一个法律科技团队花了六个月搭建的RAG系统,在内部测试中表现完美——准确率超过90%。但上线第一周,用户投诉就涌了进来:系统检索到的条款总是"差那么一点"。问的是"合同解除后赔偿如何计算",返回的却是"合同解除的条件有哪些";问的是"违约金上限",拿到的却是"定金与违约金的区别"。
这些检索结果在语义上确实相关,但对于回答具体问题毫无帮助。
这不是个例。2025年,Google DeepMind的研究团队发表了一篇题为《On the Theoretical Limitations of Embedding-Based Retrieval》的论文,用严格的数学证明揭示了一个令人不安的事实:单向量嵌入在检索任务中存在根本性的能力上限,无论模型多大、训练数据多丰富,这个上限都无法突破。
语义相似不等于语义相关
理解RAG检索失败的关键,在于区分两个容易混淆的概念:语义相似性(semantic similarity)和语义相关性(semantic relevance)。
2019年,滑铁卢大学的研究团队在EMNLP会议上发表了一篇重要论文,系统性地分析了这个问题。他们发现,传统的语义匹配任务(如问答、复述检测)与信息检索中的相关性匹配虽然都涉及文本相似度,但存在本质差异:
- 语义匹配关注的是"两个文本是否表达相同含义",强调的是概念层面的对应关系
- 相关性匹配关注的是"这个文档能否帮助回答用户的查询",强调的是实用价值
论文中举了一个形象的例子:查询"2022 FIFA足球赛"与推文"2022 world cup FIFA could be held at the end of year in Qatar"被判定为相关,因为它们共享大量关键词;但两个句子"Does RBI send its employees for higher education?“和"Does EY send its employees for higher education?“虽然结构几乎完全相同,却被判定为不是复述——因为RBI和EY是两家不同的公司。
这个发现揭示了一个核心矛盾:向量嵌入擅长捕捉语义相似性,但检索任务真正需要的是语义相关性。当这两者不一致时,检索就会失败。
向量空间的数学天花板
DeepMind的论文将这个问题推向了更深的层面。研究团队从通信复杂性理论中的sign-rank概念出发,证明了一个关键结论:嵌入向量的维度决定了模型能够区分的文档组合数量的上限。
具体来说,对于维度为 $d$ 的嵌入空间,存在一个"临界点” $n$ —— 当文档数量超过这个临界点时,模型将无法正确处理所有可能的 top-k 检索组合。这个关系遵循一个三次多项式曲线,意味着增加维度虽然有帮助,但无法从根本上解决问题。
更令人震惊的是,研究团队设计了一个名为LIMIT的测试集,任务极其简单:文档是人物简介(“Jon Durben likes Quokkas and Apples”),查询是问题(“Who likes Quokkas?")。即便是Gemini Embeddings和GritLM这样的顶级模型,在这个简单任务上的Recall@100也不到20%。相比之下,几十年前的BM25算法却表现优异——因为BM25可以被理解为一种极高维度的稀疏向量模型。
论文作者Orion Weller在GitHub上开源了LIMIT数据集和实验代码,任何开发者都可以复现这些结果。这为"为什么更大的嵌入模型仍然会检索失败"提供了一个理论答案:问题不在于模型不够大,而在于单向量表示范式本身就存在根本性局限。
充分上下文:一个被忽视的关键概念
2025年5月,Google Research团队在ICLR会议上发表了另一项重要研究,提出了充分上下文(sufficient context)的概念。
研究团队发现,现有的RAG评估方法存在一个重大盲点:它们只关注检索内容与查询的"相关性”,但忽略了一个更关键的问题——这些内容是否足够回答用户的问题。
