1990年,Yann LeCun发表了一篇题为《Optimal Brain Damage》的论文,提出了一个反直觉的发现:训练好的神经网络中,高达90%的参数可以被安全删除,而模型精度几乎不受影响。这篇文章开创了神经网络剪枝的研究领域,但三十多年后,这项技术仍然难以在实际部署中大规模应用。
问题的核心在于:删除权重很容易,让删除后的模型真正跑得更快却很难。
稀疏性的悖论:存储节省不等于计算加速
神经网络剪枝的核心思想非常直观——找到模型中"不重要"的参数并将其置零。最朴素的方法是幅值剪枝(Magnitude Pruning):直接删除绝对值最小的权重。一个训练好的模型,其权重分布通常呈现零中心的高斯分布,大量权重集中在零附近。如果按幅值排序,删除最小的50%,模型的预测能力往往不会显著下降。
但这里存在一个关键的工程陷阱:稀疏矩阵的计算效率取决于稀疏模式。
考虑一个简单的矩阵乘法 $\mathbf{Y} = \mathbf{X}\mathbf{W}$。如果$\mathbf{W}$中50%的元素被随机置零(非结构化稀疏),标准的稠密矩阵乘法内核仍然需要遍历所有元素——零值并没有被跳过,只是参与的是零乘法。要真正利用稀疏性,需要专门的稀疏矩阵库,如cuSPARSE,但这些库在GPU上的效率往往不如稠密运算,尤其是在稀疏度不够高(如50-70%)的情况下。
这就形成了一个两难境地:非结构化剪枝可以达到很高的压缩率,但难以获得实际的加速;结构化剪枝(删除整个通道、注意力头或层)可以直接减少计算量,但会带来更大的精度损失。
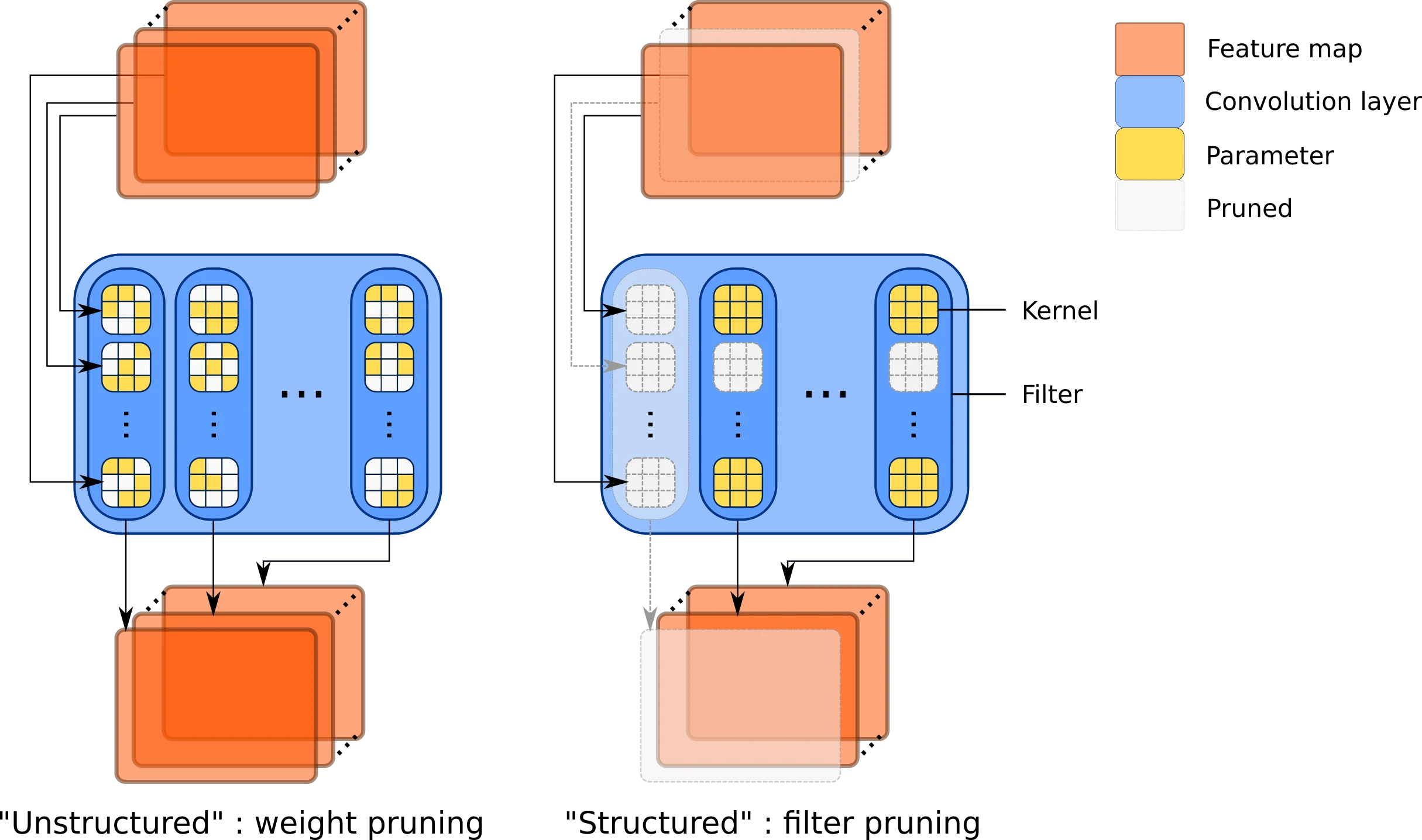
上图清晰展示了两种剪枝模式的本质区别:非结构化剪枝(左)在权重矩阵中随机置零,产生不规则的稀疏模式;结构化剪枝(右)删除整行或整列,产生规则的"块状"稀疏,可以直接减少特征图的数量。
从最优脑损伤到最优脑外科医生
LeCun的Optimal Brain Damage(OBD)方法之所以被称为"最优",是因为它不是简单地按幅值排序删除权重,而是利用二阶导数信息来评估每个权重对损失函数的"重要性"。
核心思想是:删除一个权重$w_i$会导致损失函数的变化,这个变化可以用泰勒展开近似:
$$\Delta L \approx \frac{\partial L}{\partial w_i} \Delta w_i + \frac{1}{2} \frac{\partial^2 L}{\partial w_i^2} (\Delta w_i)^2$$在训练收敛点,一阶导数接近零,因此主要贡献来自二阶项。OBD引入了一个"显著性"指标:
$$s_i = \frac{1}{2} \frac{\partial^2 L}{\partial w_i^2} w_i^2$$这个指标综合考虑了权重的幅值和对应的二阶曲率。高曲率意味着该权重处于损失函数的"陡峭"区域,删除它会带来较大的损失增加。
1992年,Hassibi和Stork提出了Optimal Brain Surgeon(OBS),进一步考虑了权重之间的相关性。OBS的核心洞察是:删除一个权重后,剩余权重可以通过最优的"补偿更新"来最小化损失增加。这需要计算Hessian矩阵的逆:
$$\delta w = -\frac{w_i}{[H^{-1}]_{ii}} H^{-1}_{:,i}$$其中$[H^{-1}]_{ii}$是逆Hessian矩阵的第$i$个对角元素,$H^{-1}_{:,i}$是其第$i$列。
OBS在理论上更加完备,但计算Hessian矩阵的逆在大型网络上代价高昂。这个限制在LLM时代变得尤为突出——计算千亿参数模型的Hessian矩阵几乎是不可能的。
彩票假说:稀疏子网络可以从头训练
2018年,MIT的Jonathan Frankle和Michael Carbin发表了一篇改变领域认知的论文:《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》。
他们的核心发现是:一个随机初始化的稠密网络中,存在一个稀疏子网络,该子网络从相同的初始化开始训练,可以达到与原网络相当的精度。这个子网络被称为"中奖彩票"(winning ticket)。
这个发现回答了一个长期困扰研究者的问题:剪枝得到的稀疏网络之所以效果好,是因为训练过程学到了有用的结构,还是因为原始初始化中就"埋藏"了好的子网络?
彩票假说的答案是后者。Frankle等人提出的迭代幅值剪枝(Iterative Magnitude Pruning, IMP)算法如下:
- 随机初始化网络,保存初始权重$\theta_0$
- 训练网络至收敛,得到$\theta$
- 按幅值删除最小的$p\%$权重,得到掩码$m$
- 将剩余权重重置为$\theta_0$(关键步骤!)
