一个承载每秒百万级请求的消息队列系统,工程师在技术选型时毫不犹豫地选择了共享内存——因为大家都知道共享内存是最快的IPC机制。三个月后,生产环境出现诡异的数据竞争问题,调试了两周才发现是同步原语使用不当。最终不得不重构,改用消息队列,性能下降了30%,但系统终于稳定了。
这不是虚构的故事。共享内存确实是最快的进程间通信方式,但它的"快"是有代价的。而那些"慢"的IPC机制,往往在生产环境中反而更可靠。理解这些机制的本质差异,比记住"哪个更快"这个结论重要得多。
基准测试告诉我们的真相
2016年,Periyar Maniammai大学的研究团队发表了一篇关于Linux IPC性能的论文。他们测试了管道、消息队列、流套接字和数据报套接字在不同数据规模下的传输时间。结果显示,对于99MB的数据,管道需要161秒,消息队列需要220秒,流套接字需要6秒,数据报套接字只需要2秒。
这个结果看起来与"常识"相悖——为什么数据报套接字反而最快?答案是测试方法。论文中的测试场景是简单的数据传输,没有考虑实际应用中的可靠性、流控和连接管理等复杂因素。真实的基准测试需要更精细的控制变量。
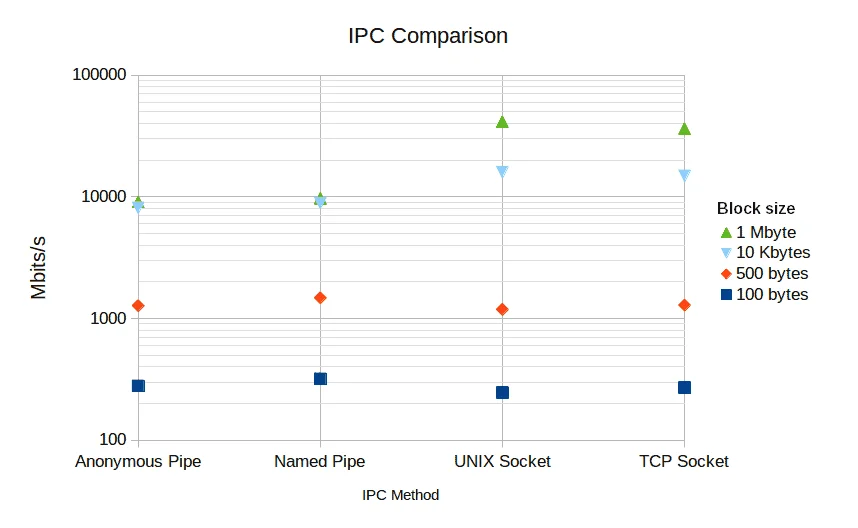
2023年,Baeldung发布了一份更系统的IPC性能测试报告。他们使用socat工具,测试了匿名管道、命名管道、Unix域套接字和TCP套接字在不同块大小下的吞吐量。测试传输2GB数据,块大小从100字节到1MB不等。
测试结果揭示了一个关键规律:IPC性能严重依赖块大小。
图片来源: www.baeldung.com
{kind=link}
| IPC类型 | 100字节块吞吐量 | 500字节块吞吐量 | 10KB块吞吐量 | 1MB块吞吐量 |
|---|---|---|---|---|
| 匿名管道 | 278 Mbit/s | 1,270 Mbit/s | 8,071 Mbit/s | 9,039 Mbit/s |
| 命名管道 | 318 Mbit/s | 1,475 Mbit/s | 8,844 Mbit/s | 9,699 Mbit/s |
| Unix套接字 | 246 Mbit/s | 1,185 Mbit/s | 15,886 Mbit/s | 41,335 Mbit/s |
| TCP套接字 | 270 Mbit/s | 1,284 Mbit/s | 14,799 Mbit/s | 36,208 Mbit/s |
当块大小为100字节时,命名管道最快(318 Mbit/s),Unix套接字最慢(246 Mbit/s)。但当块大小增加到1MB时,Unix套接字的吞吐量达到41 Gbit/s,是匿名管道的4.5倍。这种反转不是测试误差,而是IPC机制内在特性的体现。
更令人震惊的是共享内存的表现。GitHub上有一个开源的IPC基准测试项目,使用C++实现了多种IPC机制的对比测试。测试采用客户端-服务器架构,进行乒乓式消息传递。
| IPC类型 | 64字节消息 | 128字节消息 | 1024字节消息 |
|---|---|---|---|
| Unix域套接字 | 157,151 msg/s | 153,562 msg/s | 94,059 msg/s |
| 消息队列 | 207,172 msg/s | 173,801 msg/s | 49,418 msg/s |
