Hugging Face 上托管着超过50万个预训练模型,每天都有新的微调版本被上传。一个团队可能为文本分类训练了BERT,另一个团队为命名实体识别微调了T5,第三个团队为情感分析优化了RoBERTa。当需要构建一个同时具备这三种能力的系统时,传统做法是部署三个独立模型——但这意味着三倍的存储成本、三倍的GPU显存占用和三倍的推理延迟。
多任务学习理论上可以解决这个问题,但它需要同时访问所有任务的训练数据,且训练成本高昂。2023年,一个名为Task Arithmetic的方法在ICLR会议上发表,研究者们发现了一个令人惊讶的事实:只需要简单的加减法运算,就能将多个微调模型的能力"融合"到一个模型中,完全不需要重新训练。
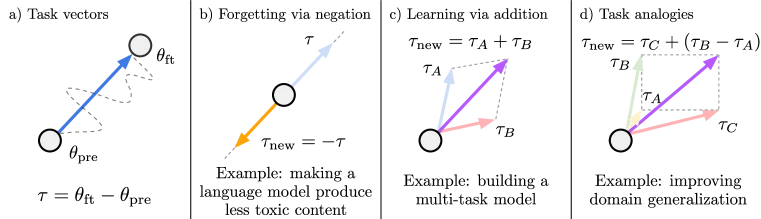 图1: Task Arithmetic的三种核心操作:任务向量定义、遗忘(取反)、学习(加法)、任务类比(来源:Ilharco et al., ICLR 2023)
图1: Task Arithmetic的三种核心操作:任务向量定义、遗忘(取反)、学习(加法)、任务类比(来源:Ilharco et al., ICLR 2023)
任务向量:参数空间中的方向
Task Arithmetic的核心洞见是**任务向量(Task Vector)**的概念。给定一个预训练模型 $\theta_{\text{pre}}$ 和针对任务 $t$ 微调后的模型 $\theta_t^{\text{ft}}$,任务向量定义为两者之差:
$$\tau_t = \theta_t^{\text{ft}} - \theta_{\text{pre}}$$这个看似简单的减法操作揭示了一个深刻的事实:微调过程中参数的变化方向和幅度,编码了特定任务所需的知识。研究者发现,不同任务的任务向量在参数空间中接近正交——这意味着它们指向不同的"技能方向"。
基于这一发现,多任务学习变成了简单的向量加法:
$$\theta_{\text{new}} = \theta_{\text{pre}} + \lambda \sum_{i=1}^{n} \tau_i$$其中 $\lambda$ 是缩放系数。更令人惊讶的是,减法同样有效:$\theta_{\text{pre}} - \lambda \tau_{\text{toxic}}$ 可以让模型"遗忘"生成有毒内容的能力。研究显示,当合并两个任务向量时,归一化准确率可以达到98.9%,几乎与独立微调模型相当。
干扰问题:为什么简单相加会失败
然而,当合并的模型数量增加时,Task Arithmetic的效果开始下降。2023年NeurIPS会议上发表的TIES-Merging论文揭示了原因:参数之间存在两种类型的干扰(Interference)。
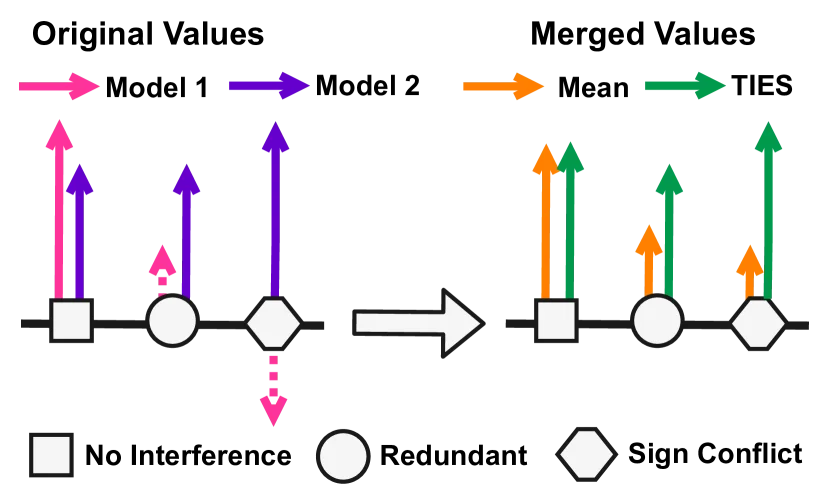 图2: 两种参数干扰:冗余参数干扰(#)和符号冲突干扰(©)(来源:Yadav et al., NeurIPS 2023)
图2: 两种参数干扰:冗余参数干扰(#)和符号冲突干扰(©)(来源:Yadav et al., NeurIPS 2023)
第一种干扰来自冗余参数。 研究者发现,在微调过程中,大多数参数只发生微小变化,真正对任务性能有贡献的参数只占少数。实验表明,保留任务向量中幅度最大的20%参数,性能几乎不下降。当合并多个模型时,这些"噪声参数"会稀释有意义的信号。
第二种干扰来自符号冲突。 同一个参数在不同任务中可能需要相反的变化方向——对于任务A,该参数需要增加;对于任务B,该参数需要减少。简单平均会使两者相互抵消,导致合并后该参数的值接近零,损害两个任务的性能。
研究者绘制了符号冲突的比例曲线:当合并两个模型时,冲突参数约占5%;当合并十个模型时,这个比例上升到25%以上。更关键的是,符号冲突随着模型数量的增加呈现加速增长趋势。