- 用掩码$m$重新训练
- 重复步骤3-5,逐步增加稀疏度
关键的发现是:权重重置至关重要。如果删除权重后保留训练后的值,子网络无法有效训练;但如果重置为原始初始化,即使删除90%的权重,子网络仍能达到与原网络相当的精度。
彩票假说的理论解释涉及神经网络的过参数化特性。一个足够大的网络包含了大量可能的子网络,随机初始化相当于同时采样了这些子网络的初始配置。其中一些子网络恰好拥有"好"的初始化——它们就是中奖彩票。
后续研究进一步提出了"强彩票假说"(Strong Lottery Ticket Hypothesis):一个随机初始化的网络中,存在一个子网络,无需任何训练就能达到目标网络的性能。这个更强的断言在2020年被Malach等人从理论上证明。
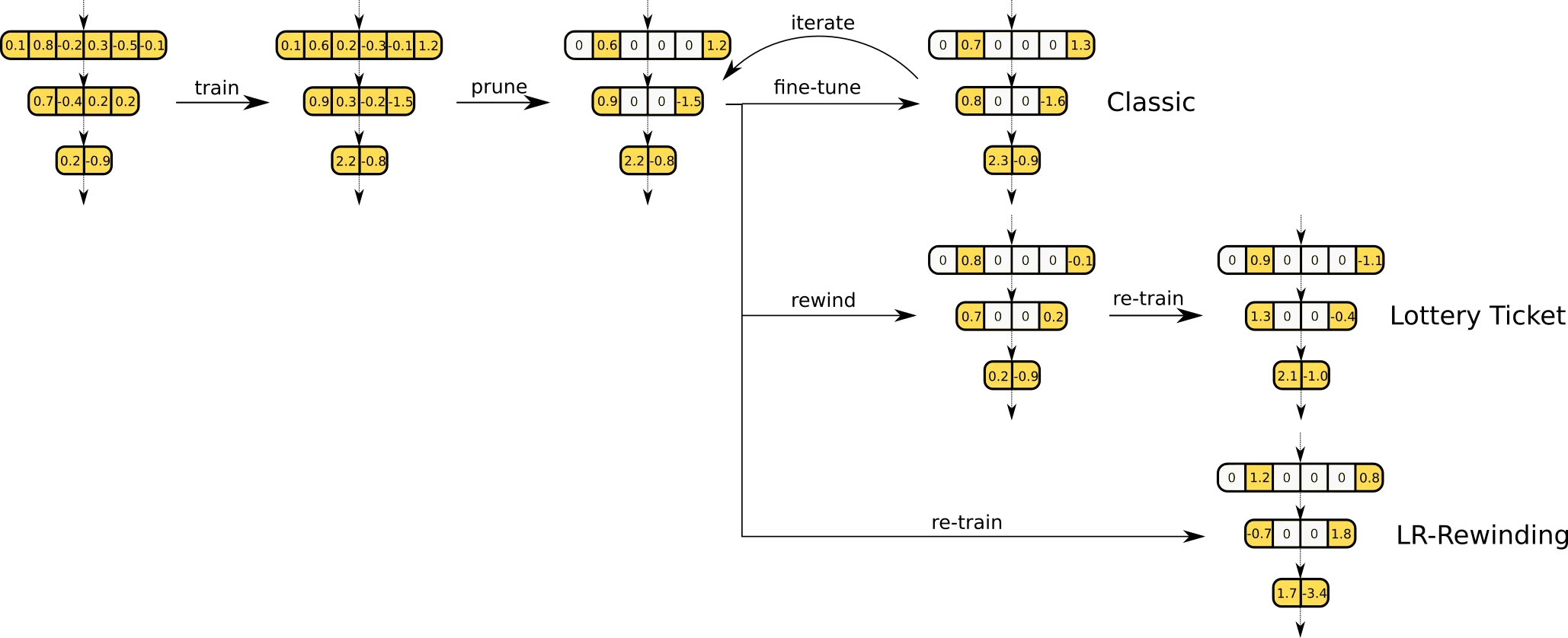
上图对比了经典剪枝框架、彩票假说实验和学习率回退三种方法的核心差异。彩票假说的关键创新在于"权重回退"——将剪枝后的权重重置为原始初始化值。
LLM剪枝的两条路径:SparseGPT与Wanda
当模型规模扩展到百亿甚至千亿参数时,传统的剪枝方法面临严峻挑战。迭代剪枝需要多次重新训练,对于LLM来说代价过高。OBD/OBS需要计算Hessian信息,在LLM规模上不可行。
2023年1月,IST Austria的Elias Frantar和Dan Alistarh提出了SparseGPT,首次实现了LLM的一次性高精度剪枝。他们的核心洞察是:将剪枝问题分解为逐层的权重重建问题。
对于每一层的线性变换$\mathbf{Y} = \mathbf{X}\mathbf{W}$,SparseGPT的目标是找到一个稀疏矩阵$\hat{\mathbf{W}}$,使得$\mathbf{X}\hat{\mathbf{W}}$尽可能接近原始输出$\mathbf{Y}$。这可以形式化为:
$$\min_{\hat{\mathbf{W}}} \|\mathbf{X}\mathbf{W} - \mathbf{X}\hat{\mathbf{W}}\|_2^2 \quad \text{s.t.} \quad \|\hat{\mathbf{W}}\|_0 \leq k$$SparseGPT采用OBS的思想,但通过巧妙的近似避免了完整的Hessian计算。它按行处理权重矩阵,对于每一行,维护一个局部的逆Hessian信息,逐步选择要删除的权重并更新剩余权重。
实验结果表明,SparseGPT可以在OPT-175B和BLOOM-176B等千亿参数模型上,在4.5小时内实现50%的稀疏度,困惑度几乎不增加。更令人惊讶的是,它可以达到60%的稀疏度,而困惑度的增加仍然可以接受——这意味着超过1000亿个权重可以在推理时被忽略。
然而,SparseGPT仍然需要求解权重重建问题,虽然高效但仍有一定的计算开销。2023年6月,CMU的研究团队提出了一个更简单的方法:Wanda(Pruning by Weights and Activations)。
Wanda的核心思想出奇简单:直接按权重幅值与输入激活范数的乘积来排序删除权重:
$$\text{score}_{ij} = |W_{ij}| \cdot \|X_{:,j}\|_2$$这个度量标准背后的直觉是:一个权重的重要性不仅取决于其自身的幅值,还取决于它对应的输入激活的"活跃程度"。如果一个权重很大,但其对应的输入特征几乎总是零,那么这个权重对最终输出几乎没有贡献。
Wanda的优势在于它不需要任何权重更新——剪枝后的模型可以直接使用。其PyTorch实现极其简洁:
def prune(W, X, s):
# W: weight matrix (C_out, C_in)
# X: input matrix (N * L, C_in)
# s: desired sparsity, between 0 and 1
metric = W.abs() * X.norm(p=2, dim=0) # 计算Wanda剪枝度量
_, sorted_idx = torch.sort(metric, dim=1) # 按输出维度排序
pruned_idx = sorted_idx[:, :int(C_in * s)] # 获取要剪枝的索引
W.scatter_(dim=1, index=pruned_idx, src=0) # 将对应权重置零
return W
实验表明,在LLaMA和LLaMA-2上,Wanda在50%稀疏度下的表现与SparseGPT相当,但计算速度快一个数量级。
| 方法 | 是否需要重训练 | 是否需要权重更新 | 计算复杂度 | 50%稀疏度困惑度(LLaMA-7B) |
|---|---|---|---|---|
| 幅值剪枝 | 否 | 否 | O(n) | 34.2 |
| SparseGPT | 否 | 是 | O(n·d²) | 6.8 |
| Wanda | 否 | 否 | O(n·d) | 7.1 |
表格来源:根据Wanda论文及后续研究整理
结构化稀疏性的硬件支持
2020年,NVIDIA在Ampere架构(A100)中引入了对结构化稀疏性的硬件支持。这个功能被称为"稀疏Tensor Core",它要求权重矩阵满足"2:4稀疏模式":在每4个连续的权重中,恰好有2个为零。
这种规则的稀疏模式有两个关键优势:
- 存储效率:只需存储非零值和2-bit的索引元数据
- 计算效率:Tensor Core可以跳过零值,理论上吞吐量翻倍
然而,2:4稀疏性是一个相对严格的约束。50%的稀疏度是固定的,不能更高也不能更低。更重要的是,从非结构化稀疏转换为2:4稀疏可能带来额外的精度损失。
NVIDIA提供了两种训练策略来获得满足2:4模式的稀疏模型:
基本流程:先训练稠密模型,然后按2:4模式剪枝,最后微调恢复精度。
渐进式稀疏训练:将目标稀疏度分成多个阶段,逐步增加稀疏度并在每个阶段微调。例如,先达到25%稀疏度,微调后再达到50%稀疏度。
腾讯的机器学习平台团队报告了在实际搜索系统中的应用结果:结合2:4稀疏性和INT8量化,在离线服务中实现了1.3-1.8倍的加速,而模型精度没有显著下降。
剪枝与量化的协同优化
剪枝和量化是两种互补的模型压缩技术。剪枝减少权重数量,量化降低每个权重的存储精度。将两者结合,可以实现更大的压缩率。