| 命名管道 | 212,938 msg/s | 208,485 msg/s | 200,204 msg/s |
| 匿名管道 | 304,432 msg/s | 287,397 msg/s | 259,470 msg/s |
| 共享内存 | 5,359,056 msg/s | 4,672,897 msg/s | 2,452,182 msg/s |
共享内存的吞吐量是匿名管道的17倍,是Unix域套接字的34倍。对于64字节的小消息,共享内存每秒能处理超过500万条,而其他IPC机制大多在20万条以下。
差距为何如此悬殊?
共享内存:接近物理极限的速度
共享内存之所以快,是因为它从根本上绕过了操作系统的数据拷贝。当一个进程通过管道发送数据时,数据会经历这样的旅程:
用户缓冲区 --write()--> 内核缓冲区 --read()--> 接收方用户缓冲区
每一次系统调用都意味着用户态到内核态的切换,每一次数据传递都涉及至少一次内存拷贝。而共享内存的工作方式完全不同:
进程A的虚拟地址空间 --> 同一块物理内存 <-- 进程B的虚拟地址空间
两个进程通过mmap()将同一个物理内存区域映射到各自的虚拟地址空间。写入进程直接写内存,读取进程直接读内存。没有系统调用,没有上下文切换,没有数据拷贝。
Linux内核通过struct page数据结构管理物理内存页。当两个进程共享内存时,它们的页表项指向同一个物理页帧。这个物理页帧的引用计数会增加,表示有多个进程在使用它。内核只负责维护这个引用关系,完全不介入数据的读写过程。
这种设计的代价是同步。共享内存本身不提供任何同步机制。当进程A在写入数据时,进程B可能同时在读取,读到一半新数据一半旧数据。必须借助额外的同步原语——信号量、互斥锁、或者原子操作——来保证一致性。
这就是开头那个故事的根源。工程师以为共享内存的"快"是免费的午餐,却忽视了同步成本。在高竞争场景下,锁的开销可能完全抵消零拷贝的优势。一个被频繁争抢的互斥锁,单次操作可能消耗上万个CPU周期,而一个无竞争的原子操作只需要几十个周期。
共享内存的隐藏陷阱
Linux提供了两种共享内存接口:System V共享内存(shmget、shmat)和POSIX共享内存(shm_open、mmap)。两者在性能上几乎没有差异,但在接口设计上有本质区别。
System V共享内存使用整数键值标识,通过ftok()将文件路径转换为键。这意味着即使进程没有继承关系,只要知道这个键值就能访问共享内存。这带来了灵活性,但也带来了风险——任何知道键值的进程都能访问,权限控制完全依赖文件系统权限。
POSIX共享内存使用路径名标识,位于/dev/shm目录下。这个目录实际上是tmpfs文件系统的挂载点,数据存储在内存中,但操作接口类似文件。你可以用ls /dev/shm查看系统中所有POSIX共享内存对象,也可以用rm /dev/shm/myshm删除一个共享内存对象。
共享内存还有一个容易被忽视的问题:清理。如果一个进程在持有共享内存对象时崩溃,这些对象会一直留在系统中。System V共享内存需要用ipcrm命令手动清理,POSIX共享内存需要rm /dev/shm/*。在生产环境中,这通常是运维脚本的一部分,但开发阶段很容易忘记。
管道:看起来简单,实则不然
管道可能是最古老的IPC机制,Unix的设计哲学就体现在管道上:连接简单工具,组合复杂功能。但管道的性能特征,远比直觉复杂。
