2023年10月,一篇名为 FP8-LM 的论文在 arXiv 上发布,研究团队用8位浮点数完成了 GPT-175B 的训练——内存占用减少39%,训练速度提升75%。这并非孤例,QLoRA 更是将模型压缩到4位,却依然保持着与16位训练相当的微调效果。这些数字背后的数学原理,揭示了深度学习一个反直觉的特性:神经网络对数值精度的要求,远比我们想象的要低。
从浮点表示到量化映射
要理解量化训练为何可行,首先需要弄清楚"精度损失"到底意味着什么。
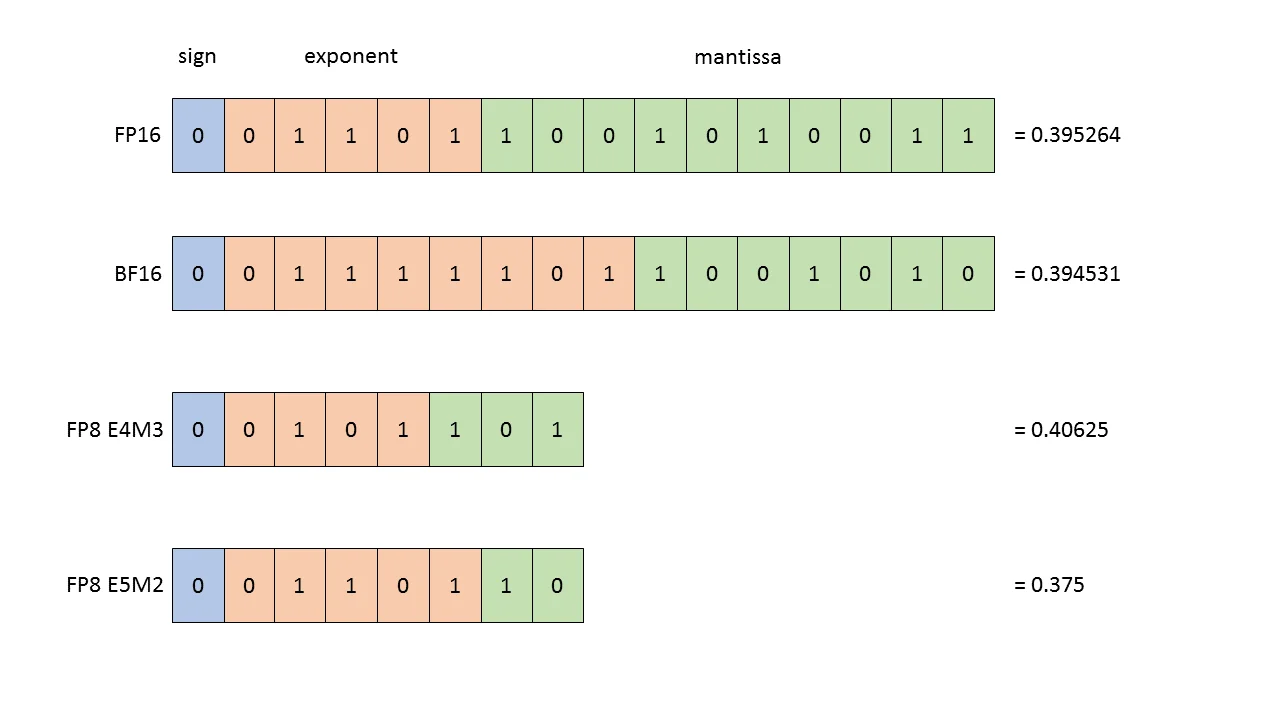
神经网络中的数值通常以32位浮点数(FP32)存储。FP32 采用 IEEE 754 标准,由1位符号位、8位指数位和23位尾数位组成,能表示的范围约为 $\pm 3.4 \times 10^{38}$,精度约为7位有效数字。这个精度对于科学计算是必要的,但对于神经网络——一个充满噪声和随机性的系统——真的需要这么多吗?
