大模型训练的显存瓶颈如何突破:从ZeRO到Flash Attention的五年技术演进
显存墙:大模型训练的第一道坎 2020年,OpenAI训练GPT-3时,1750亿参数的模型需要超过350GB的显存——这远超任何单张GPU的容量。三年后,Meta训练Llama 2-70B时,单张A100 80GB显卡甚至无法完整加载模型权重。显存,而非计算能力,已经成为大模型训练的首要瓶颈。 ...
显存墙:大模型训练的第一道坎 2020年,OpenAI训练GPT-3时,1750亿参数的模型需要超过350GB的显存——这远超任何单张GPU的容量。三年后,Meta训练Llama 2-70B时,单张A100 80GB显卡甚至无法完整加载模型权重。显存,而非计算能力,已经成为大模型训练的首要瓶颈。 ...
你花了数天清洗数据,精心调参,终于启动了训练。Loss曲线漂亮地下降,一切似乎都很顺利。突然,屏幕上跳出一个刺眼的 nan——整个训练过程在瞬间崩溃。 ...
在Transformer架构中,注意力机制让每个token都能"看见"序列中的所有其他token。但有时候,我们恰恰需要某些token"看不见"其他token——这正是Attention Mask存在的意义。这个看似简单的矩阵,承担着因果性保证、填充处理、计算优化等多重职责,是理解Transformer工作方式的关键入口。 ...
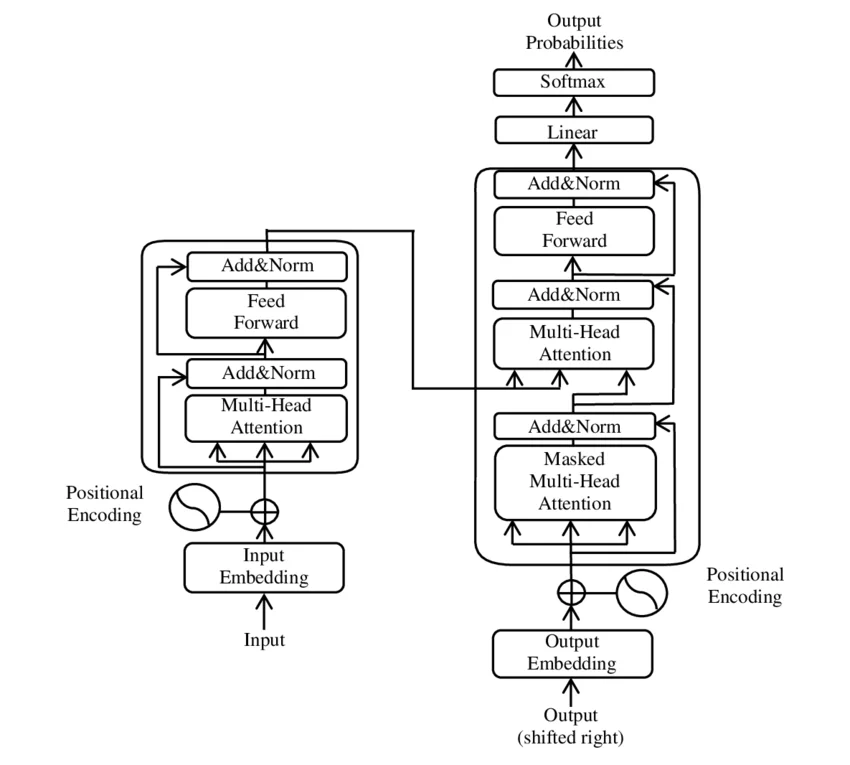
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...
2023年10月,伯克利大学的研究团队提交了一篇论文,声称可以让Transformer处理"接近无限"长度的上下文。实验数据令人咋舌:在512块TPU v4上,7B模型可以训练超过800万Token的序列;在1024块TPU v4上,这个数字飙升到1600万。 ...
2023年,当大模型的上下文窗口从4K扩展到128K甚至更长时,一个看似不可逾越的技术障碍横亘在研究者和工程师面前:注意力机制的计算复杂度随序列长度呈二次方增长。处理一个16K token的序列,光是注意力矩阵就要占用近1GB显存;64K序列的注意力矩阵更是超过16GB,直接撑爆了当时最顶级GPU的内存容量。 ...
你有没有遇到过这样的情况:把一篇三万字的技术文档投给大模型,它告诉你"上下文长度超出限制";或者好不容易把文档拆成小块分别处理,却发现模型完全忘记了前面章节的内容,给出的分析前后矛盾。 ...