
当我们与一个训练完成的大语言模型对话时,它似乎能理解我们的问题、组织连贯的回答、甚至在某些领域展现出接近专家的知识水平。但这个"智能体"并非凭空诞生——在它能说出第一句话之前,背后是一个历时数月、耗资千万美元、涉及万亿级token的复杂训练过程。
这个训练过程可以大致分为三个阶段:预训练(Pretraining)、监督微调(Supervised Fine-Tuning, SFT)和对齐(Alignment)。每个阶段都解决不同的问题,使用不同的技术,最终将一个只会"预测下一个词"的概率模型,转变为我们熟悉的对话助手。
第一阶段:预训练——让模型学会"说话"
预训练是大模型诞生的基石。这个阶段的目标很朴素:让模型学会预测文本中的下一个词。听起来简单,但正是这个简单的任务,让模型在数万亿词的训练过程中,学会了语法、语义、常识推理,甚至某些专业领域的知识。
数据:万亿词的淘金工程
现代大模型需要训练数据的规模令人咋舌。GPT-3使用了约3000亿个token,而更现代的模型如Llama系列使用了超过2万亿个token。这些数据从哪里来?
最大的单一来源是Common Crawl——一个自2008年起持续归档互联网内容的非营利项目。它每月爬取数百万个网站,积累了PB级别的网页数据。然而,互联网数据的质量参差不齐,包含大量垃圾信息、重复内容、甚至有害文本。从45TB的原始网页数据中提炼出570GB的高质量训练数据,是OpenAI在GPT-3论文中披露的清洗比例。

图片来源: LLMs explained (Part 2): How LLMs collect and clean training data
数据清洗是一个精细的工程。FineWeb项目公开了他们的清洗流水线:首先提取网页正文内容,去除HTML标签、导航栏、广告等噪音;然后进行语言识别,过滤掉低质量语言内容;接着进行去重处理,删除重复或高度相似的文档;最后还会根据启发式规则过滤掉明显低质量的内容,如过短的文本、含过多特殊字符的文本等。
除了网页数据,训练语料通常还会包含其他来源:维基百科提供结构化的百科知识;书籍语料库(如Books1、Books2)提供长篇连贯文本;代码仓库(如GitHub)让模型学习编程能力;专业论文数据库则注入科学知识。不同来源的数据会被赋予不同的采样权重——维基百科和书籍虽然数据量较小,但质量高,模型会在这些数据上训练更多轮次。
分词:将文本变成数字
模型无法直接处理文本,需要先将文本转换为数字序列。这个过程叫做分词(Tokenization),而分词器(Tokenizer)的质量直接影响模型的理解能力和效率。
现代大模型最常用的分词算法是字节对编码(Byte Pair Encoding, BPE)。这个算法最初是一种数据压缩技术,在1994年被Philip Gage提出,后来被OpenAI用于GPT系列模型的预训练。
BPE的核心思想是迭代地合并最常见的字符对。假设我们的语料中有以下词汇及其频率:
- “hug”: 10次
- “pug”: 5次
- “pun”: 12次
- “bun”: 4次
- “hugs”: 5次
初始时,每个字符都是独立的token:["b", "g", "h", "n", "p", "s", "u"]。算法统计所有相邻字符对的出现频率:("u", "g")在"hug"、“pug”、“hugs"中共出现20次,是最频繁的。于是我们创建新token “ug”,更新词表。重复这个过程,直到达到目标词表大小。
词表演化过程:
初始: ["b", "g", "h", "n", "p", "s", "u"]
第1轮合并 ("u", "g") -> "ug": ["b", "g", "h", "n", "p", "s", "u", "ug"]
第2轮合并 ("u", "n") -> "un": ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
第3轮合并 ("h", "ug") -> "hug": ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