论文中举了一个例子:
查询:“Page Not Found"的错误代码是以哪个著名实验室的404房间命名的?那里曾存储着错误信息的中央数据库。
不充分的上下文:404错误或"Page Not Found"错误表示Web服务器无法找到请求的页面。这可能是由于URL中的拼写错误、页面被移动或删除、或网站的临时问题等原因造成的。
这段上下文与查询高度相关——它就是在讲404错误。但它完全没有回答问题。研究团队将这类情况定义为"不充分上下文”。
基于这个概念,他们开发了一个自动评分器(autorater),使用Gemini 1.5 Pro来判断上下文是否充分。在人工标注的115个样本上,这个评分器的准确率超过93%。
更重要的发现是:当上下文不充分时,大语言模型更容易产生幻觉。实验数据显示,开源模型Gemma在没有上下文时错误回答率为10.2%,而在使用不充分上下文时飙升至66.1%。添加上下文本应提高答案质量,但如果是"错误"的上下文,反而会降低系统表现。

图片来源: Google Research Blog
检索失败的四类典型模式
综合多项研究和工程实践,RAG检索失败可以归纳为四种典型模式:
语义漂移
这是最常见也最隐蔽的失败模式。用户问的是具体问题,系统检索到的是主题相关但无法回答问题的内容。比如问"违约金计算标准”,检索到的是"违约金的法律性质";问"退款流程",拿到的是"退换货政策概述"。
这类失败往往发生在查询包含多个语义焦点时。嵌入模型倾向于捕捉"主要"语义,而忽略用户真正关心的细节。
文档级失配
2025年10月的一项研究发现,当答案需要跨越多个文档片段综合得出时,检索失败率显著上升。研究团队将这种现象称为"文档级检索失配"(Document-Level Retrieval Mismatch)。
传统的chunk-level检索假设每个chunk是独立的,但很多问题的答案散布在不同位置。比如"比较A和B产品的三年总成本",答案需要同时检索两个产品的价格信息并进行计算——单chunk检索难以覆盖。
分块边界切断了关键信息
这是工程实践中最容易忽视的问题。文档被机械地按token数切分,导致关键信息被"切断"在不同chunk中。
一个典型案例:某企业知识库中,产品价格表被分成多个chunk。查询"XX产品价格"时,检索到的是价格表的前半部分,而实际价格信息在下一个chunk——两个chunk的语义相似度都很高,但只有后半部分包含答案。

图片来源: Snorkel AI
领域术语无法识别
通用嵌入模型对专业术语的敏感度有限。医疗、法律、金融等领域的特定术语,可能被映射到与常见词汇相似的嵌入空间位置,导致检索结果偏离目标。
一项针对法律文档检索的研究发现,通用模型对"连带责任"和"补充责任"的区分能力显著弱于领域微调模型——虽然这两个概念在法律上有本质区别,但在语义上高度相似。
混合检索:工程层面的妥协与突破
面对这些挑战,工程界的主流应对策略是混合检索(hybrid search)——将稀疏检索(如BM25)与密集向量检索相结合。
这种方法的底层逻辑是承认两类检索各有优劣:
- BM25擅长精确匹配,对专有名词、缩写、代码片段敏感,不会因为语义相似而"跑偏"
- 向量检索擅长语义扩展,能够处理同义词、改写、拼写错误
具体的融合策略包括:
加权融合:对两种检索结果分别打分后按权重合并。混合得分公式为:
$$\text{Score}_{\text{hybrid}} = \alpha \cdot \text{Score}_{\text{vector}} + (1-\alpha) \cdot \text{Score}_{\text{BM25}}$$其中 $\alpha$ 控制两种方法的相对权重。
倒数排名融合(Reciprocal Rank Fusion, RRF):不直接比较得分,而是利用排名信息:
