一个拥有1750亿参数的语言模型,每次生成一个token都需要从内存读取超过700GB的权重数据——但实际执行的计算量却让GPU大部分时间处于空闲状态。这种"内存等待计算"的倒挂现象,是大模型推理速度的根本瓶颈。
2022年,Google研究院发表了一篇题为《Fast Inference from Transformers via Speculative Decoding》的论文,提出了一个反直觉的加速思路:用一个小模型先"猜"出接下来的几个token,然后用大模型并行验证。这个看似增加额外工作的方案,最终实现了2-3倍的推理加速,且保证输出分布与原始模型完全一致。
三年后的2025年,EAGLE-3将这一加速比推高到了6.5倍。投机解码已成为现代LLM推理系统的标配技术,被Google搜索、vLLM、TensorRT-LLM等主流框架广泛采用。
内存带宽:大模型推理的真正瓶颈
理解投机解码的价值,首先要理解LLM推理为什么慢。
在GPU上执行计算主要涉及两类资源:计算单元(执行矩阵乘法、激活函数等操作)和内存带宽(在HBM高带宽内存与计算单元之间传输数据)。现代GPU如A100的计算能力可达312 TFLOPS(BF16),但内存带宽仅为2TB/s——两者相差约150倍。
这意味着,当模型参数量超过GPU显存时,每个token生成都需要完整的权重传输。以175B模型为例:
- 权重体积:175B参数 × 2字节/参数(FP16)= 350GB
- 单次前向传播内存传输:至少350GB(实际更多,包括激活值)
- 理论传输时间:350GB ÷ 2TB/s ≈ 175ms
而实际执行的计算量呢?对于seq_len=1的推理场景,矩阵乘法的计算量远小于GPU的计算能力。研究发现,现代GPU在LLM推理时的计算利用率通常低于10%——绝大部分时间都在等待数据从内存传输过来。

图片来源: Google Research - Looking back at speculative decoding
上图清晰地展示了这一矛盾:Transformer架构的每个token生成都需要读取全部权重(Operation #1),但实际执行的操作量远低于GPU的计算能力(Operation #2)。这种"内存受限"的特性,是投机解码能够发挥作用的前提——既然计算资源大量闲置,为什么不用它来并行处理更多token?
从投机执行到投机采样
投机解码的思想源于CPU架构中的投机执行(Speculative Execution)技术。现代CPU在遇到分支指令时,会预测分支走向并提前执行相应代码。如果预测正确,就能节省等待时间;如果预测错误,则丢弃结果重新执行。
将这个思想应用到LLM推理面临一个核心挑战:LLM输出的是概率分布而非确定性结果。从分布中采样本身具有随机性——即使小模型完美预测了大模型的分布,采样结果也可能不同。
Google团队提出的投机采样(Speculative Sampling)算法巧妙地解决了这个问题。核心思想是:用小模型快速生成候选token序列,然后用大模型并行验证并决定接受或拒绝。
算法流程
假设目标模型(大模型)的概率分布为 $p(x)$,草稿模型(小模型)的分布为 $q(x)$。投机解码的完整流程如下:
起草阶段:草稿模型自回归生成 $K$ 个候选token:$x_1, x_2, ..., x_K$,记录每个token的概率 $q(x_i|x_{ 验证阶段:目标模型对整个输入序列(原始前缀 + 候选token)进行一次前向传播,获得所有位置的概率分布 $p(x_i|x_{ 接受/拒绝阶段:对每个候选token $x_i$,以概率 $\alpha_i$ 决定是否接受:
图片来源: NVIDIA Technical Blog
上图的动画展示了完整流程:草稿模型快速生成"Brown"、“Fox”、“Hopped”、“Over"四个候选token,目标模型在一次前向传播中验证它们。由于"Hopped"的概率低于草稿模型的预测,它被拒绝;最终输出"Brown Fox”,并由目标模型生成下一个token"Jumped"。
接受率:决定加速效果的关键指标
投机解码的加速比取决于两个因素:接受率(Acceptance Rate)和推测长度(Speculation Length)。
接受率 $\beta$ 定义为草稿token被目标模型接受的概率。根据理论推导:
$$\beta = 1 - D_{TV}(p, q)$$其中 $D_{TV}(p, q) = \frac{1}{2}\sum_x |p(x) - q(x)|$ 是全变差距离。这个公式揭示了一个直观的结论:草稿模型与目标模型的分布越接近,接受率越高。
加速比的理论上限可以近似为:
$$\text{Speedup} \approx \frac{1 + \beta \cdot K}{1 + \frac{T_d}{T_t} \cdot K}$$其中 $K$ 是推测长度,$T_d$ 是草稿模型单步时间,$T_t$ 是目标模型单步时间。当 $T_d \ll T_t$ 且 $\beta$ 较高时,加速比趋近于 $1 + \beta \cdot K$。
实际数据表明,当接受率低于60%时,推测解码的收益开始被验证开销抵消。因此,选择合适的草稿模型至关重要——太小会降低接受率,太大会增加起草时间。
| 接受率 | 推测长度 K=4 | 推测长度 K=8 | 实际加速比 |
|---|---|---|---|
| 90% | 4.6 | 8.2 | 2.8x |
| 75% | 3.5 | 5.1 | 2.1x |
| 50% | 2.0 | 2.5 | 1.2x |
| 30% | 1.3 | 1.4 | <1.0x |
表格来源:根据Leviathan等人论文及后续研究整理
技术演进:从独立草稿模型到自投机
投机解码提出后,研究社区迅速发展出多种变体,核心优化方向是消除独立草稿模型的依赖。
Medusa:多头解码的优雅方案
2024年1月,Together.ai团队提出了Medusa。核心创新是在目标模型的最后一层隐藏状态上添加多个解码头,每个头预测不同位置的未来token。
标准语言模型头只预测下一个token,而Medusa添加了额外的头分别预测"下下个"、“下下下个"token。这些头可以通过轻量级微调训练,且原始模型权重保持冻结。
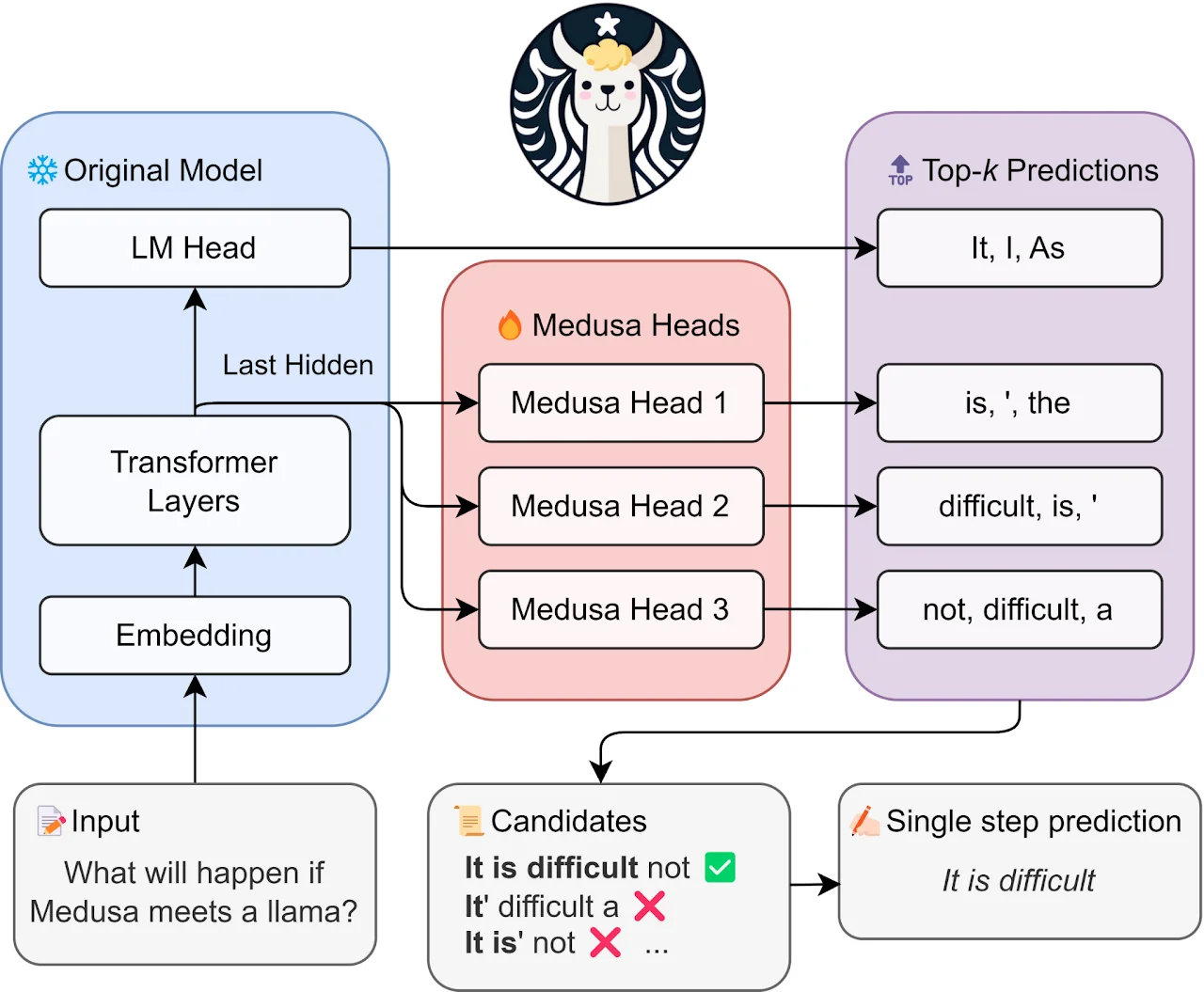
图片来源: Together.ai Blog
Medusa的优势在于:
- 无需独立草稿模型:避免了模型选择和维护的复杂性
- 参数高效:每个解码头仅包含一个前馈层,训练成本极低
- 推理无额外开销:解码头与主模型共享计算
为了充分利用多个候选token,Medusa引入了树形注意力机制(Tree Attention)。每个解码头的top-k预测组成一个候选树,通过定制的注意力掩码实现并行验证。
实验显示,Medusa在Vicuna模型上实现了约2倍的加速。更重要的是,这种方法在高温度采样(temperature > 0)场景下表现更优——当模型需要生成"创造性"输出时,Medusa的典型接受策略反而比贪婪解码更快。