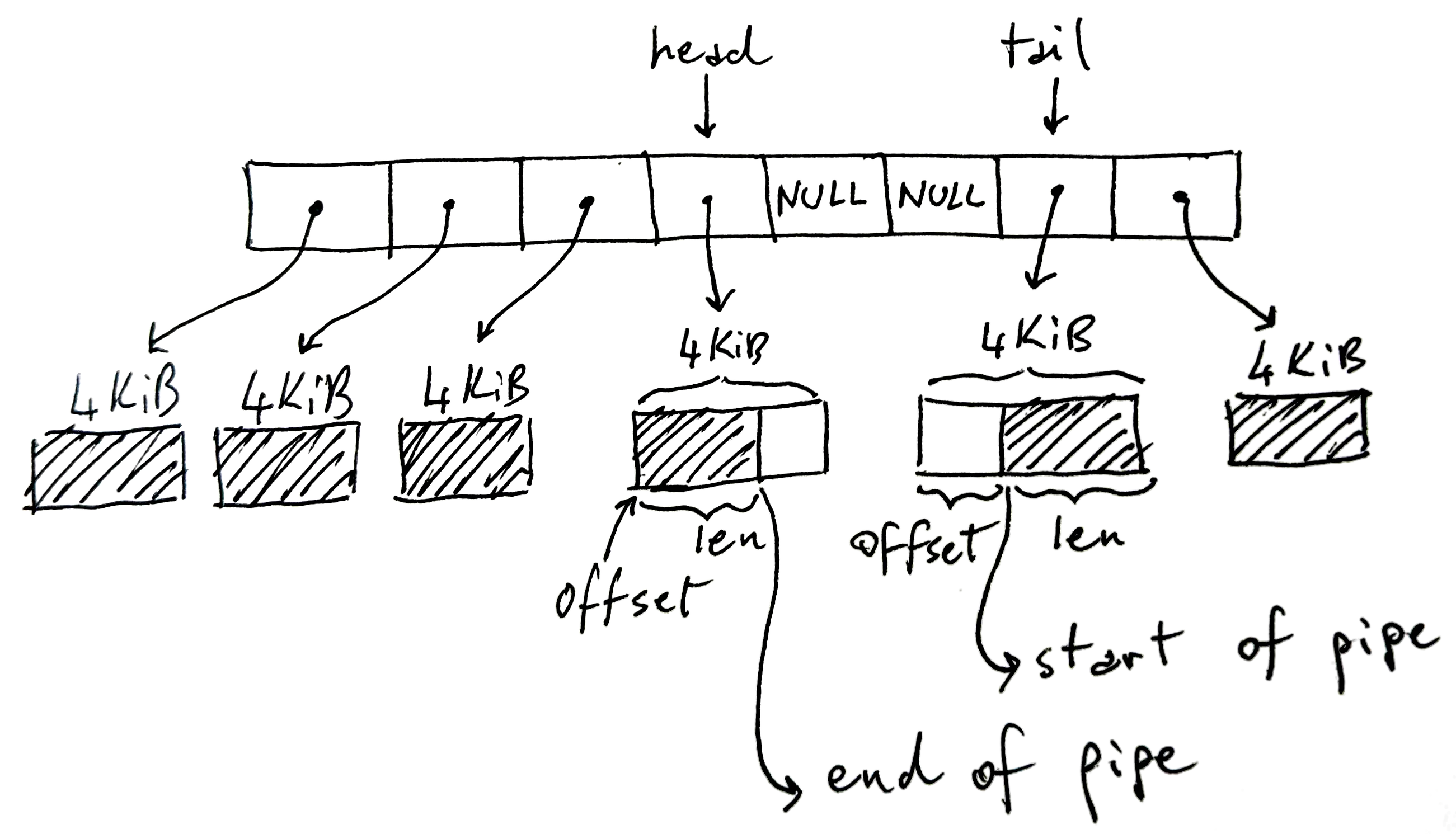
Linux管道本质上是一个环形缓冲区。从Linux 2.6.11开始,管道的默认容量是16个内存页,在x86-64系统上是64KB。每个内存页是4KB,这些页的引用被存储在一个数组中。
图片来源: mazzo.li
{kind=link}
当进程向管道写入数据时,内核会分配一个新页(如果缓冲区未满),将数据从用户空间拷贝到这个页中。读取进程从另一端读取数据时,内核将数据从页中拷贝到用户空间,然后释放这个页(如果数据已被完全读取)。
看起来很直接,但这个过程涉及大量的内核操作。每一次write()和read()都是系统调用,需要用户态-内核态切换。每一次切换需要保存和恢复寄存器状态,切换页表,可能触发TLB刷新。2018年的一项测试显示,在现代Linux系统上,单次上下文切换需要1.2到1.5微秒。
管道缓冲区的演进
Linux管道的缓冲区大小经历了多次调整。Linux 2.6.11之前,管道容量只有一页(4KB)。2.6.11将其增加到16页(64KB)。从2.6.35开始,可以通过fcntl(fd, F_SETPIPE_SZ, size)动态调整管道大小,上限由/proc/sys/fs/pipe-max-size控制,默认是1MB。
为什么默认只有64KB?这是一个权衡。更大的缓冲区意味着更高的内存占用,每个管道都会占用这么多内存。而大多数管道的使用场景——如grep pattern file | wc -l——不需要大缓冲区。数据在管道中停留的时间很短,读取进程会立即消费。
但在高性能场景下,64KB的缓冲区可能成为瓶颈。如果生产者的生产速度超过消费者的消费速度,管道会频繁满,生产者会阻塞。增大管道缓冲区可以缓解这个问题,但不能根治——关键在于平衡生产者和消费者的速度。
零拷贝优化:splice和vmsplice
Linux提供了一种特殊的系统调用,可以在管道和其他文件描述符之间移动数据,而无需将数据拷贝到用户空间。
splice(fd_in, off_in, fd_out, off_out, len, flags)在两个文件描述符之间移动数据。如果其中一个文件描述符是管道,数据可以从另一个文件描述符直接"嫁接"到管道中,而不需要拷贝。
vmsplice(fd, iov, nr_segs, flags)将用户空间的内存直接移入管道。这里"移入"不是拷贝,而是让管道直接引用用户空间的内存页。这听起来很危险——如果用户进程在管道消费数据前修改了这块内存怎么办?
答案是小心地管理生命周期。vmsplice通常配合双缓冲策略使用:进程将缓冲区A的数据vmsplice到管道后,立即开始填充缓冲区B。当管道消费完缓冲区A的数据后(通过splice移动到其他地方),进程才能重新使用缓冲区A。
2022年,一位开发者通过一系列优化,将Linux管道的吞吐量从3.5 GB/s提升到了65 GB/s。关键优化包括使用vmsplice实现零拷贝,使用大页(2MB而不是4KB)减少页表遍历开销,以及使用忙等待代替阻塞等待来消除唤醒延迟。

图片来源: mazzo.li
{kind=link}
这些优化展示了管道的性能潜力,但也揭示了其复杂性。正确使用splice和vmsplice需要对Linux内核的内存管理有深入理解。一个典型的陷阱是:vmsplice返回后,数据可能还在管道中,此时不能立即修改原缓冲区。许多开发者在这里踩坑。
