2023年,一篇来自斯坦福大学的研究揭示了一个令人深思的现象:当大语言模型的上下文窗口被大量文档填充时,模型从中间位置检索信息的能力反而不如不提供任何上下文时——这就是著名的"Lost in the Middle"效应。这个发现直接击中了RAG系统的软肋:如果我们为了提高召回率而返回更多文档,却反而降低了LLM的推理质量,那这个权衡还有什么意义?
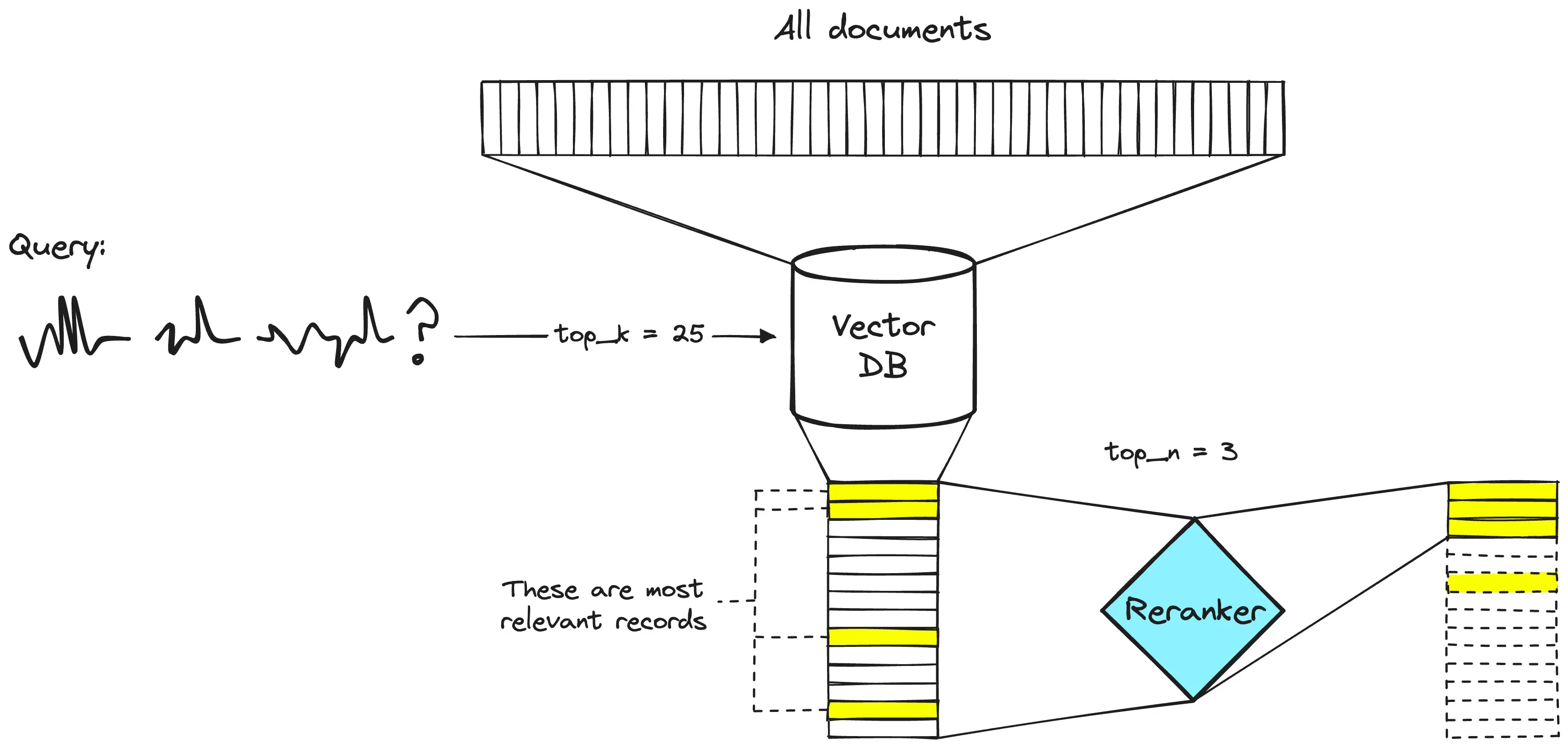
重排序技术的出现,正是为了解决这个根本矛盾。它允许我们在第一阶段大范围召回候选文档,然后在第二阶段精确筛选出最相关的少数文档。这种"先粗后精"的两阶段架构,已经在MS MARCO等基准测试中被证明能将检索准确率提升15-40%,而代价仅仅是几毫秒到几十毫秒的额外延迟。
召回与精确:信息检索的永恒困境
理解重排序的价值,必须先理解检索系统面临的核心挑战。
召回率的天花板
当用户提交一个查询时,检索系统的首要任务是从海量文档中找到所有可能相关的候选。这个指标叫做召回率(Recall):
$$\text{Recall} = \frac{|\text{检索到的相关文档}|}{|\text{所有相关文档}|}$$问题在于,语义相似的文档并不总是包含相同的关键词。用户搜索"如何让大模型更聪明",相关文档可能使用"推理时计算"、“思维链”、“涌现能力"等术语——传统的关键词匹配会完全漏掉这些结果。
