2023年6月,微软研究院发布了一篇标题充满争议性的论文:《Textbooks Are All You Need》。论文介绍了phi-1模型——一个仅有13亿参数的语言模型,在HumanEval代码基准测试上达到了50.6%的pass@1准确率,超越了拥有超过100倍参数的模型。秘密在于它的训练数据:70亿token的网页数据和10亿token由GPT-3.5生成的合成教科书数据。
这个结果引发了一个更深层的问题:用AI生成的数据来训练AI,究竟是通往更强大模型的高速公路,还是一条通往自我毁灭的死胡同?
数据稀缺与新范式
2022年,一项被广泛引用的研究预测:按照当前的数据消耗速度,高质量文本数据将在2050年耗尽,图像数据将在2060年耗尽。这个预测揭示了深度学习面临的一个根本性约束——数据的可获得性。
传统的大模型训练依赖海量的人类生成内容:网页、书籍、代码、对话记录。这些数据的采集面临三重困境:
数据稀缺:特定领域的高质量数据极其有限。医疗、法律、科学等专业领域的文本不仅数量有限,还涉及版权和隐私问题。
隐私合规:欧盟GDPR、加州CCPA等法规对个人数据的使用施加了严格限制。医疗记录、金融交易等敏感数据难以直接用于模型训练。
标注成本:监督学习需要大量人工标注。即使是GPT-4这样的模型,其训练数据中的指令响应对也耗费了数百万美元的标注成本。
合成数据提供了一个看似完美的解决方案:用算法生成的人工数据替代真实数据,既能无限扩展,又能规避隐私问题。但这引出了一个更深层的问题:当AI开始"吃自己生成的数据"时,会发生什么?
模型崩溃:Nature论文揭示的隐患
2024年7月,Nature发表了一篇来自牛津大学、剑桥大学等多所机构联合研究团队的论文,标题为《AI models collapse when trained on recursively generated data》。论文的核心发现令人警醒:当模型被递归地训练于前一代模型生成的数据时,会发生"模型崩溃"(Model Collapse)现象。
研究团队设计了一个实验:从一个初始的真实数据集开始,训练第一个模型;然后让这个模型生成数据,用于训练第二个模型;如此递归多代。结果显示,模型的输出质量逐代下降,最终退化为只产生重复、无意义的内容。
模型崩溃的机制可以从两个层面理解:
统计近似误差:生成模型只能基于有限的训练样本学习真实分布。这意味着它永远无法完美地捕捉原始数据分布的全部信息,尤其是那些出现频率很低的"尾部"数据。当这些不完美的复制被用于训练下一代模型时,误差会逐代累积。
函数近似误差:神经网络的架构限制了其表达能力。即使是理论上具有通用近似能力的网络,在实践中也会因为优化困难、正则化等因素而无法完全还原真实分布。
