2004年,Linux内核开发者面临一个棘手的问题:传统的电梯调度算法在特定工作负载下会导致请求饥饿——某些I/O请求可能永远等不到服务。这个问题的根源在于,当磁盘忙于服务某一方向的请求时,反方向的请求可能被无限期忽略。Jens Axboe设计的Deadline调度器正是为了解决这个问题,它给每个请求设定一个"死线",保证请求不会无限期等待。
二十年后,技术世界发生了戏剧性的反转:最新的高性能NVMe SSD默认使用"无调度器"模式——I/O请求被直接传递给设备,不做任何排序或优化。从精心设计的电梯算法到"什么都不做",这看似是一种倒退,实则是技术演进的必然结果。
机械时代的物理约束
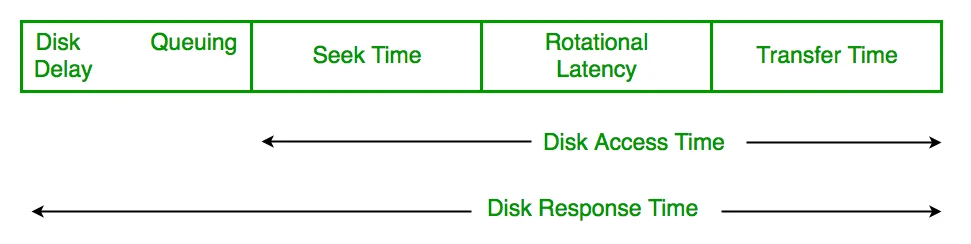
理解I/O调度器的设计动机,必须回到机械硬盘时代。传统的HDD(Hard Disk Drive)由旋转的盘片和移动的磁头组成。当需要读取数据时,磁头必须首先移动到正确的磁道(seek time,寻道时间),然后等待目标扇区旋转到磁头下方(rotational latency,旋转延迟)。这两个物理过程构成了磁盘访问时间的主体。
典型的企业级SAS硬盘转速为10,000或15,000 RPM,平均旋转延迟约为2-4毫秒。平均寻道时间约为3-5毫秒。这意味着一个随机I/O请求的总延迟约为5-9毫秒——听起来不长,但换算成IOPS(每秒I/O操作数),仅约100-200次。相比之下,现代NVMe SSD可以轻松达到百万级IOPS。
图片来源: media.geeksforgeeks.org
{kind=link}
正是这种巨大的物理延迟差异,驱动了早期I/O调度器的设计:任何能减少磁头移动和旋转等待的优化,都能带来显著的性能提升。
电梯算法的逻辑
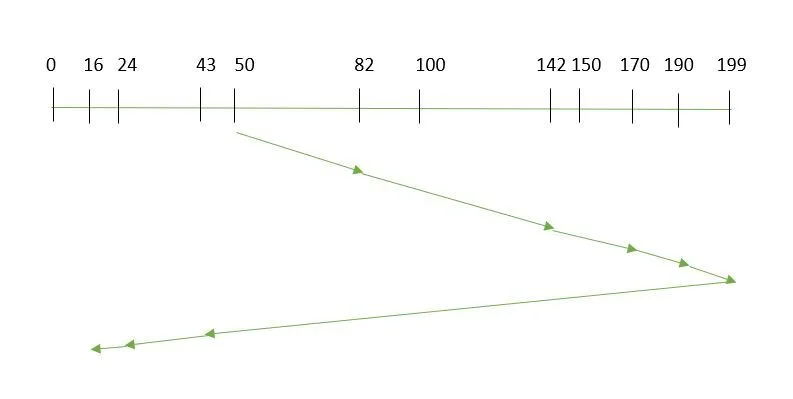
最直观的优化思路是让磁头像电梯一样工作:朝一个方向移动,沿途服务所有请求,到达尽头后反向。这就是SCAN算法,也被称为电梯算法(Elevator Algorithm)。
图片来源: media.geeksforgeeks.org
{kind=link}
假设磁头当前位置为50,待服务的请求序列为82、170、43、140、24、16、190。SCAN算法会先向大号方向移动,服务82、140、170、190,然后折返服务43、24、16。总移动距离为:(199-50) + (199-16) = 332个磁道。
电梯算法显著优于先来先服务(FCFS)——在同样的请求序列下,FCFS的总移动距离高达642个磁道,几乎是SCAN的两倍。
但电梯算法有一个致命缺陷:它不能保证请求的响应时间。如果系统持续有大量请求涌入,某些请求可能被无限期推迟。更糟糕的是,在Linux早期的实现中,读请求和写请求被混合处理,而写请求通常是异步的(进程不需要等待其完成),读请求是同步的(进程会阻塞等待)。这导致交互式应用的读请求被大量写请求"淹没",系统响应变得迟钝。
Deadline的设计权衡
Deadline调度器引入了一个简单但强大的概念:给每个请求设置截止时间。
具体实现中,Deadline维护两组队列:按扇区排序的队列(用于优化吞吐量)和按时间排序的FIFO队列(用于保证延迟)。读请求的默认截止时间为500毫秒,写请求为5秒。当请求在排序队列中被服务时,系统同时监控FIFO队列中是否有请求即将超时。一旦发现,立即优先处理即将超时的请求。