向量检索(Dense Retrieval)通过将文本编码为高维向量来解决这个问题。句子级别的嵌入能够捕获语义相似性,即使没有词汇重叠。但这里隐藏着一个根本性的信息损失:一个768维或1536维的向量,必须压缩文档的全部语义信息。
精确率的代价
当向量检索找到候选文档后,下一个问题是排序质量。向量相似度计算的是两个压缩表示之间的距离,这种近似不可避免地引入误差。更糟糕的是,Bi-encoder在编码文档时根本不知道查询内容是什么——它必须在"查询未知"的情况下生成一个通用的表示。
这就导致了一个常见现象:前三个检索结果中,最相关的文档可能被排在第二或第三位,而某些语义模糊相关的文档却排在前面。对于需要精确答案的应用场景(如技术问答、法律检索),这种排序偏差会直接影响LLM生成答案的质量。
上下文窗口的悖论
一个直觉的解决方案是返回更多文档,让LLM自己判断。但研究表明这恰恰是错误的。
当上下文窗口中的文档数量增加时,LLM面临两个挑战:注意力分散和信息过载。即使模型理论上能够处理100K token的上下文,它在长文本中定位特定信息的能力却随文本长度下降。这意味着"扔给LLM更多文档"的策略不仅浪费token成本,还可能适得其反。
