1990年9月,麦吉尔大学的计算机科学研究生Alan Emtage开发了一个名为Archie的程序。这个程序的工作方式在今天看来极其原始——它下载所有匿名FTP站点的目录列表,然后创建一个可搜索的文件名数据库。Archie不索引文件内容,因为当时的数据量小到可以手动搜索。这是人类历史上第一个互联网搜索引擎。
三十五年后的今天,Google每天处理超过85亿次搜索请求,平均响应时间约为0.5秒。在这么短的时间内,系统需要从数百亿个网页中找到最相关的结果。这种性能跨越的背后,是一场持续三十年的技术突围——从倒排索引的数学基础到语义搜索的神经网络,从单机Lucene到云原生分布式架构,每一次突破都重新定义了"搜索"的边界。
倒排索引:搜索引擎的数学基石
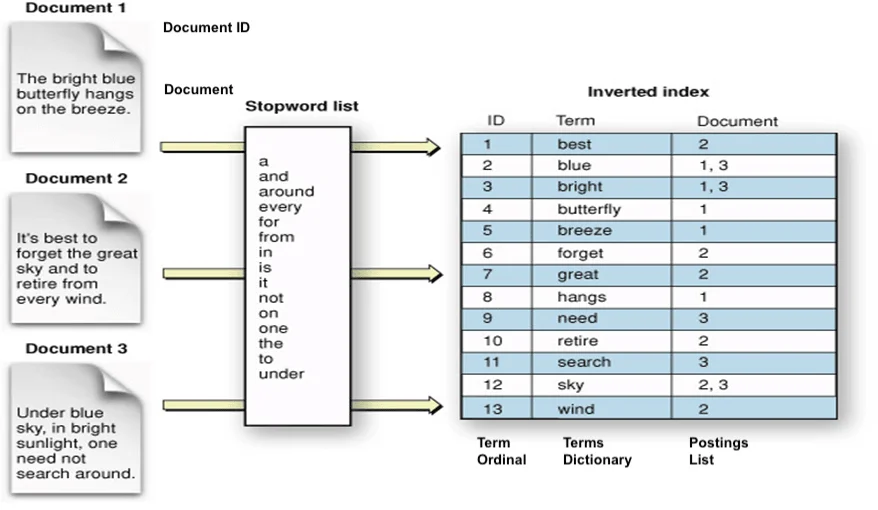
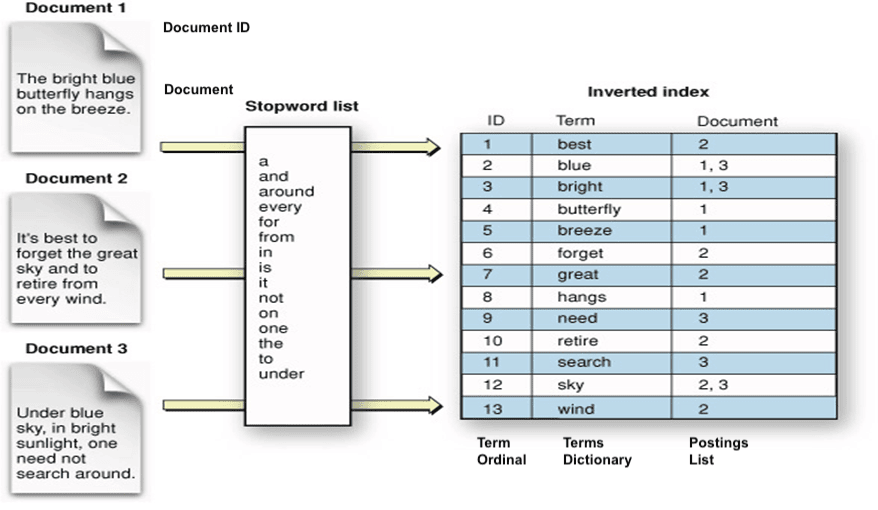
理解搜索引擎的第一步是理解一个反直觉的设计决策:存储文档时,我们习惯于"文档→词"的映射;但搜索时,我们需要的是"词→文档"的映射。这就是倒排索引(Inverted Index)的核心思想。
假设有三篇文档:
- 文档1:“搜索引擎技术发展迅速”
- 文档2:“数据库与搜索引擎密不可分”
- 文档3:“技术是第一生产力”
传统的"正排索引"存储方式是:
文档1 → [搜索引擎, 技术, 发展, 迅速]
文档2 → [数据库, 与, 搜索引擎, 密不可分]
文档3 → [技术, 是, 第一, 生产力]
当用户搜索"技术"时,系统必须遍历所有文档才能找到匹配项——时间复杂度与文档数量线性相关。
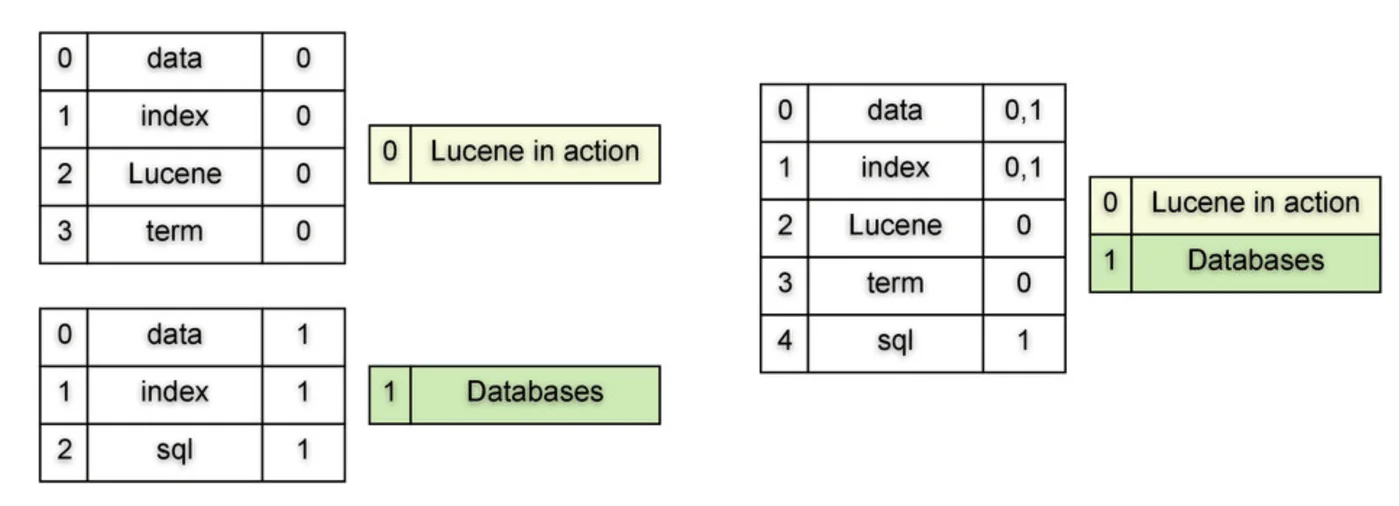
倒排索引则完全反转了这个结构:
搜索引擎 → [文档1, 文档2]
技术 → [文档1, 文档3]
发展 → [文档1]
迅速 → [文档1]
数据库 → [文档2]
与 → [文档2]
密不可分 → [文档2]
是 → [文档3]
第一 → [文档3]
生产力 → [文档3]
图片来源: j.blaszyk.me
{kind=link}
这种结构使得查找"技术"的时间复杂度降至O(1)——直接定位词项,获取文档列表。但工程实现远比这个简单的例子复杂。
