2023年,MIT韩松实验室的研究团队在测试一个看似简单的问题时,发现了一个令人困惑的现象。他们尝试用滑动窗口来限制大模型的KV Cache大小——这是控制显存占用的标准做法。然而,当窗口滑动、第一个Token被踢出缓存时,模型不是逐渐变差,而是瞬间崩溃。
困惑度(Perplexity)从正常的5.4飙升到5000以上。模型开始输出乱码:无尽的换行符、破碎的Unicode字符、重复的单词序列。这不仅仅是性能下降,而是彻底的功能失效。
更诡异的是,这个被踢出的"第一个Token",在很多情况下只是一个无意义的开始符号<s>。为什么一个语义上无关紧要的Token,竟然掌握着整个模型的"生死"?
这个发现催生了StreamingLLM框架,也让一个名为"Attention Sink"的现象浮出水面。
Softmax的隐形约束
要理解Attention Sink,需要先回到Transformer注意力机制的核心公式。给定查询向量$q$和一组键向量$\{k_1, k_2, ..., k_n\}$,注意力权重通过Softmax计算:
$$\text{Attention}(q, K) = \text{Softmax}\left(\frac{qK^T}{\sqrt{d_k}}\right)$$展开Softmax:
$$\alpha_i = \frac{e^{s_i}}{\sum_{j=1}^{n} e^{s_j}}$$其中$s_i = q \cdot k_i / \sqrt{d_k}$是查询与第$i$个键的相似度分数。
这里隐藏着一个关键约束:$\sum_{i=1}^{n} \alpha_i = 1$。Softmax强制所有注意力权重之和等于1,形成一个概率分布。
这个约束的后果是:即使当前查询与所有键都没有强匹配,注意力分数也必须"花出去"。如果$q$与$k_1, k_2, ..., k_n$的相似度都很低,Softmax仍然会分配出权重,只是这些权重会相对均匀地分散。
但实际情况更复杂。在自回归语言模型中,不同Token的Key向量并非均匀分布。某些Token的Key向量会"学会"接收这些无处安放的注意力分数——它们成为了"汇点"(Sink)。
注意力热力图中的异常条纹
MIT团队在论文《Efficient Streaming Language Models with Attention Sinks》中展示了Llama-2-7B的注意力分布可视化。结果令人震惊:
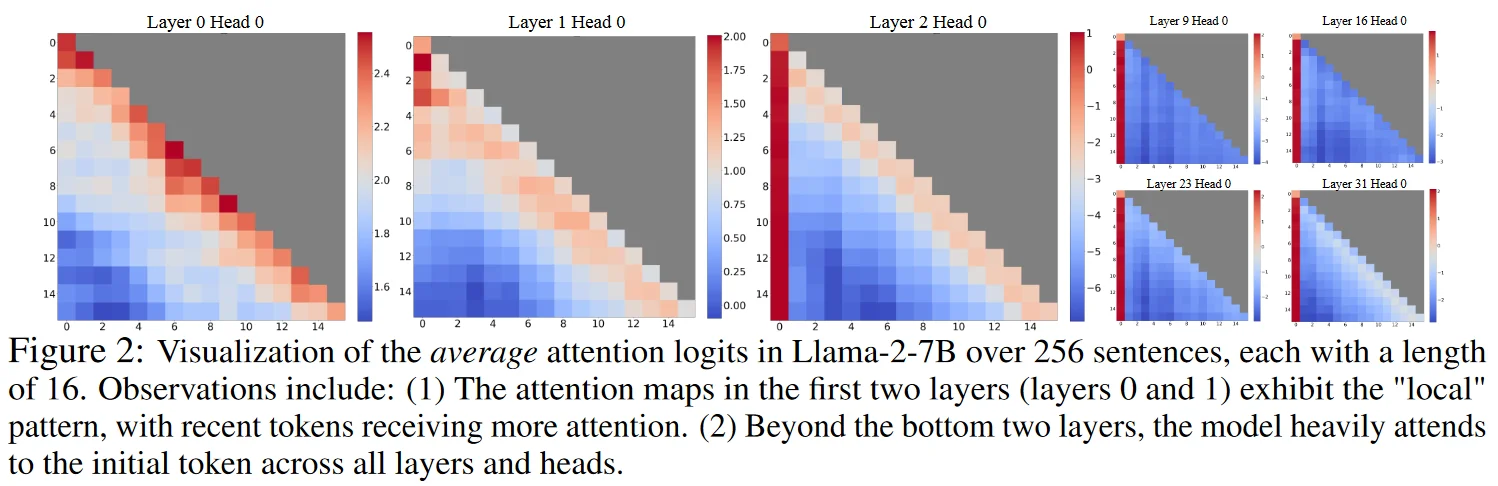
在模型的前两层(Layer 0和Layer 1),注意力呈现典型的"对角线"模式——每个Token主要关注自己附近的上下文。但从第三层开始,一个明显的深红色竖条出现在第一列:几乎所有Token都在向第一个Token分配大量注意力。
这种模式在深层网络中更加显著。某些注意力头将30%-40%的权重分配给第一个Token,无论这个Token在语义上是否与当前生成相关。
为什么是第一个Token?
