2017年,Hinton和Plaut在论文中提出了"Fast Weights"的概念——一种在推理时快速更新的记忆机制。这个想法沉寂多年,直到2020年才被Sun等人重新挖掘,演变成Test-Time Training(TTT)——一种让模型在推理阶段继续学习的技术范式。如今,这项技术已经从视觉模型的域适应工具,发展为挑战Transformer霸主地位的新架构,甚至让语言模型在ARC抽象推理基准上达到人类水平。
一个反直觉的设计选择
传统的机器学习范式有一个铁律:训练和推理是严格分离的两个阶段。模型在训练时学习,在推理时只是应用——参数被冻结,不再改变。这条规则看似理所当然,却隐藏着一个根本性问题:如果测试数据与训练数据存在差异,模型只能束手无策。
TTT的核心思想是打破这条边界。与其让模型在测试时"裸奔",不如让它继续学习——利用测试输入本身来更新参数。这听起来像是"作弊":测试数据不应该参与训练。但TTT的精妙之处在于,它使用的是自监督学习——不需要标签,只从输入数据本身构造学习任务。
这个想法的源头可以追溯到更早的工作。2013年,Mikolov等人提出的动态评估(Dynamic Evaluation)就允许语言模型在测试时继续训练。但真正让TTT成为系统性框架的,是Sun等人在2020年的工作:他们将自监督学习引入测试时适应,让视觉模型能够处理分布偏移。2023年,Sun在加州大学伯克利分校完成的博士论文系统性地探索了这一方向,将其应用于图像、视频和机器人领域。
TTT层:让隐藏状态变成一个模型
2024年7月,斯坦福大学和普林斯顿大学的研究团队发表了一篇论文,将TTT推向了一个全新的方向。他们没有在现有模型上做测试时微调,而是设计了一种全新的神经网络层——TTT层。
传统RNN的瓶颈在于隐藏状态的"表达能力"。一个固定大小的向量,要压缩数千甚至数百万个token的历史信息,这本质上是一个有损压缩问题。Transformer通过KV Cache绕过了这个问题,但代价是$O(n^2)$的复杂度和线性增长的显存占用。
TTT层的解决方案出人意料地简单:将隐藏状态本身变成一个机器学习模型。
具体来说,隐藏状态不再是固定大小的向量,而是一组可学习的权重$W$。更新规则是梯度下降:
$$W_t = W_{t-1} - \eta \nabla \ell(W_{t-1}; x_t)$$输出规则就是用更新后的权重进行预测:
$$z_t = f_{W_t}(x_t)$$其中$\ell$是自监督损失,$f$是隐藏状态模型(可以是线性模型或小型MLP)。这个设计的关键洞察是:自监督学习本身就是一种压缩历史信息的机制——正如预训练模型将互联网知识压缩进权重,TTT层将当前序列的信息压缩进隐藏状态的权重。
论文提出了两种实例化:TTT-Linear使用线性模型作为隐藏状态,TTT-MLP使用两层MLP。实验结果表明,TTT-Linear在8K上下文时已经比Mamba更快,且困惑度持续下降——而Mamba在16K之后性能就趋于饱和。
Mini-Batch与Dual Form:工程化的智慧
理论上优美的设计,在实际部署中往往遇到瓶颈。TTT层也不例外。
原始的TTT层在每个时间步执行一次梯度更新,这种在线梯度下降无法并行化。在GPU上,这意味着大量的串行计算,硬件利用率极低。研究团队借鉴了传统训练中mini-batch的思想:将多个时间步组成一个批次,在这批数据上计算梯度,然后一次性更新。
但这种并行化带来了一个新的问题。假设batch size为$b$,在第$t$步时,模型需要预测$x_{t+1}$,但此时$W$还没有被$x_t$更新——因为更新被推迟到了batch结束。这导致batch内的每个token都相当于在"回顾"更少的历史信息。
解决方案是与Transformer类似的滑动窗口注意力。在TTT层之前添加一个局部的注意力层,窗口大小设为batch size,这样即使在batch内部,模型也能看到足够多的上下文。这个设计被称为TTT-Linear with SWA。
