2016年3月,Yury Malkov和Dmitry Yashunin在arXiv上发表了一篇题为《Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs》的论文。这篇论文提出的HNSW算法,在随后的几年里成为了几乎所有主流向量数据库的核心索引——Elasticsearch、Milvus、Pinecone、Weaviate、Qdrant无一例外。
这不是偶然。当大语言模型引爆RAG(检索增强生成)应用时,一个被忽视的事实浮出水面:检索质量决定了LLM看到的"真相"。而HNSW正是那个决定检索速度与质量平衡点的关键技术。
维度诅咒:向量检索的根本困境
要理解HNSW的价值,必须先回到问题的起点——高维空间中最近邻搜索的复杂性。
假设你有一个包含100万个128维向量的数据集,用户提交一个查询向量,你需要找出最相似的10个。最直观的方法是暴力搜索:计算查询向量与每个数据向量的距离,排序后返回前10个。这个方法的时间复杂度是 $O(N \cdot d)$,其中 $N$ 是向量数量,$d$ 是维度。
对于100万个128维向量,现代CPU可以在几十毫秒内完成这个计算。但问题在于,当 $N$ 增长到10亿、100亿时,暴力搜索的延迟会线性增长,变得不可接受。
更深层的问题在于维度诅咒(Curse of Dimensionality)。在低维空间中,我们可以用k-d树、R树等空间划分数据结构来加速搜索。但在高维空间中,这些方法会退化到接近暴力搜索的效率。
原因在于高维空间的几何特性:随着维度增加,数据点变得越来越"稀疏",距离度量也变得越来越"均匀"。1998年,Arya等人在一篇经典论文中证明,对于 $d$ 维空间中的精确最近邻搜索,任何数据结构都需要 $\Omega(N^{1-1/d})$ 的查询时间。当 $d$ 较大时(比如128维),这个下界接近线性扫描。
这意味着:在高维空间中,我们无法同时获得完美的精度和极致的速度。必须做出妥协。
近似最近邻搜索(Approximate Nearest Neighbor, ANN)应运而生。核心思想是:不追求找到真正的最近邻,而是以高概率找到一个"足够接近"的邻居。这个妥协让搜索复杂度从 $O(N)$ 降到了 $O(\log N)$ 甚至更低。
六度分隔:小世界网络的理论根基
