当混合专家模型(Mixture of Experts, MoE)首次在2017年被提出时,研究者的愿景很美好:用一组专门化的"专家"网络替代传统的全连接层,让每个输入只激活一小部分参数,从而在保持计算效率的同时大幅扩展模型容量。然而,当他们真正开始训练这些模型时,却发现了一个令人沮丧的现象——路由器总是倾向于选择相同的几个专家,而让其他专家完全闲置。
这不是一个简单的bug,而是MoE架构固有的结构性问题。从GShard到Switch Transformer,从Mixtral到DeepSeek,过去七年里,无数研究团队都在与这个问题博弈。要理解为什么MoE的路由训练如此困难,我们需要深入到数学原理、优化动力学以及分布式系统的工程约束中。
从一个简单的想法开始
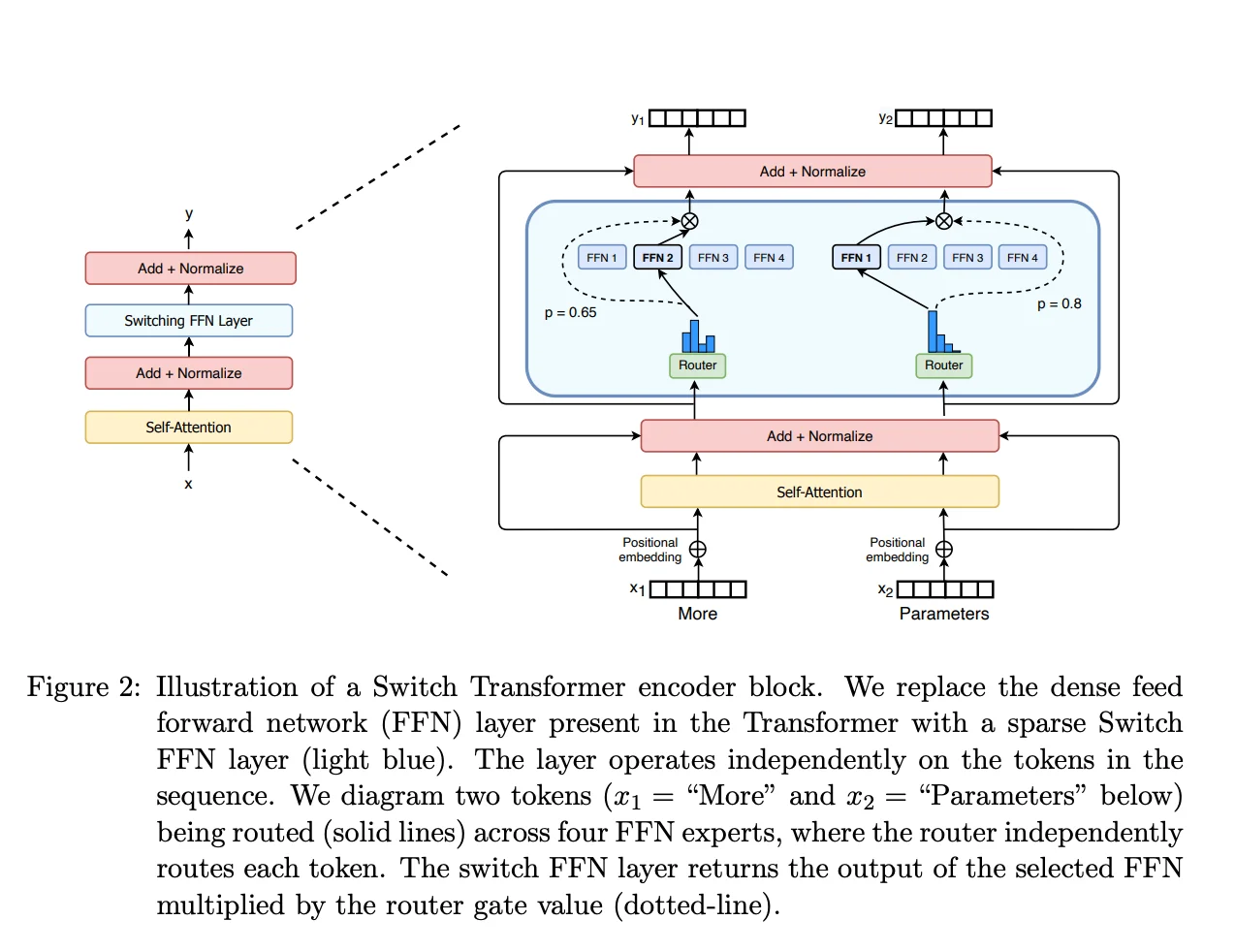
在标准的Transformer架构中,每个token都要通过一个全连接前馈网络(FFN)。这个FFN通常会将输入维度放大4倍,再压缩回原维度。当模型规模扩大时,这个简单的FFN会变得极其昂贵——参数量和计算量都呈线性增长。
MoE的核心想法是:与其让所有token都通过同一个巨大的FFN,不如创建多个较小的专家网络,让路由器为每个token选择最合适的专家。假设一个MoE层有8个专家,每个token只激活2个专家,那么理论上可以用接近8倍的总参数量,却只付出2倍的计算代价。
这个想法的数学表达非常简洁。给定输入token $x$,MoE层的输出为:
$$y = \sum_{i=1}^{N} G(x)_i E_i(x)$$其中 $G(x)$ 是路由器输出的概率分布,$E_i(x)$ 是第 $i$ 个专家的输出。如果是Top-K路由,只有概率最高的K个专家会被激活。
图片来源: HuggingFace MoE Blog
问题出在路由器 $G(x)$ 的训练上。路由器需要学会为每个token选择最合适的专家,但这个学习过程存在天然的失衡倾向。
Softmax的"马太效应"
路由器的核心组件是Softmax函数,它将原始的分数(logits)转换为概率分布:
$$G(x)_i = \frac{e^{H(x)_i}}{\sum_{j=1}^{N} e^{H(x)_j}}$$其中 $H(x)_i$ 是路由器对第 $i$ 个专家的原始评分。Softmax的设计初衷是让概率分布变得"尖锐"——差异越大,分布越集中在少数选项上。这个特性在分类任务中很有用,但在MoE路由中却成了灾难的根源。