更进一步的优化是Dual Form(对偶形式)。原始的实现需要显式存储每个时间步的梯度,内存开销巨大。对偶形式通过数学变换,将累积的梯度更新转化为矩阵运算,可以复用中间结果,避免重复计算。在实际实现中,对偶形式比原始形式快了5倍以上。
有一个有趣的定理:当隐藏状态是线性模型、使用batch梯度下降、且学习率为$\eta=1/2$时,TTT层等价于线性注意力(Linear Attention)——即没有softmax的自注意力。这说明TTT层是一个更一般的框架,线性注意力只是其特例。
TTT-E2E:端到端的长上下文突破
2025年12月,斯坦福大学与英伟达联合发表了TTT-E2E,将TTT推向了更实用的方向。
之前的工作存在一个"内外循环不匹配"的问题。内循环(测试时训练)优化的是自监督重建损失,外循环(训练时元学习)优化的是下一个token预测。这两个目标并不完全一致。
TTT-E2E的解决方案是端到端:内外循环使用相同的损失函数——下一个token预测。训练时,模型被训练为"在测试时进行一步预训练后的效果好";测试时,模型真的在上下文上做预训练。
这个设计的直观理解是:模型学会了"如何高效地从上下文中学习"。就像一个学生,不仅学会了知识,还学会了"如何在考试前快速复习"。
TTT-E2E使用标准的Transformer架构,只是将部分MLP层设为"可TTT"的。具体配置是:
- 只更新最后1/4的Transformer块中的MLP层
- 使用滑动窗口注意力(窗口大小8K)作为基础
- TTT的batch size设为1K
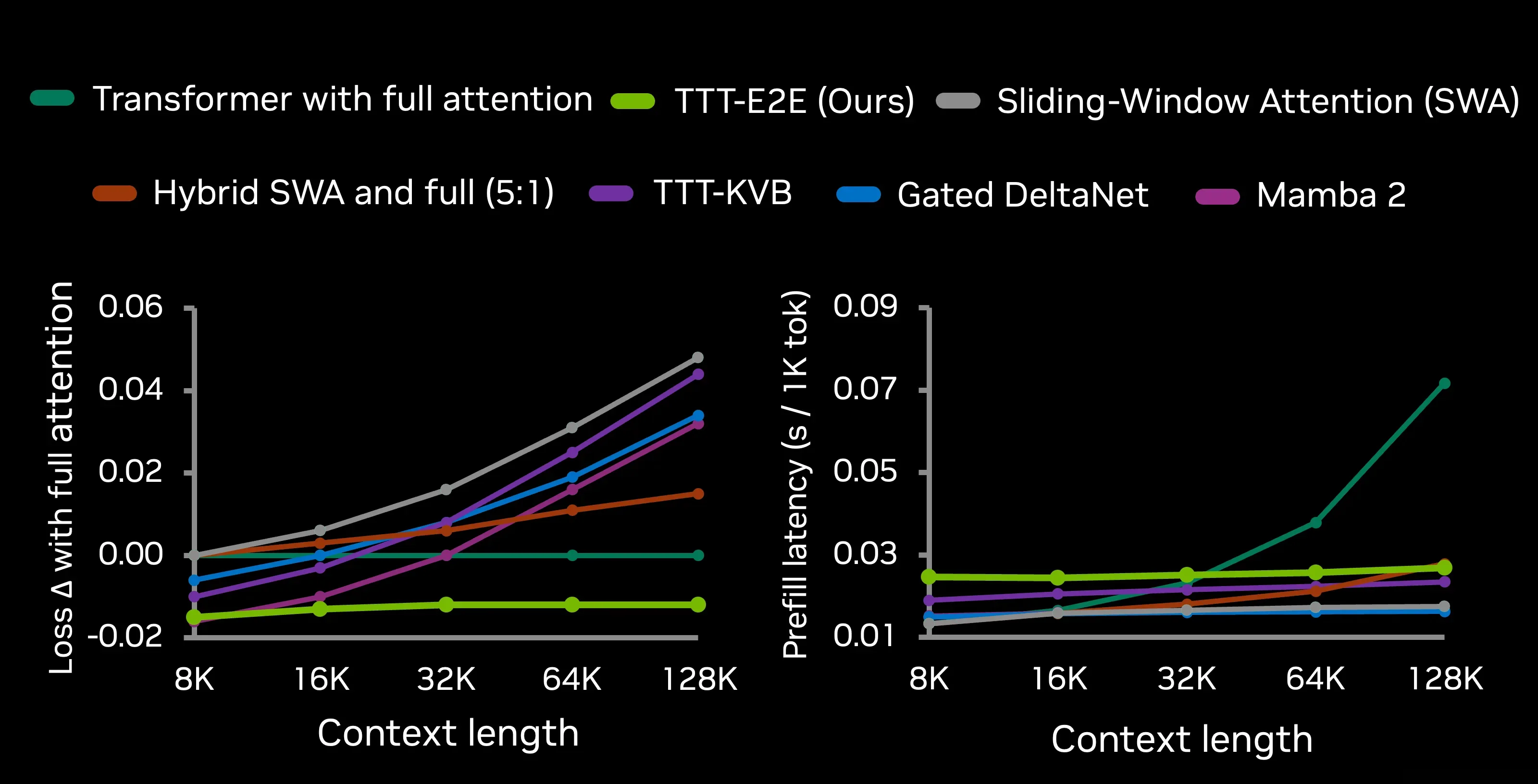
上图展示了不同方法随上下文长度变化的性能:左图为损失差值,右图为推理延迟。TTT-E2E是唯一在损失和延迟两个维度上都表现优异的方法。
实验结果令人印象深刻。在128K上下文时,TTT-E2E的推理延迟与上下文长度无关——因为信息被压缩进了权重,而不是存储在KV Cache中。相比之下,全注意力的Transformer在128K时已经比TTT-E2E慢了约3倍。在2M上下文时,TTT-E2E比全注意力快35倍,同时保持了相当的困惑度。
TTT for ARC:抽象推理的惊人突破
TTT不仅是一种架构创新,更是一种通用的推理范式。2024年11月,MIT的研究团队将TTT应用于ARC(Abstraction and Reasoning Corpus)基准测试,取得了令人瞩目的成果。
ARC是一个极具挑战性的视觉推理基准。每个任务给出2-7个示例,要求模型从示例中归纳出变换规则,然后应用到测试输入上。这些任务是"分布外"的——模型从未见过这些具体的变换规则,必须从少量示例中学习。
研究团队发现,传统的in-context learning在这个场景下效果有限。于是他们尝试了TTT:对于每个测试任务,从示例构造训练数据,然后对模型进行少量步数的微调。
关键的技术细节包括:
- Leave-One-Out任务生成:将示例中的某一个作为"伪测试用例",其余作为训练数据
- 数据增强:使用旋转、翻转、颜色置换等可逆变换扩充数据
- 任务特定的LoRA适配器:每个任务训练一个独立的低秩适配器,而非共享
结果令人震惊:使用8B参数的语言模型,TTT在ARC公共验证集上达到了53%的准确率——比之前最好的纯神经方法提升了25%。当与程序合成方法结合时,准确率达到61.9%,匹配了人类平均水平。这证明了TTT能够显著提升模型对新任务的适应能力。
TTT-Discover:科学发现的新范式
2026年1月,斯坦福大学与英伟达提出了TTT-Discover,将TTT应用于科学发现领域。
与传统的"搜索"方法(如AlphaEvolve)不同,TTT-Discover在测试时进行强化学习。模型在解决特定问题的过程中,从自己的尝试中学习,不断改进策略。
