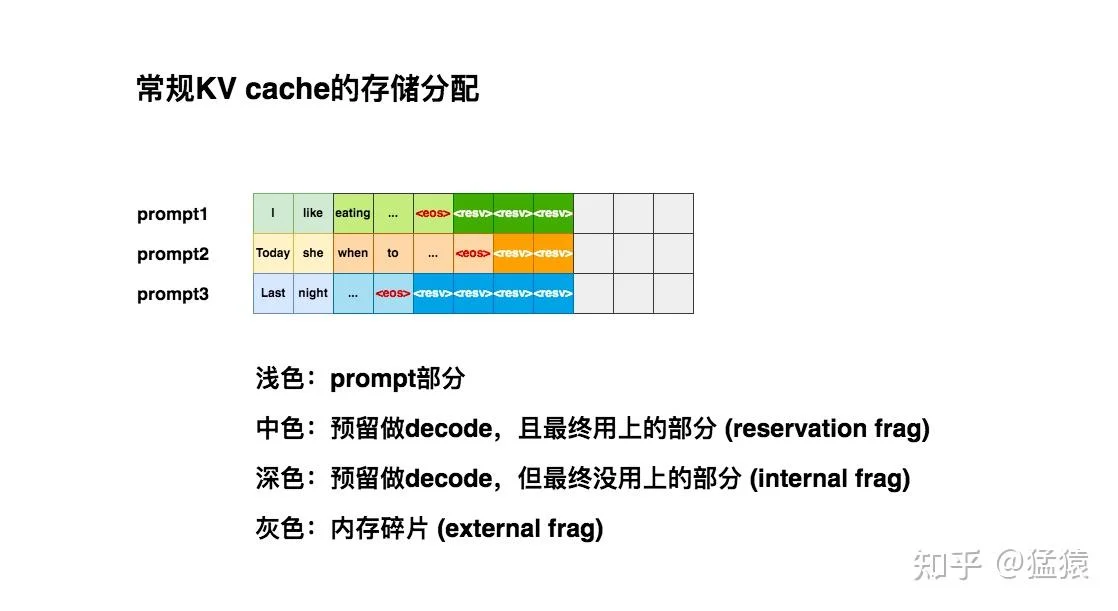
上图清晰地展示了传统分配方式的问题:浅色块是prompt已使用的空间,中色块是decode过程中逐步填充的空间,深色块是最终未被使用的内部碎片,而灰色块则是无法被新请求利用的外部碎片。尽管GPU上存在足够的空闲格子,但新请求prompt4却因无法找到连续的8个位置而被迫等待。
向操作系统取经:分页管理的智慧
面对这个问题,研究团队将目光投向了计算机系统领域一个看似毫不相关的概念——操作系统的虚拟内存管理。
在操作系统中,进程直接操作物理内存地址会带来严重问题:不同进程之间需要协调内存使用,耦合性极高。解决方案是引入虚拟内存:每个进程拥有独立的虚拟地址空间,由操作系统负责将虚拟地址映射到实际的物理地址。
早期的虚拟内存采用分段管理,为每个进程分配连续的物理内存块。这导致了与LLM推理相同的外部碎片问题:即使物理内存有足够的总空闲空间,也可能因为碎片化而无法装入新进程。
1961年,Manchester大学的Atlas计算机首次实现了分页管理。核心思想是将物理内存划分为固定大小的"页"(page),进程的代码和数据也按页划分。进程在虚拟地址空间中是连续的,但实际存储在物理内存中可以是不连续的——通过一张页表(page table)记录虚拟页到物理页的映射。
这个设计带来了两个关键优势:
- 消除外部碎片:所有页大小相同,物理内存分配不再需要找连续的大块空间
- 按需分配:进程不需要一次性加载全部内容,用到哪页就分配哪页
PagedAttention正是将这个经典思想应用到了KV Cache管理中。
Block Table:GPU上的"页表"
PagedAttention的核心设计是将KV Cache划分为固定大小的block(默认每个block存储16个token的KV数据),并为每个请求维护一张block table——这与操作系统的页表异曲同工。
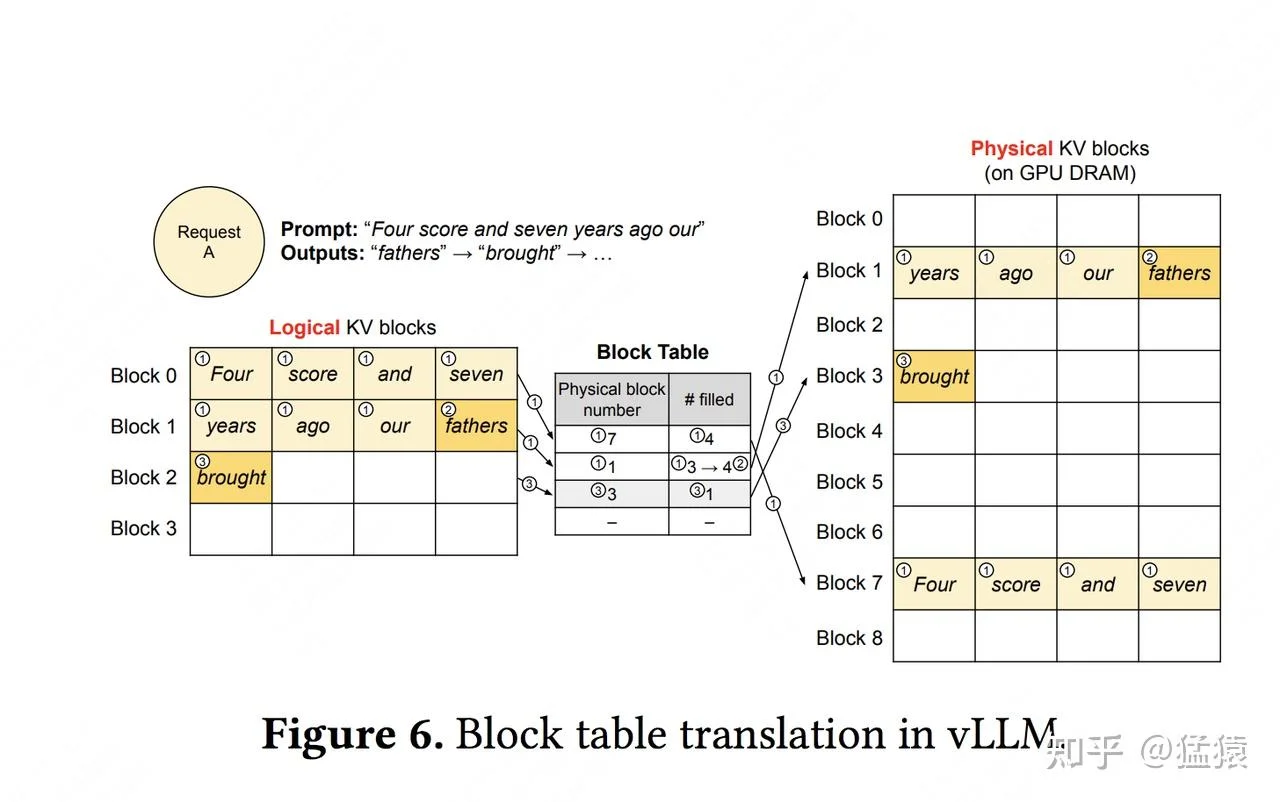
让我们通过一个具体例子来理解这套机制的运作流程。假设用户发送的prompt是"Four score and seven years ago our",共7个token。