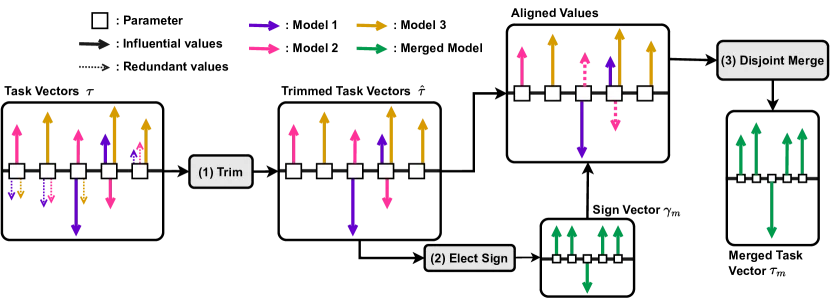 图3: TIES-Merging的三步流程:Trim(修剪)、Elect Sign(选举符号)、Disjoint Merge(分离合并)(来源:Yadav et al., NeurIPS 2023)
图3: TIES-Merging的三步流程:Trim(修剪)、Elect Sign(选举符号)、Disjoint Merge(分离合并)(来源:Yadav et al., NeurIPS 2023)
TIES-Merging:修剪、选举、合并
针对上述问题,TIES-Merging提出了三步解决方案:
第一步:修剪(Trim)。 对于每个任务向量,只保留幅度最大的top-k%参数(通常k=20),其余参数重置为零。这一步消除了大部分冗余参数的干扰。
第二步:选举符号(Elect Sign)。 对于每个参数位置,统计所有模型中正负值的出现情况,选择"总质量"更大的方向作为最终符号。形式化地,设第 $p$ 个参数在各个模型中的值为 $\{\hat{\tau}_p^t\}_{t=1}^n$,则选举符号为:
$$\gamma_p^m = \text{sgn}\left(\sum_{t=1}^{n} \hat{\tau}_p^t\right)$$第三步:分离合并(Disjoint Merge)。 对于每个参数,只保留符号与选举结果一致的模型的值,计算它们的平均值。设 $A_p = \{t \in [n] \mid \hat{\gamma}_p^t = \gamma_p^m\}$,则:
$$\tau_p^m = \frac{1}{|A_p|} \sum_{t \in A_p} \hat{\tau}_p^t$$实验结果显示,在NLP任务上,TIES-Merging比最强基线平均提升2.3%;在视觉任务上提升1.7%。当合并多个模型时,优势更加明显——合并八个模型时,Task Arithmetic的归一化准确率下降到约85%,而TIES-Merging保持在95%以上。
DARE:随机丢弃的魔力
2024年,另一项名为**DARE(Drop And REscale)**的研究提出了一个更激进的发现:我们可以随机丢弃90%甚至99%的任务向量参数,性能几乎不受影响。
DARE的两步操作如下:
- Drop:以概率 $p$ 将任务向量中的每个参数随机置零
- Rescale:将保留的参数乘以 $\frac{1}{1-p}$
这个方法背后的直觉是:神经网络严重过参数化,大部分参数的变化是冗余的。Rescale步骤确保了期望值的稳定性:
$$\mathbb{E}[\hat{\tau}] = (1-p) \cdot \frac{\tau}{1-p} + p \cdot 0 = \tau$$研究者将DARE与TIES-Merging结合,进一步提升了合并效果。在LLaMA系列模型的实验中,DARE+TIES的组合在多个基准测试上超越了单独使用任何一种方法。
理论视角:线性模式连接性
为什么模型合并在理论上是可行的?答案在于线性模式连接性(Linear Mode Connectivity, LMC)。
深度神经网络的损失景观通常是非凸的,存在大量局部最小值。然而,研究发现,从同一个预训练模型微调得到的多个模型,往往可以通过线性插值连接而不显著增加损失。这意味着这些模型位于损失景观的同一个"盆地"中。
LMC的数学定义为:对于两个模型 $\theta_1$ 和 $\theta_2$,如果对于所有 $\lambda \in [0,1]$,有:
$$L(\lambda \theta_1 + (1-\lambda)\theta_2) \approx \lambda L(\theta_1) + (1-\lambda)L(\theta_2)$$则称这两个模型满足LMC。当LMC成立时,参数空间的线性组合对应于功能空间的近似叠加。
进一步的研究揭示了**权重解耦(Weight Disentanglement)**现象:在预训练阶段,模型学会了将不同的输入空间区域映射到不同的权重空间方向。这意味着,当微调改变某个权重方向时,它主要影响特定的输入子集,而不会干扰其他输入的处理。这正是模型合并能够"各司其职"的深层原因。