重排序提供了另一个思路:不是增加传给LLM的文档数量,而是提高这些文档的精确率。通过在检索阶段就完成精确筛选,我们既保证了召回率(第一阶段大范围召回),又保证了精确率(第二阶段精细重排)。
Bi-encoder与Cross-encoder:两种编码哲学
重排序的核心是Cross-encoder模型。理解它为什么比Bi-encoder更精确,需要深入两种架构的根本差异。
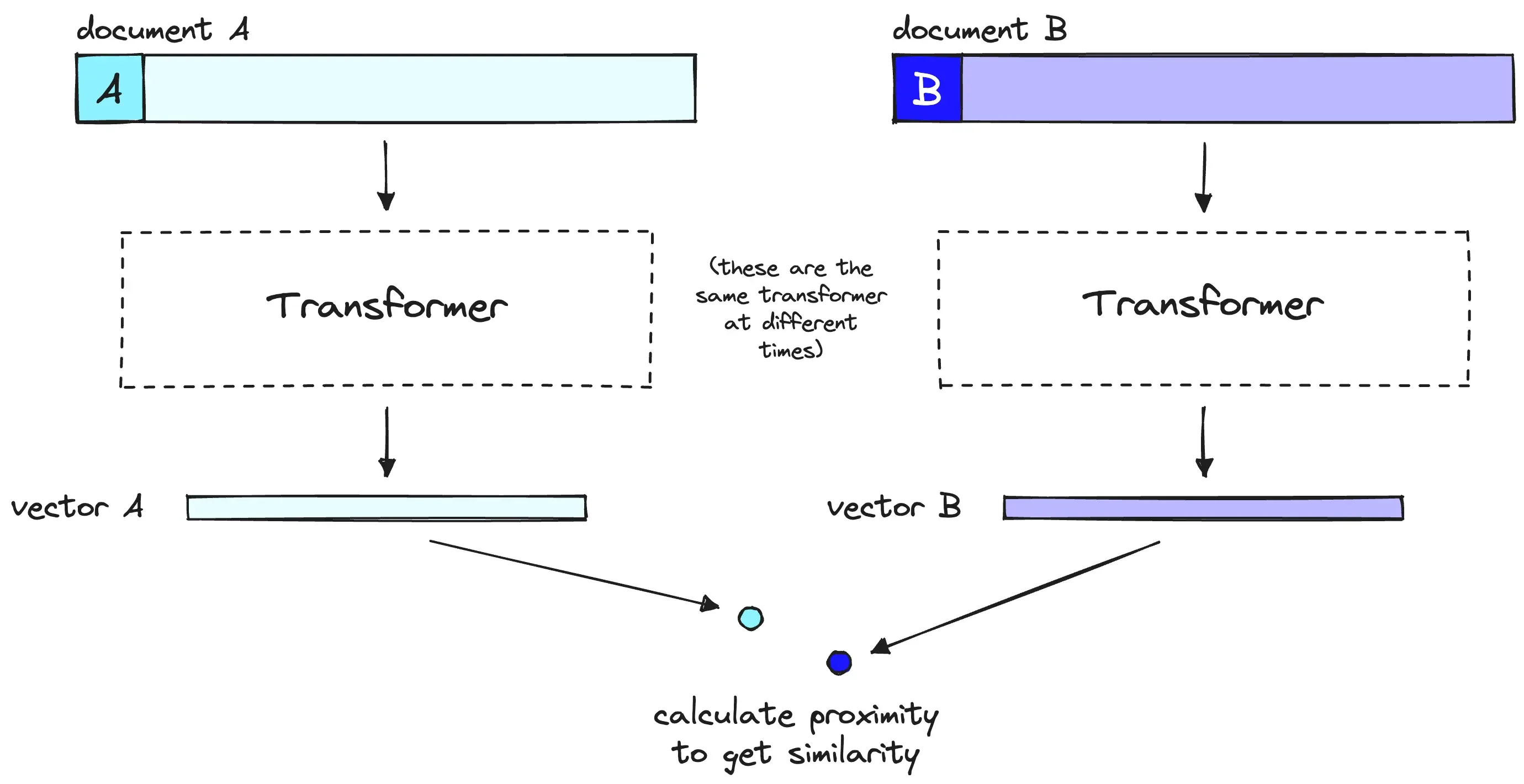
Bi-encoder:独立编码的效率代价
Bi-encoder(双编码器)是向量检索的基础架构。它的核心思想是将查询和文档分别编码为独立的向量:
$$\mathbf{q} = \text{Encoder}_Q(\text{query})$$$$\mathbf{d} = \text{Encoder}_D(\text{document})$$
$$\text{similarity} = \cos(\mathbf{q}, \mathbf{d})$$
这种架构的美妙之处在于效率:文档向量可以离线预计算并存储在向量数据库中,查询时只需计算一个查询向量,然后进行高效的向量相似度搜索。对于数百万甚至数亿文档的规模,这可以在毫秒级完成。