Prefill阶段:系统将这7个token的KV数据分成两个逻辑块。Block 0存储前4个token,Block 1存储后3个token(第4个位置暂时空闲)。此时,block table记录了逻辑块到物理块的映射:逻辑块0→物理块7,逻辑块1→物理块1。
Decode阶段:当模型生成第一个新token “fathers"时,它被追加到逻辑块1的空闲位置。当逻辑块1填满后,系统新分配一个物理块(物理块3),同时更新block table:逻辑块2→物理块3。
关键在于:逻辑上,每个请求看到的是连续的KV Cache;物理上,这些数据可以散落在GPU显存的任何位置。 block table在运行时完成地址翻译,注意力计算内核(kernel)会自动从正确的物理位置读取数据。
这套机制带来的收益是巨大的:
- 内存浪费从60-80%降至4%以下:每个请求只分配实际需要的block
- 消除外部碎片:所有block大小相同,任何空闲block都可以被任何请求使用
- 支持内存共享:不同请求的block table可以指向相同的物理block
Memory Sharing:当多个请求共享同一份记忆
PagedAttention的block table设计带来了一个意外的红利:内存共享。这在以下场景中尤为有价值:
并行采样(Parallel Sampling)
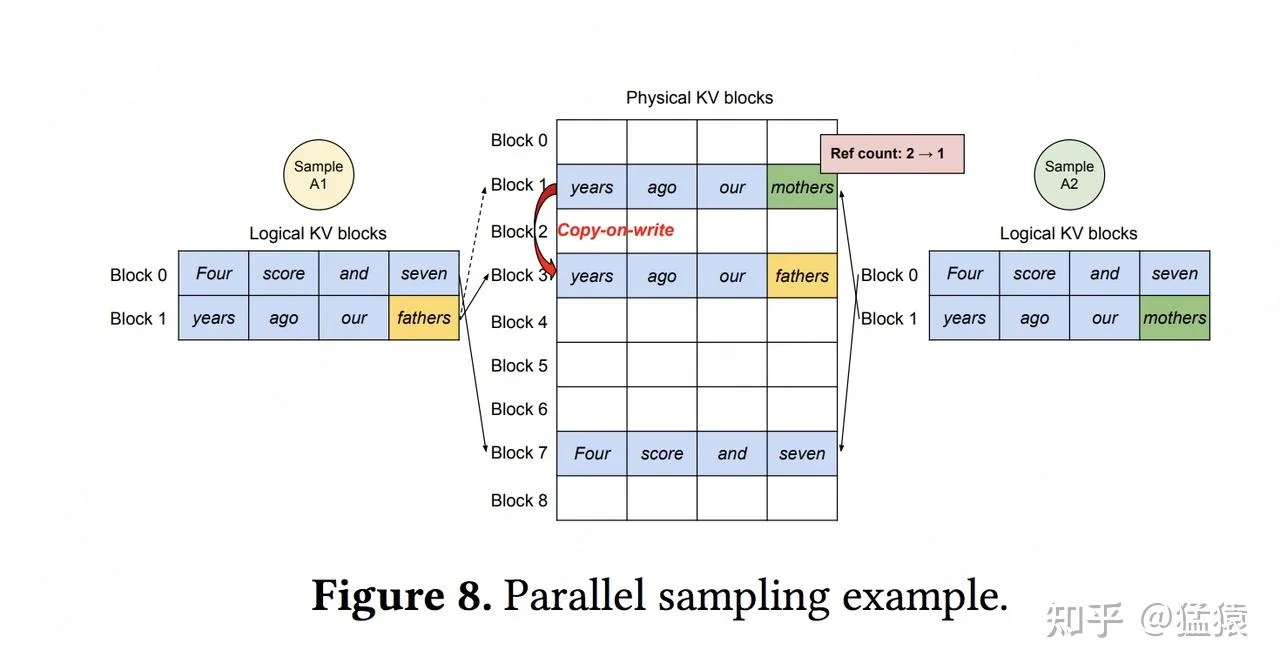
当用户希望模型对同一个prompt给出多种不同的回复时,传统系统需要为每个回复存储完整的KV Cache,其中prompt部分是完全重复的。
在PagedAttention中,所有这些请求可以共享prompt对应的物理block。只有当不同回复开始diverge(分道扬镳)时,才触发copy-on-write机制:将共享的block复制一份,各自独立修改。
Beam Search
在束搜索解码中,每一步都需要维护top-k个候选序列。这些候选序列往往共享大量前缀。PagedAttention允许这些序列通过block table共享前缀block,只有分叉点之后的block需要独立存储。