EAGLE:特征级自回归
Medusa直接预测token,而EAGLE(Extrapolation Algorithm for Greater Language-model Efficiency)选择了另一条路径:在特征层面进行自回归预测。
EAGLE的洞察是:目标模型的顶层特征(logits之前)已经包含了丰富的语义信息。利用这些特征,可以更准确地预测未来token。具体而言,EAGLE训练一个轻量级网络,输入当前特征序列,输出下一个特征预测,然后通过目标模型的LM头获得token分布。
EAGLE-2进一步引入了动态草稿树。根据草稿模型的置信度动态调整树的结构——对于"容易预测"的位置,生成更长的候选分支;对于"困难"的位置,提前终止。这种自适应策略显著提高了验证效率。
EAGLE-3:多层融合与训练时测试
2025年3月发布的EAGLE-3代表了当前投机解码技术的最高水平,实现了高达6.5倍的加速比。
EAGLE-3的核心改进有两点:
移除特征预测约束:原始EAGLE要求草稿网络预测目标模型的顶层特征,这实际上是一种额外约束。EAGLE-3直接预测token,释放了草稿网络的表达能力。
多层特征融合:不再仅依赖顶层特征,而是融合目标模型的低层、中层、高层特征。不同层的特征捕获了不同抽象级别的语义信息——低层关注局部模式,高层理解全局上下文。融合这些信息使草稿网络获得更丰富的预测依据。
flowchart TB
subgraph 目标模型
L1[低层特征] --> L2[中层特征] --> L3[高层特征]
end
L1 --> F[特征融合层]
L2 --> F
L3 --> F
F --> D[草稿网络]
D --> T[候选Token树]
T --> V[目标模型验证]
V --> A[接受/拒绝]
EAGLE-3的另一项创新是训练时测试(Training-Time Test)。在训练过程中模拟推理时的多步预测场景,让草稿网络学会处理自身预测作为输入的情况。这解决了"分布偏移"问题——推理时草稿网络的输入包含自己之前的输出,这与训练时的真实特征存在差异。
| 模型 | 方法 | MT-bench加速 | GSM8K加速 | 平均加速 |
|---|---|---|---|---|
| LLaMA-3.1-8B | 标准投机解码 | 1.93x | 2.23x | 1.92x |
| LLaMA-3.1-8B | Medusa | 2.07x | 2.50x | 2.12x |
| LLaMA-3.1-8B | EAGLE | 3.07x | 3.58x | 3.05x |
| LLaMA-3.1-8B | EAGLE-2 | 4.26x | 4.96x | 4.22x |
| LLaMA-3.1-8B | EAGLE-3 | 5.58x | 6.47x | 5.51x |
数据来源: EAGLE-3论文
实践中的权衡与选择
投机解码并非万能良药。在应用时需要考虑以下权衡:
批处理场景的收益递减
投机解码的加速效果主要来自减少内存访问次数。当批处理大小增加时,GPU计算资源被更充分地利用,内存瓶颈减轻,投机解码的收益也随之下降。
实验显示,在批处理大小超过32时,标准投机解码的加速效果开始衰减;批处理大小达到64时,某些情况下甚至会出现负收益。EAGLE-3通过更高效的验证机制,将有效加速范围扩展到批处理大小56左右。
任务特性的影响
不同任务的加速效果差异显著:
- 代码生成:加速效果最好,因为代码有大量固定模式和重复结构
