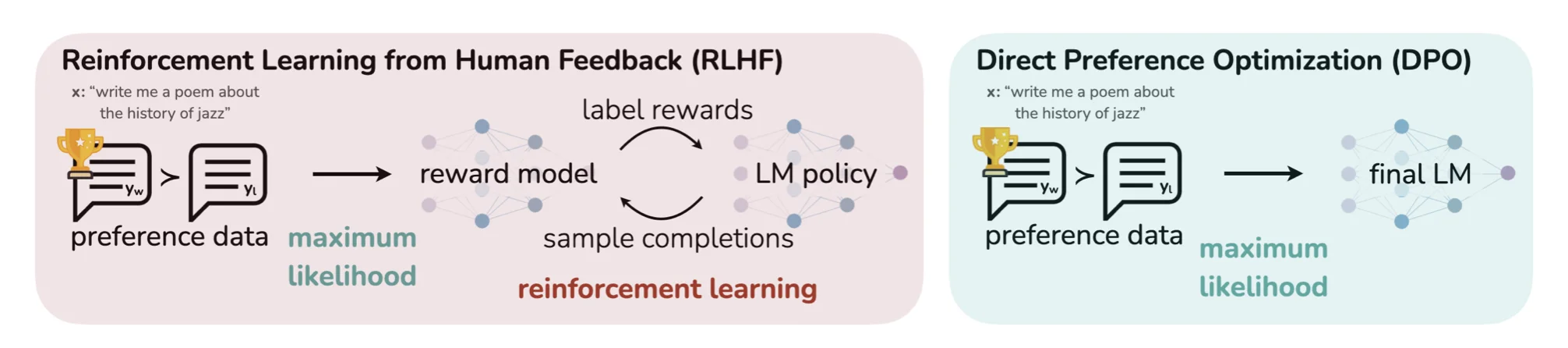
2022年,ChatGPT的成功让"人类反馈强化学习"(RLHF)成为大模型训练的标配流程。但很少有人知道,这个流程在工程实现上有多么脆弱——PPO训练需要精心调校的学习率、KL散度系数、价值函数裁剪范围等超参数,稍有不慎就会导致模型崩溃或性能退化。一位资深工程师曾调侃:“调PPO比调女朋友还难。”
2023年5月,斯坦福大学团队发表了一篇论文,提出了一个看似简单的想法:如果语言模型本身就是一个奖励模型,为什么还要单独训练一个?这个洞察催生了直接偏好优化(Direct Preference Optimization, DPO),它将RLHF的三阶段流程压缩为一步,用简单的交叉熵损失替代了复杂的强化学习。
两年后的今天,DPO已成为大模型对齐的事实标准。Zephyr、Tülu、NeuralChat等知名开源模型都采用DPO进行偏好对齐。但DPO的数学原理究竟是什么?它如何避免RLHF的复杂性?又有哪些变体方法?本文将从偏好建模的基础理论出发,逐步揭示DPO的技术内核。
偏好建模的数学基础:Bradley-Terry模型
理解DPO,首先要理解人类偏好是如何被数学建模的。
假设我们给同一个提示词$x$生成了两个回答$y_1$和$y_2$,然后让人类标注员判断哪个更好。这是一个成对比较问题。1952年,统计学家Bradley和Terry提出了一个优雅的解决方案:假设每个回答都有一个潜在的"质量分数"(可以理解为奖励值),人类选择$y_1$而非$y_2$的概率服从:
$$p(y_1 \succ y_2 | x) = \frac{\exp(r(x, y_1))}{\exp(r(x, y_1)) + \exp(r(x, y_2))}$$其中$r(x, y)$是奖励函数,表示在给定提示词$x$下回答$y$的质量。这个公式可以简化为:
$$p(y_1 \succ y_2 | x) = \sigma(r(x, y_1) - r(x, y_2))$$这里$\sigma(\cdot)$是sigmoid函数。Bradley-Terry模型的核心思想是:偏好的概率取决于奖励值之差。如果两个回答的奖励值相差很大,选择概率就接近1;如果相差很小,选择概率就接近0.5。
这个模型在体育比赛中也有广泛应用——国际象棋的Elo等级分系统本质上就是Bradley-Terry模型的一个实例。两位棋手的胜率取决于他们的等级分之差。
RLHF的传统流程及其困境
有了偏好模型,传统的RLHF流程分为三个阶段:
第一阶段:监督微调(SFT)。用高质量对话数据微调预训练模型,得到$\pi_{\text{SFT}}$。这个阶段让模型学会基本的对话能力。
第二阶段:奖励模型训练。用$\pi_{\text{SFT}}$对提示词生成多个回答,让人类标注偏好,得到数据集$\mathcal{D} = \{(x^{(i)}, y_w^{(i)}, y_l^{(i)})\}_{i=1}^N$,其中$y_w$是优选回答,$y_l$是被拒绝的回答。然后训练一个奖励模型$r_\phi$,优化目标是:
$$\mathcal{L}_R(r_\phi, \mathcal{D}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma(r_\phi(x, y_w) - r_\phi(x, y_l)) \right]$$这本质上是一个二分类问题:奖励模型要学会给优选回答打更高的分。
第三阶段:强化学习优化。用PPO算法优化策略模型$\pi_\theta$,目标是最大化期望奖励同时不偏离原始模型太远:
$$\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta} [r_\phi(x, y)] - \beta \mathbb{D}_{\text{KL}}[\pi_\theta(y|x) || \pi_{\text{ref}}(y|x)]$$这里$\pi_{\text{ref}}$是参考模型(通常是$\pi_{\text{SFT}}$),$\beta$控制KL散度约束的强度。
这个流程存在几个工程上的痛点:
首先是不稳定性。PPO是一种on-policy算法,需要在训练过程中不断采样,而采样过程本身会引入噪声。学习率稍大就会导致策略崩溃,稍小则训练极慢。
其次是超参数敏感性。PPO有多个超参数需要调优:裁剪范围$\epsilon$、GAE参数$\lambda$、价值函数系数、熵奖励系数等。这些参数之间存在复杂的相互作用,很难找到最优配置。
