2022年8月,一个名为Stable Diffusion的图像生成模型悄然开源发布。短短几个月内,它席卷了整个互联网——从设计师的工作流到普通用户的社交媒体,AI绘画不再是科技公司的专利,而是人人触手可及的工具。这场革命的核心,是一项被称为"扩散模型"的技术。
扩散模型的灵感源自非平衡热力学。2015年,Jascha Sohl-Dickstein等人在ICML上发表了一篇开创性论文,提出了用扩散过程构建生成模型的设想。但这个想法在当时并未引起轰动,因为其实现效果远不如同期崛起的生成对抗网络(GAN)。直到2020年6月,加州大学伯克利分校的Jonathan Ho等人发表了DDPM(Denoising Diffusion Probabilistic Models),人们才真正意识到扩散模型的潜力。两年后,扩散模型彻底取代GAN,成为图像生成领域的主流范式。
扩散模型的核心思想出奇地简单:如果我们可以把一张图片逐步加噪变成纯噪声,那么反过来,只要学会如何"去噪",就能从噪声中生成任意图片。但这个"学会去噪"的过程,背后隐藏着精妙的数学设计。
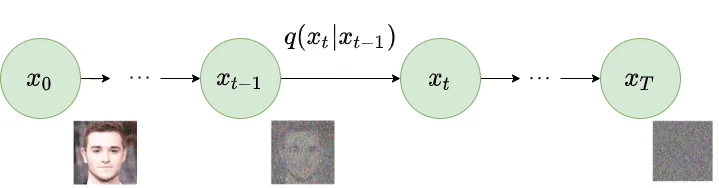
从图片到噪声:前向扩散过程
前向扩散过程是一个固定的、无需学习的马尔可夫链。给定一张原始图片$x_0$,我们通过$T$个时间步(通常$T=1000$)逐步向其添加高斯噪声,最终得到一个近乎纯噪声的$x_T$。
在每个时间步$t$,我们根据以下公式添加噪声:
$$q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t \mathbf{I})$$其中$\beta_t$是一个预先定义的噪声调度参数,控制每个时间步添加噪声的强度。DDPM原始论文采用线性调度,从$\beta_1 = 10^{-4}$线性增长到$\beta_T = 0.02$。
这里的关键洞察是:通过数学变换,我们可以直接从$x_0$跳到任意时间步$x_t$,而不需要逐步迭代。定义$\alpha_t = 1 - \beta_t$,以及$\bar{\alpha}_t = \prod_{i=1}^{t} \alpha_i$,则有:
$$q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1-\bar{\alpha}_t) \mathbf{I})$$这意味着:
$$x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1-\bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I})$$这个公式被称为"重参数化技巧"的产物,它揭示了一个关键事实:前向扩散过程可以用一个简单的线性变换来描述——原始信号$x_0$按系数$\sqrt{\bar{\alpha}_t}$衰减,同时加入标准差为$\sqrt{1-\bar{\alpha}_t}$的高斯噪声。随着$t$增大,$\bar{\alpha}_t$趋近于0,$x_t$趋近于纯噪声。
图片来源: AI Summer
噪声调度的选择对模型性能有显著影响。2021年,OpenAI的研究发现线性调度存在一个问题:在扩散过程的早期($t$较小时),图像变化过于剧烈,导致模型难以学习细微的图像特征。他们提出了余弦调度:
$$\bar{\alpha}_t = \frac{f(t)}{f(0)}, \quad f(t) = \cos\left(\frac{t/T + s}{1+s} \cdot \frac{\pi}{2}\right)^2$$其中$s$是一个小的偏移量(通常取0.008),用于防止$t=0$时的数值问题。余弦调度让图像在扩散早期保持更多的原始信息,在后期加速噪声化,这种设计被后续几乎所有扩散模型采用。
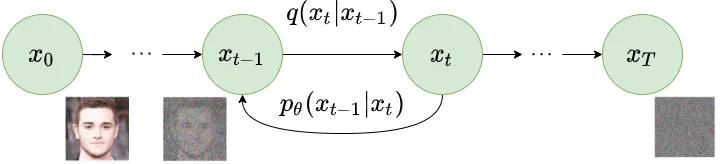
从噪声到图片:逆向去噪过程
前向扩散是"破坏"过程,逆向去噪才是"创造"过程。问题是:如何从$x_t$恢复到$x_{t-1}$?