一个关键的设计是熵目标函数(Entropic Objective)。传统的RL优化平均奖励,但科学发现关心的是最大值——找到最好的那一个解。熵目标函数倾向于最大化最高奖励的概率,而非平均奖励。
TTT-Discover在多个领域取得了突破:
- 数学:改进了Erdős最小重叠问题的上界,从0.9780提升到0.9759
- GPU内核工程:在GPUMODE竞赛中,比之前的最佳实现快了14.7%
- 算法设计:在AtCoder算法竞赛中表现优异
值得注意的是,所有这些结果都是使用开源模型gpt-oss-120b实现的,而之前最好的结果需要使用闭源的Gemini模型。
与Test-Time Compute的关系
OpenAI的o1模型引发了对"测试时计算"(Test-Time Compute)的广泛讨论。TTT与o1代表的test-time compute有什么关系?
两者都强调"在推理时投入更多计算",但实现方式不同。o1的方式是通过更长的思维链(Chain-of-Thought)和搜索,让模型"想得更久"。模型参数本身不变,只是推理过程更复杂。
TTT则更进一步:模型参数在推理时被更新。这更接近于"边做边学",而不仅仅是"想得更久"。
一个有趣的观察是:TTT层的隐藏状态大小可以非常大。在760M参数的模型中,TTT-E2E的隐藏状态达到88M参数——远超传统RNN的隐藏状态大小。这说明TTT的"表达能力"瓶颈不在于状态大小,而在于训练效率。
挑战与未来方向
TTT并非完美。当前的主要挑战包括:
训练稳定性:双层优化(内循环+外循环)容易导致梯度爆炸。TTT-MLP在某些设置下仍然不够稳定。
计算开销:虽然推理复杂度是线性的,但训练时需要计算梯度的梯度,开销更大。
理论理解:TTT为什么有效?它与隐式学习、元学习的关系是什么?这些问题仍需深入研究。
与现有架构的融合:TTT层能否与MoE、量化等技术结合?这些方向有待探索。
从更大的视角看,TTT代表了一种范式转变:从"训练一个静态模型"到"训练一个会学习的模型"。这种转变可能深刻影响未来AI系统的设计——不再追求一个万能的模型,而是追求一个能够快速适应特定任务的模型。
参考文献
- Sun, Y., et al. “Learning to (Learn at Test Time): RNNs with Expressive Hidden States.” arXiv:2407.04620, 2024.
- Akyürek, E., et al. “The Surprising Effectiveness of Test-Time Training for Abstract Reasoning.” arXiv:2411.07279, 2024.
- Sun, Y., et al. “End-to-End Test-Time Training for Long Context.” arXiv:2512.23675, 2025.
- Sun, Y., et al. “Learning to Discover at Test Time.” arXiv:2601.16175, 2026.
- Sun, Y. “Test-Time Training with Self-Supervision for Generalization under Distribution Shifts.” NeurIPS 2020.
- Krause, B., et al. “Dynamic Evaluation of Neural Sequence Models.” ICML 2018.
- Hinton, G., Plaut, D. “Using Fast Weights to Deblur Old Memories.” 1987.
- Schlag, I., et al. “Linear Transformers are Secretly Fast Weight Programmers.” ICML 2021.