但效率的代价是信息损失。当文档被编码为单个向量时,所有语义信息被压缩到固定维度。更重要的是,编码器在处理文档时完全不知道查询内容——它必须生成一个"通用"的表示,能够应对任何可能的查询。
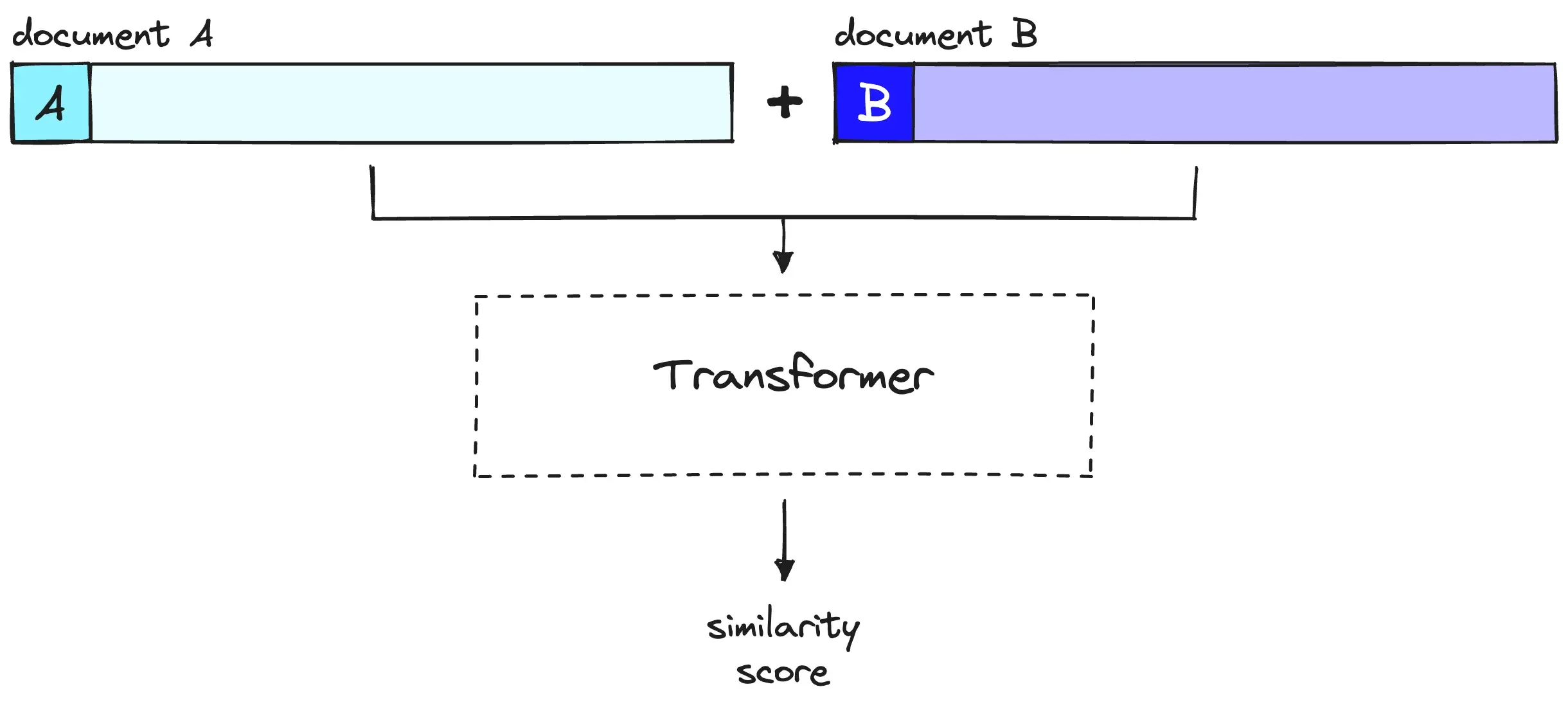
Cross-encoder:联合编码的精确优势
Cross-encoder(交叉编码器)采用完全不同的策略:将查询和文档拼接后一起输入Transformer:
$$\text{input} = [\text{CLS}] + \text{query} + [\text{SEP}] + \text{document} + [\text{SEP}]$$$$\text{score} = \text{Transformer}(\text{input})$$
关键区别在于注意力机制。在Bi-encoder中,查询的每个token只能与其他查询token交互,文档的每个token只能与其他文档token交互。而在Cross-encoder中,查询的每个token都可以直接与文档的每个token交互——这种"全注意力"机制让模型能够捕获查询与文档之间细粒度的语义对应关系。
为什么Cross-encoder更精确?
