2018年5月,欧盟《通用数据保护条例》(GDPR)正式生效。条例第17条赋予个人一项特殊权利——“被遗忘权”(Right to be Forgotten):当个人数据不再必要时,数据主体有权要求删除这些数据。对于传统数据库系统,这是一个简单的SQL DELETE语句就能解决的问题。但当这项权利遇上千亿参数的大语言模型,事情变得复杂得多。
2023年12月,《纽约时报》起诉OpenAI侵犯版权,声称GPT-4能够逐字复述其付费文章内容。这起诉讼将一个深层技术问题推到了聚光灯下:一旦数据被大模型"学进"参数里,还能"掏出来"吗?
这个问题的答案,关乎着AI产业的合规前景。
一个不可能完成的任务?
理解机器遗忘的困难,需要先理解大模型是如何"记住"数据的。
传统数据库系统中,数据以结构化形式存储,删除一条记录只需从表中移除对应行。但神经网络的记忆机制完全不同——训练数据的信息被"揉碎"后分散存储在数十亿甚至数千亿个参数中。一个事实性知识(如"埃隆·马斯克出生于南非")可能影响着模型中数千个神经元的权重值,而这些神经元同时又参与存储其他数十万条知识。
这种"分布式表示"带来了两个核心难题:
纠缠性(Entanglement):模型参数没有明确的语义边界。你不能说"第100到200个参数存储了某人的个人信息"——每条数据的影响都像墨水滴入水中,均匀散开,无法分离。
不可逆性(Irreversibility):从最终的模型参数逆向推导"哪些数据影响了哪些参数",在数学上是一个病定问题(ill-posed problem)。同样的参数更新可能由无数种不同的训练数据组合产生。
2015年,来自Lehigh大学的Yinzhi Cao和Junfeng Yang在IEEE S&P会议上首次提出"机器遗忘"概念时,他们面对的还是相对简单的机器学习模型。论文标题直接点明了核心挑战:《Towards Making Systems Forget with Machine Unlearning》。
十年后的今天,当模型参数从百万级跃迁到千亿级,这个问题不仅没有变简单,反而变得更加棘手。
精确遗忘:代价高昂的"完美方案"
机器遗忘方法可以分为两大类:精确遗忘(Exact Unlearning)和近似遗忘(Approximate Unlearning)。
精确遗忘追求一个严格的数学保证:遗忘后的模型,与"从未在要删除的数据上训练过"的模型完全等价。最直观的精确遗忘方法是从头重新训练(Retrain from Scratch)——在移除目标数据后,用剩余数据重新训练模型。这确实能保证完美的遗忘效果,但代价令人望而却步。
一个1750亿参数的模型,训练一次可能需要数百万美元的算力成本。如果每次删除请求都要重新训练,任何企业都无法承受。
2019年,一组来自多所机构的研究者在arXiv上发表了论文《Machine Unlearning》,提出了一个巧妙的框架——SISA训练(Sharded, Isolated, Sliced, and Aggregated Training)。核心思想是:与其在删除时付出高昂代价,不如在训练时就为未来的删除做准备。
SISA将训练数据分成多个"分片"(shards),每个分片独立训练一个子模型。当需要删除某条数据时,只需重新训练包含该数据的那个分片对应的子模型,最后将所有子模型的预测结果聚合即可。
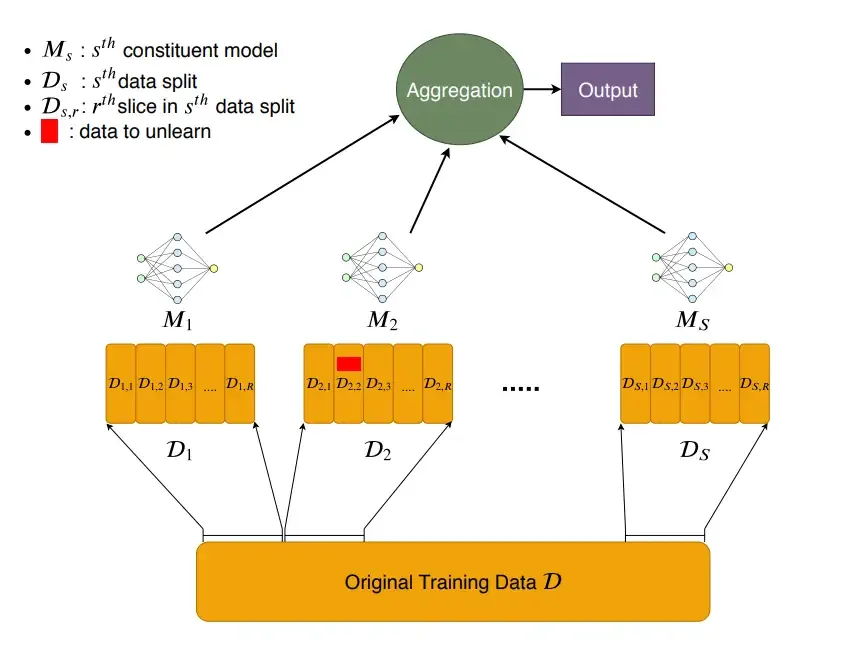
假设将数据分成$S$个分片,最坏情况下(删除请求均匀分布),重训练成本降低到原来的$1/S$。实验数据显示,在Purchase数据集上,SISA将遗忘时间缩短了4.63倍;在SVHN数据集上缩短了2.45倍;即使在ImageNet这样的复杂任务上,也能达到1.36倍的加速。