Unix域套接字:灵活性的代价
Unix域套接字(Unix Domain Socket)是另一种流行的本地IPC机制。它使用与TCP套接字相同的编程接口,但通信发生在本地,不经过网络协议栈。
Unix域套接字的优势在于灵活性。它支持流式(SOCK_STREAM)和数据报(SOCK_DGRAM)两种模式。流式模式提供可靠的字节流传输,数据报模式保留消息边界。它还支持传递文件描述符——这是其他IPC机制不具备的能力。
Cloudflare曾利用这个特性实现了一个巧妙的设计。他们需要在不影响现有nginx流量的情况下测试TLS 1.3。解决方案是:让nginx(C语言)接受TCP连接,解析Client Hello,如果客户端支持TLS 1.3,就将TCP套接字的文件描述符通过Unix域套接字传递给Go进程处理。整个过程不需要额外的数据拷贝,连接的上下文完整保留。
Unix域套接字的性能特征
Unix域套接字在内核中的实现与TCP套接字共享大部分代码。关键区别是:Unix域套接字不需要网络协议头,不需要校验和计算,不需要路由查找。数据直接从一个进程的内核缓冲区拷贝到另一个进程的内核缓冲区。
这解释了Baeldung测试中Unix域套接字在大块数据传输时的高性能。当块大小为1MB时,Unix域套接字的吞吐量达到41 Gbit/s,而TCP套接字(回环接口)只有36 Gbit/s。约15%的性能提升来自于省略的协议处理开销。
但在小块数据传输时,Unix域套接字反而比管道慢。100字节块大小时,Unix域套接字吞吐量只有246 Mbit/s,而命名管道达到318 Mbit/s。原因是Unix域套接字的内核实现更复杂。它需要维护完整的套接字状态机(监听、连接、已连接等),支持poll/epoll多路复用,支持非阻塞操作。这些功能的维护开销,在小数据量传输时变得显著。
传递文件描述符的开销
Unix域套接字最强大的特性是传递文件描述符。通过sendmsg()和recvmsg()配合SCM_RIGHTS辅助数据,可以将一个进程的文件描述符传递给另一个进程。
这个操作的本质是:内核在目标进程的文件描述符表中创建一个新条目,指向同一个打开文件对象。打开文件对象包含文件偏移量、访问模式、引用计数等信息。传递文件描述符会增加引用计数,但不拷贝文件内容。
这个操作的开销主要在于辅助数据的处理。sendmsg()需要构建msghdr结构,包含数据缓冲区和辅助数据缓冲区。recvmsg()需要解析接收到的辅助数据,提取文件描述符。整个过程涉及多次内存拷贝和格式转换。
Cloudflare的测试显示,传递单个文件描述符的延迟在微秒级别。对于每秒处理数万连接的高并发服务器,这个开销可以接受。但如果只是传递少量数据,直接在Unix域套接字上发送数据比传递文件描述符更高效。
消息队列:被误解的中等方案
消息队列在IPC谱系中处于中间位置:比共享内存慢,但比管道和套接字快(在某些测试中)。它的性能特征很大程度上取决于具体实现。
Linux提供了两套消息队列接口:System V消息队列和POSIX消息队列。两者在API和实现上有显著差异。
System V消息队列使用msgget()创建或获取消息队列,msgsnd()发送消息,msgrcv()接收消息,msgctl()控制队列属性。消息有类型字段,可以根据类型选择性接收——这是System V消息队列的独特功能。