考虑一个具体例子:查询是"Python的GIL问题如何影响多线程性能”,文档讨论的是"全局解释器锁在CPython实现中的设计缺陷及其对并发程序的影响"。
Bi-encoder将两个文本分别编码后计算相似度。由于"GIL"和"全局解释器锁"是不同的词汇,它们的嵌入向量可能不够接近。即使模型知道它们语义相关,这种知识也被压缩在固定维度的向量中。
Cross-encoder则不同。在自注意力层中,“GIL"的token可以直接关注"全局解释器锁"的token,模型能够实时识别这种词汇对应关系。更重要的是,模型可以根据查询的具体意图动态调整对文档内容的关注——如果查询询问的是"性能影响”,模型会更加关注文档中讨论性能的部分。
这种动态的、查询感知的语义匹配,正是Cross-encoder的核心优势。
Cross-encoder的技术细节
架构设计
Cross-encoder通常基于预训练的Transformer模型(如BERT、MiniLM、DeBERTa)构建。输入格式遵循标准的句子对模板:
[CLS] Query [SEP] Document [SEP]
[CLS] token的隐藏状态被用作整个输入对的表示,然后通过一个线性层输出相关性分数:
这个分数通常是未归一化的实数值,分数越高表示相关性越强。
训练方法
Cross-encoder的训练数据通常是三元组形式:$(q, d^+, d^-)$,其中$d^+$是相关文档,$d^-$是不相关文档。常用的损失函数包括:
Binary Cross-Entropy Loss:将问题转化为二分类任务,训练模型区分相关/不相关:
$$\mathcal{L} = -\sum_{i} [y_i \log(\sigma(s_i)) + (1-y_i)\log(1-\sigma(s_i))]$$RankNet Loss:直接优化排序质量,让相关文档的得分高于不相关文档:
$$\mathcal{L} = \sum_{(i,j)} \log(1 + e^{-\sigma(s_i - s_j)})$$其中$(i, j)$是一对文档,模型学习让$s_i > s_j$当文档$i$比文档$j$更相关时。
主流模型对比
MS MARCO基准测试是评估重排序模型的黄金标准。下表展示了主流Cross-encoder模型的性能:
| 模型 | NDCG@10 (TREC DL 19) | MRR@10 (MS MARCO) | 推理速度 (docs/sec) |
|---|---|---|---|
| ms-marco-TinyBERT-L2-v2 | 69.84 | 32.56 | 9000 |
| ms-marco-MiniLM-L6-v2 | 74.30 | 39.01 | 1800 |
| ms-marco-MiniLM-L12-v2 | 74.31 | 39.02 | 960 |
| bge-reranker-base | 67.28 | - | ~500 |
| bge-reranker-large | 67.60 | - | ~300 |
可以看到,模型大小与推理速度存在明显权衡。MiniLM-L6-v2在保持较高准确率的同时,推理速度远超更大的模型。对于生产环境,需要根据延迟预算选择合适的模型。
ColBERT:在效率与精确之间寻找平衡
Cross-encoder虽然精确,但计算成本高昂。对于每个候选文档,都需要运行完整的Transformer前向传播。如果第一阶段检索返回100个文档,就需要100次Transformer推理。
ColBERT提出了一种创新的"Late Interaction"机制,试图在Cross-encoder的精确性和Bi-encoder的效率之间找到平衡。
Late Interaction的核心思想
ColBERT的关键洞察是:延迟交互并不意味着放弃交互。
在Bi-encoder中,查询和文档的交互发生在最后——计算两个向量的余弦相似度。但这种交互太"浅"了,只有单个向量之间的点积。
ColBERT保留了Token级别的表示。对于查询$Q = \{q_1, q_2, ..., q_N\}$和文档$D = \{d_1, d_2, ..., d_M\}$,它计算相似度为:
$$\text{Score}(Q, D) = \sum_{i=1}^{N} \max_{j \in [1,M]} \mathbf{q}_i \cdot \mathbf{d}_j$$这个公式的含义是:对于查询中的每个token,找到文档中与之最相似的token,然后将所有查询token的最大相似度相加。这就是著名的MaxSim操作。
为什么Late Interaction有效?