Lucene的三层优化
Apache Lucene作为现代搜索引擎的事实标准,在倒排索引上做了三层关键优化:
第一层:FST压缩词项字典
当索引包含数百万个不同词项时,词项字典本身就会占用大量内存。Lucene使用有限状态转换器(Finite State Transducer, FST)来压缩这个词典。FST的核心洞察是:相邻词项往往共享前缀。例如,“apple”、“apply”、“approach"可以共享"ap"这个前缀节点。
一个实际案例:在Yelp的nrtsearch项目中,使用FST压缩后,词项字典的内存占用降低了约70%。这直接意味着更多的索引数据可以放入内存,减少磁盘IO。
第二层:Delta编码压缩倒排表
倒排表中存储的是文档ID序列,如[1, 9, 420, 1024]。Lucene使用增量编码(Delta Encoding):存储相邻ID的差值而非原始值。上述序列变为[1, 8, 411, 604]。
这个转换的意义在于:差值通常是较小的数字,可以用更少的字节存储。例如,0-127之间的数字只需要1字节,而128-16383需要2字节。在实际数据集中,大多数增量都落在1字节范围内,这使得倒排表的存储空间平均压缩了50%以上。
第三层:跳表加速合并
当查询包含多个词项时,需要对多个倒排表求交集。Lucene在倒排表上构建跳表(Skip List),使得合并操作的时间复杂度从O(n)降至O(log n)。具体实现中,每128个文档ID设置一个跳表节点,存储指向后续节点的指针。
BM25:为什么词频不是越多越好
找到了包含查询词的文档,下一个问题是:如何排序?
最直观的想法是:词项在文档中出现次数越多,文档越相关。这导致了早期TF-IDF算法的出现:
TF-IDF = TF × IDF
= (词项在文档中的出现次数) × log(总文档数 / 包含该词项的文档数)
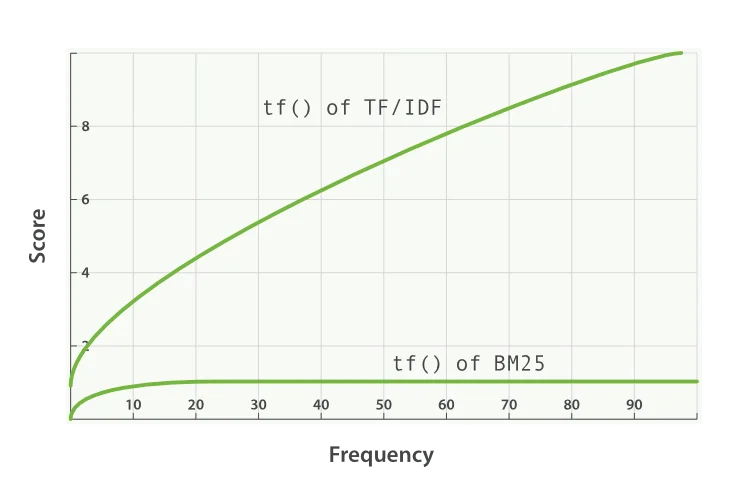
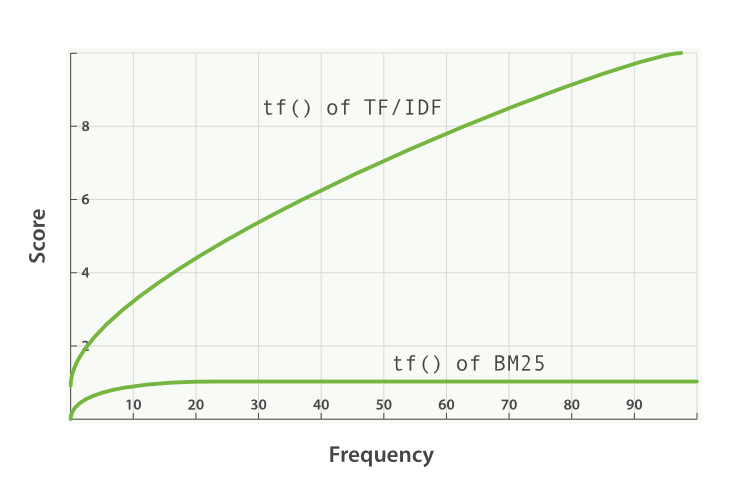
这个公式有一个致命缺陷:词频与相关性的关系不是线性的。当"技术"一词在文档中出现50次时,文档的相关性不应该比出现10次时高5倍——更可能是文档作者在堆砌关键词。