HNSW的核心思想来自一个看似无关的社会学发现。
1967年,哈佛大学社会心理学家Stanley Milgram进行了一项著名实验。他随机选取了几个起始人,要求他们尝试将一封信传递给一个指定的目标人物。传递规则是:只能传给自己认识的人,且每次只能传递一步。实验结果令人惊讶:大部分信件只需要5-6次传递就能到达目标。
这就是著名的"六度分隔“理论——地球上任意两个人之间,平均只隔着6个认识的人。
从图论角度看,这个发现揭示了一个重要性质:小世界网络。在这样的网络中,大部分节点之间只通过很短的路径相连,尽管网络整体规模可能非常庞大。
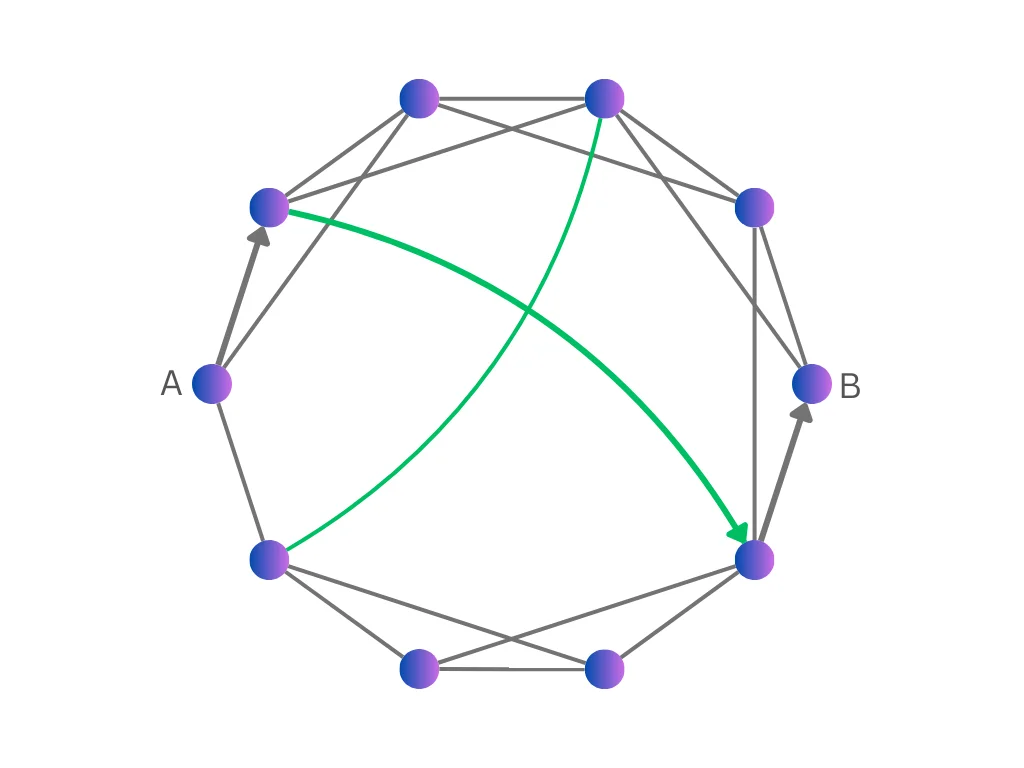
图片来源: Towards Data Science
上图中,灰色连接是本地链接(连接邻近节点),绿色连接是远程链接(连接遥远节点)。远程链接的存在使得任意两点之间可以用很少的步骤到达——比如从A到B只需要3步。
2000年,康奈尔大学的Jon Kleinberg提出了一个关键问题:Milgram实验中,人们是如何在不知道全局网络结构的情况下找到短路径的?
答案在于贪心路由(Greedy Routing):每个人只需要把信传给自己认识的所有人中,“最可能认识目标"的那个人。这个过程本身不需要全局知识,只需要局部信息。
Kleinberg进一步发现,贪心路由能否高效工作,取决于远程链接的分布方式。如果远程链接的长度服从特定分布(精确地说,长度为 $d$ 的链接概率正比于 $d^{-\alpha}$,其中 $\alpha$ 等于空间维数),则贪心路由可以在 $O(\log^2 N)$ 步内找到目标。
这个发现催生了可导航小世界(Navigable Small World, NSW)的概念:一个网络如果能够通过贪心路由在多项式对数时间内找到任意节点,就被称为"可导航"的。
NSW:第一个可工作的图索引
2011年至2014年间,Malkov等人将NSW理论应用于向量搜索,提出了一种简单而有效的方法来构建可导航小世界图。
核心思想是:按随机顺序逐个插入向量,每个新向量连接到图中已存在的最近邻节点。
这个看似简单的策略产生了一个有趣的效果:最早插入的向量往往是随机选择的,它们之间的距离较远,因此形成"远程链接”;后期插入的向量更可能连接到附近的节点,形成"本地链接”。这种自然的链接分布恰好满足可导航小世界的条件。