sequenceDiagram
participant App as 应用程序
participant SQ as 排序队列
participant FQ as FIFO队列
participant Disk as 磁盘设备
App->>SQ: 提交I/O请求(按扇区排序)
App->>FQ: 同时加入FIFO队列(设置截止时间)
loop 正常调度
SQ->>Disk: 按扇区顺序派发请求(优化吞吐)
end
Note over FQ: 监控请求是否即将超时
alt 有请求即将超时
FQ->>Disk: 立即派发超时请求
end
这种设计实现了两个目标:在正常情况下最大化吞吐量,在极端情况下保证请求不会被饿死。Deadline调度器还有一个关键参数writes_starved,默认值为2——意味着系统会优先处理读请求,只有在连续两次派发读请求后,才会派发一批写请求。这体现了另一个重要权衡:读请求的延迟直接影响用户体验,写请求可以稍等。
CFQ与公平性的追求
Deadline调度器解决了饥饿问题,但引入了新的问题:多个进程如何公平地分享磁盘带宽?一个进行大量顺序读写的进程可能完全占用磁盘,导致其他进程的请求被推迟。
CFQ(Completely Fair Queuing)调度器采用了一种完全不同的思路:为每个进程维护独立的I/O队列,按时间片轮流服务。
CFQ的核心设计借鉴了CPU调度中的公平调度思想。每个进程获得的磁盘时间与其权重成正比。当一个进程的时间片用完后,调度器切换到下一个进程。这种设计保证了每个进程都能获得"公平"的磁盘访问机会。
但CFQ有一个微妙的设计假设:进程会在发出一个I/O请求后短暂"休息",然后发出下一个请求。基于这个假设,当一个进程的队列为空时,CFQ会等待一小段时间(默认8毫秒),期待进程发出新的请求。这个机制称为"anticipatory waiting"(预期等待)或"idling"(空闲等待)。
对于机械硬盘,这个设计是合理的:如果磁头恰好位于某个进程需要的区域,继续为该进程服务可以避免磁头移动。但对于SSD,这个设计变得有害:SSD没有移动部件,随机访问和顺序访问同样快,等待只会增加延迟。
BFQ:从公平到响应性
BFQ(Budget Fair Queuing)调度器是CFQ的进化版本,由Paolo Valente在2012年提出。BFQ的核心创新是引入了"预算"(budget)的概念:每个队列被分配一个预算(以扇区数衡量),而不是时间片。当队列用完预算或队列为空时,调度器切换到下一个队列。
BFQ的代码量约为10,500行,而MQ-Deadline仅约1,000行——复杂度的差异反映了设计目标的不同。BFQ不仅要提供公平性,还要保证交互式应用的低延迟。
BFQ的"低延迟模式"(low_latency)默认开启。在这个模式下,BFQ会自动检测交互式和软实时应用(如音频视频播放器),并给予它们更高的权重。具体机制包括:
- 权重提升(weight-raising):检测到交互式应用后,临时提高其队列的权重
- 早期队列合并(Early Queue Merge, EQM):合并执行交错I/O的队列,提高吞吐量