在完全合成训练的情况下,模型的条件概率分布会逐渐收敛到某个Dirac分布,即模型总是输出同一个token,输出的多样性完全丧失。这就是所谓的"完全崩溃"(Total Collapse)。
数学视角:为什么会崩溃
2024年4月,另一篇发表在arXiv上的论文《How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse》提供了严格的数学分析框架。
研究团队将语言模型抽象为一个条件概率估计问题。给定一个上下文,模型需要估计下一个token的概率分布。在有限样本情况下,这个估计存在方差,而方差会在递归训练中累积。
论文证明了一个关键定理:在完全合成训练(每代模型仅使用上一代模型生成的数据)的情况下,完全崩溃必然发生。设$N$为崩溃发生的代数,$n$为每代的样本量,有:
$$E[N] = O(n)$$这意味着样本量越大,崩溃发生得越晚,但终究无法避免。当训练只依赖合成数据时,原始分布的"尾部"——那些出现频率低但仍有价值的信息——会逐渐消失,模型最终退化为只输出最常见的内容。
突围之路:累积数据策略
然而,模型崩溃并非不可避免。多项研究指出了关键的解决思路。
混合真实数据
当训练数据中包含一定比例的真实数据时,崩溃可以被避免。研究证明了在部分合成训练(每代模型使用真实数据和合成数据的混合)情况下,存在一个阈值:当合成数据量不超过某个上限时,模型可以保持稳定。
具体而言,设真实数据量为$n_0$,合成数据量为$n_s$,当$n_s$满足:
$$n_s = O(n_0 / \log(n_0/\epsilon))$$模型与原始分布的偏差可以被控制在$\epsilon$以内。这意味着合成数据量应该是对数级别地小于真实数据量。
数据累积而非替换
2024年4月的论文《Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data》提出了一个更直接的方法:累积数据而非替换。
传统递归训练的假设是每代数据替换上一代数据,但这不符合现实。真实情况是:新数据会与旧数据并存。论文证明,如果将各代生成的合成数据与原始真实数据累积保存,并在训练中使用全部数据,模型崩溃可以完全避免。
这个发现的直观解释是:原始真实数据始终存在于训练集中,为模型提供了对真实分布的"锚点",防止分布漂移到合成数据引入的偏差。实验表明,数据累积策略下,模型的验证损失保持稳定,而数据替换策略则导致损失持续上升。
质量与多样性的权衡
避免模型崩溃只是使用合成数据的第一步。更关键的挑战是:如何生成高质量的合成数据?
2024年10月发表在arXiv上的论文《On the Diversity of Synthetic Data and its Impact on Training Large Language Models》系统研究了这一问题。研究团队提出了LLM Cluster-Agent方法来量化合成数据的多样性,并通过控制实验揭示了质量与多样性之间的权衡关系。
