你有没有遇到过这样的情况:把一篇三万字的技术文档投给大模型,它告诉你"上下文长度超出限制";或者好不容易把文档拆成小块分别处理,却发现模型完全忘记了前面章节的内容,给出的分析前后矛盾。
这不是模型的"健忘",而是它的架构设计中存在一道无法逾越的鸿沟——上下文窗口限制。这个看似简单的问题,背后牵扯到Transformer架构的核心机制,以及过去七年学术界和工业界最激烈的技术博弈之一。
自注意力的代价:O(n²)诅咒
要理解上下文限制的根源,必须回到Transformer最核心的自注意力机制。
2017年,Google团队在《Attention Is All You Need》论文中提出了Transformer架构。与RNN逐个处理token不同,Transformer让序列中的每个token都能"看到"其他所有token,通过计算它们之间的相关性(注意力分数)来捕捉长距离依赖。这种设计的数学表达是:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$其中 $Q$(Query)、$K$(Key)、$V$(Value)分别是输入序列的三个线性变换。关键在于 $QK^T$ 这一步——对于一个长度为 $n$ 的序列,这会生成一个 $n \times n$ 的注意力矩阵,每个位置都需要与其他所有位置计算点积。
这就带来了一个无法回避的数学诅咒:计算复杂度是 $O(n^2)$。序列长度翻倍,计算量增长四倍;长度增加十倍,计算量增长百倍。更重要的是,这个 $n \times n$ 的矩阵必须完整存储在GPU显存中。对于128K token的上下文,即使使用FP16精度,单是一个注意力矩阵就需要约32GB显存——这还不包括模型参数、KV Cache等其他必需的存储。
2022年,斯坦福大学的研究团队在论文《On The Computational Complexity of Self-Attention》中给出了一个更令人沮丧的结论:基于强指数时间假设(SETH),自注意力的二次复杂度是本质性的,除非这个数学假设被推翻,否则不可能存在真正的亚二次精确注意力算法。
不过,这个理论天花板并没有阻止工程师们的尝试。2022年,斯坦福的Tri Dao团队提出了Flash Attention,通过"分块计算"(Tiling)和IO感知优化,将注意力计算的显存占用从 $O(n^2)$ 降到 $O(n)$。其核心思想是:不在GPU的高带宽内存(HBM)中存储完整的注意力矩阵,而是将计算分块后在更快的SRAM中完成,只保留最终输出。这使得训练时的上下文长度瓶颈从显存转移到了计算时间,为后来128K、200K甚至百万token上下文奠定了基础。
图片来源: LearnOpenCV
位置编码:模型如何知道"谁是谁的邻居"
解决了计算复杂度问题,还有另一道更隐蔽的关卡:位置编码。
Transformer的自注意力机制本质上是一个"集合"操作——它对输入序列的排列是不变的(permutation equivariant)。换句话说,如果你打乱输入token的顺序,自注意力输出的顺序也会相应打乱,但每个token的表示本身不会改变。这意味着模型天生无法区分"猫追狗"和"狗追猫"——除非你额外告诉它每个token的位置。
原始Transformer使用的是Sinusoidal位置编码,将位置索引编码为不同频率的正弦和余弦函数:
$$PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right)$$$$PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right)$$
这种编码方式有一个优雅的数学性质:两个位置的编码可以通过线性变换关联,使得模型能够学习相对位置关系。但它有一个致命弱点——它是一种"绝对位置编码",每个位置有一个固定的编码向量,训练时见过的位置和没见过的位置之间没有平滑过渡。
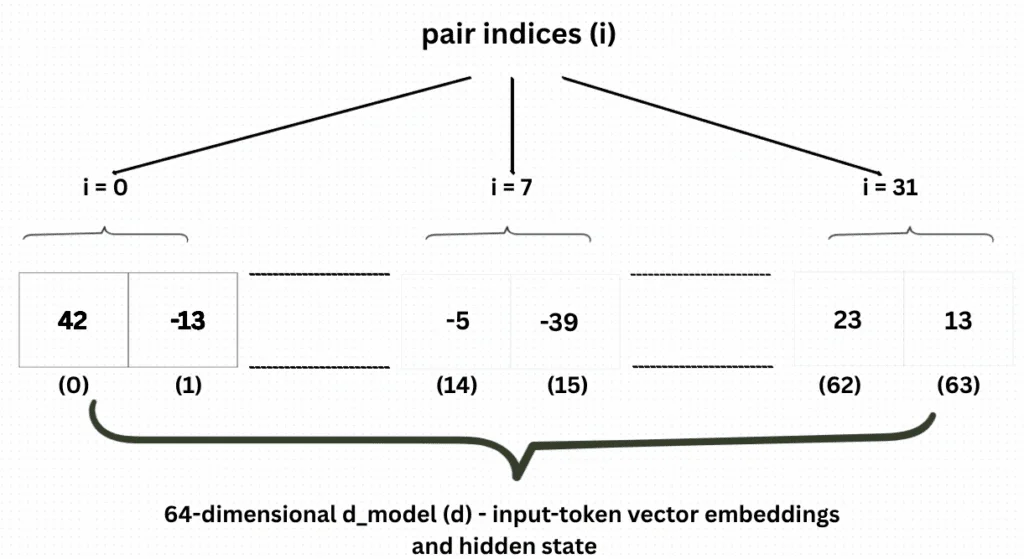
2021年,苏剑林在论文《RoFormer: Enhanced Transformer with Rotary Position Embedding》中提出了旋转位置编码(RoPE)。RoPE的核心思想是:不通过加法将位置信息注入embedding,而是通过乘法——用位置索引旋转Query和Key向量。具体来说,对于位置 $m$ 和 $n$ 的两个token:
$$(R_m \boldsymbol{q})^T (R_n \boldsymbol{k}) = \text{Re}\left[\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i}\right]$$关键观察:等式右边只依赖于相对位置 $m-n$,而不是绝对位置 $m$ 或 $n$。这意味着RoPE天然地编码了相对位置关系。
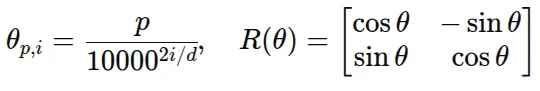
图片来源: LearnOpenCV