1994年,Stephen Robertson和Karen Spärck Jones在伦敦城市大学的研究中提出了BM25算法。其核心创新是引入词频饱和函数:
饱和分数 = (k1 + 1) × tf / (k1 × (1 - b + b × dl/avgdl) + tf)
其中tf是词频,dl是文档长度,avgdl是平均文档长度,k1和b是可调参数。
图片来源: images.contentstack.io
{kind=link}
这个函数的数学性质非常优雅:
- 当tf = 0时,分数 = 0
- 当tf → ∞时,分数 → k1 + 1(渐近上界)
- 当tf = k1时,分数 = (k1 + 1) / 2(恰好是最大值的一半)
Elasticsearch默认使用k1 = 1.2和b = 0.75。这意味着:对于平均长度的文档,当词项出现1.2次时,该词项对分数的贡献达到最大值的一半;超过这个阈值后,每次额外出现的边际贡献快速递减。
文档长度归一化的权衡
BM25的另一个关键组件是文档长度归一化。参数b控制归一化的强度:
- b = 0:完全忽略文档长度
- b = 1:完全归一化(长文档被显著惩罚)
这个设计源于一个深刻的洞察:长文档可能有两种情况——要么内容丰富覆盖更多主题(应该被奖励),要么作者啰嗦重复(应该被惩罚)。参数b让系统在这两种情况之间权衡。
实践中,新闻文章类数据通常使用较高的b值(0.75-0.9),因为新闻标题和摘要往往比正文更精炼;而学术论文类数据可能使用较低的b值(0.4-0.6),因为论文的详细论述本身是有价值的。
PageRank:链接即投票
1998年1月,Larry Page和Sergey Brin在斯坦福大学发表了题为《The PageRank Citation Ranking: Bringing Order to the Web》的论文。这篇论文提出了一个革命性的观点:不仅文档内容本身,文档之间的链接关系也是排序的重要信号。
PageRank的核心思想可以用一个"随机漫步者"模型来解释:假设一个用户在网络上随机点击链接浏览网页,他访问某个网页的概率,就是该网页的PageRank值。一个网页被越多高质量的网页链接,它就越重要。
数学公式如下:
PR(A) = (1-d) + d × Σ(PR(Ti)/C(Ti))
其中:
- PR(A)是网页A的PageRank值
- d是阻尼系数(通常设为0.85),代表用户继续点击链接的概率
- Ti是链接到A的所有网页
- C(Ti)是网页Ti的出链数量
这个公式看似简单,却解决了一个关键问题:如何避免"链接农场"作弊。在简单的链接计数模型中,一个网站可以通过创建大量互相链接的页面来提升排名。但PageRank的计算是迭代的——每个页面的排名依赖于指向它的页面的排名,形成一个递归依赖链。作弊页面虽然可能有大量链接,但这些链接来源的PageRank值很低,因此贡献有限。
值得注意的是,李彦宏在1996年就开发出了类似的RankDex算法,并获得了美国专利。Larry Page在一些专利中引用了李彦宏的工作。2000年,李彦宏使用RankDex技术创立了百度。
Lucene的段合并机制
理解现代搜索引擎,必须理解Lucene的段(Segment)机制。
当新文档被索引时,Lucene首先在内存中缓冲这些文档。当缓冲区达到一定大小(默认16MB)时,Lucene将缓冲区内容写入磁盘,形成一个不可变的段文件。这个段文件一旦写入,就不会被修改——所有更新都通过创建新段或标记删除来实现。
图片来源: j.blaszyk.me
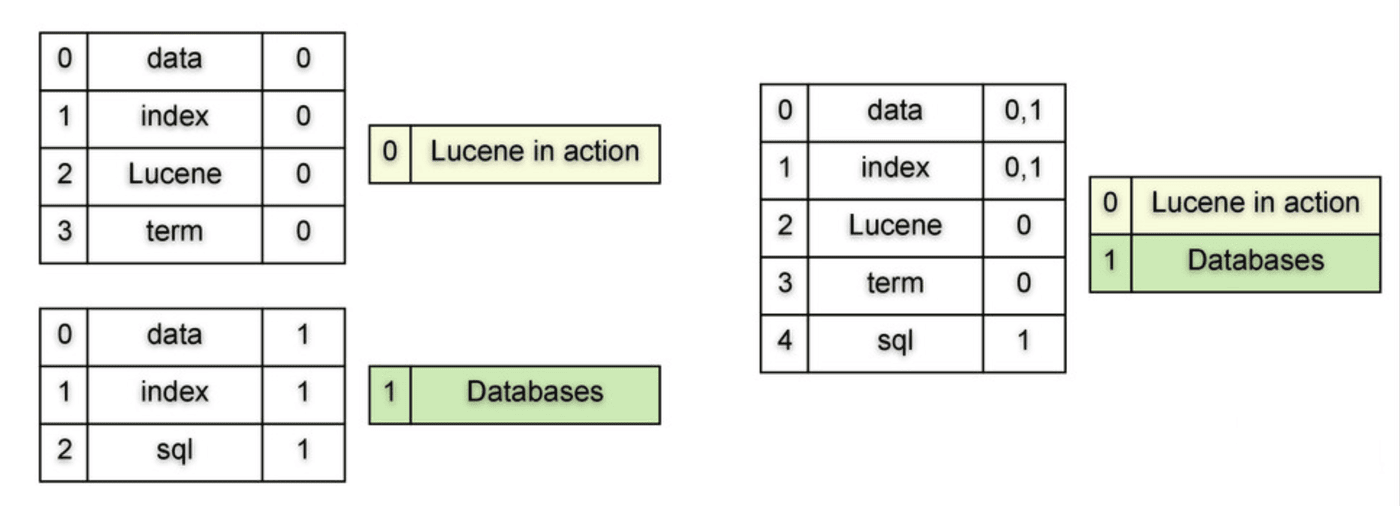{kind=link}
这种"只追加"的设计有几个关键优势:
并发安全:段文件一旦写入就不可修改,多个查询线程可以无锁并发读取,不需要担心读写冲突。
缓存友好:不可变数据结构天然适合操作系统页面缓存。热门段会自动被缓存,冷门段会被换出,无需应用层干预。
恢复简单:系统崩溃后,只需要扫描段文件列表,删除不完整的段,就可以恢复到一致状态。
但段合并也有代价。每次合并都需要读取所有待合并的段,写入新的大段。对于写入密集型应用,段合并可能成为瓶颈。Elasticsearch允许配置合并策略:TieredMergePolicy(默认)倾向于合并大小相近的段,适合大多数场景;LogByteSizeMergePolicy则按字节数合并,适合写入量稳定的场景。
分布式搜索:从单机到云原生
