2024年9月,OpenAI发布了一款名为o1的新模型。在GPQA Diamond测试——一项涵盖物理、化学、生物的博士级科学问题评估中,o1取得了77.3%的准确率,而招募的博士级专家平均得分仅为69.7%。这是AI首次在这一基准测试中超越人类专家。
更令人惊讶的是,这种能力的获得并非来自更大的模型参数或更多的训练数据。OpenAI透露,o1的核心创新在于一种被称为"推理时计算"(Inference-Time Compute)的技术——让模型在回答问题前先"思考"一段时间。
这标志着大模型发展的范式正在发生根本性转变。过去六年,AI领域信奉的教条是:更大的模型、更多的数据、更强的算力。然而,当训练Scaling Law逐渐逼近天花板,一种新的增长路径正在浮出水面:与其把计算砸在训练阶段,不如让模型在推理时"多想一会儿"。
Scaling Law的物理极限
理解推理时计算的价值,需要先理解传统Scaling Law为何正在放缓。
2020年,OpenAI发表的论文《Scaling Laws for Neural Language Models》揭示了一个关键规律:模型的测试损失与训练计算量之间存在幂律关系。具体而言,测试损失$L$可以近似表示为:
$$L(C) = \left(\frac{C_c}{C}\right)^{\alpha}$$其中$C$是训练计算量,$C_c$和$\alpha$是常数。这个公式意味着,投入更多的训练计算,模型的性能就会平滑提升。
这套理论在过去六年里被反复验证。从GPT-3的1750亿参数到GPT-4的万亿级参数,每一次规模扩展都带来了可预测的性能提升。但问题在于,幂律关系的特性决定了改进会越来越难——要对数级增加计算量才能获得线性的性能提升。
2024年下半年,多家研究机构开始报告Scaling Law正在"撞墙"。路透社披露OpenAI因规模扩展受阻而调整产品策略;The Information报道称GPT系列的改进速度正在放缓。Ilya Sutskever在NeurIPS 2024的演讲中直言:“我们所熟悉的预训练时代即将结束。”
这并非偶然。Scaling Law本身就暗示了改进的边际递减:当测试损失从2.0降到1.0需要10倍计算时,从1.0降到0.5可能需要100倍。硬件成本、能源消耗、数据枯竭——多重因素正在让训练端的规模扩展变得越来越不经济。
就在这条路径逼近极限的时刻,Google DeepMind在2024年8月发表的一篇论文提出了一个反直觉的问题:如果把计算从训练端挪到推理端,会发生什么?
两类机制:修改提议分布与搜索验证
推理时计算的核心思想是:在给定一个提示词后,允许模型使用额外的计算来改进输出。Google DeepMind的研究团队将各种方法统一到一个框架中,识别出两个独立的调控轴:修改提议分布(Modifying the Proposal Distribution)和优化验证器(Optimizing the Verifier)。
修改提议分布
第一种思路是直接改变模型生成回答的方式。最典型的例子是迭代自修正(Iterative Self-Refinement):让模型先生成一个初始回答,然后基于这个回答进行批评和修改,反复迭代直到收敛。
数学上,这相当于将模型的条件分布从$p(y|x)$修改为$p(y|x, c_1, c_2, ..., c_n)$,其中$c_i$是前几轮迭代的上下文。通过在输入中添加额外的token,模型可以在测试时动态调整其生成策略。
这种方法在"容易"的问题上表现尤为出色。当模型的初始回答已经接近正确方向,只需要进一步精炼时,迭代修改往往比从头采样多个候选更高效。
搜索验证器
第二种思路是生成多个候选答案,然后用验证器选择最优的。最简单的方法是Best-of-N采样:独立采样N个完整回答,根据验证器评分选择最高的那个。
更高级的方法是过程奖励模型(Process Reward Model, PRM)。与只对最终答案评分的输出奖励模型(ORM)不同,PRM会对解决方案中的每一个步骤进行评分。这使得树搜索成为可能:在每个步骤选择最有希望的分支继续探索,而不是盲目地生成完整答案。
研究团队比较了三种搜索策略:
- Best-of-N:并行采样N个完整答案,选择PRM评分最高的
- Beam Search:每一步保留top-k个候选,逐层扩展
- Lookahead Search:在Beam Search基础上,对每个候选执行k步前向模拟来更准确地评估
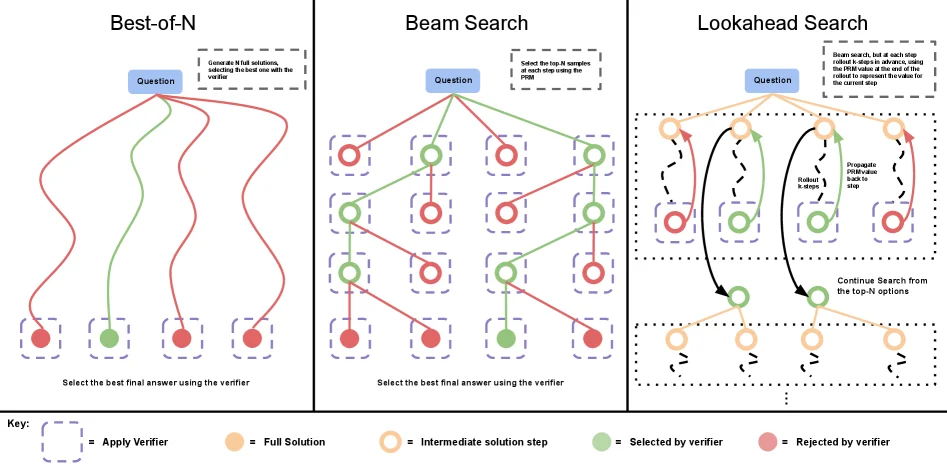
图片来源: arXiv:2408.03314
实验发现了一个关键现象:不同方法的有效性高度依赖于问题的难度。在简单问题上,迭代修正往往比树搜索更有效;但在困难问题上,需要探索多种解题策略时,树搜索则更具优势。