但SISA有两个致命缺陷:
第一,模型性能下降。由于每个子模型只看到部分数据,其性能通常低于在完整数据上训练的单模型。分片越多,性能损失越大。
第二,不适用于大模型时代。大模型训练需要海量数据来充分学习语言规律。如果将训练数据分片到数十个子模型中,每个子模型的数据量可能不足以支撑有效的语言建模。
更重要的是,SISA是一种"前瞻式"方案——它要求在模型训练之前就规划好遗忘机制。但现实中,大多数删除请求发生在模型已经部署之后。这些限制使得精确遗忘在大模型场景下难以实用化。
近似遗忘:实用主义的技术妥协
近似遗忘接受一个不那么完美的现实:遗忘后的模型可能与"从未学过该数据"的模型存在细微差异,但只要差异足够小、且在实际应用中不可察觉,就可以接受。
这个定义听起来模糊,背后却有严谨的数学形式化。近似遗忘通常使用分布距离来衡量遗忘效果。最常用的是最大均值差异(MMD)或KL散度:如果遗忘模型的输出分布与目标分布(从未学过待删除数据的模型)足够接近,则认为遗忘成功。
Gradient Ascent:反向操作的危险游戏
2023年,大模型遗忘研究迎来爆发期。最早被提出、也最直觉的方法是梯度上升(Gradient Ascent)。
正常的训练过程使用梯度下降最小化损失函数:$\theta_{t+1} = \theta_t - \eta \nabla_\theta L(\theta)$。梯度上升的做法是反向操作:$\theta_{t+1} = \theta_t + \eta \nabla_\theta L(\theta)$,即在要遗忘的数据上最大化损失。
这个想法的直觉很清晰:既然训练是让模型"记住"数据,那么反向操作应该能让模型"忘记"。但实践证明,这种方法极其危险。
2024年ICLR的一篇论文《Negative Preference Optimization》揭示了问题所在:梯度上升容易导致灾难性崩塌(Catastrophic Collapse)。在追求"遗忘"的过程中,模型不仅失去了目标知识,还可能丧失基础的语言能力——输出变成毫无意义的乱码。
更深层的问题在于:最大化损失并不等于最小化"记住"程度。损失函数衡量的是预测与标签的差异,而不是记忆强度。模型完全可以通过输出随机噪声来实现高损失,但这显然不是我们想要的"遗忘"。
NPO:从对齐中学到的教训
2024年4月,斯坦福大学团队提出了负偏好优化(Negative Preference Optimization, NPO),借鉴了DPO(Direct Preference Optimization)的思想,将遗忘问题转化为一个优化问题。
DPO的核心思想是:将偏好数据(“这个回答比那个回答好”)转化为一个可优化的目标函数。NPO将其推广到遗忘场景:将"要遗忘的数据"视为"负偏好",让模型学会回避这类输出。
NPO的损失函数形式为:
$$L_{\text{NPO}} = -\mathbb{E}_{(x,y) \sim D_f} \left[ \log \sigma\left( \beta \log \frac{\pi_\theta(y|x)}{\pi_{\text{ref}}(y|x)} \right) \right]$$其中$D_f$是要遗忘的数据集,$\pi_\theta$是当前模型,$\pi_{\text{ref}}$是参考模型(通常是最初的预训练模型),$\beta$是控制遗忘强度的超参数。
这个公式背后的直觉是:让模型在遗忘数据上的输出概率,尽可能低于参考模型的输出概率。与梯度上升不同,NPO不会鼓励模型输出随机噪声,而是引导它回归到一个"不知道这些信息"的状态。
实验结果令人振奋。在TOFU基准测试上,NPO是首个能够成功遗忘50%训练数据且保持模型效用的方法。相比之下,梯度上升方法在遗忘10%数据时就已经捉襟见肘。