假设在训练早期,某个专家 $E_3$ 因为初始化的偶然因素,在处理某些token时表现稍好。路由器会学到给 $E_3$ 分配更高的概率。这本身是合理的——路由器应该选择表现更好的专家。但问题是,更高的概率意味着 $E_3$ 会接收更多的训练数据,从而获得更多的梯度更新,变得更强。而那些被忽视的专家则缺乏训练信号,始终停留在初始状态。
这形成了一个自我强化的正反馈循环:表现好的专家变得更好,获得更多选择机会;表现差的专家没有机会改进,被进一步边缘化。在机器学习文献中,这种现象被称为"rich-get-richer dynamics"或"preferential attachment"。
更糟糕的是,Softmax的指数函数会放大这种差异。如果某个专家的logit比其他专家高1个单位,其在Softmax输出中的概率会增加约2.7倍(因为 $e^1 \approx 2.718$)。当logit差距扩大到10个单位时,概率差距会扩大到约22026倍。这种指数级的放大效应使得初始的小偏差迅速演变成决定性的差距。
专家坍缩:当模型自我阉割
当上述正反馈循环运行到极致,就会出现"专家坍缩"(Expert Collapse)——模型的几乎所有token都被路由到一两个专家,其他专家完全变成摆设。
专家坍缩带来的后果是多维度的:
参数浪费:一个8专家的MoE层,如果只有2个专家在工作,实际有效容量只相当于一个2专家模型,却要存储8个专家的参数。内存被白白浪费。
训练瓶颈:在分布式训练中,如果每个专家放在不同的设备上,负载不均会导致严重的"straggler问题"。处理热门专家的设备在忙碌工作,而处理冷门专家的设备大部分时间在等待。整个系统的吞吐量被最慢的那个节点拖累。
梯度质量问题:接收很少token的专家,其梯度估计会有很高的方差。标准的随机梯度下降依赖于大量样本的平均来获得准确的梯度方向。一个每批次只看到10个token的专家,其梯度噪声远大于一个看到1000个token的专家,优化变得不稳定。
专业化多样性丧失:当路由变得极度不均衡,热门专家被迫处理各种类型的token,变成"万金油"而非专家。冷门专家从未有机会发展出有意义的专业化。MoE架构的核心价值——通过专家分工实现知识解耦——被彻底破坏。
辅助损失:必要的恶?
