2014年,Daniel Lemire和Samy Chambi等人在arXiv上发表了一篇题为《Better bitmap performance with Roaring bitmaps》的论文。论文的核心结论令人印象深刻:相比当时主流的压缩位图方案WAH和Concise,Roaring bitmaps在交集操作上快了最多900倍,同时压缩率还提高了约2倍。这不是学术界的理论推演,而是基于真实数据集的实测结果。
这个发现挑战了当时业界的普遍认知。在此之前,基于游程编码(Run-Length Encoding, RLE)的压缩位图被认为是最优解。Oracle数据库使用它,学术界研究它,工程界信任它。Roaring bitmaps的出现揭示了一个被忽视的真相:压缩率和操作速度之间不存在不可调和的矛盾,关键在于选择正确的压缩策略。
位图的原始困境:当空间成为噩梦
要理解Roaring bitmaps的价值,必须先回到问题的起点——传统位图的本质缺陷。
位图(Bitmap)的核心思想极其简洁:用一个比特位表示一个整数是否存在。整数$N$存在,则第$N$位设为1;否则为0。这种表示方式有一个致命的优势——位运算的天然并行性。计算两个集合的交集,只需对两个位图执行按位与(AND)操作;计算并集,执行按位或(OR)。在现代CPU上,一条指令可以同时处理64位甚至更多(借助SIMD指令集可达512位),这使得集合操作的速度接近硬件极限。
问题出在稀疏数据上。假设你需要存储一个只包含两个整数 $\{100, 200000000\}$ 的集合。传统位图需要分配从第0位到第2亿位的连续空间——大约25MB内存——只为了存储两个有效位。这就是位图的"空洞问题":数据越稀疏,空间浪费越严重。
在搜索引擎和数据分析场景中,稀疏数据是常态而非例外。一个电商平台的商品索引中,“显卡"这个词可能只出现在万分之一的商品描述中;一个用户标签系统中,“高净值客户"可能只覆盖千分之一的用户。如果用传统位图存储这些数据,内存开销将变得不可接受。
压缩位图的早期尝试:RLE的统治与局限
在Roaring bitmaps之前,业界主要采用基于游程编码的压缩方案。最具代表性的是WAH(Word Aligned Hybrid)和Concise。
WAH的核心思想是将位图按机器字长(32位或64位)分块,然后对每块进行编码。如果一个字的所有位都是0,用一个特殊的标记字表示;如果是连续多个全0字,用一个字记录数量。对于非均匀的字,则原样存储。这种方案对大量连续0的区域压缩效果很好。
Concise在此基础上做了改进,采用了更紧凑的编码方式,压缩率进一步提高。
然而,这些RLE方案有一个共同的软肋:解码开销。执行交集或并集操作时,必须先解码压缩数据,操作完成后可能还需要重新压缩。当数据不是完美的连续0或连续1时,频繁的编码解码会严重拖慢操作速度。
2017年SIGMOD会议上发表的一篇论文《An Experimental Study of Bitmap Compression vs. Inverted List Compression》系统比较了各种方案,发现一个有趣的结论:在某些场景下,压缩位图甚至不如原始的倒排列表快。原因正是解码开销抵消了位运算的速度优势。
Roaring Bitmaps的设计哲学:分块自治,因地制宜
Roaring bitmaps采取了完全不同的策略。它不追求单一的压缩算法,而是承认一个事实:不同的数据分布需要不同的表示方式。
其核心架构可以概括为三句话:
- 分块隔离:将32位整数空间划分为65536个块,每块覆盖$2^{16}$个连续整数
- 自适应容器:每块独立选择最优的存储容器
- 零解码开销:所有操作直接在压缩数据上进行
graph TB
subgraph Roaring Bitmap结构
INDEX["一级索引<br/>(高16位排序数组)"] --> C1["容器1<br/>Array Container"]
INDEX --> C2["容器2<br/>Bitmap Container"]
INDEX --> C3["容器3<br/>Run Container"]
end
subgraph 整数映射
N["整数N"] --> HIGH["高16位 → 块索引"]
N --> LOW["低16位 → 块内偏移"]
end
HIGH --> INDEX
LOW --> C1
一级索引:高16位的路由表
