2017年,Google Research发表了题为《Attention Is All You Need》的论文,Transformer架构从此横空出世。但论文标题中的"All You Need"隐含了一个不言自明的假设:你能够负担得起注意力的代价。
六年后的2023年,当研究者试图将模型的上下文窗口扩展到100K token时,这个假设开始崩塌。一个简单的事实浮出水面:标准自注意力机制的计算复杂度是 $O(n^2)$,这意味着上下文长度翻倍,计算量翻四倍。对于一台配备80GB显存的A100 GPU,处理一个包含100万token的序列需要约40PB的内存来存储注意力矩阵——这个数字比全球最大的数据中心单机存储容量还要大几个数量级。
这不是工程问题,这是数学问题。而数学问题只能用数学来解决,或者绕开。
平方级的诅咒
自注意力的计算过程可以概括为三个矩阵乘法:$S = QK^T$、$P = \text{softmax}(S)$、$O = PV$。其中Q、K、V分别是查询、键、值矩阵,维度为 $n \times d$,n为序列长度,d为隐藏维度。
问题的根源在于第一个操作:$QK^T$ 会产生一个 $n \times n$ 的注意力分数矩阵。当序列长度为1K时,这个矩阵有100万个元素;当序列长度扩展到100K时,元素数量暴增至100亿。更关键的是,softmax操作需要对这个矩阵的每一行进行归一化,这意味着整个矩阵必须同时存在于内存中。
标准实现的内存复杂度分析揭示了更深层的问题。前向传播需要存储整个注意力矩阵P用于反向传播,占用 $O(n^2)$ 内存。反向传播还需要计算对Q、K、V的梯度,其中涉及对softmax的微分,进一步增加了内存压力。
A100 GPU拥有80GB的HBM(高带宽内存),理论带宽约2TB/s。对于head dimension为128的注意力计算,当序列长度为16K时,仅注意力矩阵就需要约1GB的存储空间;当序列长度达到128K时,这个数字跃升至64GB——已经逼近单卡内存极限。
但这还不是全部。GPU的内存层次结构远比简单的"显存"复杂得多。现代GPU包含多级存储:HBM(高带宽内存,容量大但相对较慢)、L2缓存(中等容量和速度)、以及SRAM(片上共享内存,容量极小但带宽极高)。以A100为例,HBM带宽约2TB/s,而SRAM带宽高达约19TB/s——相差近10倍。
标准注意力实现将中间结果(QK^T和softmax输出)写入HBM,再从HBM读取进行后续计算。这种反复的HBM访问成为性能瓶颈。计算本身很快,但等待数据移动占据了大部分时间。这正是Flash Attention要解决的核心问题。
稀疏化:用空间换时间
第一个突破方向是"不做无用功"。既然注意力矩阵是 $n \times n$ 的,但并非所有位置都需要计算,能否只计算"重要"的位置?
2020年,OpenAI的Rewon Child等人提出了Sparse Transformer。核心思想是限制每个token只能关注部分位置,而非全部序列。论文设计了两种稀疏模式:stride模式让token关注固定步长的位置,fixed模式则关注序列开头和结尾的特定位置。这种设计将复杂度从 $O(n^2)$ 降至 $O(n\sqrt{n})$。
同年,AI2研究所的Iz Beltagy等人提出了Longformer,采用了更直观的滑动窗口注意力。每个token只关注其周围固定窗口内的token,复杂度降为 $O(n \cdot w)$,其中w是窗口大小。Longformer还引入了"dilated attention"——类似空洞卷积,在扩大感受野的同时保持计算效率。