POSIX消息队列使用mq_open()创建或打开队列,mq_send()发送消息,mq_receive()接收消息,mq_close()关闭队列,mq_unlink()删除队列。POSIX消息队列支持优先级,高优先级消息会被优先接收。它还支持通知机制——当空队列变为非空时,可以发送信号或启动线程。
GitHub上的基准测试显示,System V消息队列的性能在不同消息大小下表现迥异。64字节消息时,吞吐量为207,172 msg/s,接近命名管道。但1024字节消息时,吞吐量骤降至49,418 msg/s,仅为匿名管道的五分之一。
这种"悬崖式"性能下降是消息队列设计的必然结果。消息队列在内核中维护一个链表,每个消息作为一个独立的内核对象存储。发送消息时,内核需要分配内存,将数据从用户空间拷贝到内核空间,将消息挂入链表。接收消息时,内核需要从链表摘除消息,将数据从内核空间拷贝到用户空间,释放内存。
对于小消息,分配和释放内存的开销是主要瓶颈。对于大消息,数据拷贝成为瓶颈。更糟糕的是,System V消息队列有全局限制:最大消息数、最大消息大小、最大总字节数。这些限制可以通过/proc/sys/kernel/msgmax、/proc/sys/kernel/msgmnb等文件调整,但调整需要root权限。
POSIX消息队列在Linux上的实现与System V不同。它使用内存映射文件存储消息队列内容,位于/dev/mq目录下。这意味着POSIX消息队列的元数据可以缓存在用户空间,某些操作不需要系统调用。这解释了为什么POSIX消息队列在低竞争场景下性能更好。
信号量:同步的开销
信号量本身不是IPC机制,而是同步原语。但几乎所有IPC机制都需要配合信号量使用,因此理解它的开销很重要。
Linux提供了三套信号量接口:System V信号量、POSIX有名信号量、POSIX无名信号量。
System V信号量是最复杂的。它不是一个简单的整数,而是一个信号量集,可以同时操作多个信号量。semop()可以原子地执行多个操作:等待信号量A减1,同时信号量B加1。这种复杂性带来了灵活性,但也带来了性能开销。
System V信号量的每次操作都需要系统调用,需要访问内核维护的信号量数据结构。在有竞争的情况下,进程会阻塞,内核需要将进程挂入等待队列,在信号量可用时唤醒进程。这个过程的延迟在毫秒级。
POSIX无名信号量通过sem_init()初始化,存储在共享内存中。如果多个进程共享这块内存,它们可以共享这个信号量。POSIX有名信号量通过sem_open()创建,有文件系统路径名,不相关的进程可以通过路径名访问。
Linux上的POSIX信号量使用futex(Fast Userspace Mutex)实现。在无竞争情况下,信号量的获取和释放完全在用户态完成,通过原子操作修改计数器。只有在竞争情况下才需要系统调用,进入内核态。
这解释了为什么POSIX信号量通常比System V信号量快。一项测试显示,无竞争情况下,POSIX信号量的单次操作延迟在纳秒级,而System V信号量在微秒级。差异可达三个数量级。
但"无竞争"这个前提很关键。在高并发系统中,信号量争抢是常态。一个被多个进程频繁争抢的信号量会成为瓶颈。此时信号量的实现细节不如整体架构设计重要——减少争抢本身才是解决方案。
选择困境:没有完美方案
理解了各种IPC机制的性能特征后,如何选择?
