一个客服机器人在处理多轮对话时,每次都需要重新"阅读"完整的对话历史。当对话进行到第 10 轮,模型需要处理的上下文已经膨胀到数千 token——这意味着每一轮对话都要重复计算这些相同的文本。在大规模生产环境中,这种冗余计算吞噬着昂贵的 GPU 资源,导致响应延迟累积攀升。
这不是一个假设的场景,而是大模型推理系统中普遍存在的真实痛点。Prefix Caching(前缀缓存)技术的出现,让这个问题有了近乎完美的解决方案:当多个请求共享相同的文本前缀时,只需计算一次,后续请求可以直接复用。
从 KV Cache 到 Prefix Cache:跨请求的智慧复用
要理解 Prefix Caching 的价值,必须先理解 KV Cache 在 Transformer 推理中的角色。
Prefill 与 Decode:推理的两个阶段
大模型的推理过程分为两个截然不同的阶段。Prefill(预填充)阶段处理完整的输入序列,计算每个 token 的 Key 和 Value 向量,这些向量被存储在 KV Cache 中。这个阶段的计算量与输入长度的平方成正比,是整个推理过程中计算最密集的部分。
Decode(解码)阶段则逐个生成输出 token。每生成一个新 token,模型只需要计算该 token 对之前所有 token 的注意力,已有的 KV Cache 可以直接复用。这就是为什么生成阶段的显存占用会线性增长——每个新 token 都需要追加其 KV 向量。
Prefill: 输入长度 L → O(L²) 计算量,生成完整 KV Cache
Decode: 每步 O(L) 计算,KV Cache 逐 token 增长
KV Cache 的生命周期局限
传统 KV Cache 的设计初衷是服务于单次推理请求。当请求完成后,系统会立即释放这些缓存以腾出显存。这种设计在单次问答场景下是合理的——不同请求之间没有关联,缓存无法复用。
但现实中的大模型应用往往存在大量可复用的上下文:
- 多轮对话:每一轮都需要携带完整的对话历史,历史部分完全相同
- Few-shot 学习:多个查询共享相同的示例模板
- 系统提示词:成千上万的请求使用相同的系统指令
- RAG 应用:检索的文档集合在一定时间窗口内保持不变
在这些场景中,传统 KV Cache 的"用完即弃"策略导致了巨大的计算浪费。
Prefix Caching:打破单次请求的边界
Prefix Caching 的核心思想非常直接:将已完成的 KV Cache 保留下来,供后续请求复用。
当新请求到达时,系统首先检查是否存在匹配的缓存前缀。如果找到匹配,只需计算新添加的部分,prefill 阶段的工作量可以减少 80% 甚至更多。
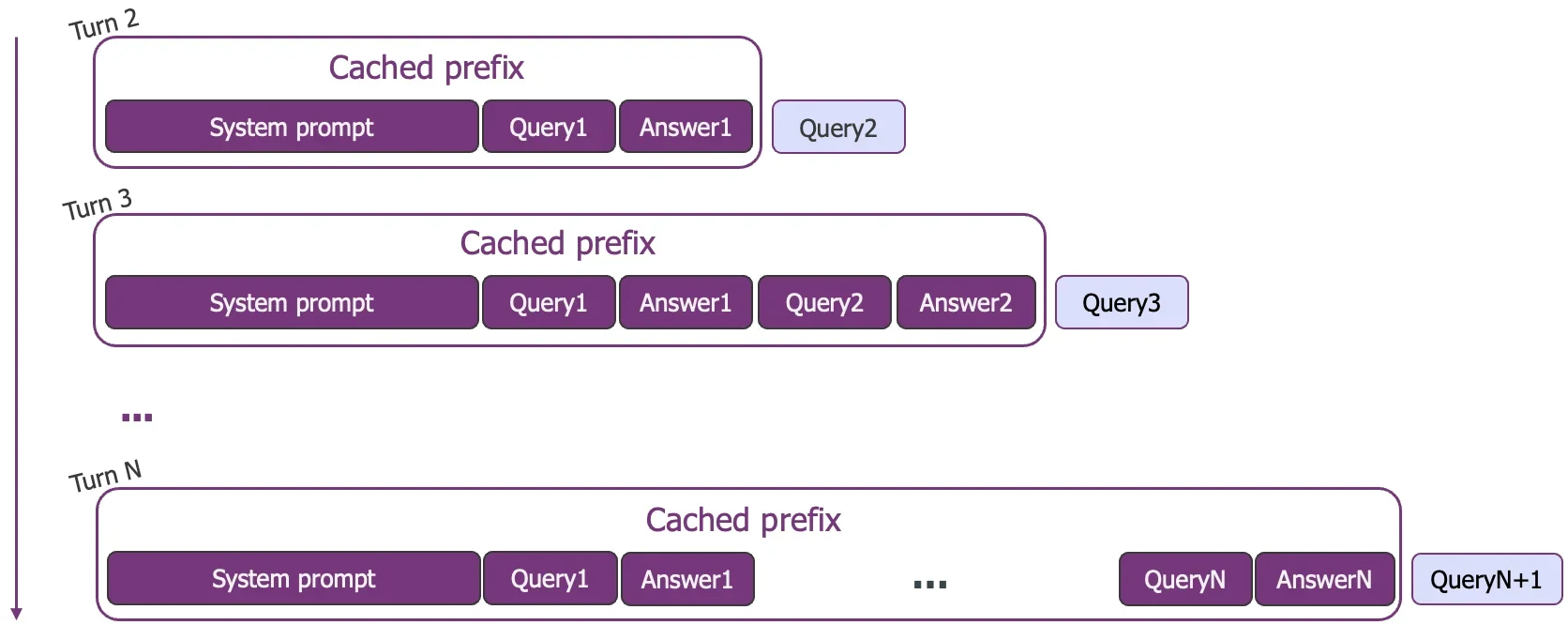
图1: 多轮对话中,对话历史作为增长的前缀被缓存,只有新的用户查询需要预填充计算 图片来源: llm-d Blog
这种复用带来的性能提升是量级的。根据 llm-d 团队的基准测试,对于一个约 10,000 token 的提示词,缓存命中的情况下 Time-To-First-Token(TTFT)从 4.3 秒骤降至 0.6 秒——这是 7 倍的加速。
两大技术流派:Block-Level Hashing vs Radix Tree