理论上,逆向分布$q(x_{t-1} | x_t)$是不可直接计算的,因为它需要对整个数据分布进行积分。但有一个关键发现:如果扩散步足够小(即$\beta_t$足够小),逆向分布也近似为高斯分布。
更妙的是,如果额外条件于原始数据$x_0$,逆向分布就变得可解析计算:
$$q(x_{t-1} | x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t \mathbf{I})$$其中:
$$\tilde{\mu}_t(x_t, x_0) = \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1-\bar{\alpha}_t} x_0 + \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t} x_t$$$$\tilde{\beta}_t = \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} \beta_t$$这个公式的直觉是:如果知道$x_0$,我们可以精确地逆向一步。但生成时我们不知道$x_0$——这正是神经网络要学习的。
用参数化模型$p_\theta$来近似逆向分布:
$$p_\theta(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))$$网络以当前噪声图像$x_t$和时间步$t$为输入,预测逆向分布的均值$\mu_\theta$和协方差$\Sigma_\theta$。
图片来源: AI Summer
训练目标:从ELBO到简化损失
扩散模型的训练目标源于变分推断。我们要最大化数据的对数似然$\log p_\theta(x_0)$,这可以通过最大化证据下界(ELBO)来实现:
$$\log p_\theta(x_0) \geq \mathbb{E}_q\left[\log \frac{p_\theta(x_{0:T})}{q(x_{1:T}|x_0)}\right]$$经过一系列推导,ELBO可以分解为:
$$\mathcal{L} = \mathbb{E}_q\left[\underbrace{D_{KL}(q(x_T|x_0) \| p(x_T))}_{\mathcal{L}_T} + \sum_{t=2}^{T} \underbrace{D_{KL}(q(x_{t-1}|x_t,x_0) \| p_\theta(x_{t-1}|x_t))}_{\mathcal{L}_{t-1}} \underbrace{-\log p_\theta(x_0|x_1)}_{\mathcal{L}_0}\right]$$其中$\mathcal{L}_T$是先验匹配项(无训练参数),$\mathcal{L}_0$是重建项,而$\mathcal{L}_{t-1}$是去噪匹配项——这是训练的核心。
关键洞察来了:结合前向扩散公式$x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1-\bar{\alpha}_t} \epsilon$,我们可以将逆向分布的均值改写为:
$$\tilde{\mu}_t(x_t, x_0) = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon\right)$$这意味着,如果能预测噪声$\epsilon$,就能计算均值$\tilde{\mu}_t$。因此,Ho等人提出让网络$\epsilon_\theta(x_t, t)$直接预测噪声,而不是预测均值。
训练目标简化为:
$$\mathcal{L}_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon}\left[\|\epsilon - \epsilon_\theta(x_t, t)\|^2\right]$$这个公式简单得惊人:随机选择时间步$t$,对原始图像$x_0$加噪得到$x_t$,让网络预测加入的噪声$\epsilon$,最小化预测噪声与真实噪声之间的均方误差。训练完成后,网络学会了在任何噪声水平下"识别"噪声——这本质上就是学会了图像的分布。
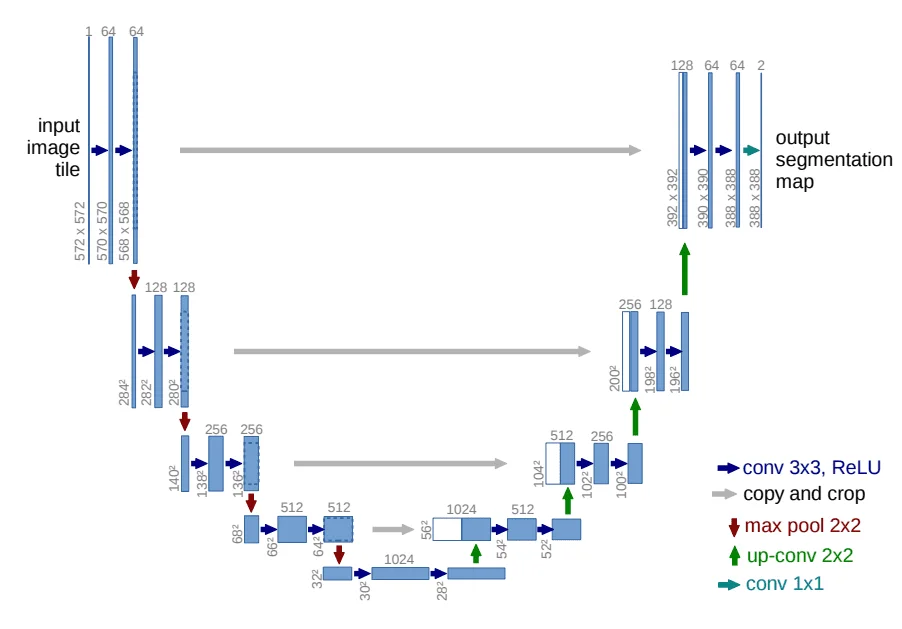
U-Net架构:时间步嵌入与跳跃连接
扩散模型的骨干网络采用U-Net架构。这个选择并非偶然:U-Net的编码器-解码器结构和跳跃连接,非常适合需要保持空间信息的图像任务。
但扩散模型的U-Net有一个特殊需求:网络需要"知道"当前处于哪个时间步$t$。不同时间步的去噪策略应该不同——早期($t$较大)需要去除大量噪声,后期($t$较小)需要精细恢复细节。
这个问题的解决方案借鉴了Transformer的位置编码思想。时间步$t$首先通过正弦位置编码转换为高维向量:
$$\text{PE}(t, 2i) = \sin\left(\frac{t}{10000^{2i/d}}\right), \quad \text{PE}(t, 2i+1) = \cos\left(\frac{t}{10000^{2i/d}}\right)$$其中$d$是嵌入维度,$i$是维度索引。这种编码方式让网络能够区分不同的时间步,同时保持相邻时间步之间的平滑过渡。
时间嵌入通过FiLM(Feature-wise Linear Modulation)机制注入到U-Net的每个残差块中:
$$\text{FiLM}(h, t) = \gamma(t) \odot h + \beta(t)$$其中$h$是特征图,$\gamma(t)$和$\beta(t)$是由时间嵌入生成缩放因子和偏置,$\odot$表示逐元素乘法。这种设计让网络能够根据时间步动态调整特征处理方式。
现代扩散模型的U-Net还引入了自注意力机制。在较低分辨率的特征层中加入自注意力,可以捕获图像的长距离依赖关系,这对于生成高质量、全局一致的图像至关重要。
图片来源: AI Summer
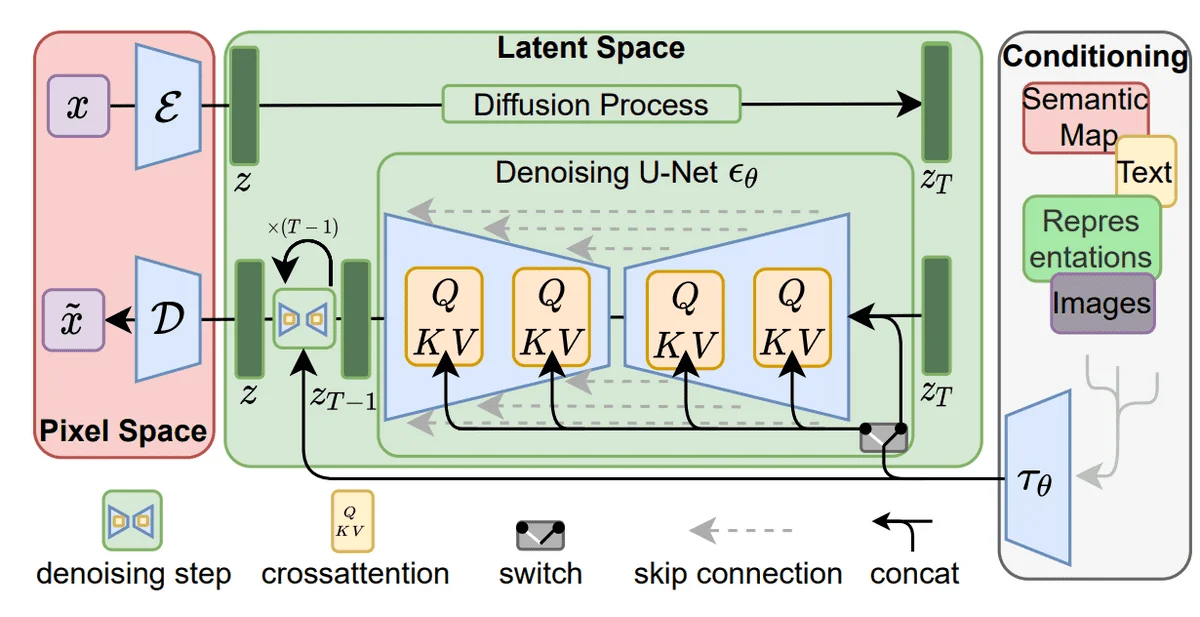
Latent Diffusion:把扩散压缩到潜在空间
DDPM的直接实现有一个致命问题:计算开销巨大。以$512 \times 512$像素的RGB图像为例,单张图片就有近80万个维度,而扩散模型需要处理1000个时间步,每个时间步都要对整个图像进行U-Net推理。这导致训练和推理都极其昂贵。
2022年,Rombach等人提出的Latent Diffusion Model(LDM)提供了一个优雅的解决方案:不在像素空间做扩散,而是在一个压缩的潜在空间进行。