- 自适应预算调整:为顺序I/O分配大预算以提高吞吐量,为随机I/O分配小预算以降低延迟
BFQ在桌面场景表现出色。根据官方文档,即使在后台有大量文件复制、编译、虚拟机I/O等任务运行时,启动应用程序或加载文件的延迟几乎与空闲系统相同。但代价是CPU开销——BFQ处理每个请求的开销约为1.9微秒,而MQ-Deadline仅为0.7微秒。
blk-mq:多核时代的架构革命
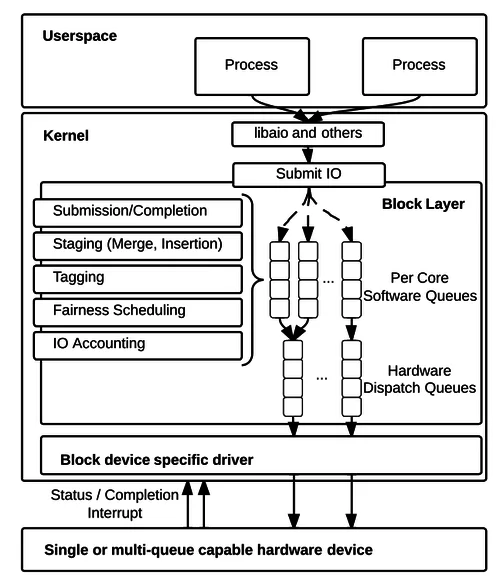
2013年,Linux 3.13内核引入了一个改变游戏规则的新架构:blk-mq(Multi-Queue Block IO Queueing Mechanism)。
传统块层使用单一请求队列,用一把锁保护。在多核系统上,这成为严重的瓶颈:多个CPU核心争抢同一把锁,导致大量时间浪费在锁等待上。当存储设备的能力从几百IOPS跃升到几百万IOPS时,软件层面的锁竞争成为新的瓶颈。
blk-mq的核心设计是两级队列架构:
图片来源: www.thomas-krenn.com
{kind=link}
-
软件暂存队列(Software Staging Queues):每个CPU核心或NUMA节点一个,用于合并请求和I/O调度。每个队列有独立的锁,消除了锁竞争。
-
硬件分发队列(Hardware Dispatch Queues):直接映射到设备的硬件队列。现代NVMe设备支持多达数十个硬件队列,blk-mq可以充分利用这种并行性。
当I/O请求到达块层时,它首先尝试最短路径:直接发送到硬件队列。只有在需要合并请求或进行I/O调度时,才会进入软件队列。这种设计在高性能NVMe设备上可以实现超过1500万IOPS。
Kyber:为低延迟而生
Kyber调度器是专门为高速多队列设备设计的,其核心思想简单而优雅:控制设备上并发请求的数量,防止请求堆积。
Kyber使用"令牌"(tokens)来控制并发。读请求和写请求分别有独立的令牌池,最大令牌数分别为256和128。当请求被派发到设备时消耗令牌,请求完成时归还令牌。如果没有可用令牌,新的请求必须等待。
令牌数量的调整基于两个可配置参数:
read_lat_nsec:读请求的目标延迟,默认2毫秒write_lat_nsec:写请求的目标延迟,默认10毫秒
Kyber持续监控实际的P90和P99延迟。如果读请求的P99延迟超过目标值,而写请求的P90延迟低于目标值,Kyber会减少写令牌数量,为读请求释放更多空间——这就是Kyber"优先读请求"的实现机制。
graph LR
subgraph 读请求
RT[读令牌池<br/>最大256] --> RD[派发到设备]
end
subgraph 写请求
WT[写令牌池<br/>最大128] --> WD[派发到设备]
end
subgraph 令牌调整逻辑
Monitor[监控P90/P99延迟]
Monitor -->|读延迟超标| ReduceW[减少写令牌]
Monitor -->|写延迟超标| ReduceR[减少读令牌]
end
2024年的一项系统性研究提供了详尽的性能数据:在NVMe SSD上,Kyber可以将P99读延迟降低35.9%(相比None调度器),同时CPU开销仅为BFQ的1/10。
None:高性能设备的最佳选择?