当数据量超过单机容量时,搜索引擎必须走向分布式。Elasticsearch的设计哲学是:每个分片(Shard)都是一个独立的Lucene索引。
一个拥有5个主分片、每个主分片1个副本的索引,在物理上由10个Lucene索引组成。当查询到达时,协调节点将查询广播到所有相关分片,合并结果后返回。
这个设计的关键权衡在于分片数量的选择:
分片过少:单个分片数据量大,查询延迟高;无法充分利用集群并行能力。
分片过多:每个分片都需要维护独立的词项字典和倒排表,内存开销大;协调节点合并结果的代价高。
Elastic官方建议:每个分片的数据量控制在10-50GB,每个节点的分片数量不超过20个/GB堆内存。例如,一个拥有30GB堆内存的节点,最多容纳600个分片。
近实时搜索的代价
Lucene的近实时(Near Real-Time, NRT)搜索能力来自一个关键设计:索引写入后,需要等待一个refresh周期(默认1秒),文档才能被搜索到。这1秒内,新文档仍然驻留在内存缓冲区中。
这个延迟是刻意为之的。如果每次写入都立即触发段的生成,会产生大量微型段,导致:
- 段合并压力激增
- 文件描述符耗尽
- 查询性能下降(需要遍历大量小段)
对于日志分析等对实时性要求不高的场景,可以将refresh间隔延长至30秒甚至更长,显著降低系统负载。对于电商搜索等要求秒级生效的场景,可以使用refresh API强制刷新。
语义搜索:理解"想要什么"而非"输入什么”
传统的词项匹配有一个根本局限:它无法理解语义。“苹果手机"和"iPhone"在词项层面毫无重叠,但在语义上几乎是等价的。
2013年,Google发布了Word2Vec论文,开启了词向量时代。核心思想是:将每个词映射到一个高维向量空间,语义相近的词在向量空间中距离较近。这个距离通常用余弦相似度衡量。
向量搜索的核心操作是:给定查询向量,在所有文档向量中找到最相似的K个。朴素算法需要计算查询向量与每个文档向量的距离,时间复杂度O(n),在大规模数据上不可行。
现代向量数据库使用近似最近邻(Approximate Nearest Neighbor, ANN)算法来加速:
HNSW(Hierarchical Navigable Small World):构建多层图结构,底层包含所有节点,上层节点是下层的子集。搜索时从顶层开始,逐层向下精确定位。查询复杂度O(log n),但需要较高的内存来存储图结构。