RoPE的另一个优势来自于它的"多时钟"设计。RoPE将向量维度分成 $d/2$ 组,每组对应一个不同的旋转频率 $\theta_i = 10000^{-2i/d}$。低索引的组(高频)旋转很快,可以精确区分相邻token;高索引的组(低频)旋转很慢,可以捕捉远程依赖。这种设计类似用多个不同精度的"时钟"同时测量位置,大大增强了位置编码的表达能力。
但问题在于:这些"时钟"在训练时只转过了一定的角度。当你把模型用于更长的序列时,低频时钟可能转到了训练时从未见过的角度——这就是位置编码的外推问题。
从外推到内插:突破上下文窗口的三条技术路线
假设一个模型在4096 token的序列上训练完成。当你给它输入第4097个token时,会发生什么?
对于Sinusoidal编码,第4097个位置的编码向量是训练时从未见过的——这是一个完全的分布外(Out-of-Distribution)输入,模型的注意力机制可能会产生不可预测的行为,导致困惑度(PPL)爆炸。对于RoPE,虽然理论上可以编码任意长的位置,但训练时见过的相对距离范围是有限的,超出这个范围同样会导致性能骤降。
方案一:位置插值(Position Interpolation, PI)
2023年6月,Meta在论文《Extending Context Window of Large Language Models via Positional Interpolation》中提出了一个朴素而有效的方案:不进行外推,而是内插。
具体做法是将输入位置索引线性压缩到训练范围内。如果训练长度是 $L_{train}$,想要扩展到 $L_{test}$,则将所有位置索引乘以因子 $L_{train}/L_{test}$:
$$pos_{new} = pos \times \frac{L_{train}}{L_{test}}$$这样,即使序列长度扩展到32K,每个token的"有效位置"仍然落在0-4096的范围内。Meta的实验显示,使用PI后,只需1000步微调就能让LLaMA模型有效利用32K上下文。
但PI有一个明显的缺陷:线性压缩会破坏局部位置关系。原本相邻的两个token,压缩后可能变成"半个位置"的差异,这会干扰模型对局部依赖的捕捉。
方案二:NTK感知缩放
2023年,一位网名为"bloc97"的研究者在Reddit社区提出了NTK-aware RoPE,其核心洞察来自RoPE的"多时钟"结构:
- 高频分量(低索引组)旋转快,在训练长度内已经转过很多圈,对它们来说,更大的位置只是"再多几圈",不存在外推问题
- 低频分量(高索引组)旋转慢,在训练长度内可能连一圈都没转完,外推会到达未训练过的角度
因此,解决方案是"高频外推、低频内插"——不是所有位置都使用相同的缩放因子,而是根据频率调整。具体来说,修改RoPE的base参数:
$$\theta_i^{new} = (10000 \cdot \kappa)^{-2i/d}, \quad \kappa = \left(\frac{L_{test}}{L_{train}}\right)^{d/(d-2)}$$这种方法可以在一定程度上免微调实现长度外推,但效果上限约为2倍训练长度,再长就会出现性能下降。
方案三:YaRN
2023年底,研究者在论文《YaRN: Efficient Context Window Extension of Large Language Models》中系统性地整合了前人的工作,并提出了更精细的缩放策略。
YaRN的关键改进是:不是简单地二分"高频"和"低频",而是为每个频率维度计算其"训练圈数" $r_i$:
$$r_i = \frac{\theta_i \cdot L_{train}}{2\pi}$$然后根据圈数动态调整缩放策略:圈数大于阈值的维度保持不变(已经充分训练),圈数小于1的维度进行内插,中间的维度平滑过渡:
$$\theta_i^{new} = \left[\gamma_i + (1 - \gamma_i)\frac{L_{train}}{L_{test}}\right]\theta_i$$此外,YaRN还引入了一个经验性的温度缩放因子:
$$\lambda = \left(1 + 0.1 \log \frac{L_{test}}{L_{train}}\right)^2$$这个因子可以缓解长上下文带来的注意力分数分布偏移问题。YaRN仅需约0.1%的原预训练数据微调,就能实现从4K到128K的上下文扩展,并且性能优于之前的所有方法。
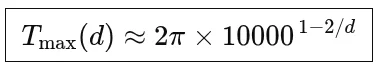
图片来源: LearnOpenCV
百万token时代:从工程优化到架构创新
当上下文扩展到百万token级别时,单纯的位置编码优化已经不够了,还需要系统性的工程创新。
Ring Attention:分布式注意力计算
2023年,伯克利的研究团队提出了Ring Attention,将长序列分割成多个块,分布在多个GPU上以环形方式传递和计算。每个GPU只需要存储局部块的KV Cache,然后将计算结果传递给下一个GPU。这种方式理论上可以实现无限长的上下文——只要你有足够的GPU。
GQA与KV Cache优化
分组查询注意力(Grouped Query Attention, GQA)是另一种降低长上下文成本的技术。标准的Multi-Head Attention中,每个注意力头都有独立的Key和Value;GQA将多个Query头共享同一组Key和Value头,从而减少KV Cache的存储量。LLaMA 2和LLaMA 3都采用了GQA,将KV Cache大小减少了约8倍。
