1983年,当Linus Torvalds还在芬兰赫尔辛基大学读书时,Unix系统的中断处理已经发展了二十多年。那时的中断处理程序必须完成所有工作:响应硬件、读取数据、通知进程。这种设计在单处理器、低频率设备时代还算可行,但随着网络速度从10Mbps攀升到100Mbps,再到今天的400Gbps,中断处理的时间预算被压缩到了微秒级。
一个看似简单的中断处理,为什么需要分成"顶半部"和"底半部"两段执行?为什么Linux内核先后引入了softirq、tasklet、workqueue、threaded interrupt四种不同的延迟处理机制?为什么PREEMPT_RT补丁要把几乎所有的中断处理都线程化?这背后是一场持续了四十年的架构博弈。
被打断的代价
理解中断处理的设计,首先要理解什么是中断上下文(interrupt context)。
当网卡收到一个数据包,它会通过IRQ线向CPU发出中断请求。CPU立即停止当前正在执行的进程,跳转到中断处理程序。此时,CPU处于中断上下文——这不是一个进程,没有进程控制块(task_struct),没有用户空间地址,没有属于自己的内核栈。中断处理程序借用被中断进程的内核栈,这个栈通常只有8KB(某些架构是16KB)。
这就是第一个硬约束:中断上下文不能睡眠。
睡眠意味着调用调度器,调度器需要一个可调度的实体(进程)。但中断上下文不是一个进程,它只是一个临时的执行状态。如果中断处理程序调用了schedule()、kmalloc(GFP_KERNEL)、或者任何可能阻塞的函数,内核会崩溃——没有进程可以切出去,也没有进程可以切回来。
// 这段代码会导致内核崩溃
irqreturn_t my_interrupt_handler(int irq, void *dev_id)
{
// 错误!在中断上下文中调用可能睡眠的函数
char *buf = kmalloc(1024, GFP_KERNEL); // GFP_KERNEL可能睡眠
// 错误!试图获取可能睡眠的互斥锁
mutex_lock(&my_mutex); // mutex可能睡眠
// 错误!访问用户空间内存
copy_from_user(user_buf, kernel_buf, size); // 可能导致页面错误
return IRQ_HANDLED;
}
第二个约束是时间。当中断发生时,CPU会禁用当前处理器的中断(x86上清除IF标志)。在禁用中断期间,所有其他中断都被阻塞。如果中断处理程序执行了10毫秒,那么这10毫秒内所有其他中断都无法响应——包括高优先级的定时器中断、其他设备的紧急中断。
这导致了一个经典的性能陷阱:中断风暴。假设一个高速网卡每秒产生100万次中断(现代10GbE网卡在高负载下很容易达到),每次中断处理需要10微秒。这意味着每秒有10秒的CPU时间花在中断处理上——数学上不可能,但实际会发生的是:CPU一直困在中断处理中,用户进程永远得不到调度。
图片来源: Linux Kernel Labs
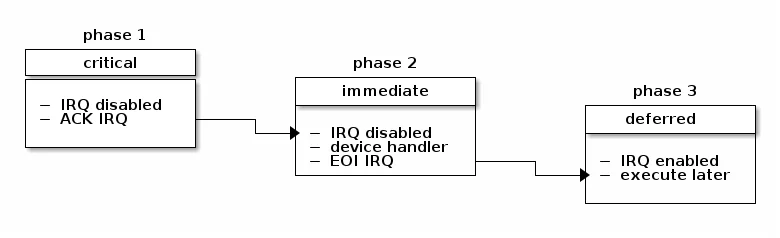
顶半部:必须做的最少工作
面对这两个约束,Unix系统设计者提出了"顶半部"和"底半部"的分离策略。
顶半部(Top Half) 是真正的中断处理程序,它在硬件中断上下文中执行,必须遵守严格的约束:
- 执行时间要尽可能短(理想情况下几微秒)
- 不能睡眠
- 只做必须立即完成的工作
“必须立即完成"的工作是什么?通常包括:
- 确认中断(acknowledge interrupt):告诉中断控制器"我正在处理这个中断”,这样中断控制器才能接收新的中断
- 读取时间敏感的数据:某些硬件的FIFO缓冲区很小,必须在溢出前读取
- 唤醒底半部处理:调度延迟处理
一个典型的网卡中断处理程序的顶半部:
irqreturn_t network_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
// 顶半部:只做最紧急的工作
// 1. 确认中断
writel(IRQ_ACK, dev->mmio_base + REG_IRQ_STATUS);
// 2. 禁用这个设备的中断(防止中断风暴)
writel(0, dev->mmio_base + REG_IRQ_ENABLE);
// 3. 调度底半部处理
napi_schedule(&dev->napi);
// 整个顶半部可能只需要几微秒
return IRQ_HANDLED;
}
注意到顶半部禁用了设备中断。这是防止中断风暴的关键策略:当有大量数据包到达时,不要让每个包都触发一次中断。相反,禁用中断,然后让底半部以轮询方式批量处理。