当存储设备足够快时,任何调度开销都是浪费。这就是"None"调度器(也称为"noop"或"无调度")的设计哲学:直接将请求传递给设备驱动,不做任何排序或合并。
但"无调度"并不意味着"无代价"。2024年的研究揭示了一个关键发现:对于现代NVMe SSD,CPU已经取代存储设备成为主要瓶颈。
测试数据显示:
- 在Samsung 980 PRO上,Linux块层使用None调度器可以达到约370 KIOPS/核心
- 而绕过内核的SPDK(Storage Performance Development Kit)可以达到约1.3 MIOPS/核心——效率提升3.6倍
这意味着Linux块层本身消耗了大量CPU周期,而这些周期在高速设备上本可以用于应用计算。
更重要的是,None调度器无法处理读写干扰问题。在SSD内部,读操作和写操作会竞争闪存芯片的访问带宽。如果系统中有大量写请求,读请求的延迟会急剧增加。测试数据显示,在32个并发写工作负载下,使用None调度器时读请求的P99延迟飙升到404.8毫秒,而使用BFQ仅为2.9毫秒——差距高达139倍。
如何选择:场景驱动的决策框架
没有"最佳"的I/O调度器,只有"最适合特定场景"的调度器。以下是不同场景的推荐选择:
NVMe SSD场景
| 场景 | 推荐调度器 | 理由 |
|---|---|---|
| 纯顺序/单一工作负载 | None | 最小化CPU开销,设备内部已足够智能 |
| 混合读写负载 | Kyber | 有效控制读写干扰,保证读延迟 |
| 桌面/交互式应用 | BFQ(低延迟模式) | 最佳响应性,交互式应用优先 |
| 数据库服务器 | MQ-Deadline | 稳定的延迟保证,较低的CPU开销 |
SATA/SAS SSD场景
BFQ通常是最佳选择,其低延迟模式可以显著提升交互体验,而顺序I/O性能与其他调度器相当。
机械硬盘场景
BFQ或MQ-Deadline。机械硬盘的物理特性使得调度器的优化空间最大——BFQ在顺序工作负载上可以比Deadline高出150%的吞吐量。
虚拟化环境
对于虚拟机镜像文件所在的存储,None通常是最佳选择——物理主机上的调度器无法感知虚拟机内部的访问模式,不如让虚拟机自己处理调度。
调优参数速查
MQ-Deadline关键参数
/sys/block/sdX/queue/iosched/
├── read_expire # 读请求截止时间(ms),默认500
├── write_expire # 写请求截止时间(ms),默认5000
├── writes_starved # 读优先次数,默认2
└── fifo_batch # 每批请求数,默认16
降低read_expire可以改善读延迟,但会增加寻道开销。增大fifo_batch可以提高吞吐量,但会增加延迟波动。
BFQ关键参数
/sys/block/sdX/queue/iosched/
├── low_latency # 低延迟模式,默认1(开启)
├── slice_idle # 空闲等待时间(ms),默认0(自适应)
└── strict_guarantees # 严格公平保证,默认0
禁用low_latency可以最大化吞吐量,适合批处理场景。设置slice_idle=0可以禁用空闲等待,适合SSD。
Kyber关键参数
/sys/block/nvmeXnY/queue/iosched/
├── read_lat_nsec # 读目标延迟(ns),默认2000000(2ms)
└── write_lat_nsec # 写目标延迟(ns),默认10000000(10ms)
降低read_lat_nsec可以优先读延迟,但会牺牲写吞吐量。设置read_lat_nsec=0会将读令牌池最大化,给予读请求最高优先级。
技术演进的本质
从电梯算法到"无调度",I/O调度器三十年的演进揭示了一个深刻的技术规律:优化的对象在变化,但权衡的本质不变。
机械硬盘时代,优化的对象是磁头移动;多核时代,优化的对象是锁竞争;NVMe时代,优化的对象是CPU开销。每一次技术进步都带来新的瓶颈,而调度器必须重新设计来应对。
今天,最激进的思路是绕过内核——SPDK、io_uring等技术代表了这一方向。但这并不意味着调度器变得不重要。恰恰相反,在云计算的多租户环境下,如何在共享存储资源上提供可预测的性能保证,仍然是一个未解决的难题。
或许未来的I/O调度器会利用机器学习来预测访问模式,或者与存储设备的内部调度器深度协同。但无论如何,理解过去的权衡决策,才能做出面向未来的设计选择。
参考资料
- Ren, Z., Doekemeijer, K., Tehrany, N., & Trivedi, A. (2024). BFQ, Multiqueue-Deadline, or Kyber? Performance Characterization of Linux Storage Schedulers in the NVMe Era. ICPE ‘24.
- Valente, P., & Andreolini, M. (2012). Improving Application Responsiveness with the BFQ Disk I/O Scheduler. SYSTOR ‘12.
- Bjørling, M., Axboe, J., Nellans, D., & Bonnet, P. (2013). Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems. SYSTOR ‘13.
- Linux Kernel Documentation. BFQ (Budget Fair Queueing). https://docs.kernel.org/block/bfq-iosched.html
- Linux Kernel Documentation. Deadline IO scheduler tunables. https://www.kernel.org/doc/html/v5.5/block/deadline-iosched.html
- Linux Kernel Documentation. Multi-Queue Block IO Queueing Mechanism (blk-mq). https://docs.kernel.org/block/blk-mq.html
- Axboe, J. (2002). Deadline I/O Scheduler. Linux Kernel Documentation.
- LWN.net. The multiqueue block layer. https://lwn.net/Articles/552904/
- Phoronix. Linux 5.6 I/O Scheduler Benchmarks: None, Kyber, BFQ, MQ-Deadline. https://www.phoronix.com/review/linux-56-nvme
- Red Hat. Setting the Disk Scheduler. RHEL Documentation.