线性注意力与SSM架构
更激进的方案是彻底抛弃二次复杂度的注意力机制。2023年底提出的Mamba架构,基于选择性状态空间模型(Selective State Space Model),将序列建模的复杂度降到了 $O(n)$。Mamba在预训练困惑度和下游任务上都能媲美同等规模的Transformer,同时推理速度更快、显存占用更低。这代表了一条可能取代Transformer的技术路线。
技术权衡:没有银弹的工程现实
回顾上下文扩展的技术演进,可以清晰地看到不同方案之间的权衡:
| 方案 | 核心思想 | 优势 | 代价 |
|---|---|---|---|
| Position Interpolation | 线性压缩位置索引 | 实现简单,微调量小 | 损失局部分辨率 |
| NTK-aware | 高频外推、低频内插 | 可免微调 | 外推能力有限 |
| YaRN | 动态频率缩放+温度调整 | 效果最佳,微调量极小 | 需要调整多个超参数 |
| Ring Attention | 分布式计算 | 理论无上限 | 通信开销大,延迟高 |
| GQA | 共享KV头 | 减少显存占用 | 轻微性能损失 |
| Mamba等SSM | 线性复杂度架构 | 推理快,显存低 | 生态不成熟,长程依赖能力存疑 |
更重要的是,即使技术上能够扩展上下文,也不意味着应该无限制地追求更长的窗口。研究表明,当上下文超过一定长度后,模型对中间部分信息的提取能力会显著下降——这被称为"Lost in the Middle"现象。在某些任务上,使用128K上下文的模型,其表现可能不如使用4K上下文+高效检索的系统。
2024年2月,微软团队在论文《LongRoPE》中首次将上下文扩展到了2048K(200万)token。他们发现,不同频率维度的最优缩放因子差异巨大,简单的统一缩放无法达到最佳效果。通过进化搜索为每个维度找到最优缩放因子,LongRoPE实现了近乎无损的百万token上下文扩展。
但这项技术仍然需要权衡:更长的上下文意味着更高的推理延迟和成本。在实际应用中,智能地压缩和检索历史信息,往往比简单地塞入更多上下文更有效。
尾声
大模型的上下文长度限制,本质上是Transformer架构设计的必然结果——自注意力的二次复杂度、位置编码的外推困境、KV Cache的显存压力,每一道都是工程师们艰难攀爬的山峰。
从2023年PI方法的提出,到YaRN的系统性优化,再到LongRoPE的百万token突破,这个领域在过去两年经历了爆发式的进步。但每一次突破都在提醒我们:没有免费的午餐。更长的上下文意味着更高的计算成本,更好的外推方法意味着更复杂的工程实现。
当你下次看到大模型告诉你"上下文超出限制"时,请记住:这背后是数学定理的硬约束、深度学习的软约束,以及无数工程师在两者之间寻找平衡的努力。而解决这个问题的终极答案,可能不是让模型记住更多内容,而是让它更聪明地忘记不重要的内容——就像人类的大脑一样。
参考资料
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864
- Chen, S., et al. (2023). Extending Context Window of Large Language Models via Positional Interpolation. arXiv:2306.15595
- Peng, B., et al. (2023). YaRN: Efficient Context Window Extension of Large Language Models. arXiv:2309.00071
- Dao, T., et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022
- Liu, H., et al. (2023). Ring Attention with Blockwise Transformers for Near-Infinite Context. arXiv:2310.01889
- Ding, Y., et al. (2024). LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens. arXiv:2402.13753
- Gu, A., & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752
- Press, O., et al. (2021). Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. arXiv:2108.12409
- 苏剑林. (2024). Transformer升级之路:16、“复盘"长度外推技术. 科学空间
- Liu, N. F., et al. (2024). Lost in the Middle: How Language Models Use Long Contexts. TACL 2024