多样性的重要性
合成数据的多样性直接影响模型的能力边界。如果生成的数据过于集中,模型将难以学习到分布的完整特征;如果过于分散,数据质量又可能下降。
研究发现,预训练阶段合成数据的多样性对下游任务的影响呈现非线性特征:低多样性时,模型性能随多样性增加而快速提升;但当多样性达到一定阈值后,边际收益递减。更重要的是,预训练阶段合成数据的多样性对微调阶段的影响比预训练本身更为显著。
质量控制策略
Google DeepMind在2024年发布的合成数据最佳实践报告总结了三个核心维度:
事实性(Factuality):合成数据中包含的信息是否准确。LLM生成的数据存在幻觉问题,可能包含虚假的事实陈述。解决方法包括使用检索增强生成(RAG)、事实核查过滤等。
保真度(Fidelity):合成数据是否真实反映目标分布的特征。这需要设计合理的评估指标和基准测试。
无偏性(Unbiasedness):合成数据是否引入或放大了偏见。由于生成模型会继承其训练数据的偏见,合成数据可能加剧这一问题。
实践案例:Cosmopedia与SmolLM
2024年,HuggingFace发布了Cosmopedia——当时最大的开源合成数据集,包含超过3000万份文档、250亿token。这个项目提供了合成数据工程的完整范例。
提示工程的核心地位
Cosmopedia的创建过程揭示了一个反直觉的事实:大规模生成合成数据的瓶颈不在于GPU算力,而在于提示工程。
团队需要设计超过3000万个不同的提示,以确保生成内容的多样性。他们采用了两种策略:
基于精选来源的提示:从斯坦福课程大纲、Khan Academy、OpenStax等教育平台提取主题,构建"教科书式"的生成提示。
基于网页数据的提示:将大规模网页数据进行聚类,识别出145个主题簇,为每个簇构建生成提示。
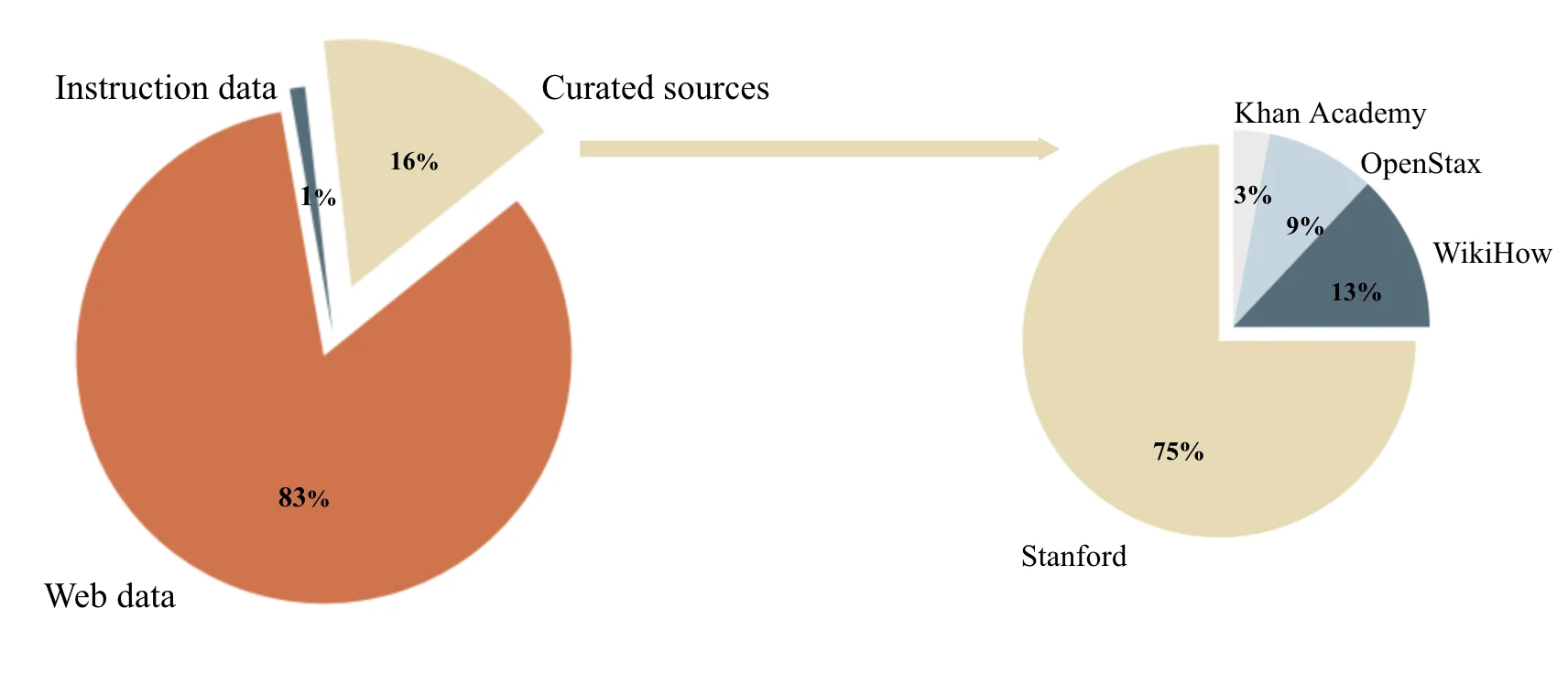
图中左侧展示了构建Cosmopedia提示的数据来源分布,右侧展示了精选来源类别内部的细分分布。网页数据贡献了超过80%的提示。
多样性与重复率的平衡
生成过程中的一个关键挑战是重复率控制。当提示设计不合理时,不同提示可能生成高度相似的内容,造成计算浪费和有效数据量虚高。
Cosmopedia通过三重策略解决这个问题:
- 主题差异化:确保不同提示覆盖不同的主题领域
- 受众差异化:针对同一主题,设计面向不同受众(儿童、中学生、大学生、研究人员)的提示
- 风格差异化:生成教科书、博客文章、WikiHow教程、故事等不同风格的内容