Prefix Caching 的核心挑战在于:如何高效地组织和检索缓存块? 目前主流的开源框架采用了两种截然不同的技术方案。
vLLM:Block-Level Hashing
vLLM 采用了一种基于哈希的块级缓存方案。其核心思想是将 KV Cache 划分为固定大小的块(block),每个块的大小通常为 16 个 token。
每个块的哈希值由三部分组成:
$$\text{hash} = H(\text{parent\_hash}, \text{block\_tokens}, \text{extra\_hashes})$$其中:
parent_hash是前一个块的哈希值,形成链式依赖block_tokens是该块内的 token 序列extra_hashes包括 LoRA ID、多模态输入哈希等附加信息
Block 1: hash(token_ids[0:16])
Block 2: hash(hash(Block 1), token_ids[16:32])
Block 3: hash(hash(Block 2), token_ids[32:48])
这种设计的关键优势在于自动发现共享前缀。当两个请求的前 N 个块完全相同时,它们的哈希值必然相同,系统自动复用这些块。
vLLM 使用 LRU(Least Recently Used)淘汰策略管理缓存。当显存不足时,最久未被访问的块会被驱逐。为了支持跨请求共享,vLLM 引入了引用计数机制——一个块只有在引用计数为零时才会真正被释放。
SGLang:RadixAttention 与 Radix Tree
SGLang 选择了完全不同的技术路线——Radix Tree(基数树)。
基数树是一种压缩的前缀树结构。与普通前缀树不同,基数树的边可以标记任意长度的序列,而非单个元素。这种特性使其非常适合存储 token 序列。
普通 Trie: root → A → B → C → D → E
Radix Tree: root → ABC → DE (边可以包含多个 token)
当新请求到达时,SGLang 在基数树中执行前缀匹配,找到最长公共前缀。匹配过程的时间复杂度为 O(L),其中 L 是请求长度。匹配完成后,系统将共享的 KV Cache 加载到当前请求的上下文中。
基数树的一个显著优势是细粒度的共享发现。两个请求可能只在中间某一段相同,基数树能够自动识别并复用这部分,而不要求严格的前缀匹配。
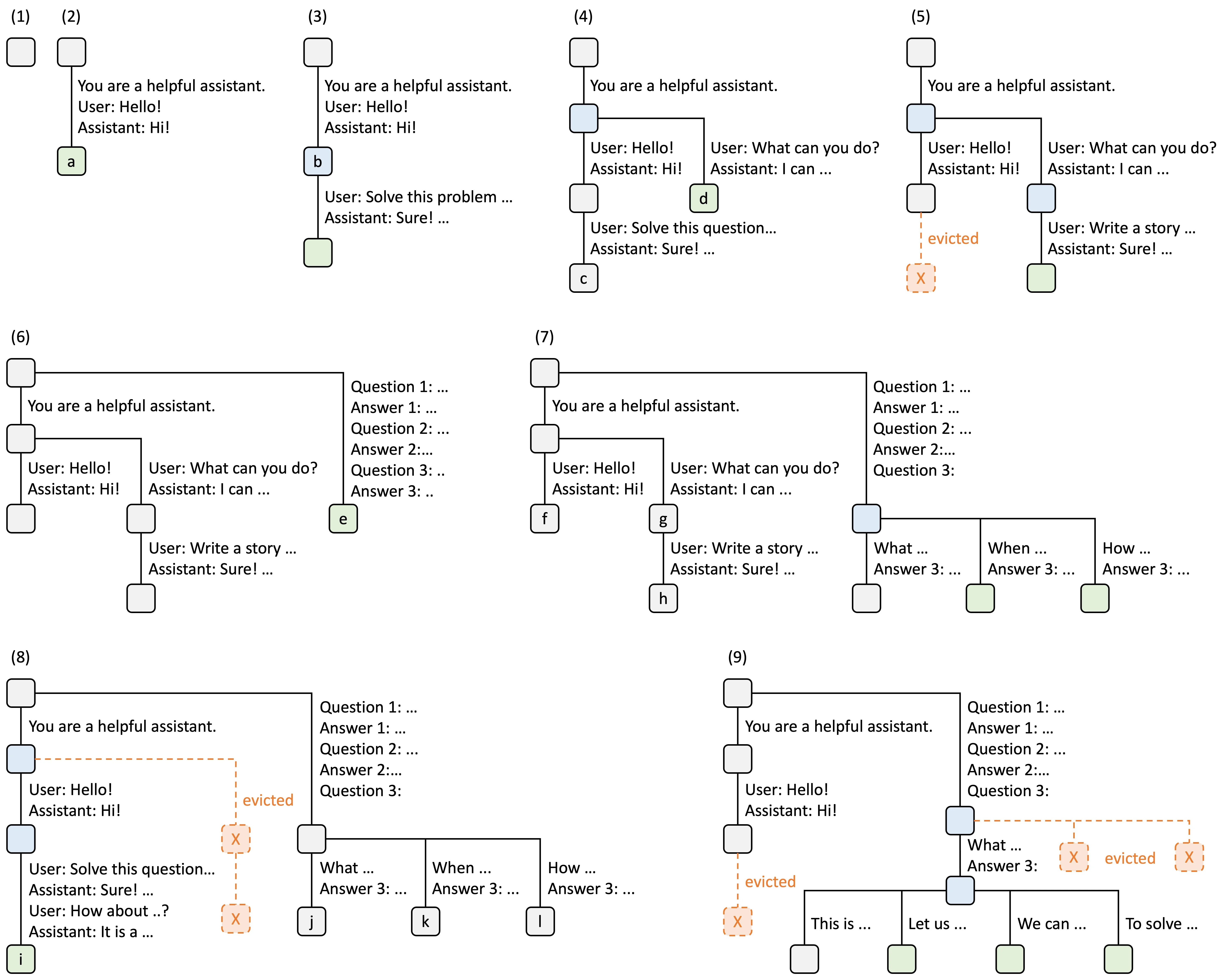
图2: SGLang 的 RadixAttention 操作示例,展示基数树如何处理多个并发请求的动态变化 图片来源: LMSYS Blog
图 2 展示了 RadixAttention 在处理多个请求时的动态演化过程。在步骤 (3) 中,新提示词到达时系统发现前缀已在基数树中,直接复用其 KV Cache。在步骤 (4) 中,新的对话会话开始,节点 “b” 被拆分以允许两个会话共享系统提示词。当显存不足时(步骤 5),LRU 策略驱逐最久未使用的节点。
两种方案的权衡
| 特性 | vLLM Block-Level Hashing | SGLang RadixAttention |
|---|---|---|
| 数据结构 | 哈希表 + 引用计数 | 基数树 |