自动前缀缓存(Automatic Prefix Caching)
在聊天应用中,几乎所有请求都会共享相同的system prompt(如"你是一个有帮助的AI助手…")。vLLM通过哈希机制自动识别这些共享的前缀:当新请求到来时,系统计算每个block的哈希值(基于block内容和前缀哈希),如果发现相同的哈希值,就直接复用已有的物理block,无需重新计算prefill。
实验数据显示,对于长共享前缀场景,prefix caching可以将KV Cache内存使用降低70-90%。
性能跃升:从理论到实践
原始论文的基准测试结果令人印象深刻:
| 场景 | 相比FasterTransformer | 相比Orca |
|---|---|---|
| OPT-13B, 短序列 | 2.2x | 1.8x |
| OPT-13B, 长序列 | 4.0x | 3.2x |
| LLaMA-13B, Beam Search | 3.5x | 2.8x |
Anyscale团队的独立测试得出了类似的结论:在OPT-13B模型上,vLLM相比naive static batching实现了最高23倍的吞吐量提升,同时还将p50延迟降低了约40%。
性能提升的幅度随着序列长度增加而增大——这正是PagedAttention设计初衷的体现:长序列场景下,传统预分配策略的内存浪费最为严重。
调度与抢占:当显存不够时怎么办
动态分配策略带来了一个新问题:如果所有请求的KV Cache都在增长,最终显存不够了怎么办?
vLLM采用了FCFS(First-Come-First-Serve)调度策略配合抢占机制:
- 当显存不足时,优先保证先到达的请求完成
- 后到达的请求被抢占:其KV Cache被换出到CPU内存,等待显存释放后再换回GPU
抢占的实现有两种策略:
Swapping:将整个请求的KV Cache block换出到CPU内存。当GPU显存充足时,再换回来继续推理。这种方式保留了已计算的结果,但需要CPU-GPU数据传输开销。
Recomputation:直接丢弃被抢占请求的KV Cache,将其重新放入等待队列。当资源充足时,从头开始重新计算。这种方式省去了换入换出的开销,但需要重新计算prefill。