Late Interaction保留了Cross-encoder的部分优势,同时避免了其计算成本。
细粒度语义匹配:不同于单向量表示,ColBERT为每个token保留独立的嵌入。这意味着"Python"这个词可以专门匹配"编程语言",而不受文档其他部分的干扰。
可预计算性:文档的token嵌入可以离线计算和索引。查询时只需计算查询的token嵌入(非常快),然后与预存储的文档嵌入计算MaxSim。
可解释性:通过分析MaxSim的对齐结果,可以直观地看到查询的哪些token与文档的哪些token匹配。

ColBERT的存储挑战
Late Interaction的代价是存储空间。对于每个文档,需要存储所有token的嵌入向量。一篇500 token的文档,如果嵌入维度是128,就需要存储$500 \times 128 = 64,000$个浮点数——是单向量表示的500倍。
ColBERTv2通过残差压缩技术将存储需求降低了6-10倍,同时保持检索质量。其核心思想是:将token嵌入量化为最近邻聚类中心的残差表示,大幅减少存储位数。
LLM-based Reranking:用大模型做排序
随着大语言模型能力的提升,一个自然的问题是:能否直接用LLM来判断文档相关性?
RankGPT的突破
2023年,研究者提出了RankGPT,使用GPT-3.5/4作为重排序器。核心方法是Listwise Ranking:将查询和一组候选文档一起输入LLM,让模型直接输出排序后的文档ID。
Query: 什么是量子纠缠?
Document 0: 量子纠缠是量子力学中的一个重要现象...
Document 1: 量子计算的基本原理包括叠加态和纠缠...
Document 2: 经典物理中的纠缠概念与量子纠缠的区别...
请根据与查询的相关性对文档进行排序,输出排序后的文档ID列表。
LLM的优势在于其强大的语义理解能力和知识储备。对于需要领域知识的查询(如医学、法律),LLM能够利用其预训练知识进行更准确的判断。
LLM Reranking的代价
然而,LLM重排序的计算成本远高于专用重排序模型。一次GPT-4 API调用可能需要数百毫秒和数美分的成本,而一个小型Cross-encoder模型在本地GPU上只需几毫秒。
更实际的方案是将LLM重排序用于特殊场景:查询非常复杂、需要领域知识、或者候选文档数量很少(top-5重排序)。
开源LLM Reranker
近期的研究展示了如何用开源LLM(如Llama、Qwen)构建高效的重排序器。通过指令微调,这些模型能够在保持较低延迟的同时,接近甚至超越商业LLM的排序质量。
RankLLM库提供了统一的接口,支持pointwise、pairwise和listwise三种重排序模式:
- Pointwise:独立评估每个文档的相关性
- Pairwise:比较两个文档哪个更相关
- Listwise:一次性对整个文档列表排序
实践指南:如何选择重排序方案
延迟预算
重排序会增加检索延迟。需要明确你的延迟预算:
- < 10ms:无法使用重排序,只能依赖Bi-encoder
- 10-50ms:可使用小型Cross-encoder(如MiniLM-L4),重排序top-20文档
- 50-200ms:可使用中型Cross-encoder或ColBERT,重排序top-50文档
- > 200ms:可考虑LLM重排序,适用于对质量要求极高的场景
候选文档数量
重排序的候选数量直接影响延迟和质量。经验法则:
- top-10重排序:延迟最低,但可能漏掉第一阶段排名靠后的相关文档
- top-50重排序:平衡召回和效率的常用选择
- top-100重排序:召回率最高,但延迟和成本也最高
领域适配
通用重排序模型在特定领域可能表现不佳。如果应用场景有特殊术语或知识(如医疗、法律、金融),考虑:
- 收集领域内的查询-文档对作为训练数据
- 在领域数据上微调Cross-encoder
- 使用LLM重排序器利用其通用知识
实施示例
以下是使用Sentence Transformers库实现重排序的典型代码:
from sentence_transformers import CrossEncoder
# 加载重排序模型
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L6-v2')