图片来源: Towards Data Science
上图展示了NSW的构建过程:向量按随机顺序插入,每个新向量连接到最近的 $m=2$ 个已插入向量。注意早期插入的向量(红色)形成了远程链接,而后期插入的向量形成了本地连接。
搜索时,从任意一个入口节点开始,贪心地移动到当前节点的邻居中距离查询向量最近的那个。重复这个过程直到无法找到更近的邻居——此时到达了局部最优。
NSW算法虽然有效,但存在一个关键问题:早期插入的"枢纽节点"会积累大量连接。因为这些节点很早就存在,后续插入的向量都可能尝试连接它们。这导致搜索时需要检查大量邻居,增加了计算开销。
具体来说,虽然搜索路径长度是 $O(\log N)$,但每一步需要检查的邻居数量可能也是 $O(\log N)$,导致总复杂度达到 $O(\log^2 N)$。
HNSW:分层结构的设计智慧
HNSW的核心创新在于:将链接按长度分离到不同的层。
想象一座多层建筑。顶层只有少数几个"枢纽"节点,它们之间通过长距离链接相连。往下每一层,节点数量增加,链接变短、变密。底层(第0层)包含所有节点,只有本地链接。
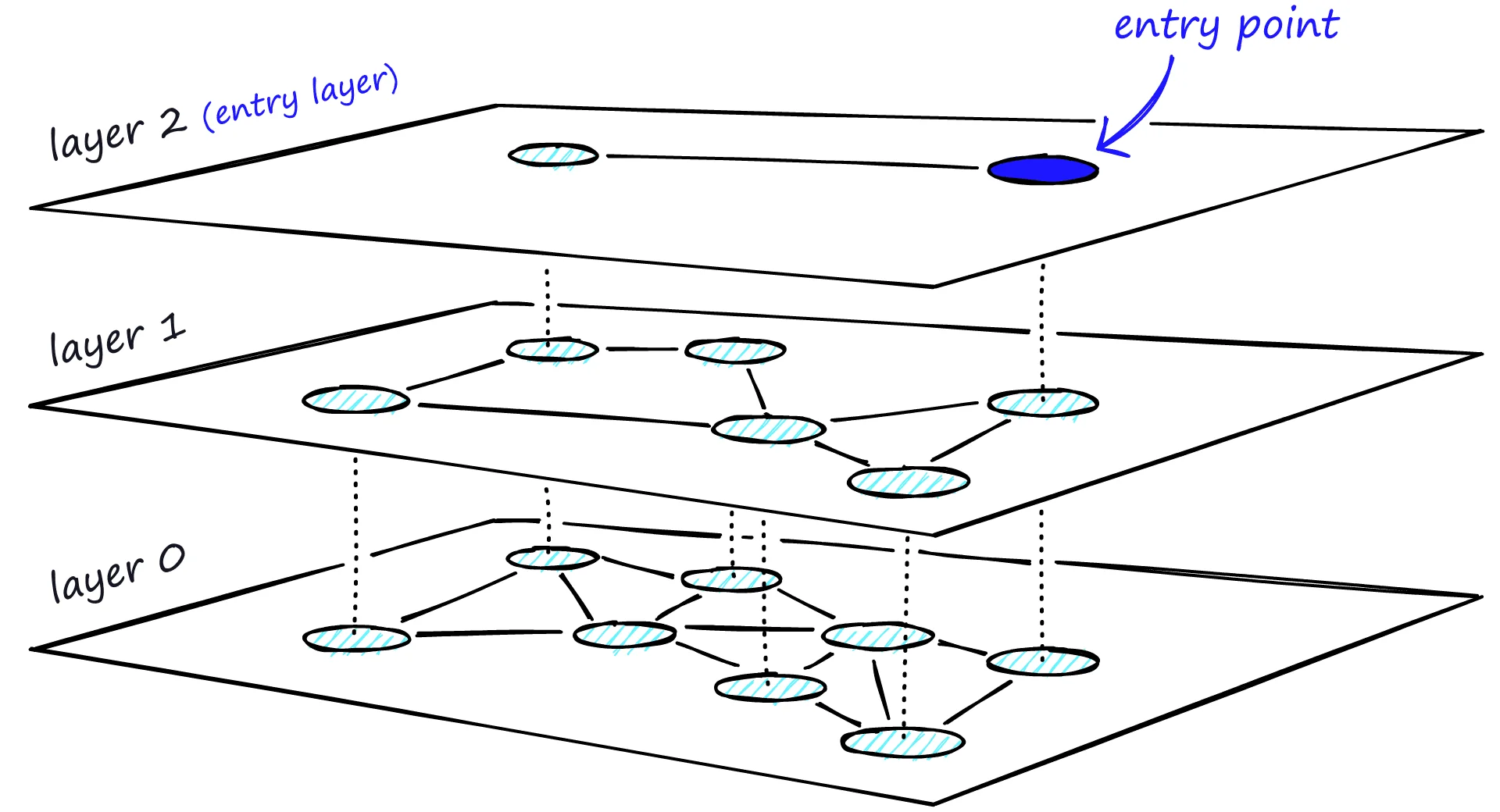
图片来源: Pinecone
这种分层结构带来了两个关键优势:
第一,搜索效率大幅提升。 搜索从顶层开始,这里只有长距离链接和少量节点,可以快速"跳跃"到目标附近。然后逐层向下,每层的搜索范围越来越精确。由于每层的节点数量和链接数量都受到严格控制,每步操作的开销是常数级别的,总复杂度降到了 $O(\log N)$。
第二,避免了枢纽节点的邻居爆炸问题。 在NSW中,早期插入的节点会积累大量邻居。而在HNSW中,一个节点在不同层可以有不同数量的连接——高层链接数量少但距离远,底层链接数量多但距离近。
节点的层级分配
HNSW使用一个随机函数来决定每个节点出现在哪些层。具体来说,一个节点出现在第 $l$ 层及以上的概率是:
$$P(level \geq l) = e^{-l/m_L}$$其中 $m_L$ 是一个参数,通常设为 $1/\ln(M)$,$M$ 是每个节点的最大连接数。
这个概率分布意味着:
- 所有节点都出现在第0层
- 约 $e^{-1/m_L}$ 比例的节点出现在第1层
- 约 $e^{-2/m_L}$ 比例的节点出现在第2层
- 以此类推