LDM首先训练一个变分自编码器(VAE),包含编码器$\mathcal{E}$和解码器$\mathcal{D}$。编码器将图像$x$压缩到低维潜在表示$z = \mathcal{E}(x)$,解码器从潜在表示重建图像$\tilde{x} = \mathcal{D}(z)$。Stable Diffusion采用的压缩比是$8 \times$,即$512 \times 512$的图像被压缩为$64 \times 64$的潜在表示。
潜在表示的维度是原始图像的$1/64$,这意味着U-Net的计算量减少了约64倍。更重要的是,VAE的压缩是有损的,它丢弃了图像的高频细节(这些细节对人眼感知影响较小),保留了语义信息。这恰好是生成任务最需要的信息。
图片来源: AI Summer
训练潜在扩散模型时,损失函数稍作修改。给定VAE编码器,潜在表示$z_0 = \mathcal{E}(x_0)$,损失变为:
$$\mathcal{L}_{\text{LDM}} = \mathbb{E}_{t, z_0, \epsilon}\left[\|\epsilon - \epsilon_\theta(z_t, t)\|^2\right]$$其中$z_t$是在潜在空间中的噪声版本。生成时,先在潜在空间采样$z_T \sim \mathcal{N}(0, \mathbf{I})$,通过逆向扩散得到$z_0$,再用VAE解码器重建为图像$x = \mathcal{D}(z_0)$。
这个看似简单的改变,使得高质量图像生成在消费级GPU上成为可能。Stable Diffusion的成功,很大程度上归功于这种架构设计。
Classifier-Free Guidance:条件生成的关键
文本到图像生成需要将文本条件注入扩散过程。一种直观的方法是训练条件模型$p_\theta(x_{t-1}|x_t, c)$,其中$c$是文本嵌入。但这种方法的条件控制能力有限。
2022年,Ho和Salimans提出了Classifier-Free Guidance(CFG),彻底改变了条件生成的方式。其核心思想是:同时训练条件模型和无条件模型,生成时将两者结合。
训练时,以概率$p_{\text{uncond}}$(通常取0.1-0.2)将条件$c$替换为空条件$\varnothing$,这样同一个网络同时学会了条件生成和无条件生成。
生成时,使用以下公式调整噪声预测:
$$\tilde{\epsilon}_\theta(x_t, t, c) = \epsilon_\theta(x_t, t, \varnothing) + s \cdot (\epsilon_\theta(x_t, t, c) - \epsilon_\theta(x_t, t, \varnothing))$$其中$s$是引导尺度(guidance scale)。当$s=1$时,退化为标准条件生成;当$s>1$时,模型被"推向"条件方向,远离无条件方向。
CFG的效果令人惊叹。更大的$s$值会产生更符合文本描述、质量更高的图像,但代价是多样性降低。实践中,$s=7-15$通常能取得较好的平衡。这就是为什么在Stable Diffusion等工具中,“CFG Scale"是一个关键参数。