底半部:四个时代的演进
底半部(Bottom Half)的历史是一部不断权衡的历史。Linux内核先后引入了四种不同的机制,每种都在解决前一种的特定问题。
第一代:BH(Bottom Half,2.0内核)
Linux 2.0时代的底半部机制非常简单:内核维护一个全局的位图,每个位代表一个底半部处理函数。顶半部设置相应的位,内核在适当的时候检查并执行。
问题也很明显:全局锁。同一时间只能有一个CPU执行底半部代码,即使系统有多个CPU。在单核时代这不是问题,但随着SMP(对称多处理器)的普及,BH成为性能瓶颈。
第二代:Softirq(2.4内核,1999年)
1999年,Linux 2.4内核引入了Softirq,这是为高性能网络设计的机制。Softirq的核心思想是:
- 静态分配:内核编译时就确定了所有softirq类型(网络发送、网络接收、定时器、块设备等)
- 可并行:同一类型的softirq可以在不同CPU上同时执行
- 原子上下文:softirq仍然在中断上下文中执行,不能睡眠
Softirq的定义:
enum
{
HI_SOFTIRQ=0, // 高优先级tasklet
TIMER_SOFTIRQ, // 定时器
NET_TX_SOFTIRQ, // 网络发送
NET_RX_SOFTIRQ, // 网络接收
BLOCK_SOFTIRQ, // 块设备
IRQ_POLL_SOFTIRQ, // 中断轮询
TASKLET_SOFTIRQ, // 普通tasklet
SCHED_SOFTIRQ, // 调度器
HRTIMER_SOFTIRQ, // 高精度定时器
RCU_SOFTIRQ, // RCU回调
NR_SOFTIRQS
};
Softirq的执行时机非常特殊:
- 在硬中断返回后立即执行
- 在
local_bh_enable()时执行 - 在
ksoftirqd内核线程中执行
这个设计有一个深刻的原因:避免上下文切换。当网络包以每秒百万计的速度到达时,每个包触发一次进程唤醒和调度是不可接受的性能开销。Softirq在中断返回后立即执行,数据包直接被处理并放入进程的接收队列,不需要任何上下文切换。
但这也带来了问题:Softirq可能"饿死"用户进程。如果网络负载极高,Softirq会持续执行,用户进程永远得不到CPU。
第三代:Tasklet(2.4内核)
Softirq太底层,使用不当会导致系统不稳定。Tasklet是在Softirq之上构建的更安全的机制:
// Tasklet是动态创建的
DECLARE_TASKLET(my_tasklet, my_tasklet_handler, data);
// 在中断处理程序中调度
tasklet_schedule(&my_tasklet);
Tasklet与Softirq的关键区别是:同一类型的tasklet在任何时刻只能在一个CPU上执行。这解决了并发访问共享数据的复杂性,但牺牲了并行性。
2024年2月,Linux内核开发者决定废弃tasklet。原因在于tasklet API存在设计缺陷:tasklet函数返回后,tasklet子系统可能还会访问tasklet_struct结构,如果函数内部释放了这个结构,就会导致use-after-free。
替代方案是新的WQ_BH工作队列类型,它提供了类似tasklet的低延迟特性,但没有API缺陷。
第四代:Workqueue(2.5内核)
Workqueue是完全不同的设计:延迟工作在进程上下文中执行,可以睡眠。
// 创建工作项
INIT_WORK(&my_work, my_work_handler);
// 调度
schedule_work(&my_work);
Workqueue的优势:
- 可以睡眠
- 可以访问用户空间
- 有完整的进程上下文
- 可以设置优先级
代价是更高的延迟:工作项需要通过调度器调度,可能需要等待其他进程释放CPU。
中断线程化:实时性的终极答案
2009年,Linux 2.6.30合并了threaded interrupt(中断线程化),这是从PREEMPT_RT实时补丁项目迁移过来的核心技术。
传统的中断处理模型有一个根本性问题:中断优先级高于任何进程。无论进程的实时优先级多高,硬件中断都能打断它。这对于硬实时系统是不可接受的——如果实时进程必须在100微秒内响应,但一个中断处理程序执行了200微秒,实时保证就被打破了。
Threaded interrupt的解决方案很简单:把中断处理程序变成内核线程。
// 传统方式:处理程序在中断上下文执行
request_irq(irq, my_handler, 0, "my_device", dev);