结果是一个金字塔结构:顶层最稀疏,底层最稠密。典型情况下,如果 $M=16$,那么:
- 第0层包含100%的节点
- 第1层包含约13%的节点
- 第2层包含约1.7%的节点
- 第3层包含约0.2%的节点
搜索过程详解
HNSW的搜索可以分为三个阶段:
第一阶段:顶层贪心搜索。 从顶层的入口节点开始,执行贪心搜索。在当前节点的所有邻居中,选择距离查询向量最近的那个,移动过去。重复直到找不到更近的邻居。
第二阶段:逐层下降。 找到当前层的局部最优后,移动到下一层的同一个节点,继续贪心搜索。这个过程在每一层重复。
第三阶段:底层候选搜索。 在第0层,不再使用简单的贪心搜索,而是维护一个大小为 efSearch 的候选集。这个候选集包含搜索过程中遇到的所有"有潜力"的节点。搜索结束后,从候选集中选出距离最近的 $k$ 个节点作为结果。
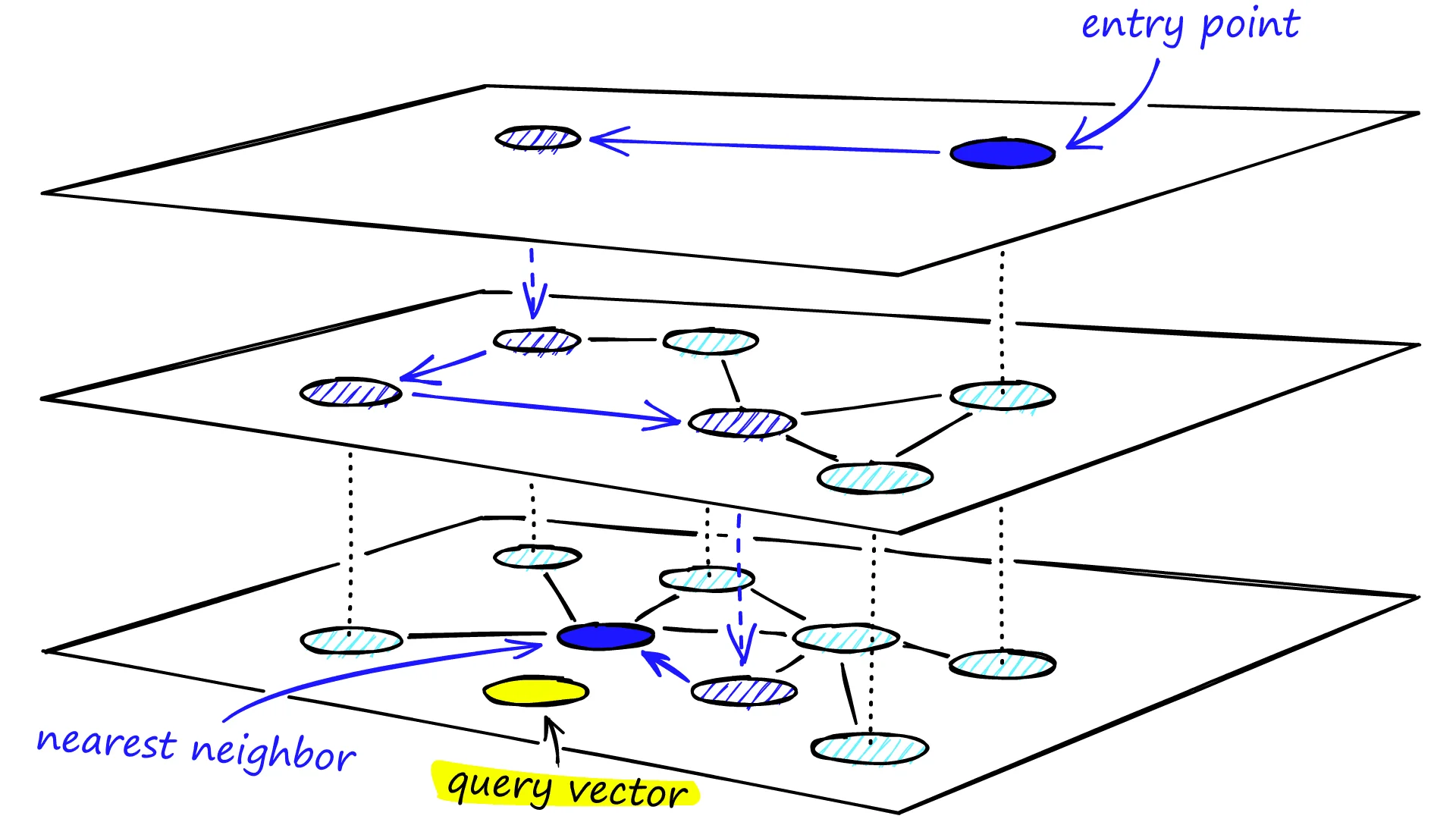
图片来源: Pinecone
上图展示了完整的搜索路径:从顶层入口点开始,通过贪心搜索逐层下降,最终在第0层找到最近邻。
插入过程详解
插入一个新向量时,HNSW执行以下步骤:
-
确定层级。 使用随机函数确定新节点出现在哪些层。假设结果是最多出现在第 $l_{new}$ 层。
-
从顶层开始搜索入口点。 从顶层的入口节点开始,执行贪心搜索找到当前层距离新节点最近的节点。这个节点成为下一层的入口点。重复直到到达第 $l_{new}$ 层。
-
从 $l_{new}$ 层开始插入。 在第 $l_{new}$ 层,使用候选搜索找到距离新节点最近的
efConstruction个节点。从中选择最多 $M$ 个作为新节点的邻居,并建立双向连接。 -
逐层向下插入。 继续在第 $l_{new}-1$ 层、$l_{new}-2$ 层…执行同样的操作,直到第0层。在第0层,每个节点可以有多达 $2M$ 个邻居。
-
简化邻居列表。 如果某个邻居的连接数超过了上限,需要修剪其邻居列表。HNSW使用一种启发式方法:不仅考虑距离,还考虑邻居之间的"多样性",避免所有邻居都聚集在一个小区域。
参数调优:三个关键旋钮
HNSW的性能很大程度上取决于三个关键参数的设置:
M:每层最大连接数
$M$ 决定了每个节点在每层(除第0层外)可以拥有的最大邻居数量。第0层允许最多 $2M$ 个邻居。
