一个训练了数千亿参数、在海量文本上学习了数十万小时的模型,面对"请列出以A开头的名字"这样一个简单问题,却陷入了这样的怪圈:
Alice, Ann, Andrew, Alice, Ann, Andrew, Alice, Ann, Andrew, Alice, Ann, Andrew, Alice, Ann, Andrew...
这不是个例。在开放式文本生成任务中,这种被称为"模型退化"(Model Degeneration)或"重复诅咒"(Repeat Curse)的现象屡见不鲜。模型会生成字符级别的重复(如"the the the…")、短语级别的循环(如"I don’t know. I don’t know. I don’t know…"),甚至段落级别的复制粘贴。
2019年,Ari Holtzman等人在ICLR发表的论文《The Curious Case of Neural Text Degeneration》首次系统性地揭示了这一问题。六年后的今天,即便GPT-4级别的模型已经可以写出流畅的长文,重复循环的阴影依然挥之不去。这背后隐藏着一个关于概率、注意力与训练数据的复杂技术故事。
自注意力机制:重复的数学温床
要理解重复循环为何发生,必须先理解Transformer架构的核心——自注意力机制(Self-Attention)。
在自回归生成过程中,模型逐个token地生成文本。每一步,模型需要计算当前候选token与上下文中所有已生成token之间的关系。这个计算的核心是Query-Key-Value机制:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$其中,$Q$是查询矩阵,$K$是键矩阵,$V$是值矩阵。关键点在于$QK^T$这个矩阵乘法——它在计算每一对token之间的点积相似度。
当上下文中出现重复token时,一个微妙但致命的机制被触发。假设上下文已经包含了"the the",当模型计算下一个token的概率时:
- 相同的embedding产生高点积:两个"the"的词向量完全相同,因此它们之间的点积(可以类比为余弦相似度)达到最大值
- 注意力分数被放大:softmax函数将高点积转化为高注意力权重
- 更高的复制概率:模型倾向于"复制"被高度关注的token
这就形成了一个正反馈循环:重复的token获得更高的注意力权重,更高的注意力权重使得模型更倾向于生成重复的token。研究者们将这种现象称为"自我强化效应"(Self-Reinforcement Effect)。
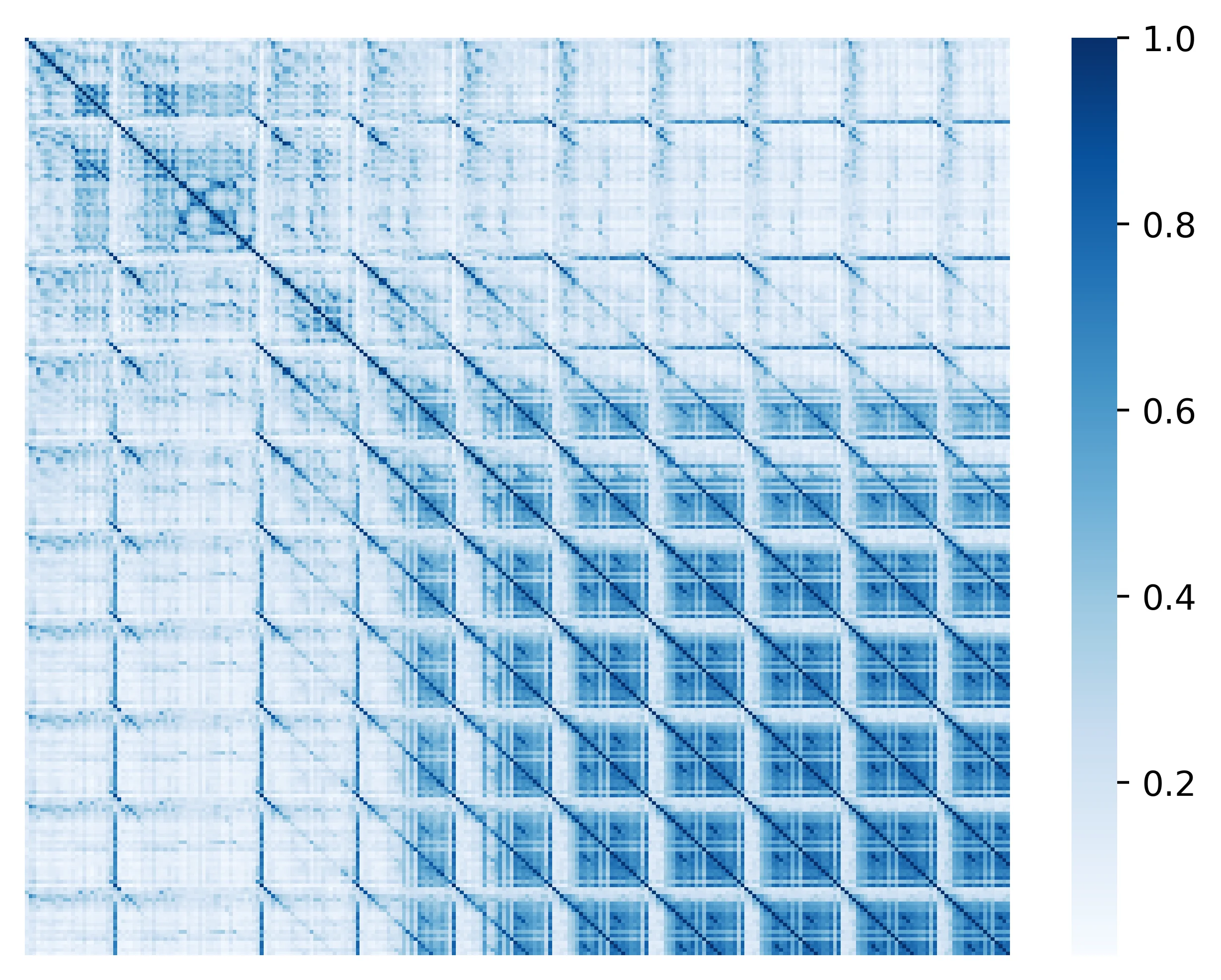
图1: 贪婪搜索生成的文本的token相似度矩阵。非对角线上的高相似度分数(红色区域)清楚地表明了重复问题的存在。 图片来源: Hugging Face Blog - Contrastive Search
训练数据:重复问题的根源