系统会根据请求的特性自动选择更优的策略。对于长prompt的请求,swapping更划算;对于短prompt的请求,recomputation可能更快。
技术权衡:没有完美方案
PagedAttention并非没有代价。其核心权衡在于:
优势:
- 接近零的内存碎片(<4%)
- 支持灵活的内存共享
- 更高的并发批处理能力
- 与continuous batching天然契合
代价:
- 需要维护block table的内存开销(通常很小)
- 注意力计算kernel需要处理非连续内存访问
- 换入换出带来的CPU-GPU通信开销(在显存紧张时)
在实践中,这些代价相比收益是值得的。vLLM已成为当前最流行的开源LLM推理框架之一,其设计理念也被TensorRT-LLM、SGLang等框架借鉴吸收。
从系统视角看AI优化
PagedAttention的成功揭示了一个重要趋势:大模型优化的战场已不限于模型架构本身。Flash Attention从硬件层级重新设计计算流程,PagedAttention从操作系统汲取内存管理智慧,投机解码则借鉴了CPU架构的投机执行思想。
这些跨领域的知识迁移,正在成为推动大模型落地的关键力量。当我们在讨论"AI基础设施"时,讨论的不仅是更大更强的GPU,更是如何将这些数十年来沉淀的系统设计智慧,应用到新一代计算范式中。
参考资料:
- Kwon, W., et al. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” SOSP 2023.
- Yu, G., et al. “Orca: A Distributed Serving System for Transformer-Based Generative Models.” OSDI 2022.
- vLLM Documentation: PagedAttention Design
- Anyscale Blog: “Achieve 23x LLM Inference Throughput & Reduce p50 Latency”