计算最优分配策略
这一发现催生了"计算最优分配"(Compute-Optimal Scaling)的概念:根据问题的难度动态选择最合适的推理策略。
研究团队定义了一个难度分级系统,将问题分为五个难度级别。对于每个级别,在验证集上确定最优的超参数配置(如采样数量、beam宽度、lookahead深度),然后在测试集上应用这些配置。
结果显示,与固定使用Best-of-N相比,计算最优分配可以将效率提升4倍以上。换言之,用相同的计算预算,计算最优策略可以达到Best-of-N四倍计算量才能达到的性能。
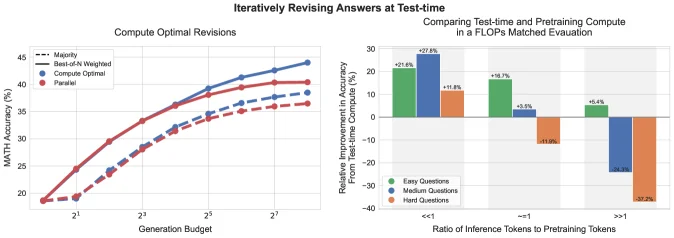
图片来源: arXiv:2408.03314
左图展示了这一效果:随着计算预算增加,计算最优策略(绿色曲线)与Best-of-N基线(蓝色曲线)之间的差距逐渐拉大。
训练计算 vs 推理计算的权衡
最引人注目的发现在于:在FLOPs等价的条件下,小模型配合推理时计算可以超越14倍大的模型。
研究团队设计了一个对比实验:比较一个较小模型(PaLM 2-S*)使用推理时计算,与一个较大模型使用贪心解码的性能。在FLOPs等价的前提下,当推理token与预训练token的比例在一定范围内时,推理时计算往往更优。
具体而言:
- 在简单和中等难度问题上,推理时计算比训练更大的模型更高效
- 在最困难的问题上,预训练更多参数仍然更有优势
这一发现具有重要的工程意义。训练一个14倍大的模型需要天文数字的算力投入,而且一旦训练完成就无法更改。而推理时计算具有灵活性:可以根据问题的难度动态调整投入,只在需要时才消耗更多计算。
论文中给出了一个直观的权衡公式。设$N_{train}$为预训练token数,$N_{inference}$为推理token数,$D$为模型参数量,则总FLOPs可以近似为:
$$\text{FLOPs} \approx 6 \cdot D \cdot (N_{train} + N_{inference})$$传统观点认为$N_{inference} \ll N_{train}$,推理计算可以忽略不计。但当$N_{inference}$被主动放大——比如生成更长的思维链、采样更多候选、执行更深的搜索——推理计算就变得不可忽视,甚至可能成为主导因素。
从理论到实践:o1与DeepSeek-R1
Google DeepMind的论文为推理时计算奠定了理论基础,而OpenAI o1和DeepSeek-R1则将这一理念付诸实践。
OpenAI o1:隐藏的思维链
OpenAI在2024年9月发布的o1系列首次将推理时计算大规模产品化。根据公开信息,o1在回答问题前会先生成一段"隐藏的思维链"(Hidden Chain-of-Thought)——用户看不到这段推理过程,但需要为它付费。
o1在AIME 2024数学竞赛预选赛中取得了74.4%的准确率,而GPT-4o仅为12%。在Codeforces编程竞赛中,o1达到Elo 1673分,相当于89百分位的人类选手水平。
o1的核心技术细节尚未公开,但从OpenAI的描述可以推断,它很可能结合了:
- 强化学习训练:让模型学会生成有价值的推理步骤
- 自适应计算分配:根据问题难度调整思考时间
- 验证与回溯:在推理过程中检测错误并修正
OpenAI的研究人员在系统卡片中特别强调了"思维链监控"(CoT Monitoring)的重要性:通过检查隐藏的推理过程,可以更好地理解模型的行为,检测潜在的欺骗或对齐问题。
DeepSeek-R1:纯强化学习的奇迹
如果说o1的细节仍然神秘,DeepSeek-R1则提供了完全透明的技术路线。
2025年1月,DeepSeek团队发布的R1模型展示了一个令人震惊的事实:无需人类标注的思维链数据,仅通过强化学习(RL),模型就能自发涌现出高级推理能力。
DeepSeek-R1的训练分为四个阶段:
- 冷启动:用少量高质量推理数据进行监督微调
- 推理强化学习:使用GRPO(Group Relative Policy Optimization)算法,让模型在可验证任务(数学、编程)上自主探索
- 拒绝采样与监督微调:从强化学习模型中采样高质量推理数据,用于微调
- 全场景强化学习:将推理能力扩展到更广泛的任务
关键突破在于第二阶段。研究团队发现,只要给模型足够大的规模和合适的奖励信号,复杂推理模式——如自我反思、验证、策略切换——会自发涌现。这些模式不是被显式编程的,而是通过大规模强化学习自然习得的。
DeepSeek-R1在MATH-500上达到97.3%的准确率,在AIME 2024上达到79.8%,与o1-1217相当。考虑到R1的参数量(671B MoE,每次激活37B)远小于传闻中o1的规模,这一成绩更加令人印象深刻。