- 更大的 $M$ 意味着图更加稠密,搜索时有更多路径可选择,召回率更高。但代价是更大的内存占用和更慢的索引构建速度。
- 更小的 $M$ 意味着图更加稀疏,内存占用更少,但可能导致搜索陷入局部最优,召回率下降。
实践中,$M$ 通常设置在16到64之间。Pinecone的基准测试显示,对于Sift1M数据集(100万个128维向量),$M=32$ 是一个不错的起点。
efConstruction:构建时搜索宽度
efConstruction 控制索引构建时,每一层为插入节点寻找邻居时的候选集大小。
- 更大的
efConstruction意味着构建时考虑更多候选,图的质量更高,最终召回率更好。代价是更慢的构建速度。 - 更小的
efConstruction意味着更快的构建速度,但可能牺牲图质量。
值得注意的是,efConstruction 主要影响构建时间,对搜索时间的影响较小(除非查询量非常大)。因此,如果构建时间不是瓶颈,建议设置较高的值(如200-400)。
efSearch:查询时搜索宽度
efSearch 控制查询时,第0层候选集的大小。这是最常在运行时调整的参数。
- 更大的
efSearch意味着更彻底的搜索,更高的召回率,但更慢的查询速度。 - 更小的
efSearch意味着更快的查询速度,但可能错过真正的最近邻。
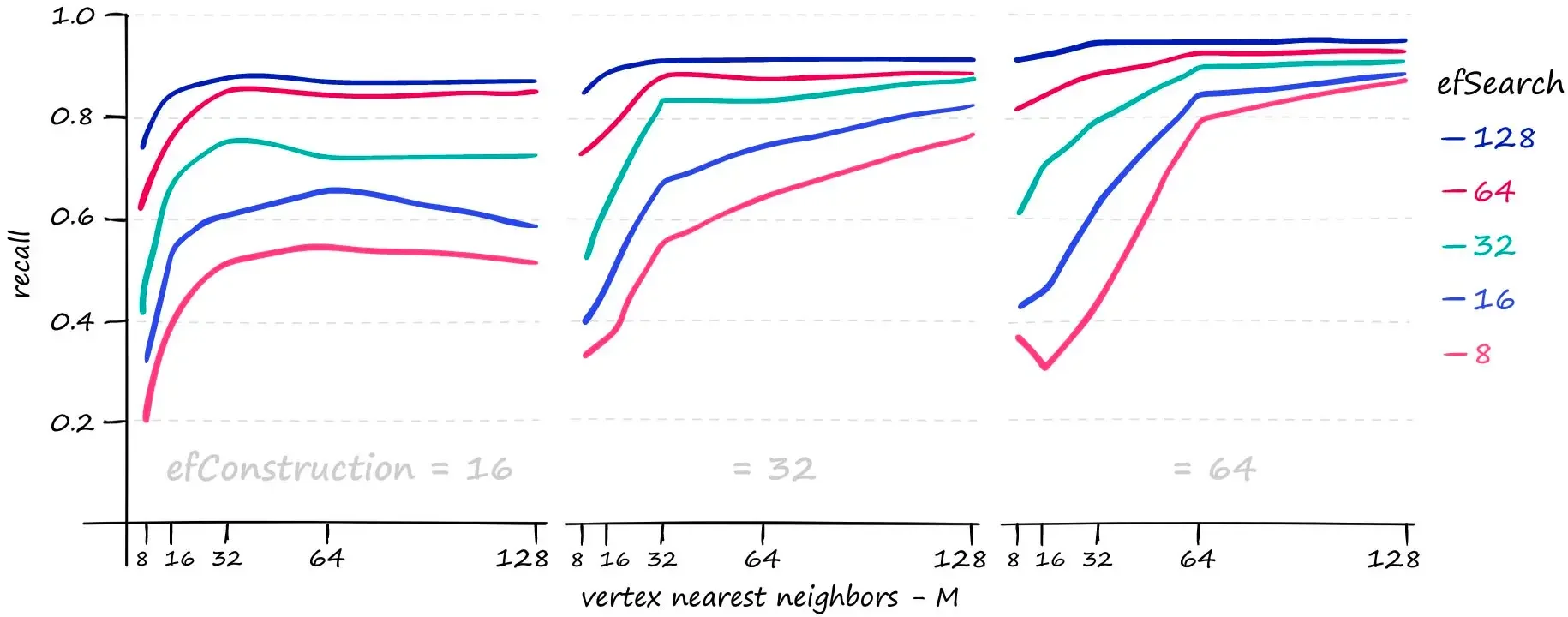
图片来源: Pinecone
上图展示了不同参数组合下的召回率。可以看到,较大的 $M$ 和 efSearch 可以显著提升召回率,但代价是更长的搜索时间。
与其他索引的对比
在向量搜索领域,HNSW并非唯一选择。了解它与主流替代方案的对比,有助于做出正确的技术决策。
Flat索引:完美的基准
Flat索引(暴力搜索)是所有ANN算法的上限:它保证100%的召回率。当数据量较小(比如小于10万向量)或召回率要求极高时,Flat索引可能是最佳选择。
在Sift1M数据集上,Flat索引的查询时间约为18毫秒,而HNSW($M=64$,efSearch=64)只需要约0.6毫秒——快了30倍。但当召回率要求不高时,这个差距会更大。
IVF(倒排文件索引)
IVF使用聚类将向量分组。查询时,只在与查询向量最近的几个聚类中搜索。