Roaring bitmaps将32位无符号整数的高16位作为"块索引”。例如,整数$131090$的二进制表示为0000 0000 0000 0010 0000 0000 0001 0010,高16位为2,意味着它属于第2号块;低16位是18,表示它在块内的偏移是18。
一级索引存储所有已存在的块的高16位值及其对应的容器指针,以排序数组的形式组织。查找一个整数时,先用二分查找定位到对应的块,再在块内查找。由于一级索引是有序数组,查找时间复杂度为$O(\log m)$,其中$m$是已存在的块数量(最多65536)。
三种容器:各司其职的精妙分工
Roaring bitmaps定义了三种容器类型,每种针对特定的数据分布进行优化:
Array Container(数组容器)
当块内元素数量不超过4096时使用。本质上是一个16位整数的排序数组,直接存储每个元素的低16位。
为什么是4096?这是经过精确计算的临界值:
$$4096 \times 2 \text{ bytes} = 8192 \text{ bytes} = 2^{16} \text{ bits}$$恰好等于一个Bitmap Container的大小。当元素更少时,数组更省空间;当元素更多时,位图更省空间。
Array Container的查找使用二分搜索,时间复杂度$O(\log n)$。虽然比Bitmap的$O(1)$稍慢,但在元素数量有限时($\leq 4096$),实际差异可以忽略。
Bitmap Container(位图容器)
当块内元素数量超过4096时使用。这是一个标准的$2^{16}$位(8KB)位图,每位对应一个可能的低16位值。查找是$O(1)$的直接位访问,对于密集数据既快速又紧凑。
Run Container(游程容器)
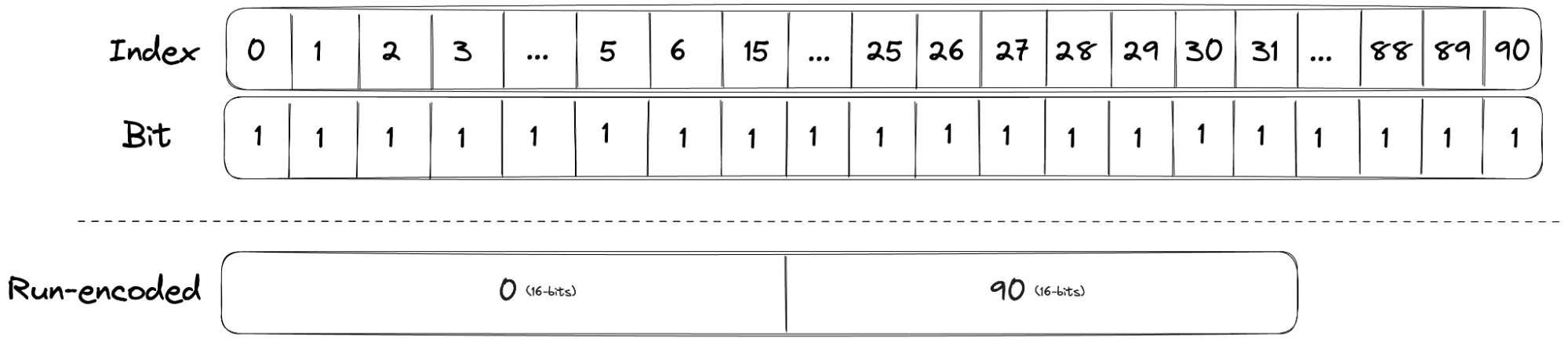
这是2016年第二篇论文引入的优化,专门处理长连续序列。例如,块内包含$\{0, 1, 2, ..., 99\}$这100个连续整数,用Array Container需要200字节(100个16位整数),用Bitmap Container需要8KB,而Run Container只需要4字节(存储起始值0和长度99)。
Run Container使用变长的short数组,偶数位置存储游程起始值,奇数位置存储游程长度减一。检测是否应该使用Run Container的逻辑很简单:只有当它确实比Array或Bitmap更小时才转换。
容器转换:动态适应数据变化
Roaring bitmaps的精妙之处在于容器类型不是固定的。随着数据的增删,容器会自动转换:
- Array Container元素超过4096 → 转换为Bitmap Container
- Bitmap Container元素减少到4096以下 → 转换为Array Container
- 调用
runOptimize()时 → 如果Run Container更小则转换
这种自适应机制确保了无论数据如何变化,始终使用最优的存储方式。
交集操作:为什么快900倍
Roaring bitmaps相比RLE方案最显著的性能优势体现在交集操作上。原因在于不需要解码。
考虑两个Roaring bitmaps求交集的过程:
- 遍历两个一级索引,找到具有相同高16位的块对
- 对每个匹配的块对,根据容器类型选择算法:
- Bitmap × Bitmap:直接按位与,结果按基数决定容器类型
- Bitmap × Array:遍历Array元素,检查Bitmap中对应位是否为1
- Array × Array:类似归并排序的双指针合并
关键观察:整个过程中没有任何解压缩操作。数据始终以压缩形式参与计算,CPU直接操作压缩后的结构。
相比之下,WAH和Concise在执行交集时必须:
- 解码压缩块为原始位图(或部分解码)
- 执行位运算
- 可能需要重新压缩结果
当数据不是理想的连续0区域时,这个解码-计算-编码的循环会反复发生,成为性能瓶颈。
论文中给出的实测数据:
| 操作类型 | Roaring vs WAH | Roaring vs Concise |
|---|---|---|
| 稀疏数据交集 | 900× 快 | 30× 快 |
| 密集数据交集 | 4× 快 | 3× 快 |
| 压缩率提升 | 4× 更小 | 2× 更小 |
注意这里的"稀疏数据"在位图语境下指的是大量0和少量1交替出现的模式,这是RLE最不擅长处理的场景。
实战应用:从Lucene到Grab