图中展示了针对同一主题(“为什么要去太空?")设计的三种不同提示:面向幼儿的教科书、面向专业人士和研究人员的教科书、面向高中生的教科书。这种受众差异化策略使同一主题可以生成12倍数量的独特提示。
最终,Cosmopedia实现了低于1%的重复率,远优于早期合成数据集的5-10%。
SmolLM:小模型的胜利
基于Cosmopedia训练的SmolLM系列模型验证了合成数据的有效性。1.7B参数的SmolLM在多个基准测试上超越了同样规模的模型,甚至在某些任务上接近了10倍参数量的模型。
SmolLM的训练数据混合策略值得借鉴:
- Cosmopedia v2:280亿token的合成教科书和故事
- Python-Edu:40亿token的教育性Python代码
- FineWeb-Edu:2200亿token的高质量教育网页数据
这个混合策略体现了合成数据的正确使用方式:作为高质量补充,而非真实数据的替代。
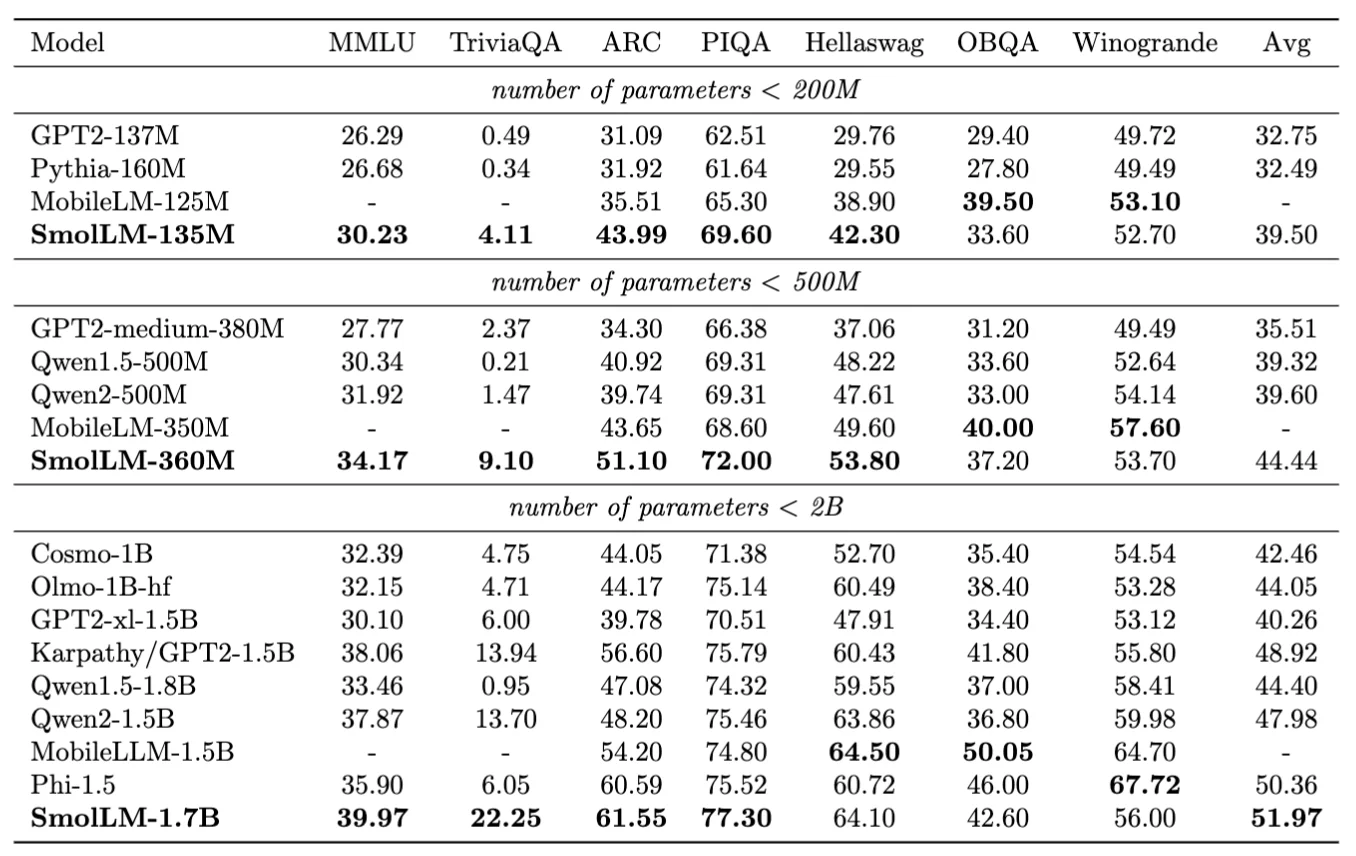
图中展示了SmolLM三个规模(135M、360M、1.7B参数)在多个推理和常识基准测试上的表现。SmolLM-1.7B在大多数基准上超越了同规模的其他模型,验证了高质量合成数据的有效性。
数据工程的新范式
合成数据的兴起正在重塑大模型训练的数据工程范式。从实践经验和学术研究中,可以总结出以下原则:
数据混合的黄金比例
当前研究表明,合成数据的占比应该严格控制。虽然具体比例因任务而异,但总体原则是:合成数据量应该显著少于真实数据量,尤其是在预训练阶段。
对于微调任务,合成数据的比例可以相对更高,但通常不应超过总数据量的30-40%。关键的数学约束是:合成数据量应该是对数级别地小于真实数据量,以确保分布偏差可控。
基准测试去污染
合成数据的一个潜在风险是基准测试污染:生成的数据可能无意中包含了测试集的内容。Cosmopedia项目实施了严格的去污染流程:使用10-gram重叠检测候选污染样本,然后使用序列匹配算法进行二次确认,移除重叠率超过50%的样本。
持续评估与迭代
合成数据的质量不能仅靠生成阶段的控制,还需要通过下游任务性能来验证。HuggingFace在开发Cosmopedia v2时,通过训练1.8B参数的测试模型,评估不同提示策略的效果,最终确定了最佳的受众分布(40%中学生、30%大学生、30%混合风格)。
未来展望
合成数据正在成为大模型训练不可或缺的组成部分,但其使用需要谨慎和科学的方法。几个值得关注的趋势:
更强大的生成模型:随着GPT-4级模型的开源化,合成数据的质量有望大幅提升。但这也带来新的问题:更强大的生成模型是否意味着更隐蔽的错误模式?
领域特定的合成数据:医疗、法律、金融等专业领域对合成数据的需求迫切,但也面临更严格的事实性要求。检索增强生成(RAG)技术可能成为解决方案。