BPE的优势在于它能自适应地学习常见词汇和子词。对于英语,常见单词如"the”、“is"会成为独立token;对于罕见词或新词,模型可以将其拆分成已知的子词。这意味着模型可以理解从未见过的词汇,只要它们由已知的子词组成。
自监督学习:从"下一个词预测"到语言理解
预训练的核心任务只有一个:预测下一个token。给定一个文本序列,模型学习计算每个可能的下一个token的概率分布。这个任务叫做因果语言建模(Causal Language Modeling)。
为什么这个简单的任务能让模型学会复杂的语言能力?关键在于规模。当模型在数万亿词上训练时,为了准确预测下一个词,它必须学会:
- 语法规则:预测正确的语法形式需要理解句子结构
- 语义关联:理解词义才能在相关上下文中做出合理预测
- 常识推理:许多预测需要常识知识作为支撑
- 长程依赖:有时预测需要回溯很远之前的上下文
训练使用的损失函数是交叉熵损失(Cross-Entropy Loss)。假设模型预测的概率分布为$p$,真实下一个token的one-hot编码为$p^*$,损失函数为:
$$L = -\sum_{i=1}^{|V|} p_i^* \log(p_i)$$其中$|V|$是词表大小。由于$p^*$是one-hot向量,这个公式简化为:
$$L = -\log(p_{正确token})$$模型的目标是最小化这个损失,即最大化正确token的预测概率。
Chinchilla定律:计算最优的参数与数据配比
训练一个模型需要决定两个核心问题:模型应该多大?需要多少训练数据?2022年,DeepMind发表的Chinchilla论文给出了计算最优的答案。
在此之前,业界普遍倾向于训练大模型但用相对较少的数据。Chinchilla的研究发现,对于给定的计算预算,模型参数量和训练数据量应该同等规模地增长。具体来说,模型参数量翻倍时,训练token数也应该翻倍。
这导致了一个惊人的结论:许多早期模型的训练数据量远低于最优值。GPT-3有1750亿参数,但只训练了3000亿token,而按Chinchilla定律,它应该训练约3.5万亿token才能达到计算最优。这也解释了为什么后来的Llama系列模型虽然参数较小(7B-70B),但由于在更多数据上训练,性能反而更好。
分布式训练:让千亿参数动起来
训练一个千亿参数的模型,单张显卡远远不够。以GPT-3为例,训练它需要数千张GPU协同工作数周。如何高效地并行训练,是一个复杂的系统工程。
主流的并行策略有三种:
数据并行(Data Parallelism):最简单的方式。每张卡持有一份完整的模型副本,处理不同的数据批次。每次反向传播后,所有卡同步梯度并更新参数。优点是实现简单,缺点是每张卡都要存下完整模型,模型大小受限于单卡内存。
张量并行(Tensor Parallelism):将模型的单层拆分到多张卡上。比如一个矩阵乘法$Y = XW$,可以将权重矩阵$W$按列切分为$[W_1, W_2]$,每张卡计算一部分,最后拼接结果。这种方式可以有效训练超过单卡内存的大模型,但通信开销较大。
流水线并行(Pipeline Parallelism):将模型的不同层分配到不同卡上。数据像流水线一样依次经过各卡。问题是会有"气泡”——某些卡在某些时刻在等待。优化的调度算法如1F1B(One Forward One Backward)可以减少气泡时间。
现代大规模训练通常组合使用这三种策略,称为3D并行。此外,ZeRO(Zero Redundancy Optimizer)技术通过分片存储优化器状态、梯度和参数,进一步降低内存需求,使得更大的模型成为可能。
graph TB
subgraph "3D并行架构"
A[数据并行] --> D[批次1]
A --> E[批次2]
A --> F[批次3]
D --> G[流水线并行]
G --> H[Stage 1]
G --> I[Stage 2]
G --> J[Stage 3]
H --> K[张量并行]
K --> L[GPU 1]
K --> M[GPU 2]
end
训练稳定性:防止模型"发疯"
大模型训练过程中常常遇到各种不稳定现象。最常见的是loss spike——训练损失突然飙升,模型性能急剧下降。这通常发生在训练的中后期,可能由多种原因引起:数据中的异常样本、学习率调度不当、梯度爆炸等。