最后是计算开销。PPO需要维护四个模型:策略模型、参考模型、奖励模型、价值模型。每次更新都需要前向传播所有模型,内存和计算开销巨大。
DPO的核心洞察:奖励函数的重参数化
DPO的出发点是一个看似平凡的问题:如果我们知道最优策略,能否反推出奖励函数?
答案是肯定的。对于KL正则化的奖励最大化问题,最优策略的形式可以解析地写出:
$$\pi^*(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right)$$其中$Z(x) = \sum_y \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right)$是配分函数,确保概率归一化。
对上式取对数并重新排列,可以得到:
$$r(x, y) = \beta \log \frac{\pi^*(y|x)}{\pi_{\text{ref}}(y|x)} + \beta \log Z(x)$$这个公式揭示了关键洞察:奖励函数可以用策略函数和参考函数的比值来表示。更重要的是,配分函数$Z(x)$只依赖于提示词$x$,在成对比较中会相互抵消。
将这个重参数化代入Bradley-Terry模型:
$$p(y_w \succ y_l | x) = \sigma\left(\beta \log \frac{\pi^*(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi^*(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)$$现在,偏好概率完全用策略函数$\pi^*$表示,不再显式出现奖励函数!这就是DPO的核心突破:语言模型本身就是奖励模型。
DPO的目标函数与梯度分析
有了上述推导,DPO的目标函数水到渠成。对于数据集$\mathcal{D} = \{(x, y_w, y_l)\}$,DPO的损失函数为:
$$\mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma\left(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right) \right]$$这只是一个简单的二元交叉熵损失,完全不需要强化学习!
理解DPO为什么有效,需要分析它的梯度。损失函数对参数$\theta$的梯度为:
$$\nabla_\theta \mathcal{L}_{\text{DPO}} = -\beta \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \underbrace{\sigma\left(\hat{r}_\theta(x, y_l) - \hat{r}_\theta(x, y_w)\right)}_{\text{权重系数}} \left( \underbrace{\nabla_\theta \log \pi_\theta(y_w|x)}_{\text{增加优选概率}} - \underbrace{\nabla_\theta \log \pi_\theta(y_l|x)}_{\text{降低劣选概率}} \right) \right]$$其中隐式奖励$\hat{r}_\theta(x, y) = \beta \log \frac{\pi_\theta(y|x)}{\pi_{\text{ref}}(y|x)}$。
这个梯度公式蕴含着深刻的直觉:
权重系数:$\sigma(\hat{r}_\theta(x, y_l) - \hat{r}_\theta(x, y_w))$表示当前模型"误判"的程度。如果模型已经正确排序($\hat{r}_\theta(y_w) > \hat{r}_\theta(y_l)$),权重接近0,梯度更新很小;如果模型排序错误,权重接近1,梯度更新强烈。
双向调节:梯度同时增加优选回答的概率、降低劣选回答的概率。这与简单的监督学习(只增加优选回答的概率)有本质区别。
隐式KL约束:通过$\pi_{\text{ref}}$的引入,DPO自然地限制策略不偏离太远,这正是RLHF中KL约束的替代。
DPO论文中做了一个消融实验:如果移除权重系数,直接用$\log \pi(y_w) - \log \pi(y_l)$作为目标,模型会快速退化为重复生成少数高概率回答。这说明权重系数是DPO稳定性的关键。
DPO与PPO的实证对比
理论上,DPO优化的是与RLHF相同的目标函数。但实践中表现如何?