Roaring bitmaps已经渗透到现代数据系统的各个角落。
Elasticsearch/Lucene:倒排索引的压缩革命
2015年,Lucene 5引入了Roaring bitmaps作为filter cache的存储格式。官方博客详细解释了这个决策的技术背景。
在搜索引擎中,倒排索引将词项映射到文档ID列表。当执行布尔查询如"Java AND Python AND Rust"时,需要对三个文档ID集合求交集。如果这些集合用传统位图存储,内存开销巨大;如果用跳表存储,求交集需要多路归并。
Lucene采用了一种混合策略:
- 磁盘上的倒排索引:使用Frame of Reference(FOR)编码,将文档ID分块压缩存储
- 内存中的filter cache:使用Roaring bitmaps缓存频繁使用的过滤器结果
Elasticsearch的基准测试显示,使用Roaring bitmaps后,filter cache的内存占用下降了约60%,而查询延迟几乎没有变化。
Grab:用户分群的性能飞跃
东南亚超级应用Grab在2023年的技术博客中分享了他们使用Roaring bitmaps的经验。Grab的Segmentation Platform需要处理数千万用户的标签分群,用于个性化推荐、营销触达和风控决策。
原有方案将用户ID逐行存储在ScyllaDB中,一个百万用户的分群需要约4MB存储。当需要检查用户是否属于某个分群时,必须查询数据库。
迁移到Roaring bitmaps后:
- 百万用户分群压缩到**<1MB**
- 通过SDK本地缓存,会员检查延迟从40ms降到<1ms
- 支持实时的集合运算(交、并、差),无需重新计算
Grab的通讯平台借助这个能力实现了新的频率控制功能,能够同时对多个百万级分群执行交集运算,QPS达到15000,P99延迟仍低于1ms。
ClickHouse:列式分析的加速引擎
ClickHouse将Roaring bitmaps作为原生数据类型支持,允许在SQL中直接使用。这对于用户画像分析特别有用:
-- 计算同时满足多个标签的用户数
SELECT
rb_and_cardinality(
rb_build(group_array(user_id)) FILTER (WHERE tag = 'vip'),
rb_build(group_array(user_id)) FILTER (WHERE tag = 'active')
) as overlap_count
FROM user_tags
ClickHouse还支持将Roaring bitmap序列化存储,用于构建预聚合的用户画像表,大幅降低实时查询的计算压力。
与其他数据结构的权衡
Roaring bitmaps不是万能药,它有自己的适用边界。
vs 传统BitSet
BitSet在密集数据上依然是最快的选择。当你的数据密度超过50%时,BitSet的直接位访问几乎无法被超越。Roaring bitmaps的额外开销(一级索引、容器管理)在密集场景下反而成为负担。
Baeldung的基准测试给出了具体数据:对于1000万个元素、密度50%的集合,BitSet的并集操作吞吐量为3000 ops/s,而Roaring bitmaps为6200 ops/s——优势明显。但对于100%密度的集合,两者差距缩小。
vs Bloom Filter
Bloom Filter和Roaring bitmaps解决的是不同的问题。Bloom Filter是概率数据结构,允许假阳性(报告存在但实际不存在),但空间占用极小。Roaring bitmaps是精确数据结构,不允许任何错误。
| 特性 | Roaring Bitmaps | Bloom Filter |
|---|---|---|
| 准确性 | 100%精确 | 允许假阳性 |
| 空间效率 | 依赖数据分布 | 固定(约9.6 bits/元素) |
| 删除操作 | 支持 | 不支持(标准版) |
| 集合运算 | 精确的交、并、差 | 只能合并,不能求交集 |
如果你的场景可以容忍假阳性,Bloom Filter通常更省空间。如果必须精确,Roaring bitmaps是更好的选择。
vs HyperLogLog
HyperLogLog用于基数估计,即估算一个集合有多少个不同元素。它的空间占用极小——只需12KB就能估计数十亿级基数,误差约2%。