| 匹配粒度 | 块级别(固定大小) | Token 级别(任意位置) |
| 查找复杂度 | O(1) 哈希查找 | O(L) 树遍历 |
| 内存开销 | 较低 | 较高(需维护树结构) |
| 共享发现 | 仅前缀匹配 | 可发现任意公共序列 |
| 适用场景 | 可预测的固定模板 | 动态变化的对话流 |
根据 RunPod 的基准测试,在多轮对话场景下,SGLang 的 RadixAttention 相比 vLLM 的 Automatic Prefix Caching 实现了约 10-20% 的性能优势。但在单次请求或模板固定的批处理场景中,两者的差距缩小,vLLM 甚至可能在某些情况下领先。
工业界实践:从技术到商业
Prefix Caching 不仅是一项技术优化,更已经演变为大模型服务商的核心商业能力。
OpenAI:隐式缓存与成本节省
OpenAI 在 2024 年推出了 Prompt Caching 功能,该功能对所有符合条件的请求自动启用,无需开发者额外配置。
缓存机制的工作原理如下:
- 路由阶段:请求被路由到基于前缀哈希的特定服务器
- 查找阶段:检查目标服务器上是否存在匹配的缓存前缀
- 复用或计算:命中则跳过 prefill,未命中则完整计算并缓存
核心性能数据:
- 延迟降低:最高 80%
- 输入成本降低:最高 90%
- 最小缓存长度:1,024 token
- 缓存保留时间:5-10 分钟(内存),最长 24 小时(扩展存储)
OpenAI 采用了隐式缓存策略——开发者无需修改代码,系统自动识别可复用的前缀。为了最大化命中率,官方建议将静态内容(系统提示词、示例等)放在消息数组的开头,将动态内容(用户输入)放在末尾。
Anthropic:显式缓存控制
Anthropic 的 Claude API 采用了显式的缓存控制策略。开发者需要在请求中明确标记哪些部分应该被缓存:
{
"messages": [
{"role": "user", "content": [
{"type": "text", "text": "长文档内容...", "cache_control": {"type": "ephemeral"}},
{"type": "text", "text": "用户问题..."}
]}
]
}
定价策略:
- 缓存命中的输入 token:$0.30 / 百万 token
- 未缓存的输入 token:$3.00 / 百万 token
- 价格差距:10 倍
这种显式控制虽然增加了使用复杂度,但提供了更精确的缓存管理能力。开发者可以明确知道哪些内容被缓存,避免了隐式缓存可能带来的不确定性。
智能路由:分布式场景下的缓存感知
当模型部署从单实例扩展到多副本集群时,Prefix Caching 面临新的挑战:每个副本维护独立的缓存,标准负载均衡器会将相关请求分散到不同副本,破坏缓存局部性。
llm-d 项目提出的解决方案是 Precise Prefix-Cache Aware Scheduling:
- 全局缓存视图:所有副本的缓存状态通过 KVEvents 流同步到中央索引
- 缓存亲和评分:为每个请求计算各副本的缓存命中率
- 智能路由:结合负载均衡和缓存亲和度做出路由决策
在 8 个 vLLM 副本(16 张 H100 GPU)的测试环境中,精确缓存感知调度相比随机调度实现了:
- TTFT P90:0.54 秒 vs 92 秒——170 倍改进
- 吞吐量:8,730 token/s vs 4,429 token/s——翻倍
前沿进展:Learned Prefix Caching
传统的 LRU 淘汰策略在 LLM 场景下存在根本性局限:最近最少使用不等于最不可能复用。
用户在与大模型对话时,会在轮次之间停顿思考。一个持续进行中的复杂任务对话,尽管可能有一段时间没有活跃,但其被继续使用的概率远高于一个已经结束的简单问答。LRU 无法捕捉这种语义层面的模式。
NeurIPS 2025:LPC 框架
普林斯顿大学研究团队在 NeurIPS 2025 上发表的论文《Learned Prefix Caching for Efficient LLM Inference》提出了 LPC(Learned Prefix Caching) 框架,首次将机器学习引入缓存淘汰决策。
LPC 的核心是一个对话延续预测器:
- 数据解析:提取用户提示文本
- 文本嵌入:使用 multilingual-e5-small 模型生成语义向量
- MLP 分类:输出对话继续的概率分数
概率更新采用衰减函数:
$$\text{prob}_{\text{cur}} = \text{prob}_{\text{original}} \times \frac{\text{decay}}{\text{decay} + (1 - \text{prob}_{\text{original}})}$$其中 $\text{decay} = \exp(-\Delta t \times \text{scale})$,$\Delta t$ 是距离上次访问的时间间隔。
性能提升
在三个真实对话数据集(LMSys、ShareGPT、Chatbot Arena)上的评估结果显示:
| 数据集 | 相同命中率下缓存大小减少 | 相同缓存大小下命中率提升 |
|---|---|---|
| LMSys | 18% | 13-38% |
| ShareGPT | 30% | 14-98% |
| Chatbot Arena | 43% | 15-30% |
在模拟的分布式推理环境中,LPC 实现了 11% 的 prefill 吞吐量提升,并使 7% 的请求 TTFT 降低了 42-75%。
实践指南:如何设计可缓存的提示词
无论使用哪个框架或服务商,以下原则可以帮助最大化 Prefix Caching 的收益:
结构优化
将静态内容置于前端。缓存匹配基于前缀,因此系统提示词、Few-shot 示例、文档上下文等不变部分应放在消息数组的开头。
推荐结构:
[System Prompt] → [文档/示例] → [对话历史] → [当前问题]
避免结构:
[当前问题] → [对话历史] → [System Prompt] // 无法命中缓存
长度考虑
OpenAI 和 Anthropic 都要求最小缓存长度(通常 1,024 token)。对于短提示词,可以合并多个相关请求或添加背景文档来达到阈值。
多模态处理
图像等多模态输入同样可以被缓存。vLLM 通过将图像哈希编码到块的 extra_hashes 中来支持多模态缓存。需要注意的是,相同的图像必须使用相同的处理参数(如 detail 级别),否则会被视为不同的输入。