量化将连续的浮点值映射到离散的整数网格。对于均匀量化,核心公式为:
$$\bar{x} = s \cdot \left[\text{clamp}\left(\left\lfloor \frac{x}{s} \right\rceil + z, 0, 2^b - 1\right) - z\right]$$其中 $s$ 是缩放因子,$z$ 是零点偏移,$b$ 是量化位数,$\lfloor \cdot \rceil$ 表示四舍五入。这个看似简单的映射,引入了两类误差:
截断误差:当原始值超出量化范围时被强制裁剪到边界。缩放因子 $s$ 越大,可表示的范围越宽,截断误差越小。
舍入误差:将浮点值映射到最近的量化网格点。缩放因子 $s$ 越小,网格越密集,舍入误差越小。舍入误差的范围是 $[-\frac{s}{2}, \frac{s}{2}]$。
这是一个经典的权衡问题:一个缩放因子无法同时最小化两种误差。而在神经网络中,不同张量的数值分布差异巨大——权重通常呈高斯分布,梯度则呈现重尾分布,激活值可能是非负的单峰分布。统一处理必然顾此失彼。
神经网络为何能容忍量化噪声
量化引入的噪声理论上应该干扰梯度下降的收敛,但实践中神经网络表现出了惊人的鲁棒性。这种鲁棒性的来源有三个层面。
过参数化带来的冗余
现代神经网络高度过参数化。一个有数十亿参数的模型,其有效维度远小于参数数量——损失函数的Hessian矩阵拥有大量接近零的特征值,意味着优化空间中存在无数等价的平坦区域。在这种"冗余参数空间"中,微小的扰动不会根本性地改变模型的优化轨迹。
数学上,设参数 $\theta$ 的扰动为 $\Delta\theta$,则损失函数的变化为:
$$\Delta L \approx \nabla L \cdot \Delta\theta + \frac{1}{2}\Delta\theta^T H \Delta\theta$$当Hessian矩阵 $H$ 的特征值集中在零附近时,即使 $\Delta\theta$ 较大,二阶项的贡献也微乎其微。过参数化网络本质上在这个方向上是"钝感"的。
训练本身就是噪声过程
梯度下降不是纯粹的数学优化。随机梯度下降(SGD)本身就引入了噪声——每个mini-batch的梯度只是真实梯度的一个有偏估计。量化的舍入误差不过是又一种噪声源,而且这种噪声的量级往往小于mini-batch采样带来的方差。
研究表明,适当噪声反而有助于泛化。在平坦的极小值附近,噪声帮助优化器"逃离"尖锐区域,最终收敛到更平坦、泛化性更好的解。量化噪声在某种程度上起到了正则化的作用。
权重的数值分布特性
训练收敛后的神经网络权重通常呈现零均值的高斯分布,且方差较小。这种分布对于量化非常友好:大部分值集中在零附近,不需要极端的动态范围。4位量化可以覆盖 $[-7, 7]$ 的范围,对于典型初始化和训练后的权重已经足够。
真正棘手的是激活值和梯度。激活值经过ReLU等非线性函数后变成非负分布,而梯度由于链式法则的乘法性质,经常出现极端的离群值。这也是为什么量化训练需要特殊处理这些张量的原因。
直通估计器:让梯度穿过不可微的函数
量化函数 $\lfloor \cdot \rceil$ 在整数边界处导数未定义,在其他位置导数为零。反向传播似乎无从下手。
直通估计器(Straight-Through Estimator, STE)是解决这一困境的关键技巧。其核心思想极其简单:在前向传播时执行真实的量化操作,在反向传播时假装量化函数是恒等映射:
$$\frac{\partial \bar{x}}{\partial x} \approx 1$$这当然不是真实的梯度,但它提供了一个"足够好"的信号,让优化器能够沿着正确的方向更新参数。STE 的有效性可以从两个角度理解:
-
局部近似:在训练的大部分时间里,参数的更新幅度很小。如果 $x$ 从一个量化网格点移动到相邻点需要 $\Delta x = s$ 的变化,那么单次更新的梯度通常远小于这个值。在"网格点之间"的微观尺度上,量化函数确实近似于恒等。
-
梯度方向正确:虽然STE低估了梯度的幅度,但方向是正确的。梯度下降最终关心的是"往哪个方向走",而不是"走多远"。学习率的调整可以补偿幅度的偏差。
更精细的方法是让量化参数本身变成可学习的。Learned Step Size Quantization(LSQ)将缩放因子 $s$ 视为可训练参数,通过梯度下降自动寻找截断误差和舍入误差的最佳平衡点。其梯度公式为:
$$\frac{\partial \bar{x}_i}{\partial s} = \begin{cases} -\frac{x_i}{s} + \lfloor \frac{x_i}{s} \rceil & \text{if } q_{\min} \leq x_i \leq q_{\max} \\ n & \text{if } x_i < q_{\min} \\ p & \text{if } x_i > q_{\max} \end{cases}$$这种方法在4位量化场景下显著提升了精度。
FP8格式:精度与动态范围的精妙分工
FP8 的设计体现了对神经网络训练过程的深刻理解。它定义了两种格式:
E4M3:1位符号 + 4位指数 + 3位尾数,最大值约 $\pm 448$。更高的尾数位意味着更好的精度,适合存储权重和前向激活值。
E5M2:1位符号 + 5位指数 + 2位尾数,最大值约 $\pm 57344$。更大的指数范围能处理更极端的数值,适合存储梯度。
为什么梯度需要更大的动态范围?考虑链式法则,梯度是各层雅可比矩阵的乘积。如果某一层的雅可比矩阵特征值分布不均,乘积的结果会出现极端的数值。深层网络中的梯度可能跨越多个数量级,E4M3 的范围远远不够。
NVIDIA H100 的 Transformer Engine 采用了"混合格式"策略:前向传播使用 E4M3,反向传播使用 E5M2。这种不对称设计专门针对前向和反向的不同需求。
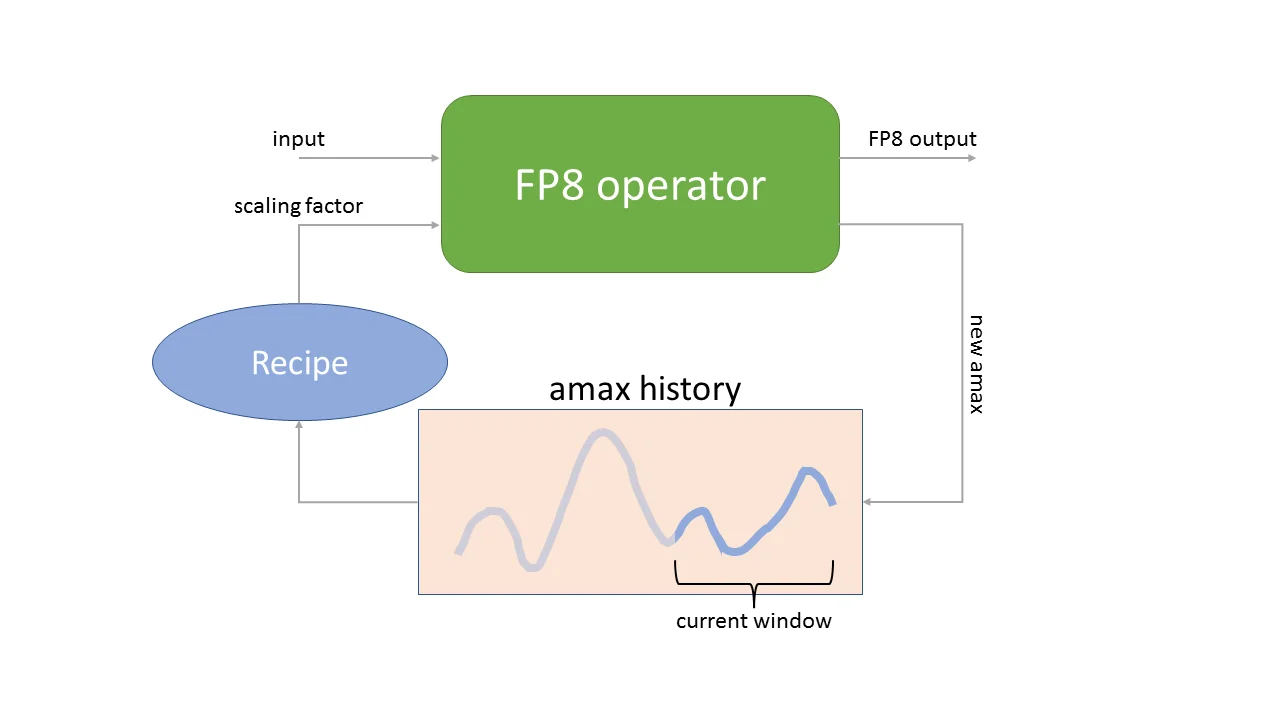
但单一缩放因子无法让FP8适配所有张量。FP8采用了"延迟缩放"策略:为每个FP8张量维护一个独立的缩放因子,该因子基于最近若干次迭代中该张量的最大绝对值计算。这种方法避免了实时计算缩放因子的开销,代价是需要额外的存储空间记录历史数据。
量化感知训练:让模型学会适应低精度
量化感知训练(Quantization-Aware Training, QAT)的思想是:在训练过程中就模拟量化效果,让模型"适应"低精度表示。这比训练后再量化(Post-Training Quantization, PTQ)更能在低位宽下保持精度。
QAT在计算图中插入"伪量化"节点:前向传播时执行量化操作,反向传播时使用STE传递梯度。整个训练过程在浮点精度下进行,但模型学到的参数对量化后的推理友好。
QAT的关键技术细节:
批量归一化折叠:批量归一化层在推理时会被合并到前一个卷积或线性层的权重中。如果在QAT时忽略这一点,训练和推理的量化噪声分布会不一致。静态折叠——将BN参数预先合并到权重中——是一种简单有效的处理方式。