IVF的优势在于内存效率更高,构建速度也更快。但它的劣势在于需要预先训练(确定聚类中心),且当数据分布发生变化时需要重新索引。
在召回率方面,IVF通常能达到70-95%,与HNSW相当。但在高维空间中,IVF的聚类效果会下降,而HNSW的表现更加稳定。
LSH(局部敏感哈希)
LSH通过哈希函数将相似向量映射到相同的桶中。查询时,只需检查查询向量所在桶及相邻桶中的向量。
LSH的问题在于对高维数据效果不佳。为了保持较高召回率,需要大量哈希表,导致内存占用急剧增加。在128维的Sift1M数据集上,LSH需要8倍于原始向量的存储空间才能达到90%召回率。
性能对比表
| 索引类型 | 内存占用 | 查询时间 | 召回率 | 适用场景 |
|---|---|---|---|---|
| Flat | ~500MB | ~18ms | 100% | 小数据集、高精度要求 |
| LSH | 20-600MB | 1.7-30ms | 40-85% | 低维数据、小数据集 |
| HNSW | 600-1600MB | 0.6-2.1ms | 50-95% | 大数据集、高召回率要求 |
| IVF | ~520MB | 1-9ms | 70-95% | 中等数据集、内存受限场景 |
数据来源:Pinecone基于Sift1M数据集(100万128维向量)的基准测试。
生产环境中的挑战
HNSW虽然在学术基准测试中表现出色,但在生产环境中面临一系列挑战。
内存占用:最大的痛点
HNSW是内存密集型的索引。除了存储原始向量外,还需要存储图结构。对于每个节点,需要存储:
- 各层邻居的ID列表
- 层级信息
- 原始向量数据
以Sift1M为例,$M=64$ 时索引大小约为1.6GB。对于更大的数据集,内存需求会线性增长。这导致HNSW在内存受限的环境下难以部署。
解决方案:向量量化。 产品量化(Product Quantization, PQ)可以将向量压缩到原始大小的1/8甚至更小,代价是一定的精度损失。许多向量数据库支持HNSW+PQ的组合索引,在保持较高召回率的同时大幅降低内存占用。
召回率随数据规模衰减
2025年的一项研究表明,HNSW的召回率会随着数据库规模的增加而下降——这个现象比Flat索引更加明显。
在一项使用LAION数据集的实验中,当数据库从5万向量增长到20万向量时,HNSW($M=16$,efConstruction=100,efSearch=40)的Recall@5从87%下降到了77%,而Flat索引只从89%下降到了83%。