Google Research的BigBird则结合了多种稀疏模式:随机注意力(随机选择部分位置关注)、窗口注意力(关注邻近位置)、全局注意力(特定token如[CLS]关注所有位置)。论文证明这种组合可以在理论上逼近完整的注意力矩阵,同时保持线性复杂度。
但稀疏注意力有一个根本性的权衡:你放弃了完整的注意力矩阵,也就放弃了某些信息传递路径。2023年发布的Mistral 7B采用了滑动窗口注意力,窗口大小为4096。在处理长文档时,位置0的token与位置5000的token之间没有直接的注意力连接,信息只能通过多层传播间接传递——类似于卷积神经网络中感受野逐层扩大的机制。
这种"信息扩散"机制在实践中证明了有效性,但也意味着稀疏注意力并非银弹。对于需要全局信息的任务(如文档级别的问答),稀疏模式可能无法捕捉关键的远程依赖。
线性化:重写注意力公式
如果稀疏化是"减少计算",那么线性化就是"换一种计算方式"。
2020年,Katharopoulos等人在论文《Transformers are RNNs》中提出了一个关键洞见:注意力的核心计算 $\text{softmax}(QK^T)V$ 可以被重写。如果将softmax分解为指数函数,并应用矩阵乘法的结合律:
$$\text{softmax}(QK^T)V = \text{softmax}(\phi(Q)\phi(K)^T)V$$其中 $\phi$ 是一个特征映射函数。关键在于,如果选择合适的 $\phi$,可以改变计算顺序:
$$\text{softmax}(QK^T)V \approx \phi(Q)(\phi(K)^T V)$$原本需要先计算 $n \times n$ 的矩阵,现在先计算 $d \times d$ 的矩阵——复杂度从 $O(n^2 d)$ 降为 $O(nd^2)$。
同年,Google Research的Choromanski等人提出了Performer,引入了FAVER+(Fast Attention Via positive Orthogonal Random features)方法。核心思想是使用随机特征来近似softmax核函数:
$$\text{softmax}(q^Tk) \approx \phi(q)^T\phi(k)$$其中 $\phi(x)$ 使用随机投影将输入映射到高维空间,使得点积近似于softmax核。Performer在理论上保证了近似质量,并在多项长序列任务上验证了有效性。
然而,线性注意力在实践中面临一个尴尬的现实:尽管复杂度降低了,但模型质量往往也会下降。线性近似意味着损失了softmax的精确计算,对于某些对精度敏感的任务,这种损失可能影响最终效果。因此,大规模模型训练中,线性注意力的采用率相对有限。
IO感知:重新审视硬件
2022年5月,斯坦福大学的Tri Dao等人发表了Flash Attention,开创了一条全新的优化路径。
Flash Attention的核心洞见是:瓶颈不在计算,而在数据移动。与其改变注意力计算的数学公式,不如重新设计算法以适应GPU的内存层次结构。
GPU执行计算的时间可以用一个简单的公式估算:
$$T = \max(T_{compute}, T_{memory})$$其中 $T_{compute}$ 是纯计算时间,$T_{memory}$ 是内存访问时间。对于注意力计算,A100的FP16算力约312 TFLOPS,但内存带宽只有约2 TB/s。当序列长度为8K、head dimension为128时:
- 计算量:约 $4 \times 8K^2 \times 128 = 33.5$ GFLOPS
- 内存访问量:需要多次读写 $n \times n$ 的注意力矩阵,约 $n^2 \times 4$ bytes $\times$ 读写次数
简单的计算表明,内存访问时间远超计算时间——这是一个内存受限的操作。
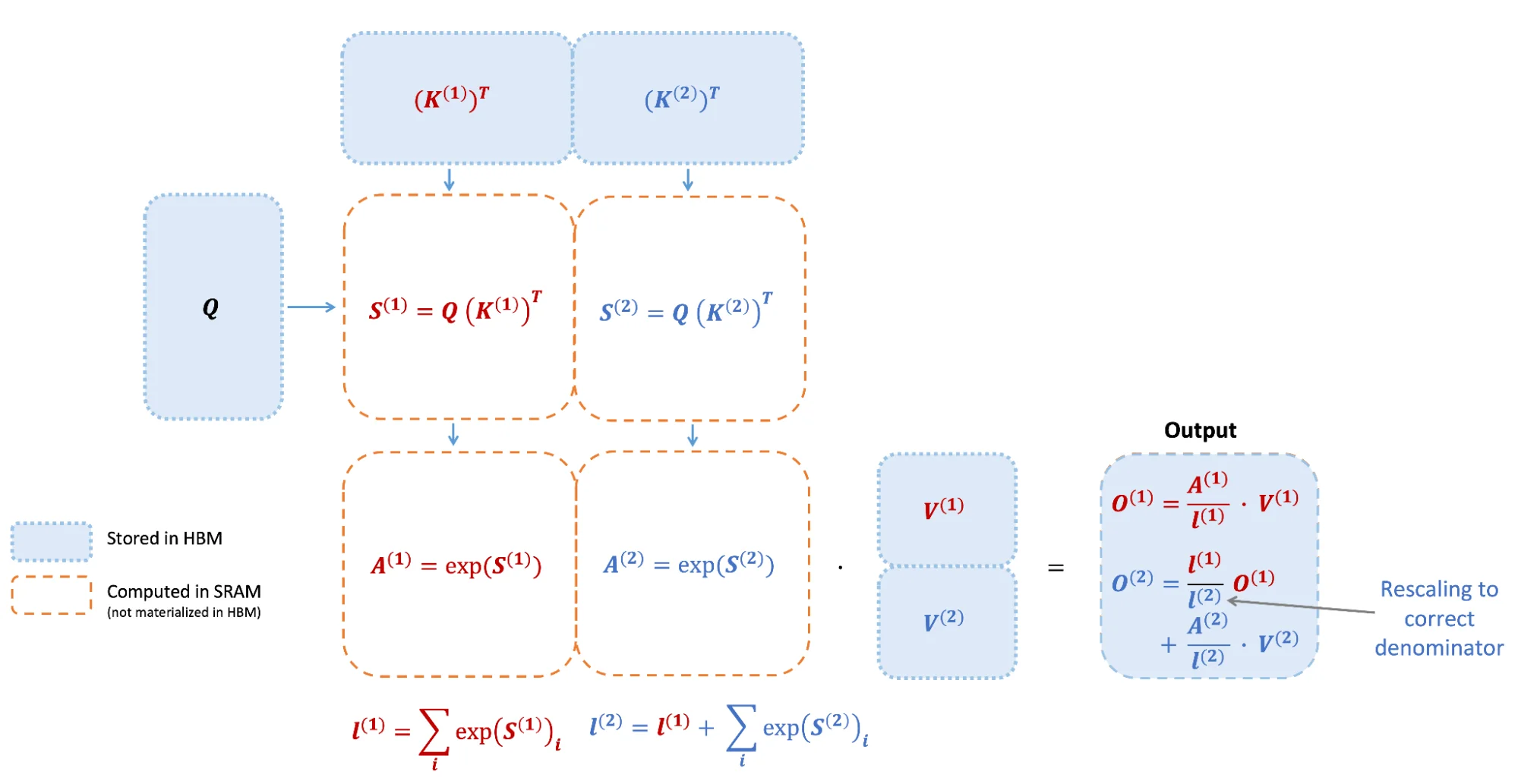
Flash Attention的解决方案是分块计算(Tiling):将Q、K、V矩阵分成小块,每块大小足以放入SRAM(A100上约192KB)。在SRAM内完成注意力的完整计算,只将最终结果写回HBM。
关键的技术挑战在于softmax。Softmax需要对整行进行归一化,而行跨越多个块。Flash Attention采用了"在线softmax"技术,通过维护运行时的最大值和指数和,在不完整计算的情况下得到正确结果。
具体而言,对于注意力矩阵的两个块 $S_1$ 和 $S_2$,传统方法需要:
$$m = \max(\max(S_1), \max(S_2))$$$$\ell = \text{sum}(e^{S_1 - m}) + \text{sum}(e^{S_2 - m})$$
$$O = (e^{S_1 - m} \cdot V_1 + e^{S_2 - m} \cdot V_2) / \ell$$
Flash Attention将这个过程分解为可增量更新的形式,在遍历K、V块的过程中逐步更新输出,无需存储完整的注意力矩阵。
图片来源: princeton-nlp.github.io
结果令人印象深刻:Flash Attention将内存复杂度从 $O(n^2)$ 降为 $O(n)$,同时在A100上实现了2-4倍的端到端加速。更重要的是,它没有改变注意力的计算结果——这是一种精确优化,而非近似。
2023年7月,Dao发布了Flash Attention 2,进一步优化了GPU利用率。原版Flash Attention在A100上仅能达到约30-50%的理论峰值FLOPS,Flash Attention 2通过改进线程块间的工作分配和减少共享内存读写,将利用率提升至50-73%。在GPT-2训练中,端到端加速达到2倍。
2024年7月,Flash Attention 3针对NVIDIA Hopper架构(H100)进行了深度优化。新架构引入了Tensor Memory Accelerator(TMA)和异步Tensor Core操作,Flash Attention 3利用这些特性实现了:
- Warp特化:将线程分为"生产者"(负责数据加载)和"消费者"(负责计算),利用异步操作重叠数据传输和计算
- 流水线softmax:将softmax计算与矩阵乘法并行执行
- FP8支持:利用Hopper的FP8 Tensor Core,在保持精度的同时实现近2倍的吞吐量
Flash Attention 3在H100上达到了740 TFLOPS/s的FP16吞吐量(理论峰值的75%),以及近1.2 PFLOPS/s的FP8吞吐量。
分布式:突破单卡限制
当单卡内存无法容纳超长序列时,分布式计算成为必然选择。但注意力的 $O(n^2)$ 特性使得简单的数据并行不再适用——你无法将一个 $n \times n$ 的矩阵切分到多张卡上而不产生大量的跨卡通信。