一个自然的顺序是:先剪枝再量化。剪枝产生稀疏模型后,对剩余的非零权重进行量化。SparseGPT和Wanda的作者都验证了这种方法的有效性:50%稀疏度 + INT4量化,可以在几乎不损失精度的情况下将模型大小压缩到原来的1/8。
然而,简单的串联并不总是最优的。2024年,多项研究提出了联合优化的方法。核心思想是:在剪枝决策时考虑量化误差,或在量化时考虑稀疏结构。
Amazon的研究团队在2025年提出了Wanda++,引入"区域梯度"的概念来改进原始Wanda方法。在剪枝决策时,Wanda++不仅考虑局部的重要性分数,还评估删除一个权重对周围权重的影响。这种方法在多语言LLM上表现尤为出色,将剪枝后的困惑度降低了高达52%。
另一个有趣的方向是"稀疏感知量化"。传统的量化方法对所有权重使用统一的量化尺度,但在稀疏模型中,剩余的非零权重可能具有不同的统计特性。针对性地设计量化策略可以进一步降低量化误差。
局部剪枝与全局剪枝的权衡
剪枝决策的粒度也是一个重要的设计选择。局部剪枝(Local Pruning)在每一层独立决定要删除的权重比例,而全局剪枝(Global Pruning)在整个网络范围内统一排序和删除。
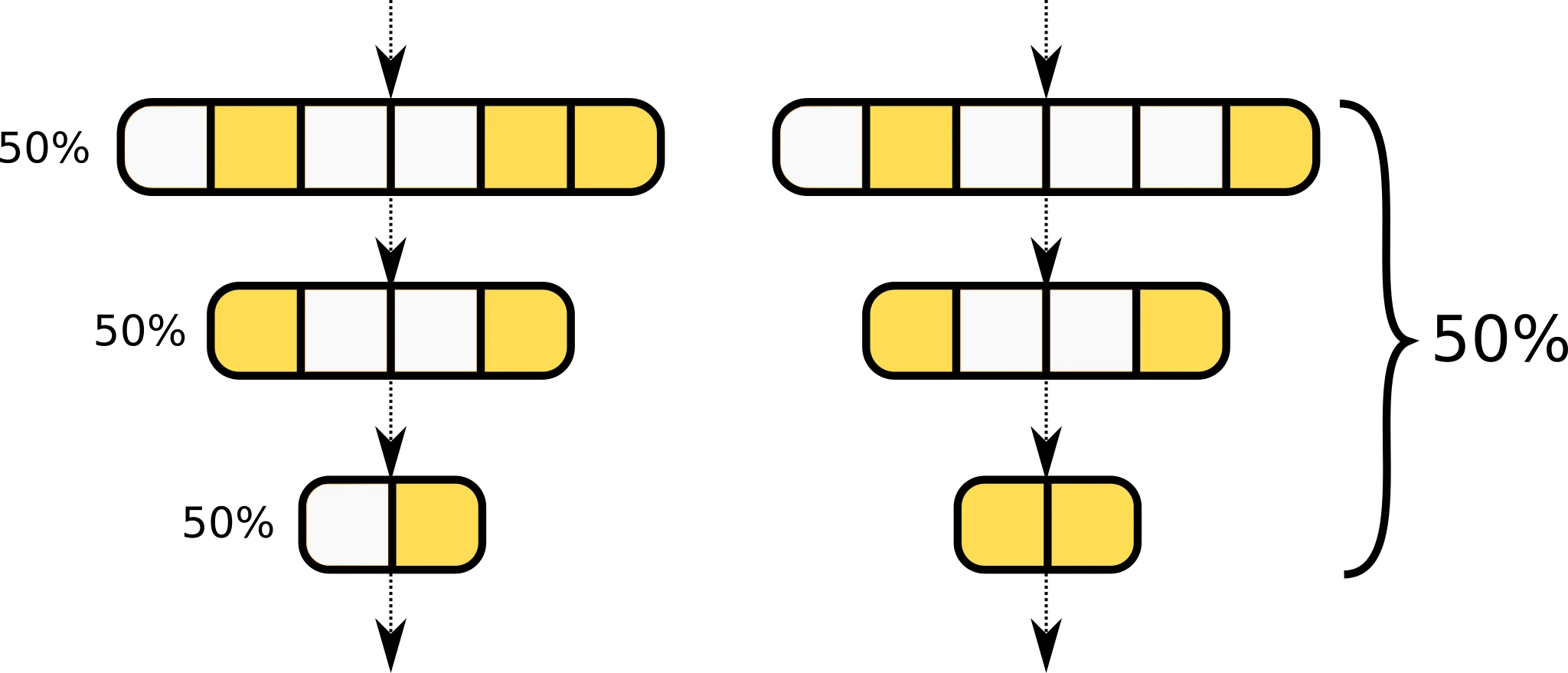
全局剪枝通常能获得更好的精度,因为它可以根据各层的实际重要性动态分配稀疏度。然而,全局剪枝也可能导致"层崩塌"(Layer Collapse)——某些层被过度剪枝,导致整个网络失效。局部剪枝更加保守,确保每一层都保留足够的容量,但可能无法达到最优的整体压缩率。
对于LLM,研究表明不同层对剪枝的敏感度差异很大。早期层(嵌入层和前几层Transformer)通常更敏感,因为它们负责处理原始输入;后期层也较敏感,因为它们产生最终输出;中间层相对鲁棒。因此,一种常见策略是为不同层分配不同的剪枝比例——敏感层保留更多权重。
剪枝技术的边界与未来
尽管剪枝技术在理论上已经相当成熟,但在实际部署中仍然面临挑战。
非结构化剪枝的硬件困境。虽然SparseGPT和Wanda可以在50%稀疏度下保持较高精度,但这种不规则的稀疏模式难以在现有硬件上高效执行。NVIDIA的2:4稀疏性是一个解决方案,但它限制了稀疏度的灵活性。AMD和Intel也在探索类似的硬件支持,但生态系统尚未成熟。
结构化剪枝的精度损失。删除整个注意力头或FFN神经元可以直接减少计算量,但通常会带来更大的精度下降。2024年的LLM-Pruner和2025年的SlimLLM等工作尝试通过梯度信息和语义分析来识别真正"冗余"的结构组件,但问题尚未完全解决。
动态剪枝的可能性。现有的剪枝方法都是静态的——剪枝决策在部署前固定。但研究表明,不同输入对模型的依赖模式不同。动态剪枝可以根据输入特征实时选择保留的权重,潜在地实现更好的精度-效率权衡。这种方法需要特殊的硬件支持,目前仍处于研究阶段。
剪枝技术的演进反映了一个更广泛的工程原则:没有放之四海而皆准的最优方案,只有在特定约束下的最佳权衡。非结构化剪枝在存储压缩上效果显著,结构化剪枝在计算加速上更有优势。选择哪种方法,取决于部署场景的具体约束——是内存受限、计算受限,还是延迟敏感。