2023年,一篇发表于NeurIPS的论文《Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective》提供了一个令人震惊的发现:训练数据中的重复模式与生成重复之间存在强烈的因果关系。
研究者的实验设计非常精巧。他们将训练数据按重复率(rep-2分数)分成六个分片,分别训练GPT-2模型,然后测量生成文本的重复率。结果显示:训练数据的重复率与生成文本的重复率之间存在近乎线性的正相关关系。
更令人惊讶的是,模型会放大训练数据中的重复模式。当训练数据的rep-2分数为10%时,生成文本的rep-2分数可能高达60%——放大了六倍。这类似于机器学习中的"偏见放大"现象。
基于这一发现,研究者提出了重复丢弃(Repetition Dropout)方法:在训练过程中,随机屏蔽对重复n-gram的注意力,强制模型学习在不依赖重复模式的情况下进行预测。实验表明,这一简单方法可以将生成文本的重复率从47%降低到10%以下。

图2: 训练数据的重复率与生成文本的重复率之间的强相关性。模型不仅学习而且放大了训练数据中的重复模式。 图片来源: Li et al., NeurIPS 2023
Attention Sinks:另一个视角
2025年,一篇发表在ICML的论文《Interpreting the Repeated Token Phenomenon in Large Language Models》揭示了重复问题与"注意力汇聚"(Attention Sinks)现象之间的深层联系。
注意力汇聚是指Transformer模型倾向于将大量注意力分配给序列开头的token(通常是BOS token)。研究者发现,这是因为模型需要通过一个"锚点"来存储全局信息,维持文本的流畅性。
问题出在这里:当输入包含大量重复token时,第一层注意力机制会误判,将这些重复token也标记为"锚点"。由于重复token具有相同的embedding,模型无法区分第一个token和后续的重复token。结果是,重复token获得了本应只属于BOS token的"超级注意力",彻底破坏了模型的正常行为。
研究者发现了一个关键的两阶段机制:
- 标记阶段:第一层注意力通过因果掩码识别序列的第一个token
- 放大阶段:特定MLP神经元被激活,向第一个token的隐藏状态添加高幅值向量
当重复token被错误标记后,同一个放大机制被触发,导致整个序列的注意力分布被扭曲。
graph TD
A[输入序列] --> B[第一层注意力]
B --> C{识别第一个token}
C -->|正常情况| D[标记BOS token]
C -->|重复序列| E[错误标记所有重复token]
D --> F[Sink神经元放大]
E --> G[过度放大重复token]
F --> H[正常注意力分布]
G --> I[扭曲的注意力分布]
I --> J[模型行为异常]
解码策略:从贪婪到采样
理解了重复问题的根源,接下来探讨解决方案。最直接的干预发生在解码阶段。
贪婪搜索的陷阱