如果只看吞吐量,共享内存是明显的赢家。但共享内存需要手动同步,同步代码的正确性难以保证。一个微妙的竞态条件可能在测试环境不会触发,在生产环境中突然出现,导致数据损坏。
如果只看简单性,管道是最容易的。父子进程通过pipe()创建管道,一个写一个读,不需要额外的同步机制。但管道是单向的(Linux 2.6.35后支持双向管道,但行为与Unix域套接字不同),容量有限,不支持文件描述符传递。
如果只看灵活性,Unix域套接字最全能。流式/数据报模式,阻塞/非阻塞操作,文件描述符传递,与epoll完美配合。但Unix域套接字的性能在小数据量传输时不如管道,大数据量传输时不如共享内存。
消息队列适合消息边界明确的场景。发送方发送一条消息,接收方接收一条完整的消息,不需要自己切分字节流。但消息队列的性能随消息大小下降明显,且有全局限制。
具体场景的选择建议
数据库连接池:多个工作进程共享连接池,使用共享内存存储连接状态,配合POSIX无名信号量同步。连接池状态变化不频繁,同步开销可控。吞吐量是首要目标。
日志收集系统:工作进程将日志发送到收集进程,使用Unix域套接字。日志消息大小不一,Unix域套接字支持变长消息。收集进程可以用epoll同时监听多个工作进程。可靠性比吞吐量更重要,不能因为单个进程阻塞而影响整个系统。
实时音频处理:音频数据以固定速率产生,处理延迟要求严格。使用共享内存配合忙等待,避免系统调用的不可预测延迟。同步使用原子操作,避免锁的开销。延迟是首要目标,可以牺牲CPU利用率。
Web服务器主从架构:主进程监听端口,将连接分配给工作进程。如果使用预派生模型,主进程可以通过Unix域套接字传递文件描述符给工作进程。如果使用线程池模型,所有线程共享进程地址空间,不需要IPC。
配置同步:主进程读取配置,通知工作进程重新加载。使用信号或eventfd。eventfd比管道轻量,只是一个64位计数器,不需要缓冲区。写入是非阻塞的,读取会阻塞直到计数器非零。开销在微秒级,配置重新加载不频繁,性能不是瓶颈。
性能之外的因素
选择IPC机制时,性能只是考量因素之一。可靠性、可维护性、可移植性同样重要。
可靠性涉及数据完整性。管道和Unix域套接字提供可靠传输,数据不会丢失、乱序或重复。消息队列也提供可靠性保证,但需要处理队列满的情况。共享内存不提供任何可靠性保证,进程崩溃可能留下不完整的数据。
可维护性涉及调试难度。管道和Unix域套接字的行为相对简单,问题容易定位。消息队列是内核对象,可以用ipcs命令查看状态。共享内存最难调试,数据竞争的问题可能只在特定时序下出现。
可移植性涉及跨平台兼容。POSIX定义的IPC机制(管道、Unix域套接字、POSIX消息队列、POSIX信号量)在大多数Unix系统上可用。System V IPC在Linux和大部分商业Unix上可用,但Windows不支持。共享内存在所有现代操作系统上都支持,但API不同(Linux用mmap,Windows用CreateFileMapping)。
从基准测试到生产决策
Baeldung的测试显示Unix域套接字在1MB块大小下吞吐量是管道的4.5倍。但这不意味着所有场景都应该选择Unix域套接字。
如果你的应用发送的是64字节的小消息,GitHub的测试显示管道的吞吐量是Unix域套接字的2倍。如果你的应用需要传递文件描述符,只有Unix域套接字支持。如果你的应用需要多进程共享状态,共享内存是唯一选择。