面对专家坍缩,研究者的第一反应是添加一个"辅助损失"(Auxiliary Loss),强制路由器均匀分配token。这个想法最早出现在GShard论文中,后来被Switch Transformer进一步简化。
辅助损失的设计目标是让每个专家接收大致相同数量的token。具体来说,对于一批token,辅助损失计算每个专家的"重要性分数"(即该专家接收的平均路由概率)和"负载分数"(即该专家实际处理的token比例),然后惩罚这两个分数的变异系数:
$$L_{aux} = \alpha \cdot \frac{1}{N} \sum_{i=1}^{N} f_i \cdot P_i$$其中 $f_i$ 是路由到专家 $i$ 的token比例,$P_i$ 是专家 $i$ 的平均路由概率,$\alpha$ 是控制辅助损失权重的超参数。
这个方法有效,但代价沉重。辅助损失本质上是一个正则化项,它会引入与主任务目标(语言建模损失)相冲突的梯度。当 $\alpha$ 太小时,负载均衡无法保证;当 $\alpha$ 太大时,语言建模性能会被拖累。
DeepSeek团队在2024年的论文中精确地描述了这个困境:
“虽然辅助损失可以缓解训练过程中的负载不均衡,但它也引入了不必要的梯度,这些梯度与语言建模目标相冲突。这些干扰梯度会损害模型性能,因此现有的MoE方法始终需要在负载均衡和模型性能之间进行权衡。”
这种权衡在实践中表现为一种微妙的两难:你想让路由器均匀分配token,但又不想过度惩罚它做出"正确"的选择。如果一个token确实更应该由专家A处理,辅助损失却在说"你应该更多地考虑专家B",这就是在给模型灌输噪声。
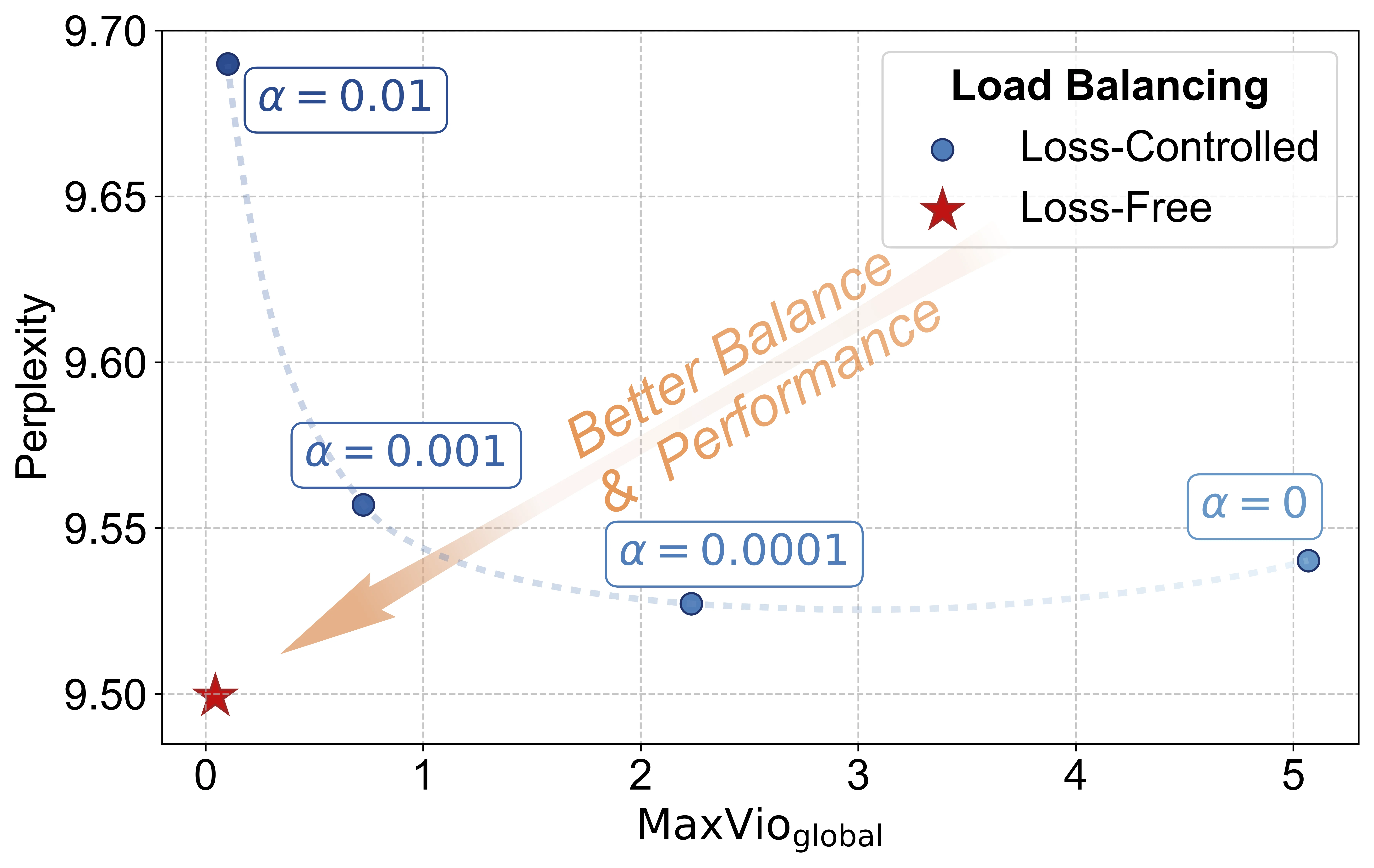
Loss-Free Balancing:打破两难
2024年,DeepSeek团队提出了一个突破性的方案:Loss-Free Balancing。核心想法非常简单——既然辅助损失的问题在于它引入了干扰梯度,那就干脆不用损失函数来控制均衡,而是用一个独立于梯度的机制直接调整路由分数。
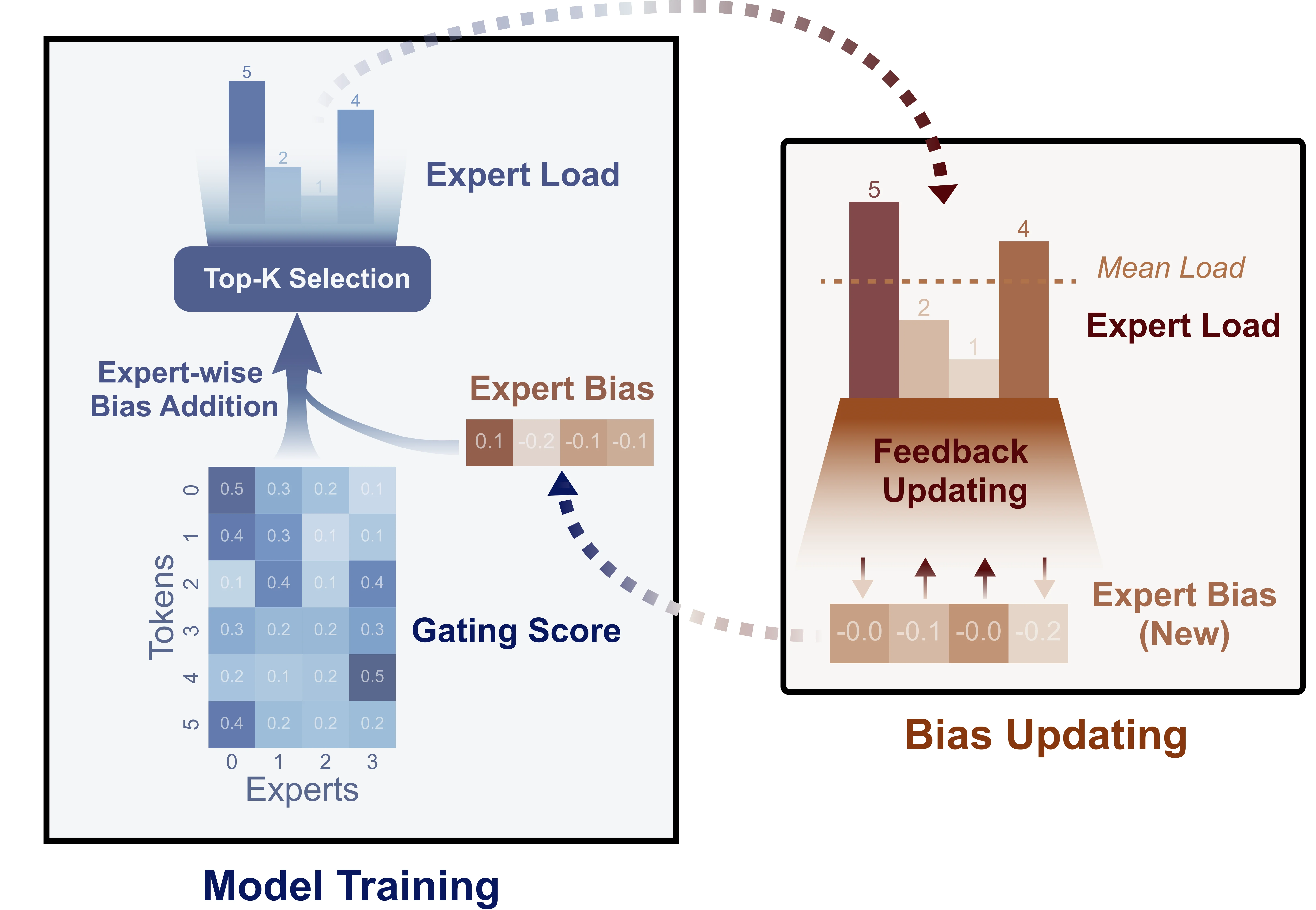
具体做法是:在路由器计算Top-K选择之前,为每个专家的路由分数添加一个动态偏置项:
$$G'(x)_i = G(x)_i + b_i$$其中 $b_i$ 是专家 $i$ 的偏置项。注意这个偏置只影响路由选择,不参与最终输出的加权计算。