文本条件通过交叉注意力机制注入U-Net。在U-Net的中间层,加入交叉注意力模块:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$其中$Q$来自图像特征,$K$和$V$来自文本嵌入。这种设计让图像的每个位置都能"关注"文本的相关部分,实现细粒度的文图对齐。
DDIM:加速采样的非马尔可夫路径
标准DDPM采样需要1000步逆向扩散,每步都要运行一次U-Net,这导致生成速度极慢。2020年,Jiaming Song等人提出了DDIM(Denoising Diffusion Implicit Models),实现了10-50倍的采样加速。
DDIM的核心洞察是:前向扩散过程的马尔可夫性质对生成并非必要。我们可以构建一类非马尔可夫的前向过程,它们有相同的训练目标,但允许更快的逆向采样。
DDIM的采样公式为:
$$x_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \underbrace{\left(\frac{x_t - \sqrt{1-\bar{\alpha}_t}\epsilon_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}}\right)}_{\text{预测的}x_0} + \sqrt{1-\bar{\alpha}_{t-1}} \cdot \epsilon_\theta(x_t, t)$$这个公式直接从$x_t$跳到$x_{t-1}$,不依赖于中间状态。更重要的是,我们可以跳过时间步,直接从$x_t$跳到$x_{t-\Delta t}$,从而大幅减少采样步数。实验表明,使用50步DDIM采样就能达到接近1000步DDPM采样的质量。
DDIM还有一个有趣性质:它是确定性的。给定相同的初始噪声$x_T$,DDIM总是生成相同的图像。这为图像编辑和插值提供了便利——可以通过编码真实图像到噪声空间,再解码回来实现各种变换。
扩散模型 vs GAN:生成模型的范式之争
在扩散模型崛起之前,GAN统治了图像生成领域多年。理解两者的差异,有助于把握扩散模型的优势。
GAN采用对抗训练:生成器产生假图像,判别器区分真假,两者博弈提升。这种设计让GAN能够生成锐利、真实的图像,但也带来了严重的训练不稳定性和模式崩溃问题——生成器可能只学会生成有限的几种图像,无法覆盖数据分布的全貌。
扩散模型采用了完全不同的策略。它不试图一次性生成图像,而是学习"如何从噪声中逐步恢复图像”。这种渐进式的生成方式,让模型能够精细地学习数据分布的每一个细节。更关键的是,扩散模型的训练目标简单而稳定——只是预测噪声的均方误差,不涉及任何对抗博弈。
从数学角度看,GAN隐式地学习数据分布,而扩散模型显式地建模数据分布的得分函数(score function,即对数概率密度的梯度)。得分函数的学习在高密度区域相对容易,但在低密度区域(数据稀疏的地方)却极其困难。扩散模型通过多尺度噪声扰动解决了这个问题:噪声让数据"扩散"到整个空间,低密度区域被"填满",使得得分函数处处可学习。
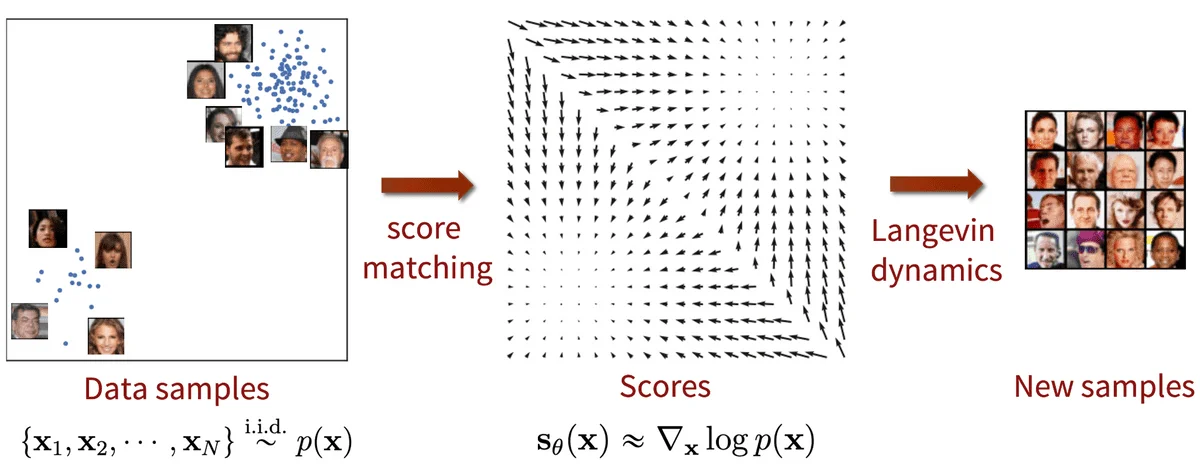
图片来源: AI Summer
生成质量方面,扩散模型通常能产生更多样化、更符合数据分布的样本。评估指标FID(Fréchet Inception Distance)衡量生成图像与真实图像在特征空间的分布距离,数值越低越好。在ImageNet等标准数据集上,扩散模型的FID显著优于GAN。