合成数据的评估标准:目前缺乏统一的合成数据质量评估框架。建立类似ImageNet那样的标准化基准,对于推动领域发展至关重要。
法规与伦理:合成数据的使用涉及版权、隐私、透明度等法律问题。如何在技术创新与合规之间取得平衡,是整个行业需要共同面对的挑战。
回到文章开头的问题:用AI生成的数据训练AI,究竟是福是祸?答案取决于使用方式。盲目地让模型"吃自己生成的数据"确实会导致崩溃,但精心设计的合成数据工程可以让小模型拥有大智慧。关键在于理解数据的本质:它不是可以无限复制的比特流,而是承载着现实世界复杂性的人类知识结晶。合成数据的使命,不是替代这种复杂性,而是以一种可控的方式扩展它。
参考文献
- Gunasekar, S., et al. (2023). Textbooks Are All You Need. arXiv:2306.11644.
- Shumailov, I., et al. (2024). AI models collapse when trained on recursively generated data. Nature, 631, 755-763.
- Seddik, M. E. A., et al. (2024). How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse. arXiv:2404.05090.
- Gerstgrasser, M., et al. (2024). Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data. arXiv:2404.01413.
- Chen, H., et al. (2024). On the Diversity of Synthetic Data and its Impact on Training Large Language Models. arXiv:2410.15226.
- Liu, R., et al. (2024). Best Practices and Lessons Learned on Synthetic Data for Language Models. arXiv:2404.07503.
- Ben Allal, L., et al. (2024). Cosmopedia: how to create large-scale synthetic data for pre-training. HuggingFace Blog.
- Abdin, M., et al. (2024). Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219.