自我纠正的困境
推理时计算的一个重要组成部分是自我纠正——让模型发现并修正自己的错误。然而,研究发现这远比想象中困难。
2024年ICLR的一篇论文《Large Language Models Cannot Self-Correct Reasoning Yet》给出了一个令人沮丧的结论:在缺乏外部反馈的情况下,LLM的自我纠正往往会降低而非提高答案质量。
问题在于,LLM往往无法可靠地识别自己推理中的逻辑错误。当模型被要求"检查并纠正"时,它可能基于表面模式而非深层逻辑进行修改,导致原本正确的答案被改错,或原本错误的答案被改成另一个错误答案。
这解释了为什么验证器(如PRM)如此重要。验证器提供了一个独立于生成器的判断信号,使得纠正有据可依。o1和DeepSeek-R1之所以能在复杂推理任务上表现优异,很可能就是因为它们学会了在内部进行"验证-修正"循环,而不是简单的自我批评。
推理Scaling Law的未来
推理时计算的兴起正在重塑AI研究和产业格局。
计算经济学的新平衡
传统的AI经济学关注训练成本。但推理时计算引入了一个新变量:每次查询的边际成本可以动态调整。对于简单问题,快速响应;对于复杂问题,投入更多计算。
这带来了新的优化空间。Sebastian Raschka指出:“训练通常非常昂贵,但它是一次性成本。推理扩展相对便宜,但它是每次查询都要支付的成本。“在总查询量可预测的场景下,可以精确计算训练与推理的最佳投入比例。
安全与对齐的新维度
OpenAI的研究人员注意到,思维链监控为模型对齐提供了新工具。通过检查推理过程,可以更早发现欺骗行为或对齐问题。
但这也带来了风险:如果模型学会在隐藏的思维链中隐藏真实意图,监控可能反而产生虚假的安全感。2025年3月,OpenAI发布的研究指出,直接对思维链施加优化压力会迅速导致"思维链混淆”(CoT Obfuscation),使推理过程变得难以解释。
开源生态的新机遇
推理时计算降低了模型部署的门槛。如果小模型配合推理扩展可以达到大模型的性能,那么在边缘设备上运行强大的AI成为可能。QwQ-32B的成功就是一个例证:这个320亿参数的模型在多个推理基准上与DeepSeek-R1和o1-mini相当,而参数量仅为R1的二十分之一。
从GPT-3到GPT-4,AI能力的提升主要来自"更大的模型”。但从o1到DeepSeek-R1,一个新的范式正在形成:与其把计算砸在训练阶段,不如让模型学会"思考"。
这并不意味着训练扩展就此终结。对于最困难的问题——那些模型尚未掌握基础知识的领域——预训练仍然不可替代。但对于推理密集型任务,计算最优分配策略提供了一个更灵活、更经济、也更可持续的路径。
推理时计算的核心洞察可以追溯到人类认知的本质:面对困难问题时,我们不会立即给出答案,而是反复思考、验证、修正。让AI学会这个过程,或许是通向更智能系统的重要一步。
参考文献
- Snell, C., et al. (2024). Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv:2408.03314.
- Wu, Y., et al. (2024). Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving. arXiv:2408.00724.
- OpenAI. (2024). Learning to reason with LLMs. OpenAI Blog.
- OpenAI. (2024). OpenAI o1 System Card. arXiv:2412.16720.
- DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948.
- Huang, J., et al. (2024). Large Language Models Cannot Self-Correct Reasoning Yet. ICLR 2024.
- Lightman, H., et al. (2023). Let’s Verify Step by Step. arXiv:2305.20050.
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361.
- Hoffmann, J., et al. (2022). Training Compute-Optimal Large Language Models (Chinchilla). arXiv:2203.15556.
- Brown, T., et al. (2020). Language Models are Few-Shot Learners (GPT-3). NeurIPS 2020.