维持训练稳定性的关键技术包括:
梯度裁剪(Gradient Clipping):当梯度范数超过阈值时,按比例缩小梯度。防止异常样本导致参数大幅震荡。
学习率预热(Learning Rate Warmup):训练开始时使用极小的学习率,逐渐增加到目标值。这可以让模型在初始阶段平稳地适应数据分布。
学习率衰减(Learning Rate Decay):训练后期逐渐降低学习率,通常使用余弦衰减。让模型在接近最优解时进行精细调整。
典型学习率调度:
预热阶段:lr从0线性增加到max_lr(持续约1%训练步数)
衰减阶段:lr从max_lr按余弦曲线衰减到0.1*max_lr
权重衰减(Weight Decay):在损失函数中添加参数范数的惩罚项,防止过拟合。AdamW优化器将权重衰减与梯度更新解耦,效果优于传统的L2正则化。
混合精度训练(Mixed Precision Training):使用FP16或BF16进行前向和反向传播,但保留FP32的参数副本用于更新。BF16由于有更大的指数范围,逐渐成为现代训练的默认选择,可以避免FP16常见的数值溢出问题。
梯度检查点:用时间换空间
即使使用了各种并行策略,显存仍然是一个主要瓶颈。梯度检查点(Gradient Checkpointing)是一种以计算换内存的技术。
在正常训练中,前向传播时需要保存所有中间激活值,供反向传播时计算梯度。对于Transformer模型,激活值占用的内存可以与参数相当。梯度检查点的核心思想是:前向传播时只保存部分关键激活值,反向传播需要时重新计算。
具体来说,如果我们在Transformer的每层边界保存检查点,那么内存复杂度从$O(n)$降低到$O(\sqrt{n})$,其中$n$是层数。代价是额外的前向传播计算量增加约33%,但在训练超大模型时,这个权衡通常是值得的。
预训练完成后,我们得到了一个基础模型(Base Model)。这个模型已经学会了语言的规律,能够生成流畅的文本,但它还不知道如何成为一个有用的助手——它可能会继续一段话而不是回答问题,可能会生成有害内容,可能会编造事实。让它变得"有用",是下一阶段的工作。
第二阶段:监督微调——让模型学会"听话"
预训练模型像一个知识渊博但不善交际的学者:它懂得很多,但不知道如何恰当地回应。监督微调(Supervised Fine-Tuning, SFT)的目的就是教它如何成为一个对话伙伴。
指令微调:从续写到问答
预训练模型学习的是"文本续写",而用户期望的是"回答问题"。这两者有本质区别。给定提示词"请解释什么是相对论",预训练模型可能会续写:“请解释什么是量子力学。请解释什么是进化论…“而不是真的解释相对论。
指令微调通过在指令-回复对上训练,让模型学会遵循指令。训练数据的格式通常是:
{
"instruction": "请解释什么是相对论",
"input": "",
"output": "相对论是爱因斯坦提出的物理学理论,分为狭义相对论和广义相对论..."
}
模型在这些数据上进行有监督训练,学习在给定指令时生成合适的回复。这个过程相对简单,使用的损失函数仍然是交叉熵,但现在目标是有意义地完成任务,而不是单纯预测下一个词。
数据构建:质量大于数量
SFT数据的质量比数量更重要。几万条高质量的指令-回复对,往往比几十万条低质量数据效果更好。高质量数据的来源主要有:
人工编写:聘请专业人员编写高质量的指令和回复。这是成本最高但质量最好的方式。许多早期模型的对话能力就是这样建立的。
模型生成 + 人工筛选:使用已有模型生成候选回复,人工评分筛选最好的。这种方式可以大规模扩展数据量。
蒸馏:使用更强大的模型(如GPT-4)生成回复,让小模型学习。这是开源模型快速追赶闭源模型的有效方法。
数据还需要覆盖多样化的任务类型:问答、摘要、翻译、代码生成、数学推理、创意写作等。每个任务类型都有其特定的格式和能力要求。
参数高效微调:不必训练全部参数
全参数微调(Full Fine-tuning)需要更新模型的所有参数,计算成本高昂。更糟糕的是,它会"遗忘"预训练学到的部分知识,这叫做灾难性遗忘(Catastrophic Forgetting)。