对于LLM时代的实践者,一个合理的策略是:首先尝试量化(技术成熟、效果稳定);如果需要进一步压缩,考虑Wanda等无需重训练的剪枝方法;如果部署硬件支持结构化稀疏(如A100),可以探索2:4稀疏性训练。在可预见的未来,剪枝技术将继续与量化、蒸馏等方法协同演进,共同推动大模型从云端走向边缘。
参考文献
-
LeCun, Y., Denker, J. S., & Solla, S. A. (1990). Optimal Brain Damage. Advances in Neural Information Processing Systems, 2, 598-605.
-
Hassibi, B., & Stork, D. G. (1993). Second Order Derivatives for Network Pruning: Optimal Brain Surgeon. Advances in Neural Information Processing Systems, 5, 164-171.
-
Frankle, J., & Carbin, M. (2019). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. International Conference on Learning Representations.
-
Frantar, E., & Alistarh, D. (2023). SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot. International Conference on Machine Learning.
-
Sun, M., Liu, Z., Bair, A., & Kolter, J. Z. (2024). A Simple and Effective Pruning Approach for Large Language Models. International Conference on Machine Learning.
-
NVIDIA. (2020). NVIDIA A100 Tensor Core GPU Architecture. NVIDIA Whitepaper.
-
Malach, E., et al. (2020). Proving the Lottery Ticket Hypothesis: Pruning is All You Need. International Conference on Machine Learning.
-
Dong, X., Chen, G., & Yan, S. (2017). Learning to Prune Deep Neural Networks via Layer-wise Optimal Brain Surgeon. Advances in Neural Information Processing Systems, 30.