偏置项的更新规则很直观:如果某个专家最近接收的token过多,就降低它的偏置(让它在竞争中不那么容易被选中);如果某个专家太清闲,就提高它的偏置(给它更多机会)。关键在于,这个更新过程完全在梯度计算之外进行,不会对主任务产生任何干扰。
实验结果令人印象深刻。在1B参数、100B token的训练规模上,Loss-Free Balancing相比传统的辅助损失方法,不仅获得了更好的负载均衡(最大违反度从0.72降到0.04),还实现了更低的验证困惑度(9.50 vs 9.56)。这打破了长期以来"负载均衡与模型性能不可兼得"的信条。
更重要的是,Loss-Free Balancing天然兼容专家并行训练。在分布式设置中,随着计算批次的增大,其负载均衡优势会更加明显。这对于训练超大规模MoE模型至关重要。
细粒度专家分割:让专家更加专注
另一个重要的架构创新来自DeepSeekMoE。传统MoE架构中,每个专家是一个完整的FFN,粒度较粗。DeepSeekMoE提出了两个改进:
细粒度专家分割:将每个专家进一步切分成更小的单元。假设原本有8个专家,每个专家有 $d$ 个隐藏单元;现在可以分割成64个小专家,每个专家只有 $d/8$ 个隐藏单元。这样做的好处是,路由器可以在更细的粒度上组合专家,实现更灵活的知识表示。
共享专家隔离:设置一部分专家为"共享专家",所有token都必须通过它们。这些共享专家负责学习通用知识,避免不同专家重复学习相同的内容。
$$y = \sum_{i=1}^{K_s} G^{(s)}(x)_i E_i^{(s)}(x) + \sum_{i=1}^{K_r} G^{(r)}(x)_i E_i^{(r)}(x)$$其中上标 $(s)$ 表示共享专家,$(r)$ 表示路由专家。
这种设计的动机是:在传统MoE中,不同专家可能会学习到相似的知识(比如多个专家都学会了处理标点符号),造成参数冗余。通过共享专家机制,可以让路由专家专注于独特的、差异化的知识,最大化参数效率。
Router Z-Loss:驯服指数爆炸
除了负载均衡问题,MoE训练还面临另一个隐蔽的威胁:路由器logit的数值爆炸。
在训练过程中,路由器的logit $H(x)$ 可能会变得非常大。当logit值超过约88时,float32精度的 $e^x$ 就会溢出变成无穷大。即使使用标准的"减去最大值"技巧来避免Softmax计算溢出,极大的logit仍然会带来严重的数值问题:
- 梯度消失:当概率分布变得极其尖锐(比如一个专家的概率是0.9999,其他专家加起来只有0.0001),梯度会变得极小,路由器无法学习新的路由策略。
- 精度损失:当logit跨越巨大的数值范围时,浮点运算会丢失有效数字,引入累积误差。
- 训练崩溃:极端情况下,梯度可能变成NaN,整个训练过程需要从检查点恢复。
ST-MoE论文提出了Router Z-Loss来约束logit的规模:
$$L_z = \frac{1}{B} \sum_{i=1}^{B} \left(\log \sum_{j=1}^{N} e^{H(x_i)_j}\right)^2$$这个损失惩罚log-sum-exp值(即logits的"有效规模"),鼓励路由器保持适度的logit值。与辅助损失不同,Z-Loss不关心哪个专家被选中,只关心logit的绝对大小。两者通常结合使用。
实验表明,Router Z-Loss对训练稳定性至关重要,尤其是在大规模模型上。Google团队发现,没有Z-Loss的大型MoE模型经常出现训练不稳定,而小型模型则较少遇到这个问题——这是一种"规模敏感性"的体现。
Expert Choice Routing:反转控制权
另一种激进的解决方案是Expert Choice Routing(EC),由Google在2022年提出。传统的"Token Choice"路由让每个token选择Top-K专家,而EC让每个专家主动选择Top-K token。

EC的优势是天然的完美负载均衡——每个专家恰好处理预定数量的token,不存在热门专家过载或冷门专家闲置的问题。实验表明,EC在训练效率上比传统的Token Choice快2倍以上。
然而,EC有一个致命缺陷:它违反了自回归语言模型的因果约束。在EC中,一个token被路由到哪个专家,取决于整个batch中所有token的情况——包括"未来"的token。这意味着在预测第 $t$ 个token时,模型已经"看到"了第 $t+1, t+2, ...$ 的信息。这会导致信息泄露,破坏模型的泛化能力。
DeepSeek团队在论文中量化了这种泄露的严重程度:对于一个稀疏比为 $r$(平均激活专家数/总专家数)的MoE层,EC最多可以泄露 $\log_2 \binom{N}{Kr}$ 比特的信息每token。一个9层、16专家、平均激活2专家的MoE,总共可以泄露超过50比特的信息——足够让每个token确定其后继token的身份。