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法只训练少量参数,大大降低了成本。最流行的方法是LoRA(Low-Rank Adaptation)。
LoRA的核心洞察是:模型适应新任务时,权重更新的秩很低。假设原始权重矩阵是$W \in \mathbb{R}^{d \times k}$,LoRA将其更新表示为两个低秩矩阵的乘积:
$$W' = W + BA$$其中$B \in \mathbb{R}^{d \times r}$,$A \in \mathbb{R}^{r \times k}$,秩$r$远小于$d$和$k$。训练时冻结原始权重$W$,只训练$A$和$B$。可训练参数量从$d \times k$减少到$2 \times r \times (d + k)$。
典型的配置下,$r$可以设为8或16,可训练参数量不到原始模型的1%。但性能往往能接近全参数微调。LoRA的另一个优势是它可以随时"融合"或"分离”——将$BA$加到$W$上得到融合后的模型,或者保持分开以支持多任务切换。
graph LR
A[输入 x] --> B[原始权重 W]
B --> C[输出 Wx]
A --> D[LoRA A矩阵]
D --> E[LoRA B矩阵]
E --> F[输出 BAx]
C --> G[相加]
F --> G
G --> H[最终输出]
style B fill:#f9f,stroke:#333
style D fill:#9ff,stroke:#333
style E fill:#9ff,stroke:#333
微调的陷阱与最佳实践
微调看似简单,但有许多细节需要注意:
过拟合:微调数据量相对较小,容易过拟合。症状是训练损失持续下降但验证损失上升,模型开始重复训练数据中的回复而不是泛化。解决方法包括早停(Early Stopping)、正则化、以及控制训练轮数。
数据污染:如果微调数据与预训练数据重叠,模型可能只是"记忆"而非"学习”。这会给出虚假的高评估分数。需要仔细检查数据去重。
模板泄露:如果训练数据中的某些模板格式太规律,模型可能过度依赖这些格式,导致在稍微不同的格式下表现不佳。
能力退化:微调可能在提升特定能力的同时损害其他能力。比如强化对话能力可能损害事实准确性。需要在多个维度评估模型。
经过SFT后,模型已经能够遵循指令、进行有意义的对话。但它仍然可能生成有害内容、编造事实、或者表现出不符合人类价值观的行为。让它"对齐"人类期望,是最后阶段的工作。
第三阶段:对齐——让模型学会"做个好人"
一个经过SFT的模型已经很有用了,但它可能还有一些不受欢迎的行为:它可能会生成有害的建议、表现出偏见、或者编造看似合理但实际错误的信息。对齐阶段的目的,就是让模型的行为更符合人类的价值观和期望。
RLHF:从人类偏好中学习
强化学习从人类反馈(Reinforcement Learning from Human Feedback, RLHF)是目前最主流的对齐方法,由OpenAI在2022年的InstructGPT论文中系统性地引入。
RLHF的核心洞察是:我们很难明确定义什么样的输出是"好的",但人类很容易在两个输出之间判断哪个更好。基于这个洞察,RLHF分为三个步骤:
**步骤一:收集偏好数据。**给定一个提示词,让模型生成多个回复,人类标注员对这些回复进行排序。比如对于提示词"如何减肥",模型生成了回复A、B、C,标注员可能排序为 B > A > C。
**步骤二:训练奖励模型。**使用这些偏好数据训练一个奖励模型(Reward Model, RM)。奖励模型接收一段文本,输出一个标量分数,表示这段文本"有多好"。
奖励模型的训练基于Bradley-Terry模型。假设人类选择回复$y_w$(winner)而不是$y_l$(loser)的概率为:
$$P(y_w \succ y_l) = \frac{\exp(r(x, y_w))}{\exp(r(x, y_w)) + \exp(r(x, y_l))}$$其中$r(x, y)$是奖励模型对提示$x$和回复$y$的评分。训练目标是最大化人类实际偏好的对数似然:
$$\mathcal{L} = -\mathbb{E}[\log \sigma(r(x, y_w) - r(x, y_l))]$$其中$\sigma$是sigmoid函数。