安全隔离
在多租户环境中,vLLM 支持 cache_salt 参数来隔离不同用户或租组的缓存:
{
"messages": [...],
"cache_salt": "tenant-123-secret"
}
这可以防止时序攻击——攻击者通过观察响应延迟差异来推断缓存内容。
性能调优建议
vLLM 配置
vllm serve model_name \
--enable-prefix-caching \
--prefix-caching-hash-algo sha256 \
--gpu-memory-utilization 0.9
关键参数:
--enable-prefix-caching:启用自动前缀缓存--prefix-caching-hash-algo:哈希算法(sha256 最安全,xxhash 最快)--gpu-memory-utilization:显存利用率,影响可用缓存空间
SGLang 配置
import sglang as sgl
@sgl.function
def multi_turn_chat(s, system_prompt, user_input):
s += system_prompt + "\n"
s += "User: " + user_input + "\n"
s += "Assistant: " + sgl.gen("response") + "\n"
SGLang 的 RadixAttention 默认启用,无需额外配置。前端始终发送完整提示词,运行时自动处理前缀匹配和缓存复用。
Prefix Caching 已经从一个学术优化技术演变为大模型服务的核心基础设施。从开源框架到商业 API,从单实例到分布式集群,缓存复用的能力正在重塑推理成本的结构。当一个 10,000 token 的提示词可以通过缓存将延迟从 4 秒降到 0.6 秒,当缓存命中的 token 成本是未命中的十分之一,Prefix Caching 不再是锦上添花,而是规模化部署的必选项。
参考资料
- Kwon, W., et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. SOSP 2023.
- Zheng, L., et al. (2024). Efficiently Programming Large Language Models using SGLang. NeurIPS 2024.
- Yang, D., et al. (2025). Learned Prefix Caching for Efficient LLM Inference. NeurIPS 2025.
- OpenAI. (2024). Prompt Caching Documentation.
- Anthropic. (2024). Prompt Caching - Claude API Docs.
- llm-d Project. (2025). KV-Cache Wins You Can See: From Prefix Caching in vLLM to Distributed Scheduling.
- vLLM Documentation. Automatic Prefix Caching.