为什么模型选择第一个Token作为"汇点",而不是其他位置?答案藏在两个技术细节中。
自回归的可见性约束:在因果注意力(Causal Attention)机制下,Token $t$只能看到Token $1, 2, ..., t$。第一个Token是唯一被所有后续Token"看到"的位置。这意味着第一个Token的Key向量参与了所有位置的注意力计算,获得了最多的"训练机会"来学习如何成为一个好的汇点。
RoPE的几何优势:旋转位置编码(RoPE)通过旋转向量来编码位置信息。对于位置$m$的Token,其查询向量被旋转角度$m\theta$。关键在于:第一个位置($m=0$)的旋转角度为0,旋转矩阵是单位矩阵。
$$R_0 = I$$这给第一个Token带来了计算上的特殊性。其他Token经过旋转后,与第一个Token的Key向量计算点积时,不受位置旋转的影响。这种"零旋转"特性使第一个Token成为所有其他Token的"锚点"。
ICLR 2025的论文《What are you sinking? A geometric approach on attention sink》进一步从几何角度解释:第一个Token实际上充当了表示空间的参考帧(Reference Frame),为其他Token提供了坐标系的原点。没有这个锚点,Token之间的相对位置关系就无法稳定建立。
窗口注意力为何失败
当使用滑动窗口限制KV Cache大小时,一旦窗口移动,旧的Token会被踢出缓存。如果第一个Token被踢出,注意力计算的分母会发生剧变:
$$\sum_{j=1}^{n} e^{s_j} \quad \rightarrow \quad \sum_{j=2}^{n} e^{s_j}$$假设第一个Token原本获得了30%的注意力权重,意味着$e^{s_1}$占据了分母的很大一部分。当它被移除后,分母骤降,剩余Token的注意力权重被剧烈放大,整个分布崩塌。
这解释了为什么Window Attention不是"逐渐变差",而是"瞬间崩溃"——这是一个数学上的不连续跳变。
StreamingLLM:一个简洁的解决方案
理解了问题根源,解决方案变得异常简单:永远不要踢出第一个Token。
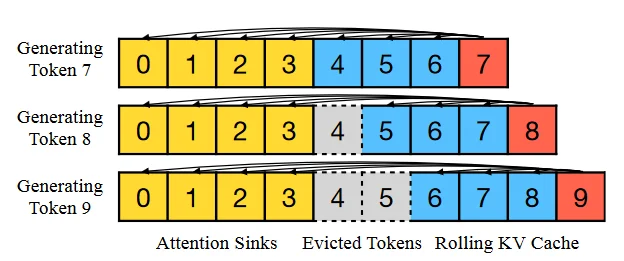
StreamingLLM框架的核心设计是将KV Cache分为两部分:
- Attention Sinks:永久保留最初的$S$个Token(实验表明4个足够)
- Rolling Cache:滑动窗口保留最近的$W$个Token
KV Cache = [Sink Tokens (固定)] + [Recent Tokens (滑动)]
这种设计保持了$O(1)$的显存占用(与序列长度无关),同时稳定了注意力分布。
位置编码的处理技巧
保留KV Cache还不够,还需要处理位置编码。如果Token原本在位置10000被生成,直接复用其Key向量会导致位置信息错乱。
StreamingLLM的解决方案是:在缓存中重新分配相对位置。
- Sink Tokens获得位置$0, 1, 2, 3$
- Rolling Cache中的Token获得位置$4, 5, ..., 4+W$
实际实现中,Key向量在应用RoPE之前被缓存。每次解码时,根据当前缓存内的相对位置重新应用旋转变换。这样,无论原始文本有多长,模型"看到"的始终是一个固定的短窗口。
400万Token的稳定性测试
论文报告了一个令人印象深刻的结果:StreamingLLM可以在长达400万Token的文本上保持稳定的困惑度。
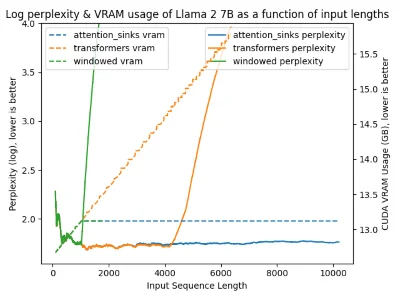
作为对比,Dense Attention在超过预训练长度后性能急剧下降,Window Attention在第一个Token被踢出时瞬间崩溃。只有StreamingLLM在整个测试过程中保持平稳。
效率方面,相比"滑动窗口重计算"方法(每生成一个Token都重新计算窗口内的所有KV),StreamingLLM实现了高达22.2倍的加速。
ICLR 2025:更深层的理解
2024年10月,Sea AI Lab的研究团队在论文《When Attention Sink Emerges in Language Models: An Empirical View》中系统性地研究了Attention Sink的出现条件。
几个关键发现:
训练过程的影响:Attention Sink并非模型架构的固有属性,而是在训练过程中涌现的。研究发现,只有当模型经过足够的优化、在充足的数据上训练后,Attention Sink才会稳定出现。
与损失函数的相关性:Sink的位置与训练目标高度相关。在标准语言建模中,第一个Token成为Sink;而在Prefix Language Modeling中,Sink出现在前缀Token中。