// 线程化方式:处理程序在内核线程中执行
request_threaded_irq(irq, my_primary_handler, my_thread_fn,
IRQF_ONESHOT, "my_device", dev);
my_primary_handler仍在硬中断上下文中执行,但它应该只做最少的工作(如确认中断),然后返回IRQ_WAKE_THREAD唤醒内核线程。真正的处理工作在my_thread_fn中执行,这是一个普通的内核线程,可以被调度、被抢占、被更高优先级的实时进程打断。
在PREEMPT_RT内核中,几乎所有中断都被强制线程化。这带来一个有趣的现象:标准内核中,高负载网络可能导致ksoftirqd进程占用大量CPU;而在PREEMPT_RT内核中,这些工作分散在irq/内核线程中,可以被实时调度器管理。
NAPI:中断与轮询的混合
网络子系统面临一个独特的挑战:现代高速网卡(10Gbps、25Gbps、100Gbps)可以在极短时间内产生大量中断。如果每个数据包触发一次中断,CPU会完全被中断处理占用。
NAPI(New API)是Linux对这一问题的回答,它混合了中断和轮询两种模式:
- 低负载时:使用中断模式。每个数据包触发一次中断
- 高负载时:切换到轮询模式。禁用中断,内核主动轮询网卡
// NAPI的核心:中断处理程序
irqreturn_t napi_interrupt(int irq, void *dev_id)
{
struct napi_struct *napi = dev_id;
// 禁用中断,调度NAPI轮询
napi_schedule(napi);
return IRQ_HANDLED;
}
// NAPI轮询函数
int napi_poll(struct napi_struct *napi, int budget)
{
int work_done = 0;
// 处理最多budget个数据包
while (work_done < budget && has_packets()) {
process_one_packet();
work_done++;
}
if (work_done < budget) {
// 没有更多数据包,重新启用中断
napi_complete(napi);
enable_interrupts();
}
return work_done;
}
NAPI的budget参数是一个精妙的权衡:太大会增加延迟(其他进程得不到CPU),太小会降低吞吐量(一次中断只处理少量数据包)。默认值通常是64或300个数据包。
NAPI的另一个优势是批处理。在轮询模式下,数据包可以批量处理,充分利用CPU缓存。研究表明,批处理可以将每包处理开销降低30%以上。
中断亲和性:多核时代的调度艺术
在多核系统中,中断可以路由到不同的CPU核心。正确配置中断亲和性对性能至关重要。
# 查看中断亲和性
cat /proc/irq/44/smp_affinity
0000000f
# 设置中断只由CPU 0-3处理
echo 0f > /proc/irq/44/smp_affinity
中断亲和性的设计有几个考虑:
缓存局部性:如果网卡中断和用户进程在不同的CPU上,数据需要跨CPU缓存传输。更好的方案是让网卡中断和接收数据包的进程在同一个CPU上。
负载均衡:高速网卡通常使用多队列(RSS),每个队列的中断可以绑定到不同的CPU。这实现了中断处理的并行化。
实时隔离:在实时系统中,可以把所有普通中断绑定到一组CPU,让另一些CPU专门运行实时任务。这通过isolcpus内核参数和irqaffinity配置实现。
ksoftirqd:最后的防线
当softirq持续到达,超过了内核在硬中断返回后能够处理的限度时,剩余的softirq被交给ksoftirqd内核线程处理。
每个CPU有一个ksoftirqd线程:
# ps -e | grep ksoftirqd
837 ? 00:00:00 ksoftirqd/0
838 ? 00:00:00 ksoftirqd/1
839 ? 00:00:00 ksoftirqd/2
840 ? 00:00:00 ksoftirqd/3
ksoftirqd是一个调度实体,它使用SCHED_NORMAL优先级。这意味着:
- 它可以和其他进程公平地竞争CPU
- 它不会饿死用户进程
- 它可以被实时进程抢占
当ksoftirqd占用大量CPU时,通常意味着系统有极高的网络或块设备负载。这不是问题本身,而是系统正在正确地平衡softirq处理和用户进程执行。
内核代码中的关键检查:
static void irq_exit(void)
{
// ...