RMU:表示层面的干预
2024年3月发布的WMDP基准测试论文同时提出了一种新方法——表示误导遗忘(Representation Misdirection Unlearning, RMU)。这种方法不再在输出层面操作,而是直接干预模型的内部表示。
RMU的核心洞察是:知识在模型中以"表示向量"的形式存储。如果我们能扰乱与目标知识相关的表示,就能实现遗忘。
具体而言,RMU在模型的中间层注入噪声,使得模型在面对遗忘数据时产生"错误"的内部表示。这种干预是精心设计的:它只在检测到输入与遗忘数据相关时才激活,从而最小化对其他能力的影响。
WMDP论文的实验显示,RMU能够将模型在危险知识(如生物武器制造)上的表现降低到随机水平,同时保持其在相关领域(如普通生物学)上的正常表现。
评估的困境:如何证明"真的忘了"
机器遗忘面临一个独特的挑战:如何证明遗忘成功?
传统的机器学习任务有清晰的评估指标——准确率、F1分数、BLEU等。但遗忘是一个"负向"目标:我们希望模型"做不到"某事。如何量化"做不到"的程度?
TOFU:虚构世界的遗忘测试
2024年发布的TOFU(Task of Fictitious Unlearning)基准测试采用了一个巧妙的设计:创建一组完全虚构的作者传记数据,让模型学习这些不存在的"知识",然后测试模型遗忘这些知识的能力。
由于这些作者是虚构的,模型的预训练数据中从未出现过相关信息。这消除了一个关键干扰因素:我们不用担心模型通过其他途径"知道"这些信息。
TOFU定义了两类数据集:
- Forget Set:需要遗忘的数据(如某位虚构作者的生平)
- Retain Set:需要保留的数据(其他虚构作者的信息)
评估指标包括:
- Model Utility:模型在Retain Set上的表现,衡量遗忘是否影响了其他能力
- Forget Quality:通过KS检验比较遗忘模型和参考模型在Forget Set上的输出分布
MUSE:六维全面评估
2024年7月发布的MUSE基准测试提出了更全面的评估框架,定义了六项期望属性:
- No Memorization:模型不应能回忆起遗忘数据的具体内容
- No Knowledge Sensitive:模型不应展现出对遗忘数据相关概念的"隐性偏好"
- No Privacy Leakage:不应能通过成员推断攻击检测到数据曾被用于训练
- No Extraction:不应能通过特定提示提取遗忘数据的内容
- Maintain Utility:遗忘不应损害模型在其他任务上的能力
- No Recovery:即使使用对抗性查询,也不应能恢复遗忘的知识
WMDP:危险知识的遗忘测试
WMDP(Weapons of Mass Destruction Proxy)聚焦于一个特殊场景:让模型"忘记"制造危险武器的知识。基准包含3,668道选择题,覆盖生物安全、网络安全和化学安全三个领域。
WMDP的价值在于其明确的实用背景。2023年美国总统行政令明确要求评估AI系统的危险能力。WMDP为这类评估提供了公开、标准化的工具。
遗忘的脆弱性:量化恢复的惊人发现
2024年10月,一篇发表在ICLR 2025的论文揭示了一个令人不安的现象:量化可能恢复被遗忘的知识。
研究者发现,当对经过遗忘处理的模型进行4-bit量化时,被"遗忘"的知识有83%被恢复了。即使在全精度下,遗忘模型仍然保留了21%的目标知识。
这个发现的意义深远。量化是大模型部署的标配技术——它可以将模型大小压缩到原来的1/4,使大规模部署成为可能。但如果量化能恢复被遗忘的知识,那么现有的遗忘方法在实际部署中可能完全失效。
为什么会发生这种现象?