- 数学推理:次之,推理过程有规律可循
- 创意写作:相对较低,需要更多"意外"和多样性
这意味着,对于面向特定任务的部署,需要根据实际工作负载评估投机解码的价值。
实现复杂度
从工程角度,各种方法的实现复杂度差异明显:
| 方法 | 需要独立模型 | 训练成本 | 框架支持 |
|---|---|---|---|
| 标准投机解码 | 是 | 无(使用现成小模型) | vLLM, TensorRT-LLM |
| Medusa | 否 | 低(微调解码头) | vLLM |
| EAGLE系列 | 否 | 中(训练草稿网络) | TensorRT-LLM |
对于快速验证,使用现成的小模型作为草稿模型是最简单的起点。对于生产部署,Medusa或EAGLE的方案能提供更稳定的高加速比。
深层启示:为什么投机解码有效?
投机解码的成功揭示了一个深层次的规律:大模型在"简单"token上的预测能力,远超其实际表现所需。
Google原始论文中举了一个形象的例子:生成"7的平方根是____“这句话,“7"这个token几乎是"免费"的——上下文中已经出现过"square root of”,复制即可。而"2.646"这个精确值才是真正需要模型能力的部分。
这意味着,大模型的大量计算实际上是在"重复工作”——用千亿参数验证那些本可以由小模型正确预测的token。投机解码通过分工,让大模型专注于真正需要其能力的"困难"决策,从而大幅提升整体效率。
更深层地,这触及了LLM推理的本质问题:当前的Transformer架构是否存在内在的低效性? 如果一个千亿参数模型的输出可以通过更小模型"逼近”,那么这些参数是否真正被有效利用?
投机解码是一个实用的答案,但可能不是最终答案。未来的架构设计——如混合专家模型(MoE)、条件计算、动态深度——可能从更根本上解决这个问题。在此之前,投机解码将继续作为LLM推理加速的基石技术,支撑着从聊天机器人到代码助手的各类应用。
参考文献
-
Leviathan, Y., Kalman, M., & Matias, Y. (2023). Fast Inference from Transformers via Speculative Decoding. ICML 2023.
-
Cai, T., et al. (2024). Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads. ICML 2024.
-
Li, Y., et al. (2024). EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty. ICML 2024.
-
Li, Y., et al. (2025). EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test. arXiv:2503.01840.
-
Chen, C., et al. (2023). Accelerating Large Language Model Decoding with Speculative Sampling. arXiv:2302.01318.
-
Stern, M., Shazeer, N., & Uszkoreit, J. (2018). Blockwise Parallel Decoding for Deep Autoregressive Models. NeurIPS 2018.