因此,虽然EC在训练效率上表现出色,但它不适用于需要因果预测的语言模型。这提示我们:负载均衡不是唯一需要考虑的因素,模型的整体设计约束同样重要。
Token Dropping:被迫的取舍
当路由器真的无法均匀分配token时,系统会怎么做?答案是"丢弃"多余的token。
每个专家都有一个预设的"容量"(Capacity),表示它最多能处理多少token。容量由一个容量因子(Capacity Factor)控制:
$$\text{Expert Capacity} = \left\lfloor \frac{\text{tokens per batch}}{\text{number of experts}} \times \text{capacity factor} \right\rfloor$$当路由到某个专家的token超过其容量时,多余的token会被丢弃——它们不经过该专家的处理,直接通过残差连接传递到下一层。
Token Dropping是一种"硬约束":它强制保证每个专家的工作量有上限,但代价是某些token得不到充分的专家处理。容量因子是一个关键的权衡参数:
- 容量因子太小(如1.0):严格的容量限制,大量token被丢弃,模型性能下降。
- 容量因子太大(如2.0):宽松的容量限制,token很少被丢弃,但每个专家的缓冲区变大,计算和通信开销增加。
Switch Transformer的实验表明,较低的容量因子(1.0-1.25)在大多数情况下表现良好,token丢弃率控制在可接受范围内。但这是一个经验结论,实际的最佳值取决于数据分布、专家数量和训练规模。
分布式训练中的负载均衡挑战
MoE的负载均衡问题在分布式训练中变得更加复杂。在"专家并行"(Expert Parallelism)设置下,不同的专家分布在不同的设备上。每个训练步骤需要以下流程:
- 每个设备处理自己那份数据,计算每个token应该路由到哪个专家
- 通过All-to-All通信,将token发送到目标专家所在的设备
- 每个设备处理自己负责的专家的输入
- 通过另一个All-to-All通信,将结果返回原设备
- 合并结果,计算梯度,同步参数
这个流程中,All-to-All通信是最昂贵的操作。如果负载不均衡,通信时间会被最慢的设备拖累。更糟糕的是,All-to-All的延迟与最大负载成正比,而不是平均负载。
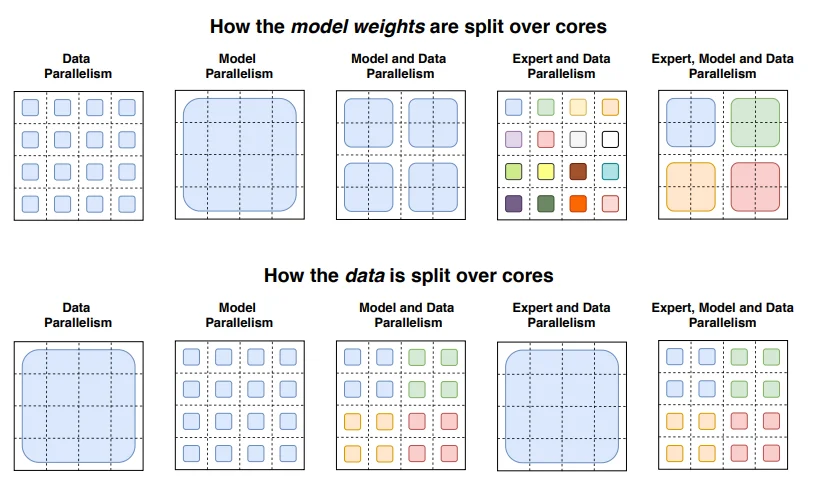
图片来源: HuggingFace MoE Blog