$$\text{RRF}(d) = \sum_{r \in R} \frac{1}{k + \text{rank}(d, r)}$$其中 $R$ 是多个检索结果集,$k$ 是平滑参数(通常取60),$\text{rank}(d, r)$ 是文档 $d$ 在结果集 $r$ 中的排名。
这种方法对得分尺度不敏感,更容易调参。
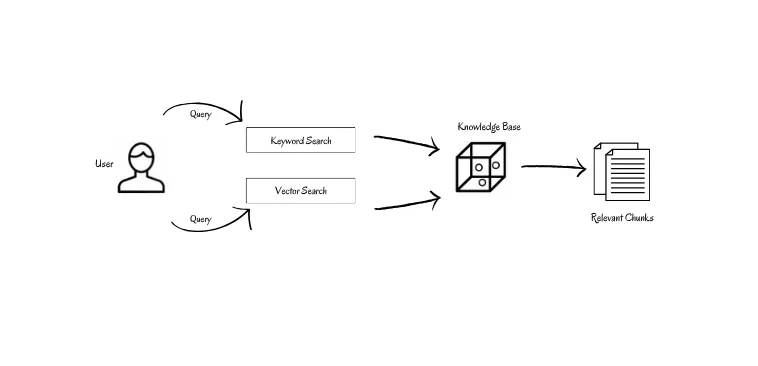
图片来源: VectorHub by Superlinked
重排序:第二道防线
混合检索解决的是"召回"问题,但检索结果的质量参差不齐。重排序(reranking)作为第二阶段处理,对候选文档进行精细筛选。
重排序模型(如cross-encoder)的核心优势在于:它能够同时"看到"查询和文档,进行深层的语义交互,而不是像双塔模型那样分别编码后再比较相似度。
这种能力的代价是计算成本——重排序无法用于全库检索,只能作为后处理步骤对有限候选集进行精细化排序。
实验数据显示,在混合检索基础上加入重排序,可以将答案准确率提升5-15个百分点,尤其在复杂查询上效果显著。
flowchart LR
Q[用户查询] --> V[向量检索]
Q --> B[BM25检索]
V --> F[分数融合]
B --> F
F --> C[候选文档集]
C --> R[重排序模型]
R --> L[LLM生成]
评估框架:量化检索质量
改进RAG系统需要科学的评估方法。RAGAS框架提供了四个核心指标:
- Context Precision:检索内容中有多少比例是真正相关的
- Context Recall:回答问题所需的信息有多少被成功检索
- Faithfulness:生成答案对检索内容的忠实程度
- Answer Relevance:生成答案与用户查询的相关程度
这些指标将RAG系统的表现拆解为多个维度,便于定位问题源头。比如,Context Recall低说明检索环节不足,需要优化召回策略;Faithfulness低则说明生成环节有问题,模型可能过度依赖自身知识而非检索内容。
技术权衡与现实选择
没有完美的检索系统。每一种优化策略都伴随着成本:
- 混合检索增加系统复杂度,需要维护两套索引和检索逻辑
- 重排序引入额外延迟,需要平衡准确率与响应时间
- 更大的嵌入维度提高存储和计算成本,边际收益递减
- 领域微调需要高质量标注数据,冷启动成本高
工程实践中的选择往往取决于具体场景:对于高价值、低频次的查询(如法律咨询),可以接受更高的延迟换取更好的准确率;对于高频次、低风险的查询(如FAQ检索),简单快速的方案可能更合适。
DeepMind论文的结论值得每位RAG开发者深思:单向量嵌入的局限是数学层面的事实,而非可以通过更大模型或更多数据解决的问题。这意味着,未来的检索系统很可能需要超越"查向量、取top-k"的简单范式,探索更复杂的多阶段、多信号融合架构——这不是倒退,而是对信息检索本质的回归。
参考文献
- Weller, O., et al. (2025). On the Theoretical Limitations of Embedding-Based Retrieval. arXiv:2508.21038
- Rao, J., et al. (2019). Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling. EMNLP 2019.
- Rashtchian, C., et al. (2025). Sufficient Context: A New Lens on Retrieval Augmented Generation Systems. ICLR 2025.
- es, et al. (2025). RAGAS: Automated Evaluation of Retrieval Augmented Generation. arXiv:2309.15217