# 第一阶段检索结果(假设来自向量检索)
query = "什么是检索增强生成"
candidates = [
{"id": 1, "text": "RAG是一种将检索与生成结合的技术..."},
{"id": 2, "text": "知识图谱的构建方法包括自顶向下..."},
{"id": 3, "text": "向量数据库的使用场景和优化策略..."},
]
# 构建查询-文档对
pairs = [(query, doc["text"]) for doc in candidates]
# 计算相关性分数
scores = reranker.predict(pairs)
# 根据分数重排序
ranked_results = sorted(
zip(candidates, scores),
key=lambda x: x[1],
reverse=True
)
性能评估指标
评估重排序质量需要理解几个关键指标:
NDCG@K
Normalized Discounted Cumulative Gain考虑了文档的相关性级别和排序位置。对于多级相关性标注(如完全相关、部分相关、不相关),NDCG惩罚将高度相关文档排在后面的情况:
$$\text{DCG@K} = \sum_{i=1}^{K} \frac{2^{rel_i} - 1}{\log_2(i+1)}$$$$\text{NDCG@K} = \frac{\text{DCG@K}}{\text{IDCG@K}}$$
MRR@K
Mean Reciprocal Rank关注第一个相关文档的位置,适用于只需要一个答案的场景:
$$\text{MRR} = \frac{1}{|Q|} \sum_{q \in Q} \frac{1}{\text{rank}_q}$$其中$\text{rank}_q$是查询$q$的第一个相关文档的排名位置。
实际性能数据
在NVIDIA的测试中,重排序能将RAG系统的准确率从65%提升到85%以上,而增加的延迟仅为整个查询时间的10-15%。关键是在召回阶段返回足够的候选(top-50或top-100),然后在重排序阶段精确筛选出top-3到top-10的文档传给LLM。
重排序不是万能药
重排序能够提升排序质量,但它无法修复第一阶段的召回缺陷。如果相关文档根本没有被第一阶段检索到,重排序也无法挽救。
优化重排序效果的关键是:
- 确保第一阶段召回足够广:使用混合检索(向量+关键词)提高召回率
- 选择合适的重排序候选数量:平衡延迟和质量
- 根据领域特点调整模型:必要时进行微调
重排序是RAG系统中一个相对简单但效果显著的优化手段。理解其原理和权衡,能够帮助你在效率与精确之间做出明智的技术决策。
参考文献
- Nogueira, R., & Cho, K. (2019). Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085.
- Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR 2020.
- Khattab, O., et al. (2022). ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. NAACL 2022.
- Sun, W., et al. (2023). RankGPT: Is ChatGPT Good at Ranking? arXiv preprint arXiv:2304.09542.
- Liu, N., et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv preprint arXiv:2307.03172.
- Xiao, S., et al. (2023). C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv preprint arXiv:2309.07597.
- Craswell, N., et al. (2021). MS MARCO: Benchmarking Ranking Models in the Large-Data Regime. SIGIR 2021.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019.