更关键的是,基准测试测量的是理想条件下的峰值性能。生产环境有更多变数:CPU缓存热度、内存带宽竞争、调度延迟、其他进程的干扰。一个在基准测试中快10%的方案,在生产环境中可能快5%,也可能慢20%。
正确的做法是:理解每种IPC机制的性能特征和适用场景,根据具体需求缩小选择范围,然后在候选方案上进行实际测试。测试应该在目标硬件上进行,使用真实的工作负载,考虑长尾延迟而不仅仅是平均吞吐量。
共享内存确实比管道快100倍,但只有在你正确使用它时。Unix域套接字确实比管道灵活,但只有在你需要这种灵活性时。选择IPC机制,本质上是在性能、可靠性、复杂性之间做权衡。没有最优解,只有最适合的解。
参考资料
- Durairaj, R., & Krishnaveni, S. (2016). Comparing and Evaluating the Performance of Inter Process Communication Models in Linux Environment. International Journal of Trend in Research and Development.
- Baeldung. (2023). IPC Performance Comparison: Anonymous Pipes, Named Pipes, Unix Sockets, and TCP Sockets. https://www.baeldung.com/linux/ipc-performance-comparison
- brylee10. (2023). Unix IPC Benchmarks. GitHub. https://github.com/brylee10/unix-ipc-benchmarks
- mazzo.li. (2022). How fast are Linux pipes anyway? https://mazzo.li/posts/fast-pipes.html
- Eli Bendersky. (2018). Measuring context switching and memory overheads for Linux threads. https://eli.thegreenplace.net/2018/measuring-context-switching-and-memory-overheads-for-linux-threads/
- Cloudflare. (2018). Know your SCM_RIGHTS. https://blog.cloudflare.com/know-your-scm_rights/
- Linux man-pages project. (2025). pipe(7) - Linux manual page. https://man7.org/linux/man-pages/man7/pipe.7.html
- Linux man-pages project. (2025). unix(7) - Linux manual page. https://man7.org/linux/man-pages/man7/unix.7.html
- Goldsborough, P. IPC Bench. https://github.com/goldsborough/ipc-bench