2023年10月,斯坦福大学的Hao Liu等人提出了Ring Attention,巧妙地解决了这个问题。
Ring Attention的核心思想是:将序列切分为块,分配到不同的GPU上,每张GPU持有自己负责的Query块和完整的Key-Value块。但K、V不需要同时存在——可以通过"环形"通信模式,让K、V块在GPU间依次传递。
具体流程如下:
- GPU i 持有 Query 块 $Q_i$ 和 Key-Value 块 $K_i, V_i$
- 在第一个step,每个GPU用本地的 $K_i, V_i$ 计算部分注意力
- 然后,GPU i 将 $K_i, V_i$ 发送给 GPU (i+1),同时接收来自 GPU (i-1) 的 $K_{i-1}, V_{i-1}$
- 重复上述过程,直到每个GPU都"看到"所有的Key-Value块
这种设计的关键优势在于:通信(发送/接收K、V块)可以与计算(注意力计算)并行进行,隐藏了通信开销。理论上,只要有足够的GPU,Ring Attention可以处理任意长度的序列。
论文报告的基准测试显示,在512张A100 GPU上,Ring Attention可以处理长度达1亿token的序列。这为"无限上下文"打开了理论可能。
但Ring Attention也有局限:它依赖于高速的GPU间互连(如NVLink或InfiniBand),通信延迟会直接影响整体性能。此外,随着GPU数量增加,负载均衡成为挑战——如果某些位置的注意力计算更密集,部分GPU可能处于空闲状态。
推理优化:减少KV Cache
训练时的优化是一方面,推理时的挑战同样严峻。在自回归生成中,每生成一个token都需要计算它与之前所有token的注意力,这意味着需要存储之前所有token的Key和Value——这就是KV Cache。
对于标准的多头注意力(Multi-Head Attention, MHA),假设hidden dimension为 $d_{model}$,num_heads为 $h$,序列长度为 $n$,则KV Cache的大小为:
$$\text{KV Cache Size} = 2 \times n \times h \times d_{head} \times \text{sizeof(float16)}$$对于GPT-3规模的模型($d_{model}=12288$, $h=96$),处理32K上下文需要约24GB的KV Cache——这还只是存储,不包括计算。
2019年,Google的Noam Shazeer提出了Multi-Query Attention (MQA):让所有Query head共享同一组Key和Value head。这将KV Cache的大小减少了 $h$ 倍。代价是模型表达能力可能下降,但在实践中这种下降往往可以接受。
2023年,Google Research提出了Grouped-Query Attention (GQA),在MHA和MQA之间取得平衡。GQA将Query heads分成若干组,每组共享一组Key-Value heads。例如,对于32个Query heads,可以分成8组,每组4个heads共享K、V,KV Cache大小为MHA的1/4,同时保留了比MQA更强的表达能力。
这些优化直接影响了实际部署。使用GQA的模型在长上下文推理时,可以将KV Cache压缩到原来的1/8甚至更小,大幅降低了显存压力和推理成本。
位置编码:扩展而非重建
注意力优化解决的是计算瓶颈,但还有另一个问题:如何让模型理解超长的位置关系?