工程实践:MergeKit
对于想要尝试模型合并的开发者,开源工具MergeKit提供了现成的解决方案。它支持多种合并方法:
# MergeKit配置示例
merge_method: ties
base_model: meta-llama/Llama-2-7b-hf
models:
- model: model_a
parameters:
weight: 1.0
- model: model_b
parameters:
weight: 1.0
parameters:
density: 0.2 # 保留top 20%参数
normalize: true
MergeKit支持的方法包括:简单平均(Linear)、球面线性插值(SLERP)、Task Arithmetic、TIES-Merging、DARE等。工具已集成到Hugging Face生态系统中,用户可以直接通过Python API调用。
实际应用中,MergeKit已被用于创建多个知名开源模型。例如,OpenChat模型通过合并多个微调版本获得了更好的对话能力;某些Stable Diffusion变体通过合并不同风格的模型实现了风格混合。
局限与未来方向
尽管模型合并技术取得了显著进展,但仍存在局限性:
性能差距:合并模型与多任务联合训练之间仍存在性能差距。当任务数量增加到20个以上时,差距变得更加明显。
架构限制:现有方法要求参与合并的模型具有相同的架构,且通常需要从同一个预训练模型微调而来。对于异构模型的合并,需要额外的架构转换步骤。
符号估计的瓶颈:TIES-Merging的核心是正确估计符号向量。研究者发现,如果使用多任务联合训练模型的符号作为"神谕",合并性能可以接近联合训练水平——但获取这个神谕恰恰需要昂贵的多任务训练。
未来研究方向包括:自适应合并系数学习、无需验证集的超参数选择、以及将模型合并与其他技术(如LoRA、量化)结合以降低存储成本。
参考文献
- Ilharco G, Ribeiro M T, Wortsman M, et al. Editing models with task arithmetic[C]//ICLR. 2023.
- Yadav P, Tam D, Choshen L, et al. TIES-Merging: Resolving interference when merging models[C]//NeurIPS. 2023.
- Yu L, Yu F, Mahajan H, et al. Language models are supertools: Zero-shot task adaptability in the weight space[J]. arXiv:2402.05840, 2024.
- Yang E, Liu Z, Wang S, et al. Model merging in LLMs, MLLMs, and beyond: Methods, theories, applications and opportunities[J]. arXiv:2408.07666, 2024.
- Ortiz-Jimenez G, Favero A, Frossard P. Task arithmetic in the tangent space: Improved editing of pre-trained models[C]//NeurIPS. 2023.
- Frankle J, Dziugaite G K, Roy D, et al. Linear mode connectivity and the lottery ticket hypothesis[C]//ICML. 2020.
- Godfrey J. MergeKit: Tools for merging large language models[J]. GitHub Repository, 2024.