原因在于:在高维空间中,当向量密度增加时,图中的"捷径"变得更加拥挤,贪心搜索更容易陷入局部最优。
解决方案:动态调参。 随着数据规模增长,需要定期评估召回率并调整 efSearch。另外,混合检索(结合BM25等传统检索方法)可以在一定程度上缓解这个问题。
索引更新困难
HNSW的索引构建是增量式的,理论上支持动态插入。但删除操作比较棘手:删除一个节点会破坏图结构,导致搜索路径中断。
目前的解决方案主要有:
- 软删除: 标记节点为已删除,但不真正从图中移除。这会带来一定的内存浪费。
- 延迟重建: 定期重建整个索引,将删除的节点彻底清除。
- 标记删除+后台压缩: 后台线程定期压缩图结构,填补删除留下的空洞。
实践建议
基于以上分析,以下是使用HNSW的一些实践建议:
参数选择起点
对于通用RAG应用:
- $M$: 16-32
efConstruction: 100-200efSearch: 根据延迟要求调整,从40开始
对于高精度要求场景:
- $M$: 48-64
efConstruction: 200-400efSearch: 100-200
监控与调优
在部署后,应该监控以下指标:
- 查询延迟分布: P50、P99延迟是否在可接受范围
- 召回率: 可以通过定期采样评估(用Flat索引作为基准)
- 内存使用: 是否接近上限
当召回率下降时,优先调整 efSearch;当内存不足时,考虑降低 $M$ 或使用量化。
混合检索策略
纯向量检索在面对海量数据时会遇到瓶颈。结合元数据过滤、关键词检索(BM25)或知识图谱的混合策略,可以在保持高召回率的同时减少向量搜索的规模。
例如,先用BM25过滤出最相关的1000个文档,再在这些文档中进行HNSW向量搜索,可以显著提升效率和准确性。
结语
HNSW的成功并非偶然。它巧妙地将六度分隔的社会学洞察、可导航小世界图的算法设计、以及分层跳表的数据结构融合在一起,创造了一个既快速又灵活的向量检索引擎。
在AI时代,向量检索已成为支撑RAG、推荐系统、语义搜索等应用的核心基础设施。而HNSW作为这一领域的事实标准,其重要性不言而喻。
然而,HNSW并非完美。内存占用高、大规模下的召回率衰减、动态更新困难等问题,仍然是工程实践中需要面对的挑战。理解这些权衡,才能在合适的场景选择合适的工具。
正如Malkov在原始论文中写道:“没有免费的午餐。” 在向量检索的世界里,我们永远在速度、精度和资源消耗之间寻找那个最佳平衡点。
参考文献
-
Malkov, Y. A., & Yashunin, D. A. (2016). Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. arXiv preprint arXiv:1603.09320.
-
Malkov, Y., Ponomarenko, A., Logvinov, A., & Krylov, V. (2014). Approximate nearest neighbor algorithm based on navigable small world graphs. Information Systems, 45, 61-68.
-
Kleinberg, J. (2000). The small-world phenomenon: An algorithmic perspective. Proceedings of the 32nd ACM Symposium on Theory of Computing.
-
Milgram, S. (1967). The small-world problem. Psychology Today, 1(1), 61-67.
-
Arya, S., Mount, D. M., Netanyahu, N. S., Silverman, R., & Wu, A. Y. (1998). An optimal algorithm for approximate nearest neighbor searching fixed dimensions. Journal of the ACM, 45(6), 891-923.
-
Pugh, W. (1990). Skip lists: A probabilistic alternative to balanced trees. Communications of the ACM, 33(6), 668-676.
-
Bernhardsson, E. (2021). ANN Benchmarks. GitHub repository.