Key Bias的本质:论文提出Attention Sink更像是"Key Bias"——它们存储了额外的注意力分数,但对Value计算的贡献有限。这意味着Sink Token主要起到"稳定分母"的作用,而非提供语义信息。
Sigmoid Attention:另一种思路
既然Attention Sink的根源是Softmax的归一化约束,一个自然的问题是:能否改变注意力函数本身?
Sigmoid Attention提供了一个替代方案:
$$\alpha_i = \sigma(s_i) = \frac{1}{1 + e^{-s_i}}$$与Softmax不同,Sigmoid不强制权重之和为1。每个权重独立计算,不受其他Token的影响。研究发现,使用Sigmoid Attention的模型不会出现Attention Sink现象。
但这带来了新的权衡:去掉了归一化约束,模型的训练动态会发生变化,需要重新调优超参数。目前Softmax Attention仍然是主流选择。
工程实践:如何使用
StreamingLLM已被集成到多个主流推理框架中。
Hugging Face Transformers:通过attention_sinks库可以直接使用:
from attention_sinks import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
attention_sink_size=4, # 保留前4个Token作为Sink
attention_sink_window_size=1020, # 滑动窗口大小
device_map="auto"
)
vLLM框架:vLLM在实现KV Cache管理时考虑了Attention Sink的影响,通过分页管理支持流式推理。
关键配置参数:
attention_sink_size:Sink Token数量,默认4attention_sink_window_size:滑动窗口大小,影响显存占用和上下文长度
局限性与误区
尽管StreamingLLM解决了流式推理的稳定性问题,但有几个关键局限需要理解:
上下文窗口并未扩大:StreamingLLM让模型能够"跑得久",但并没有增加模型的"记忆容量"。如果第5000个Token需要参考第100个Token的信息,而窗口大小只有1024,模型仍然无法获取那个信息。
Sink Token数量是经验值:4个Sink Token是一个通过实验确定的安全值,覆盖了大多数分词器在开头可能插入的特殊Token。但对于特定模型,最优数量可能不同。
与长上下文技术的区别:StreamingLLM解决的是流式生成的稳定性问题,而非长文本理解问题。它应该与Context Extension技术(如长窗口微调、Ring Attention)结合使用,而非替代它们。
从技术洞察到工程创新
StreamingLLM的成功提供了一个重要的方法论启示:深入理解模型行为的底层机制,往往能带来简洁而有效的解决方案。
研究团队没有选择增加模型复杂度或重新训练,而是通过观察注意力分布的异常模式,找到了问题的数学根源——Softmax归一化与KV Cache管理的交互。最终的解决方案只需保留几个Token,却解决了困扰工业界已久的技术难题。
这个发现也影响了后续的模型设计。一些新的预训练方法开始显式地添加专用的"Sink Token",让模型在训练阶段就学会利用这个汇点。这可能会成为未来大模型预训练的标准范式。
参考文献
-
Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2023). Efficient Streaming Language Models with Attention Sinks. ICLR 2024. arXiv:2309.17453
-
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., … & Lin, M. (2024). When Attention Sink Emerges in Language Models: An Empirical View. ICLR 2025. arXiv:2410.10781
-
Ruscio, V., Nanni, U., & Silvestri, F. (2025). What are you sinking? A geometric approach on attention sink. arXiv preprint. arXiv:2508.02546
-
Gu, X., & Dao, T. (2024). No Attention Sink, No Massive Activations with Rectified Softmax. arXiv:2504.20966
-
Hugging Face Blog: Attention Sinks in LLMs for endless fluency. https://huggingface.co/blog/tomaarsen/attention-sinks