Loss-Free Balancing在这里展现了另一个优势:它可以实现近乎完美的全局负载均衡,而且随着计算批次增大(这正是专家并行带来的效果),均衡性会进一步提高。这为超大规模MoE训练扫清了一个重要的障碍。
实践中的权衡与建议
综合上述分析,MoE路由训练的核心挑战可以归纳为:如何在保证负载均衡的同时,不损害路由器的决策质量和模型的整体性能。
对于预训练阶段,推荐以下策略:
- 使用Loss-Free Balancing替代或补充传统的辅助损失。DeepSeek-V3已验证了这一方法在大规模训练中的有效性。
- 添加Router Z-Loss以稳定训练,系数建议从 $10^{-3}$ 开始调试。
- 设置适度的容量因子(1.25左右),在token丢弃和计算效率之间取得平衡。
- 监控关键指标:最大违反度(MaxVio)、路由熵、Z-Loss值、token丢弃率。
对于微调阶段,情况有所不同:
- 稀疏模型更容易过拟合,可以考虑更高的dropout率。
- 辅助损失在微调时可能不需要,或者使用更小的系数。
- 小批量、高学习率往往比标准的微调超参数更有效。
- 指令微调对MoE尤其有效,收益可能超过同等规模的稠密模型。
对于推理部署:
- 所有专家参数都需要加载到内存,即使每次只激活一小部分。这要求足够的VRAM。
- 在低延迟场景下,MoE的推理速度优势明显;在高吞吐场景下,需要精心设计批处理策略。
- 模型压缩(如量化、蒸馏)可以缓解内存压力,但需要针对MoE的特殊结构进行调整。
尚未解决的问题
尽管取得了长足进步,MoE路由训练仍有一些开放问题:
专家专业化的本质:实验表明,decoder-only MoE的专家并没有形成清晰的领域专门化(如"代码专家"、“数学专家”),而是在更细粒度的语法特征上表现出选择性。这种"弱专门化"是否是MoE的固有特性,还是可以通过训练策略改进?
超大规模专家的可行性:当专家数量扩展到成百上千时,路由器的搜索空间急剧扩大,训练是否还能保持稳定?Switch Transformer展示了2048专家的可行性,但更大规模的探索还很有限。
多模态MoE的挑战:当输入包含文本、图像、音频等多种模态时,如何设计路由机制?不同模态的数据分布差异很大,统一的负载均衡策略可能不再适用。
推理时计算扩展:近期的研究表明,增加推理时的计算量(如思维链、搜索)可以提升模型性能。MoE的稀疏激活特性如何与这种范式结合,是一个有趣的探索方向。
结语