跨层均衡:相邻层之间的权重可以通过等价变换来重新分配数值范围。例如,如果某层的权重方差远大于下一层,可以通过缩放来平衡两层的量化难度。这需要利用ReLU等激活函数的齐次性:$f(sx) = s \cdot f(x)$。
AdaRound:传统的舍入方法是"舍入到最近",但这并不总是最优的。AdaRound通过优化目标函数来选择舍入方向:
$$\arg\min_V \|f_a(Wx) - f_a(\hat{W}\hat{x})\|_F^2 + \lambda f_{\text{reg}}(V)$$其中 $f_a$ 是激活函数,正则项鼓励优化变量收敛到0或1(对应向下或向上舍入)。这种方法在4位量化下能带来显著的精度提升。
QLoRA:4位微调的信息论最优解
QLoRA将量化训练推向了4位的极致。其核心创新是 NormalFloat4(NF4)数据类型。
传统的量化假设数值均匀分布,但神经网络权重实际上服从高斯分布。对于 $k$ 位量化,信息论最优的量化网格应该让每个量化区间包含相同概率质量的输入值。这意味着在概率密度高的区域(权重分布的中心),网格应该更密集;在密度低的区域(分布的尾部),网格可以更稀疏。
NF4的构建过程:
- 将标准正态分布分成 $2^k$ 个等概率区间
- 每个区间的代表值取该区间内分布的期望值
- 这些代表值构成量化码本
对于来自 $\mathcal{N}(\mu, \sigma^2)$ 的权重,只需先标准化到 $\mathcal{N}(0, 1)$,然后应用NF4码本,再用 $\mu$ 和 $\sigma$ 反标准化即可。
QLoRA还引入了"双重量化":量化常数本身也被量化。存储一个FP16的缩放因子需要16位,但如果有256个这样的缩放因子,平均每个参数的分摊开销就是 $\frac{16}{256} = 0.0625$ 位。通过再次量化这些常数,可以进一步压缩到平均每参数0.127位的额外开销。
混合精度训练的损失缩放
FP16的动态范围远小于FP32,梯度容易出现数值下溢。损失缩放是解决这一问题的标准方法:
$$\text{scaled\_loss} = \text{loss} \times \text{scale\_factor}$$缩放因子必须是2的幂次(只改变指数位,不改变尾数),这样缩放后的梯度可以直接用于参数更新,最后再除回去。关键是选择合适的缩放因子:太小无法避免下溢,太大可能导致上溢。
动态损失缩放在训练过程中自动调整缩放因子:如果检测到梯度出现NaN或Inf,说明当前因子过大,将其减半;如果连续若干步没有出现数值问题,尝试将因子翻倍。这种自适应策略使得FP16训练的稳定性接近FP32。
BF16(Brain Float16)提供了另一种思路:它牺牲尾数精度换取更大的动态范围。BF16有8位指数(与FP32相同),但只有7位尾数。这意味着它可以存储与FP32相同范围的数值,但精度降低到约3位有效数字。对于梯度——更需要动态范围而非精度——BF16比FP16更合适。
NVFP4:4位训练的前沿探索
NVIDIA Blackwell架构引入了NVFP4格式,将训练推向更低的精度。NVFP4采用 E2M1 格式(1位符号 + 2位指数 + 1位尾数),最大值仅约 $\pm 6$。
为了在如此有限的范围内工作,NVFP4采用了块级缩放:每16个元素共享一个FP8(E4M3)缩放因子,外加一个全局FP32缩放因子防止溢出。这种细粒度的缩放大幅降低了每个元素所需的动态范围。