贪婪搜索(Greedy Search)是最简单的解码策略:每一步选择概率最高的token。它高效但脆弱——一旦陷入重复循环,就完全没有逃脱机制。这正是前文提到的正反馈循环的完美受害者。
温度参数:熵的调节器
温度参数$T$通过调整logits来控制概率分布的"尖锐度":
$$p_i = \frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)}$$- 当$T \to 0$时,分布趋于one-hot,模型变得极其确定,接近贪婪搜索
- 当$T \to \infty$时,分布趋于均匀,模型输出变得随机
高温增加了输出的多样性,但代价是可能牺牲语义连贯性。过高的温度会让模型"胡言乱语"。
Top-k与Top-p:截断的艺术
Top-k采样限制模型只从概率最高的k个token中选择。Top-p(核采样)则动态选择概率累积达到p的最小token集合。
这两种方法都通过引入随机性来打破确定性循环。但它们有一个共同的局限:只能预防初始的重复,无法在重复已经开始后帮助模型恢复。
重复惩罚:事后的补救
重复惩罚(Repetition Penalty)直接针对已出现的token施加惩罚:
$$\text{logit}'(t) = \begin{cases} \text{logit}(t)/\alpha & \text{if } \text{logit}(t) > 0 \\ \text{logit}(t) \times \alpha & \text{if } \text{logit}(t) < 0 \end{cases}$$其中$\alpha > 1$是惩罚系数。这种方法简单有效,但过于"暴力"——有时会抑制合理的、非重复性的用词。
更精细的控制来自两种变体:
- 频率惩罚(Frequency Penalty):根据token出现的次数进行成比例惩罚,$\text{logit}'(t) = \text{logit}(t) - \alpha \times \text{count}(t)$
- 存在惩罚(Presence Penalty):只要出现过就施加固定惩罚,$\text{logit}'(t) = \text{logit}(t) - \alpha$
| 参数 | 惩罚依据 | 主要目标 | 适用场景 |
|---|---|---|---|
| Repetition Penalty | 是否出现 | 阻断循环 | 严重重复 |
| Frequency Penalty | 出现次数 | 降低高频词 | 轻微重复 |
| Presence Penalty | 是否出现 | 鼓励新词 | 词汇多样性 |
对比搜索:平衡的艺术
2022年,Yixuan Su等人在NeurIPS发表的论文《A Contrastive Framework for Neural Text Generation》提出了对比搜索(Contrastive Search),一种更优雅的解决方案。
对比搜索的核心思想是同时考虑两个因素:
$$x_t = \underset{x \in V^{(k)}}{\arg\max} \left\{ (1-\alpha) p_\theta(x|x_{- 第一项是模型置信度:token $x$ 被模型预测的概率
- 第二项是退化惩罚:$x$ 与上下文中所有token的最大相似度
- $\alpha$ 是平衡系数
对比搜索的精妙之处在于:它不是简单惩罚重复,而是在保持语义连贯性的同时,主动避免生成与上下文过于相似的token。
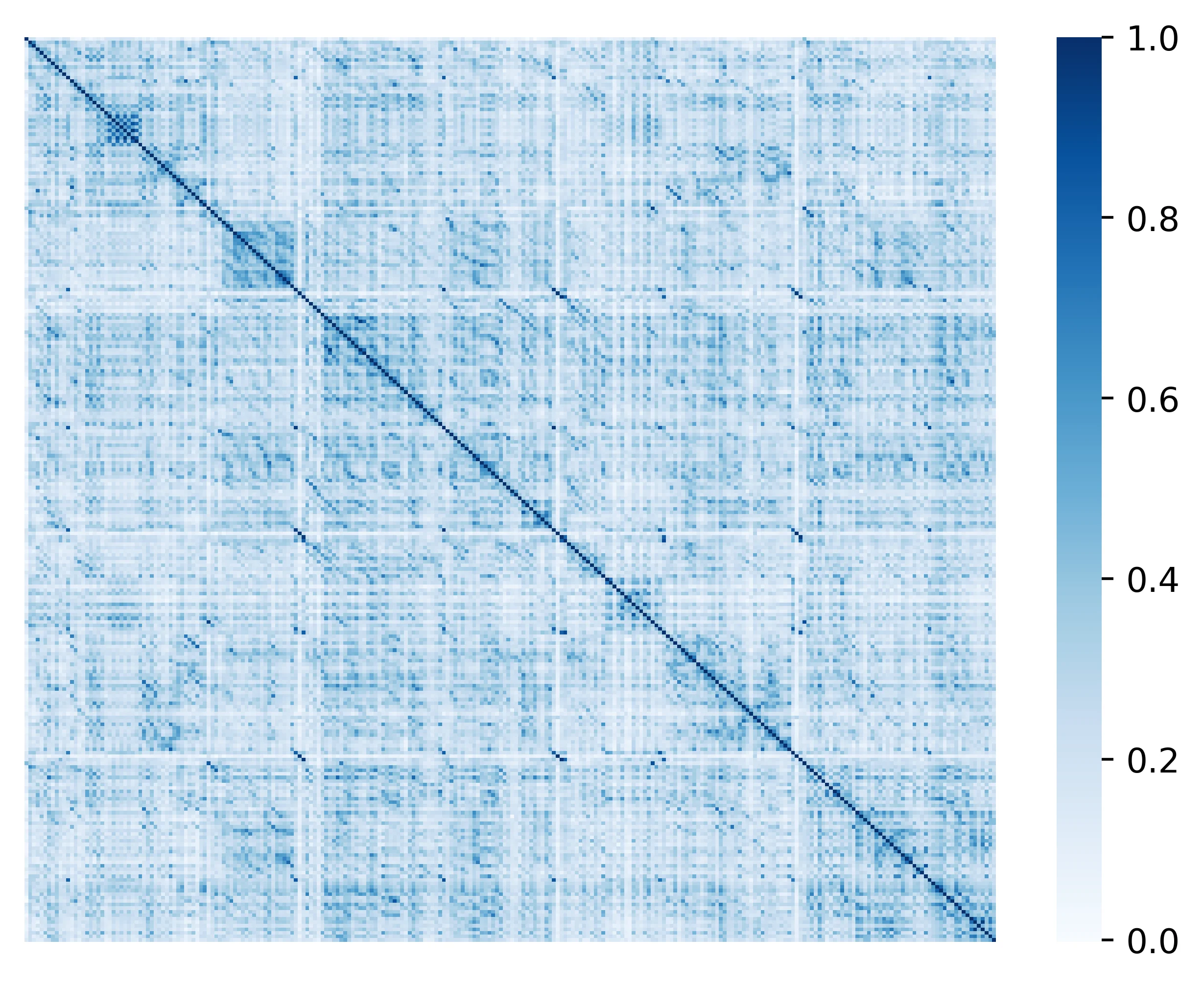
图3: 对比搜索生成的文本的token相似度矩阵。高相似度分数主要集中在对角线上,表明退化问题被成功解决。 图片来源: Hugging Face Blog - Contrastive Search
实验结果令人印象深刻。使用相同的GPT-2模型和相同的提示词,对比搜索能够生成流畅、连贯、无重复的长文本,而贪婪搜索和核采样分别在重复和语义漂移上失败。
Beam Search的隐藏参数
2025年12月,一篇arXiv论文《Solving LLM Repetition Problem in Production》揭示了一个被广泛忽视的关键细节:Beam Search的early_stopping参数是解决重复问题的关键。
Beam Search通过维护多个候选序列来探索更广泛的解空间。但研究者发现,只有当early_stopping=True时,Beam Search才能有效打断重复循环:
| 配置 | 重复率 |
|---|---|
| Greedy Search | ~80% |
| Beam Search (early_stopping=False) | ~60% |
| Beam Search (early_stopping=True) | ~0% |
原因在于:当early_stopping=True时,算法一旦找到足够数量的完整候选序列就立即终止,避免了在搜索空间中"绕圈子"回到重复模式的风险。
特征层面的干预
2025年ACL会议上,一项研究从特征视角(Feature Perspective)重新审视了重复问题。研究者使用稀疏自编码器(Sparse Autoencoders, SAE)识别出模型中专门负责"重复"的特征。
SAE将模型的激活分解为可解释的特征方向:
$$\hat{x} = b_{dec} + \sum_{i=1}^{F} f_i(x) W_{dec,i}$$研究者发现,通过"激活"这些重复特征,可以诱导模型产生重复输出;反过来,通过"抑制"这些特征,可以有效缓解重复问题。更有趣的是,这些特征往往与特定语义类别相关——如人名、日期、专有名词等——揭示了重复问题与模型内部知识组织的深层联系。
工程实践的最佳组合
在生产环境中,单一方案往往难以应对所有场景。基于现有研究,推荐以下组合策略:
第一层防线:解码策略
- 使用对比搜索($\alpha=0.6$, $k=4$)或Beam Search($n=5$,
early_stopping=True) - 对于需要确定性的场景,温度设为0