// 如果softirq处理时间过长或重启次数过多
if (time_after(jiffies, end_time) ||
--restart <= 0) {
// 唤醒ksoftirqd
wakeup_softirqd();
return;
}
// 否则继续在当前上下文处理
invoke_softirq();
}
四种机制的选择指南
面对四种底半部机制,如何选择?以下是决策框架:
| 机制 | 执行上下文 | 能否睡眠 | 并发性 | 典型场景 |
|---|---|---|---|---|
| Softirq | 中断上下文 | 不能 | 同类型可并行 | 网络收发、RCU |
| Tasklet | 中断上下文 | 不能 | 同实例串行 | 设备驱动(已废弃) |
| Workqueue | 进程上下文 | 能 | 无限制 | 文件系统操作 |
| Threaded IRQ | 进程上下文 | 能 | 无限制 | 实时驱动 |
具体选择建议:
- 网络驱动:使用Softirq + NAPI。这是唯一能处理每秒百万包的机制
- 块设备驱动:使用Softirq或Workqueue,取决于是否需要文件系统操作
- 需要访问用户空间:必须使用Workqueue或Threaded IRQ
- 需要睡眠锁:必须使用Workqueue或Threaded IRQ
- 实时系统:使用Threaded IRQ,配合
SCHED_FIFO优先级设置
实践中的性能调优
监控中断分布
# 查看中断统计
watch -n1 "cat /proc/interrupts"
# 查看每个CPU的softirq时间
cat /proc/softirqs
# 使用perf分析中断处理
perf record -e irq:* -a sleep 10
perf report
调整NAPI参数
# 调整NAPI预算(默认64)
sysctl -w net.core.netdev_budget=300
# 启用忙轮询(低延迟应用)
sysctl -w net.core.busy_poll=50
sysctl -w net.core.busy_read=50
配置中断亲和性
# 将网卡中断绑定到CPU 0-3
for irq in $(grep eth0 /proc/interrupts | cut -d: -f1); do
echo 0f > /proc/irq/$irq/smp_affinity
done
# 使用irqbalance自动平衡
systemctl enable irqbalance
设计哲学:没有完美的方案
回顾中断处理机制四十年的演进,可以看到几个反复出现的主题:
延迟与吞吐量的权衡:Softirq延迟最低但可能饿死进程;Workqueue延迟较高但公平性好。NAPI在高负载时牺牲延迟换取吞吐量。
并行性与简单性的权衡:Softirq允许多核并行但需要复杂的锁机制;Tasklet串行执行但编程简单。
实时性与效率的权衡:Threaded IRQ提供了实时性保证,但增加了上下文切换开销。
这些权衡没有"正确"答案,只有适合特定场景的选择。理解这些机制的设计动机,才能在系统设计和性能调优中做出正确的决策。
Linux内核的中断处理架构不是一蹴而就的设计,而是四十年来无数工程师在面对真实问题时不断演进的产物。从最初的"中断处理程序做完所有事",到顶半部/底半部分离,再到中断线程化,每一次演进都解决了一个特定的痛点,但也引入了新的复杂性。这正是系统设计的本质:在约束条件下寻找最优解,而约束本身也在不断变化。
参考资料
- The end of tasklets - LWN.net
- How realtime kernels differ - Linux Kernel Documentation
- Interrupts - Linux Kernel Labs
- NAPI - Linux Kernel Documentation
- SMP IRQ affinity - Linux Kernel Documentation
- Interrupt handler - Wikipedia
- Juggling software interrupts and realtime tasks - LWN.net
- Understanding the Linux Kernel, 3rd Edition - O’Reilly
- Linux Device Drivers, 3rd Edition - O’Reilly
- Softirqs, Tasklets, Bottom Halves - Matthew Wilcox