IVF(Inverted File Index):将向量空间划分为多个簇,每个簇有一个中心向量。查询时,只计算与查询向量最近的几个簇中的向量。查询复杂度取决于簇的数量,但需要预先确定簇数。
LSH(Locality Sensitive Hashing):使用哈希函数将相似向量映射到相同的桶中。查询时只需检查对应桶中的向量。查询复杂度O(1)的桶查找 + 桶内比较,但精度依赖于哈希函数的设计。
混合搜索:词汇与语义的融合
纯粹的向量搜索也有问题:它可能错过字面匹配但语义不太相关的结果。例如,搜索"Python爬虫”,向量搜索可能返回"网页抓取工具",但用户可能正在寻找的是包含"Python"和"爬虫"两个词的具体代码示例。
现代搜索引擎倾向于使用混合搜索(Hybrid Search):同时执行词项搜索和向量搜索,然后合并结果。
最常用的合并算法是倒数排名融合(Reciprocal Rank Fusion, RRF):
RRF_score(d) = Σ 1 / (k + rank_i(d))
其中rank_i(d)是文档d在第i个排序列表中的排名,k是一个常数(通常设为60)。
RRF的优雅之处在于:它不依赖分数的绝对值,只依赖排名。这使得词项搜索的BM25分数和向量搜索的余弦相似度分数可以直接融合,无需复杂的归一化。
Google在2024年引入的SearchGPT原型,以及主流搜索引擎的"AI概览"功能,本质上都是混合搜索的变体:用传统搜索确保精确匹配,用神经网络补充语义理解。
结语:搜索的本质是权衡
三十年的搜索引擎技术演进,本质上是一场持续的权衡:
- 精确 vs 召回:BM25的饱和函数权衡了词频精确性和召回率
- 实时 vs 效率:Lucene的段机制权衡了实时性和索引效率
- 语义 vs 字面:混合搜索权衡了语义理解和精确匹配
没有万能方案,只有特定场景下的最佳选择。理解这些权衡背后的逻辑,才能在面对具体问题时做出正确的架构决策。搜索技术仍在快速演进——大语言模型正在重塑查询理解和答案生成,多模态搜索正在突破文本边界。但无论技术如何变化,倒排索引和概率排序模型作为信息检索的基石,其价值不会褪色。