第二层防线:惩罚参数
- 设置温和的重复惩罚(1.05-1.15)作为安全网
- 配合轻量的存在惩罚(0.1-0.3)鼓励多样性
第三层防线:训练干预
- 对于有控制权的模型,在训练数据中应用重复丢弃
- 或使用DPO(Direct Preference Optimization)微调,让模型学习偏好非重复输出
第四层防线:后处理
- 实时监测重复率
- 检测到重复时动态调整参数或重新生成
未解之谜与未来方向
尽管六年来的研究已经揭示了重复问题的诸多机制,一些根本性问题仍然悬而未决:
为什么模型"愿意"陷入循环? 从训练目标来看,最大化似然估计并不直接鼓励重复。一种假说是:在重复模式上,模型找到了一条"捷径"——从最近的上下文中复制比从头生成更容易降低损失。
为什么指令微调能缓解问题? 研究者发现,经过指令微调的模型(如ChatGPT)重复率明显降低。但这是因为指令数据本身的重复率较低,还是指令微调改变了模型的某种内在机制?
是否存在完美的解决方案? 目前所有方案都在"阻止重复"和"保持质量"之间存在权衡。是否存在一种理论上的最优解?
2024年,一篇论文的标题道出了这个领域的现状:“Contrastive Search Is What You Need”——也许我们不需要完美的方案,只需要足够好的工程智慧。
参考文献
- Holtzman, A., et al. “The Curious Case of Neural Text Degeneration.” ICLR 2020.
- Li, H., et al. “Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective.” NeurIPS 2023.
- Su, Y., et al. “A Contrastive Framework for Neural Text Generation.” NeurIPS 2022.
- Gandelsman, Y., et al. “Interpreting the Repeated Token Phenomenon in Large Language Models.” ICML 2025.
- Yao, J., et al. “Understanding the Repeat Curse in Large Language Models from a Feature Perspective.” ACL 2025 Findings.
- Fu, Z., et al. “A Theoretical Analysis of the Repetition Problem in Text Generation.” AAAI 2021.
- Anonymous. “Solving LLM Repetition Problem in Production: A Comprehensive Study of Multiple Solutions.” arXiv 2025.