原始Transformer使用绝对位置编码,将位置信息直接加到输入embedding上。这种设计有一个隐含假设:训练时见过的最大位置决定了推理时能够处理的最大长度。如果训练时只见过2048个位置,推理时就无法处理更长的序列——超出部分的位置编码是未定义的。
2021年,苏剑林等人提出了RoPE(Rotary Position Embedding),采用相对位置编码的思想。RoPE通过旋转矩阵将位置信息融入Query和Key,使得注意力分数只依赖于token之间的相对位置差,而非绝对位置。
RoPE的一个关键特性是"外推性":通过适当的位置插值,可以将训练时的上下文窗口扩展到更长的推理长度。2023年,多个研究团队提出了RoPE的扩展方法:
- Position Interpolation (PI):将位置索引线性缩放到训练范围内
- NTK-aware Scaled RoPE:根据神经正切核理论调整缩放因子
- YaRN (Yet another RoPE extensioN):结合上述方法,进一步优化长上下文性能
这些方法使得预训练模型可以在不重新训练的情况下扩展上下文窗口。例如,通过YaRN,一个训练时只见过4K上下文的模型可以在推理时处理128K的序列,同时在长上下文任务上保持较好的性能。
权衡的艺术
没有免费的午餐。每一种优化都伴随着权衡:
| 方法 | 复杂度 | 内存 | 精度影响 | 适用场景 |
|---|---|---|---|---|
| 标准注意力 | $O(n^2 d)$ | $O(n^2)$ | 无 | 短序列 |
| 稀疏注意力 | $O(n \cdot w \cdot d)$ | $O(n \cdot w)$ | 中等 | 长序列,局部依赖 |
| 线性注意力 | $O(nd^2)$ | $O(nd)$ | 较高 | 超长序列,精度要求不高 |
| Flash Attention | $O(n^2 d)$ | $O(n)$ | 无 | 通用,硬件支持 |
| Ring Attention | $O(n^2 d/p)$ | $O(n/p)$ | 无 | 分布式超长序列 |
Flash Attention的成功在于它是一种"精确优化"——不改变计算结果,只改变计算方式。这使得它成为当前大规模模型训练的默认选择。从GPT-4到Llama 3,几乎所有主流大模型都采用了Flash Attention或其变体。
稀疏注意力在特定场景下仍有价值。Mistral的滑动窗口注意力证明了:对于大多数自然语言任务,局部依赖远比全局依赖重要。一个4096的窗口已经能够覆盖绝大多数有意义的语义关系。
线性注意力则面临更艰难的处境。尽管复杂度更优,但精度损失使得它在追求最高质量的场景中难以立足。一个有趣的观察是:当序列长度超过100K时,线性注意力的优势才会真正显现——但这个长度目前只有极少数应用场景需要。
尚未结束的探索
注意力优化的故事还在继续。2023年底,卡内基梅隆大学的Albert Gu等人提出了Mamba,一种基于状态空间模型(SSM)的架构,理论上实现了线性复杂度,同时在多项任务上匹敌Transformer。Mamba的出现提出了一个根本性问题:注意力是必需的吗?
但答案并非非此即彼。2024年发布的Jamba模型将Mamba层与注意力层混合使用,在保持线性复杂度的同时保留了注意力的某些优势。这暗示着未来的架构可能是多种机制的融合。
从2017年的原始Transformer到2024年的Flash Attention 3,注意力优化的历程折射出AI发展的一个核心主题:理论与实践的对话。O(n²)的复杂度是理论约束,但GPU的内存层次结构提供了突破这个约束的工程路径。Ring Attention将单卡限制转化为分布式优势,RoPE扩展将训练约束转化为推理可能。
当注意力不再成为瓶颈,上下文窗口的边界正在被不断推远。从最初的512 token到如今的100K+,这个数字背后是无数次算法与硬件的协同进化。而每一次边界的突破,都为AI解锁了新的应用场景:长文档理解、代码仓库分析、多轮对话记忆、视频理解…
问题从来不是"注意力是否足够",而是"我们能为注意力付出多少"。当这个代价被不断降低,注意力的价值便得以充分释放。
参考文献
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS.
- Dao, T., et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS.
- Dao, T. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.
- Dao, T., et al. (2024). FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. NeurIPS.
- Liu, H., et al. (2023). Ring Attention with Blockwise Transformers for Near-Infinite Context.
- Choromanski, K., et al. (2020). Rethinking Attention with Performers. ICLR.
- Katharopoulos, A., et al. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. ICML.
- Beltagy, I., et al. (2020). Longformer: The Long-Document Transformer.
- Zaheer, M., et al. (2020). Big Bird: Transformers for Longer Sequences. NeurIPS.
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need.
- Ainslie, J., et al. (2023). GQA: Training Generalized Multi-Query Transformer Models.
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding.
- Peng, B., et al. (2023). YaRN: Efficient Context Window Extension of Large Language Models.