Roaring bitmaps可以用于精确基数计算(cardinality()操作),但空间占用随集合大小线性增长。两者不在同一竞争维度:需要精确结果用Roaring,只需要估计用HLL。
工程实现的考量
在生产环境中使用Roaring bitmaps需要考虑几个实际问题:
语言和库选择
官方维护了多语言实现:
- Java:
org.roaringbitmap:RoaringBitmap - Go:
github.com/RoaringBitmap/roaring - C/C++:
github.com/RoaringBitmap/CRoaring(支持AVX2/AVX-512/NEON SIMD优化) - Rust:
github.com/RoaringBitmap/roaring-rs
CRoaring是性能最优的实现,包含了大量SIMD优化。Java和Go版本适合快速集成,性能略低但足够应对大多数场景。
64位支持
Roaring bitmaps最初为32位整数设计。64位版本(如CRoaring的roaring64_bitmap_t)通过映射多个32位Roaring bitmap实现,空间效率略有下降,但原理相同。
序列化格式
所有实现都遵循统一的序列化规范,可以在不同语言间互操作。这意味着你可以在Java服务中创建Roaring bitmap,序列化后传输给Go服务继续使用。
冷热数据分离
对于大规模部署,建议将Roaring bitmaps存储在对象存储(如S3)中,服务启动时按需加载到本地缓存。Grab的SDK实现就是这个模式,通过LRU缓存管理内存使用。
结语
Roaring bitmaps的成功揭示了一个工程真理:最优解往往不是单一算法,而是多种策略的智能组合。通过分块自治、容器自适应的设计,它在稀疏和密集数据、压缩率和操作速度之间找到了精妙的平衡点。
从2014年的论文到今天被Elasticsearch、ClickHouse、Spark、Redis等系统广泛采用,Roaring bitmaps已经证明了它的实用价值。当你下次需要处理大规模集合运算时,不妨考虑一下这个"压缩位图之王”——它可能比你想象的更快、更省。
参考资料
- Chambi, S., Lemire, D., Kaser, O., & Godin, R. (2016). Better bitmap performance with Roaring bitmaps. Software: Practice and Experience, 46(5), 709-719. arXiv:1402.6407
- Lemire, D., Kaser, O., Kurz, A., Deri, L., Vagh, C., Aji, M., & Glavic, S. (2018). Roaring Bitmaps: Implementation of an Optimized Software Library. Software: Practice and Experience, 48(4), 867-895. arXiv:1709.07821
- Elastic Blog. (2015). Frame of Reference and Roaring Bitmaps. elastic.co/blog
- Grab Engineering. (2023). Streamlining Grab’s Segmentation Platform. engineering.grab.com
- Baeldung. (2024). Introduction to Roaring Bitmap. baeldung.com
- RoaringBitmap Official Site. roaringbitmap.org
- GitHub - CRoaring. github.com/RoaringBitmap/CRoaring
- Wang, K., et al. (2017). An Experimental Study of Bitmap Compression vs. Inverted List Compression. SIGMOD 2017. cs.purdue.edu
- Oberoi, V. (2022). A primer on Roaring bitmaps. vikramoberoi.com
- ClickHouse Documentation. Roaring Bitmap Functions. clickhouse.com