NVFP4训练还引入了随机舍入:以概率将值舍入到相邻的两个量化点,概率与距离成反比。这在期望意义上是无偏的,避免了确定性舍入引入的系统性偏差。
另一个关键技术是随机Hadamard变换:在权重梯度计算前对激活和梯度应用正交变换,使数值分布更接近高斯分布,减少极端离群值的影响。
量化训练的代价与权衡
量化训练不是免费的午餐。降低精度带来的收益和代价需要仔细权衡。
收益:
- 内存带宽需求降低,内存容量压力减小
- 计算吞吐提升(INT8/FP8 Tensor Core 的峰值算力远高于FP32)
- 功耗降低
- 通信开销减少(分布式训练中的梯度同步)
代价:
- 需要额外的工程实现(缩放因子管理、数值稳定性监控)
- 可能需要调整超参数(学习率、初始化)
- 极低位宽(<4位)下精度下降明显
- 某些操作(如LayerNorm、Softmax)仍需高精度
一个重要的认知是:量化训练不是一个"开关",而是一个"旋钮"。不同层、不同张量对精度的敏感度不同。LLM中的最后几层、归一化层、注意力分数通常需要更高的精度。现代量化框架允许逐层、逐张量地配置精度,在性能和精度之间找到最佳平衡。
数学视角的总结
量化训练能够成功的数学本质在于:神经网络的损失景观是高度冗余和平坦的。在这种景观上,优化路径有一定的"容错空间"——轻微的噪声和偏差不会从根本上改变收敛终点。
从信息论角度看,神经网络中的数值通常包含大量冗余信息。权重的有效信息内容远低于其存储位数所暗示的理论上限。量化本质上是一种有损压缩,它去除了冗余,保留了真正影响模型行为的"信号"。
从优化理论角度看,量化可以被视为一种特殊的正则化。它限制了参数空间的有效维度,某种程度上防止了过拟合。过参数化模型的泛化能力,部分源于这种隐式的约束。
当我们将视野从"如何精确表示数值"转向"如何保留有效信息",量化的必要性就不再是一个需要证明的命题,而是一个几乎必然的设计选择。在计算资源受限的现实约束下,用最少的比特承载最多的有效信息,是工程与数学的最优解。
参考文献
- Nagel, M., et al. “A White Paper on Neural Network Quantization.” arXiv:2106.08295, 2021.
- Wu, K., et al. “FP8-LM: Training FP8 Large Language Models.” arXiv:2310.18313, 2023.
- Dettmers, T., et al. “QLoRA: Efficient Finetuning of Quantized LLMs.” NeurIPS 2023.
- Esser, S. K., et al. “Learned Step Size Quantization.” ICLR 2020.
- NVIDIA Transformer Engine Documentation: FP8 Primer.
- Micikevicius, P., et al. “Mixed Precision Training.” ICLR 2018.
- Banner, R., et al. “Post training 4-bit quantization of convolution networks for rapid-deployment.” NeurIPS 2019.
- Nagel, M., et al. “Up or Down? Adaptive Rounding for Post-Training Quantization.” ICML 2020.