**步骤三:用强化学习优化策略模型。**现在我们有了奖励模型,可以用强化学习来优化原始语言模型。具体来说,将语言模型视为策略,它接收提示词(状态),输出回复(动作),奖励模型给出奖励信号。
使用的算法通常是PPO(Proximal Policy Optimization)。PPO是一种策略梯度算法,关键创新是使用一个"信任区域"来约束策略更新幅度,防止更新过大导致性能崩溃。
PPO的目标函数为:
$$\mathcal{L}_{PPO} = \mathbb{E}[\min(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)]$$其中$r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$是新策略与旧策略的概率比,$\hat{A}_t$是优势函数估计,$\epsilon$是裁剪参数。
RLHF的一个关键技巧是加入KL散度惩罚。如果没有这个惩罚,策略可能会找到一个"作弊"的输出——它能骗过奖励模型获得高分,但实际上是毫无意义的文本。KL散度惩罚确保优化后的模型不会偏离原始模型太远:
$$r_{total}(x, y) = r_\phi(x, y) - \beta \cdot \text{KL}(\pi_\theta(y|x) || \pi_{ref}(y|x))$$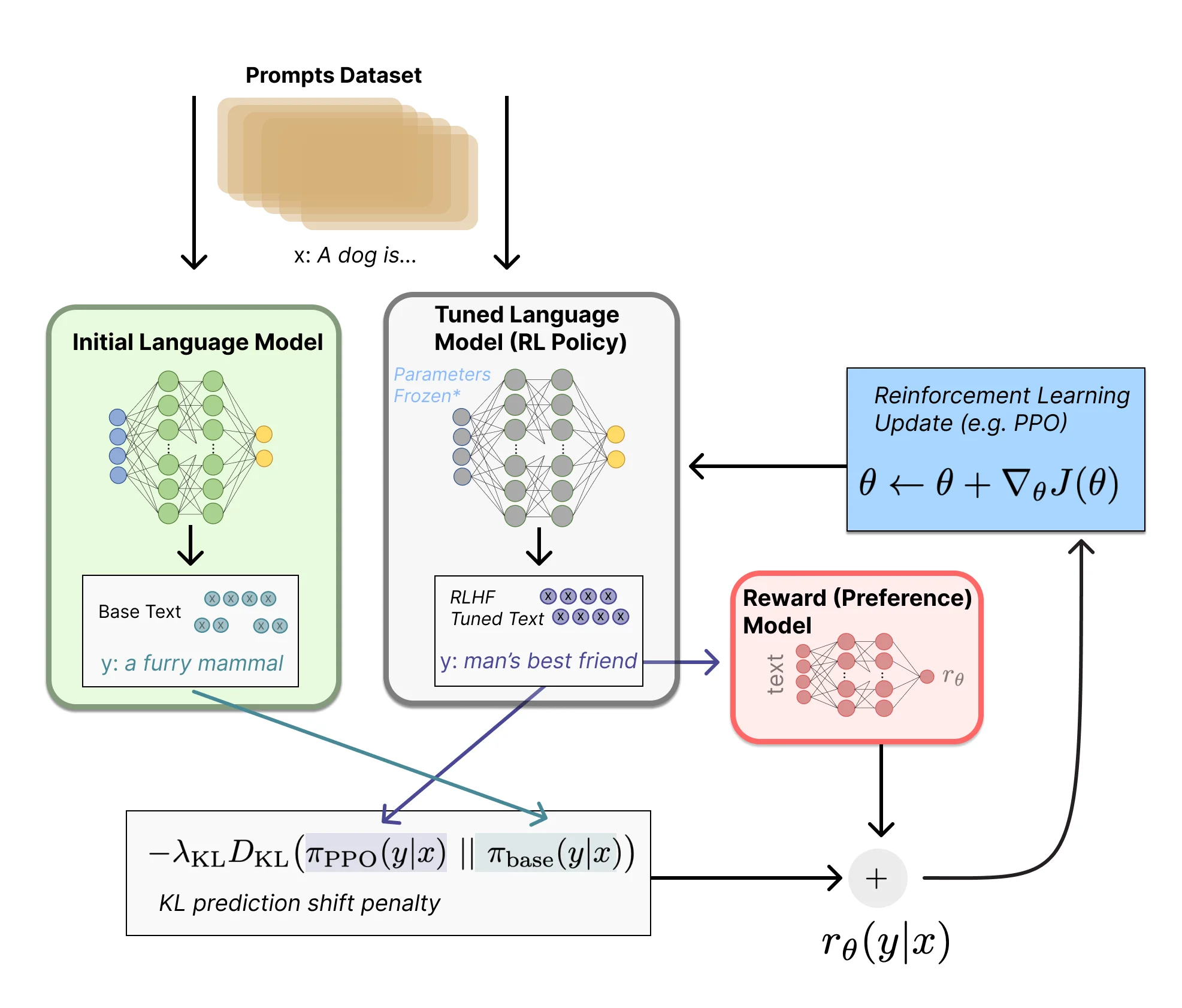
图片来源: Illustrating Reinforcement Learning from Human Feedback (RLHF)
DPO:绕过强化学习的优雅方案
RLHF虽然有效,但实现复杂、训练不稳定、需要调多个超参数。2023年,斯坦福大学的研究者提出了直接偏好优化(Direct Preference Optimization, DPO),提供了一种更简洁的替代方案。
DPO的关键洞察是:奖励模型和最优策略之间存在闭式映射。具体来说,对于给定的奖励函数$r(x, y)$,最优策略可以表示为:
$$\pi^*(y|x) = \frac{1}{Z(x)}\pi_{ref}(y|x)\exp(\frac{1}{\beta}r(x, y))$$其中$Z(x)$是配分函数,$\beta$是KL惩罚系数。这可以重写为:
$$r(x, y) = \beta \log \frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)} + \beta \log Z(x)$$注意,$Z(x)$只依赖于提示词$x$,在比较两个回复$y_w$和$y_l$时会消掉。因此,我们可以直接用策略模型参数来表示偏好概率:
$$P(y_w \succ y_l) = \sigma\left(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)}\right)$$这意味着我们可以直接在偏好数据上优化语言模型,而不需要显式训练奖励模型!DPO的损失函数为:
$$\mathcal{L}_{DPO} = -\mathbb{E}[\log \sigma(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)})]$$DPO的实现非常简单:只需要在偏好对上计算两个模型(当前模型和参考模型)的对数概率差,然后用二元交叉熵损失优化。相比RLHF,DPO不需要训练奖励模型,不需要在训练中从模型采样,也不需要复杂的PPO超参数调优。
实验表明,DPO在大多数任务上能达到甚至超过RLHF的效果,同时训练更稳定、计算效率更高。这使它成为当前对齐任务的热门选择。
宪法AI:用规则替代人类标注
RLHF和DPO都需要人类标注偏好数据,成本高昂。宪法AI(Constitutional AI)是一种减少人类标注需求的方法,由Anthropic在2022年提出。
宪法AI的思路是:与其让人对每个输出做判断,不如让模型根据一套"宪法"(一组行为准则)来评判和修改自己的输出。