原始DPO论文在三个任务上进行了对比:情感控制(IMDb评论生成正面情感)、摘要生成(TL;DR数据集)、单轮对话(Anthropic HH数据集)。结果显示:
在情感控制任务上,DPO在奖励-KL前沿上全面超越PPO,即使在相同的KL散度下,DPO也能达到更高的奖励值。更有趣的是,DPO甚至超过了使用真实奖励的PPO(PPO-GT)。
在摘要生成任务上,用GPT-4作为评判者,DPO在温度0时的胜率达到61%,超过PPO的57%。而且DPO对采样温度更鲁棒——PPO在高温时性能急剧下降,而DPO保持稳定。
在对话任务上,DPO是唯一能在计算效率范围内超越数据集中优选回答的方法。传统的"Best-of-N"策略需要采样128个候选回答才能达到类似效果,这在实际部署中不可行。
2024年的一项研究《Is DPO Superior to PPO for LLM Alignment?》提出了不同观点:在代码生成等需要复杂推理的任务上,PPO仍然优于DPO。研究者认为,PPO的在线学习能力使其能更好地探索策略空间。这提示我们:DPO和PPO各有适用场景,选择需要考虑任务特性。
DPO的局限性催生了变体方法
DPO虽然简化了流程,但也暴露了一些问题,催生了多个变体方法。
过拟合问题与IPO
DPO的一个显著问题是容易过拟合。在训练过程中,如果继续训练超过收敛点,模型性能会下降。这源于DPO损失函数的特性:当$\pi_\theta(y_w|x)$接近1、$\pi_\theta(y_l|x)$接近0时,梯度仍然存在,只是被sigmoid压缩了。
Google DeepMind提出的Identity Preference Optimization (IPO) 通过添加正则化项解决这个问题:
$$\mathcal{L}_{\text{IPO}} = \mathbb{E}\left[\left(\log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} - \frac{1}{2\beta}\right)^2\right]$$IPO的损失函数是二次的,这意味着当差距足够大时,梯度会趋向于0,模型自然收敛。实践表明,IPO可以训练到完全收敛而不需要早停。
非成对数据与KTO
DPO要求成对偏好数据:每个提示词需要两个回答和它们的偏好标签。但在实际应用中,这种数据获取成本高昂——用户往往只给出"点赞"或"点踩",而非成对比较。
ContextualAI提出的Kahneman-Tversky Optimization (KTO) 放宽了这个要求。KTO基于前景理论(Prospect Theory),将每个回答独立标记为"好"或"坏":
$$\mathcal{L}_{\text{KTO}} = \mathbb{E}\left[\lambda_w \cdot (1 - \sigma(\beta(\hat{r}_\theta(x, y_w) - z_{\text{ref}}))) \cdot \text{好的样本}\right] + \mathbb{E}\left[\lambda_l \cdot \sigma(\beta(\hat{r}_\theta(x, y_l) - z_{\text{ref}})) \cdot \text{坏的样本}\right]$$其中$z_{\text{ref}}$是一个参考值,$\lambda_w$和$\lambda_l$是权重参数。KTO的关键洞察是:人类对"获得"和"损失"的感知是不对称的,这可以用前景理论建模。
KTO的优势在于可以充分利用生产环境中的隐式反馈数据——用户的点赞/点踩行为本身就是偏好信号。这使得模型可以持续从用户反馈中学习。
免参考模型的ORPO
DPO和IPO都需要维护一个参考模型$\pi_{\text{ref}}$,这增加了显存开销。韩国科学技术院(KAIST)提出的Odds Ratio Preference Optimization (ORPO) 完全消除了参考模型。
ORPO的核心是用**赔率比(Odds Ratio)**替代对数概率比:
$$\text{OR}(y|x) = \frac{\pi_\theta(y|x)/(1 - \pi_\theta(y|x))}{\pi_\theta(y_w|x)/(1 - \pi_\theta(y_w|x))}$$ORPO将偏好对齐融入SFT阶段,通过一个温和的惩罚项来抑制劣选回答:
$$\mathcal{L}_{\text{ORPO}} = \mathcal{L}_{\text{SFT}} + \lambda \cdot \mathcal{L}_{\text{odds ratio}}$$实验表明,仅用UltraFeedback数据集,ORPO微调的Mistral-7B在AlpacaEval 2.0上达到12.20%的胜率,超越了多个7B和13B参数的模型。ORPO的另一个优势是训练速度快——不需要额外的参考模型前向传播。