研究者提出了一种解释:遗忘方法(尤其是梯度上升)倾向于"压制"目标知识相关的神经元激活,但这些神经元的参数值并未发生根本改变。量化过程中的舍入误差可能"释放"这些被压制的激活,导致知识恢复。
另一个深层原因在于神经网络参数的冗余性。大模型通常存在大量冗余参数,同样的功能可以由不同的参数组合实现。遗忘方法可能只影响了一条"路径",而知识的"备份"仍然存在。
对抗攻击:被遗忘者的反击
量化恢复只是一个开始。更严峻的挑战来自对抗性攻击。
2025年的研究表明,通过精心设计的提示,攻击者可以从"已遗忘"的模型中提取出被删除的知识。一种称为REBEL的方法通过进化搜索策略,成功从多个声称已遗忘的模型中恢复了敏感信息。
这揭示了遗忘技术的根本性困境:遗忘不是一个二元状态,而是一个连续谱。模型可能"表面上"遗忘了某些知识,但在特定的查询模式下,这些知识可能被重新激活。
法律与技术的鸿沟
机器遗忘领域面临的最深层挑战,或许是法律框架与技术现实之间的巨大鸿沟。
GDPR第17条要求"删除"个人数据,但"删除"在AI语境下意味着什么?
传统数据库中的删除是一个确定性操作:数据要么存在,要么不存在。但在神经网络中,数据的影响被"溶解"到参数空间中。即使我们应用了遗忘技术,也无法数学证明某个人的数据"完全"消失了——只能证明其影响被"足够大地"降低了。
这种不确定性给合规带来了巨大挑战。企业如何证明自己履行了删除义务?当用户质疑"你们真的删除了我的数据吗?",法律上什么程度的遗忘才算合规?
更复杂的是版权问题。《纽约时报》诉OpenAI案的核心争议在于:当受版权保护的内容被"学进"模型参数后,模型对这类内容的生成是否构成侵权?如果侵权成立,版权人是否有权要求模型"遗忘"相关内容?
这些问题目前没有明确的法律答案。技术界和法学界都在探索中。
遗忘的未来
机器遗忘是一个年轻的领域,2024年之前的研究甚至难以称之为一个"领域",更多是零散的技术尝试。但随着GDPR等隐私法规的严格执行,以及版权诉讼的升温,这项技术正在获得前所未有的关注度。
目前的共识是:完美的遗忘几乎不可能实现。近似遗忘方法虽然无法达到精确遗忘的理论保证,但在实践中可能"足够好"——如果遗忘后的模型在面对绝大多数查询时都无法提取目标知识,或许就能满足合规要求。
更根本的问题可能在于模型架构本身。如果神经网络天然无法实现可靠的遗忘,也许我们需要重新思考模型的设计。一些研究者开始探索"可解释遗忘"的架构——从设计上就考虑遗忘需求,让知识的存储更加模块化、可定位。
在这个AI正在深入社会每个角落的时代,机器遗忘不仅仅是一个技术问题。它关乎数据主权、隐私权、知识产权,以及我们如何构建一个"负责任"的AI生态系统。答案尚未清晰,但问题本身已经无法回避。
参考文献
- Cao, Y., & Yang, J. (2015). Towards Making Systems Forget with Machine Unlearning. IEEE S&P 2015.
- Bourtoule, L., et al. (2021). Machine Unlearning. IEEE S&P 2021.
- Zhang, R., et al. (2024). Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning. ICLR 2025.
- Li, N., et al. (2024). The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning. ICML 2024.
- Maini, P., et al. (2024). TOFU: A Task of Fictitious Unlearning for LLMs. arXiv:2401.06121.
- Shi, W., et al. (2024). MUSE: Machine Unlearning Six-Way Evaluation for Language Models. arXiv:2407.06460.
- Wang, F., et al. (2024). Catastrophic Failure of LLM Unlearning via Quantization. ICLR 2025.
- Geng, J., et al. (2025). A Comprehensive Survey of Machine Unlearning Techniques for Large Language Models. arXiv:2503.01854.
- Tech Policy Press. (2025). The Right to Be Forgotten Is Dead: Data Lives Forever in AI.
- OpenAI. (2023). Reporting the facts about the New York Times’ lawsuit.