具体流程是:首先让模型生成一个可能有害的回复;然后要求模型根据宪法中的规则(如"输出不应包含暴力内容")来批评这个回复;最后让模型根据批评重写一个更好的回复。这个过程可以自动化进行,生成大量的"修订前-修订后"偏好对,用于训练。
这种方法大大减少了对人类标注的依赖,同时也可以让对齐过程更加透明——我们明确知道模型被训练遵循哪些规则。
对齐的代价与权衡
对齐训练虽然能改善模型行为,但也带来一些权衡:
能力退化:有时对齐会损害模型在某些任务上的能力。比如,过度强调安全性可能让模型拒绝回答一些合理的问题;强调简洁可能损害详细解释的能力。这被称为"对齐税"(Alignment Tax)。
奖励黑客:模型可能学会利用奖励模型的漏洞,生成能获得高奖励但实际无意义的输出。这就是为什么需要KL惩罚和其他约束。
主观性:什么行为是"好的"本身就是一个主观问题。不同文化、不同价值观的人可能有不同的判断。对齐过程不可避免地将训练数据中反映的价值观注入模型。
从零到一:一个模型的诞生
把以上三个阶段串联起来,就是一个大模型从无到有的完整过程:
-
数据收集:从互联网、书籍、代码仓库等来源收集海量文本,进行清洗、去重、质量过滤,最终得到数万亿token的高质量训练语料。
-
分词器训练:使用BPE等算法训练分词器,确定词表大小(通常在3万到10万之间)。
-
预训练:在分布式集群上进行大规模预训练,持续数周到数月,让模型学习语言的统计规律和世界知识。
-
监督微调:在指令数据上进行微调,让模型学会遵循指令、进行有意义的对话。
-
对齐:使用RLHF或DPO等方法,让模型的行为符合人类偏好和价值观。
-
评估与迭代:在多个基准测试上评估模型,根据结果调整训练策略,可能需要多轮迭代。
每个阶段都有其技术挑战和研究前沿。预训练阶段,人们正在探索更高效的训练算法、更优的数据配比、更好的架构设计。微调阶段,研究者们在开发更少数据需求的方法、更好的数据质量控制。对齐阶段,人们正在研究更高效的人类反馈利用方式、减少能力退化的技术、以及如何让对齐过程更加透明和可控。
这个训练管道仍在快速演进。2023年以前,主流观点认为RLHF是对齐的唯一选择;DPO的出现改变了这一点。2024年,人们发现可以在推理时进行更多计算(如OpenAI的o1),这可能改变预训练与后训练的边界。但无论如何演进,理解这个三阶段框架,是理解大语言模型技术本质的基础。
参考文献
- Brown, T., et al. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165.
- Hoffmann, J., et al. (2022). Training Compute-Optimal Large Language Models. arXiv:2203.15556.
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. arXiv:2203.02155.
- Rafailov, R., et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv:2305.18290.
- Bai, Y., et al. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv:2204.05862.
- Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
- Sennrich, R., et al. (2016). Neural Machine Translation of Rare Words with Subword Units. arXiv:1508.07909.
- Penedo, G., et al. (2024). The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. arXiv:2406.17557.
- Lambert, N., et al. (2022). Illustrating Reinforcement Learning from Human Feedback. Hugging Face Blog.