工程实践:超参数与最佳实践
DPO虽然简化了流程,但仍有几个关键超参数需要调优。
β参数的选择
$\beta$是最重要的超参数,它控制KL约束的强度。$\beta$越大,模型越保守,越接近参考模型;$\beta$越小,模型越激进,可能过拟合偏好数据。
HuggingFace的一项大规模实验揭示了有趣的发现:最优$\beta$值因模型和数据集而异。对于Zephyr-7B-SFT,最优$\beta$是0.01;对于OpenHermes-2.5-Mistral-7B,DPO的最优$\beta$是0.6,KTO是0.3,IPO是0.01。
实践中,建议从$\beta=0.1$开始,然后在$[0.01, 0.5]$范围内网格搜索。如果模型生成过于保守或重复,降低$\beta$;如果模型偏离原始能力太多,增加$\beta$。
数据质量的影响
DPO对数据质量非常敏感。Stanford 2025年的一项研究发现,数据选择策略对最终性能的影响甚至超过算法选择。
关键原则包括:
- 标注一致性:优选和劣选回答之间应有明确的质量差距
- 数据多样性:避免过度集中在特定领域或风格
- 分布匹配:偏好数据的分布应与模型实际应用场景匹配
过拟合的识别与规避
DPO容易在训练后期过拟合。识别过拟合的信号包括:
- 验证损失开始上升
- 生成多样性下降(重复率上升)
- 对未见提示词的泛化能力下降
规避策略包括:
- 使用IPO替代DPO,或添加早停
- 监控KL散度:$\mathbb{D}_{\text{KL}}[\pi_\theta || \pi_{\text{ref}}]$不应超过阈值
- 限制训练epoch数量,通常1-2个epoch足够
从理论到实践:Zephyr的成功案例
2023年10月发布的Zephyr-7B是DPO成功应用的典范。它的训练流程分为两步:
- 蒸馏SFT:用教师模型(GPT-4)的输出进行监督微调
- 蒸馏DPO(dDPO):用教师模型对多个候选回答进行排序,构建偏好数据,然后用DPO对齐
Zephyr在MT-Bench上达到7.34分,超越了当时的Llama 2 70B Chat等大模型。这一成功证明了DPO在资源有限情况下的有效性——用7B参数达到接近大模型的对话能力。
后续的Tülu 2、NeuralChat等模型也采用了类似的DPO流程,进一步验证了这一方法的普适性。
写在最后
DPO的成功揭示了一个深刻的道理:有时候,简化问题比解决复杂问题更有效。
RLHF将偏好学习转化为强化学习问题,引入了复杂的on-policy采样、价值函数估计、GAE计算等技术。DPO通过奖励函数重参数化,发现这些复杂性在语言模型场景下是不必要的——一个简单的分类损失就足够了。
但DPO并非万灵药。它假设偏好数据是独立同分布的,这在在线学习场景下可能不成立。PPO的在线能力使其能更好地探索策略空间,这在某些任务上可能是优势。实践中,选择DPO还是PPO,需要权衡计算资源、数据特性、任务复杂度等因素。
DPO的变体(IPO、KTO、ORPO)各自解决了DPO的特定问题,形成了丰富的偏好优化工具箱。理解这些方法的数学原理,才能在实际应用中做出正确的选择。
参考文献
- Rafailov, R., et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. NeurIPS 2023.
- Azar, M. G., et al. (2024). A General Theoretical Paradigm to Understand Learning from Human Preferences. ICML 2024.
- Ethayarajh, K., et al. (2024). KTO: Model Alignment as Prospect Theoretic Optimization. arXiv:2402.01306.
- Hong, J., et al. (2024). ORPO: Monolithic Preference Optimization without Reference Model. EMNLP 2024.
- Tunstall, L., et al. (2023). Zephyr: Direct Distillation of LM Alignment. arXiv:2310.16944.
- Xu, S., et al. (2024). Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study. arXiv:2404.10719.