MoE路由训练的困难,本质上是条件计算与全局优化之间的张力。让每个token独立选择专家,最大化了局部效率,却可能导致全局失衡。辅助损失试图用全局约束来纠正这种失衡,但又引入了梯度干扰。Loss-Free Balancing通过解耦机制打破了这个死循环,但这是否是最优解,还有待验证。
从更广阔的视角看,MoE的成功与困境,反映了深度学习领域的一个核心主题:如何在模型规模、计算效率、训练稳定性之间找到平衡。没有免费的午餐,每一种优化都伴随着代价。理解这些代价的本质,才能在实践中做出明智的权衡。
参考文献
- Shazeer, N., et al. “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.” arXiv:1701.06538, 2017.
- Lepikhin, D., et al. “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.” arXiv:2006.16668, 2020.
- Fedus, W., et al. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” JMLR 23(120), 2021.
- Zhou, Y., et al. “Mixture-of-Experts with Expert Choice Routing.” NeurIPS 2022.
- Zoph, B., et al. “ST-MoE: Designing Stable and Transferable Sparse Expert Models.” arXiv:2202.08906, 2022.
- Dai, D., et al. “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models.” ACL 2024.
- DeepSeek-AI. “Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts.” arXiv:2408.15664, 2024.
- Jiang, A.Q., et al. “Mixtral of Experts.” arXiv:2401.04088, 2024.
- Riquelme, C., et al. “Scaling Vision with Sparse Mixture of Experts.” NeurIPS 2021.