| 特性 | GAN | 扩散模型 |
|---|---|---|
| 训练稳定性 | 差,需要大量技巧 | 好,目标简单 |
| 模式崩溃 | 常见 | 基本不存在 |
| 生成多样性 | 受限 | 丰富 |
| 生成速度 | 快(单次前向) | 慢(多步迭代) |
| 条件控制 | 相对困难 | 容易(CFG等) |
| 数学框架 | 隐式分布 | 显式概率模型 |
扩散模型的主要缺点是生成速度慢。GAN生成一张图片只需一次网络前向,而扩散模型需要几十到上千次迭代。这是扩散模型"牺牲速度换取质量"的代价。近年来,研究者提出了多种加速方法,如DPM-Solver、一致性模型等,将采样步数压缩到个位数,正在逐步缩小与GAN的速度差距。
从U-Net到DiT:架构的新方向
2023年,一个引人注目的趋势开始浮现:用Transformer替代U-Net作为扩散模型的骨干网络。Peebles和Xie提出的DiT(Diffusion Transformer)证明了这条路的可行性。
DiT的核心思想是将潜在表示分割成patches,像Vision Transformer那样处理。每个DiT块包含自注意力和前馈网络,同时通过自适应层归一化(adaLN)注入时间步和条件信息。
DiT的关键发现是:Transformer架构在扩展性上优于U-Net。当模型规模增大时,U-Net的性能提升趋于平缓,而DiT则展现出类似于语言模型的scaling laws——性能随规模持续提升。OpenAI的视频生成模型Sora就采用了DiT架构,证明了这条路径在大规模场景的有效性。
从架构演进的角度看,扩散模型正在经历从CNN(U-Net)到Transformer(DiT)的转变,这与计算机视觉领域的整体趋势一致。Transformer的统一架构和出色的扩展性,使其成为下一代扩散模型的候选骨干。
三年历程:从理论到应用的爆发
扩散模型的发展速度令人瞠目。以下是关键节点的时间线:
- 2015年:Sohl-Dickstein等人首次提出扩散模型的理论框架,但效果不佳
- 2019年:Song和Ermon提出分数匹配生成模型,为扩散模型奠定另一条理论基础
- 2020年6月:DDPM论文发表,证明扩散模型可以媲美GAN
- 2020年10月:DDIM提出,实现采样加速
- 2021年2月:Improved DDPM提出余弦噪声调度
- 2021年5月:Classifier Guidance(Guided Diffusion)首次让扩散模型击败GAN
- 2021年12月:Classifier-Free Guidance提出,简化条件生成
- 2022年4月:DALL-E 2发布,引发AI绘画热潮
- 2022年5月:Imagen发布,展示语言模型与扩散模型的结合
- 2022年8月:Stable Diffusion开源,将AI绘画普及到大众
- 2023年2月:ControlNet发布,实现精细的空间控制
- 2023年:DiT架构提出,开启Transformer骨干时代
- 2024年2月:Sora发布,DiT架构在视频生成的成功应用
仅仅三年时间,扩散模型从实验室走向了千家万户。这背后是研究社区的集体努力:数学理论的完善、工程实现的优化、大规模数据的积累、开源社区的贡献。扩散模型的成功,是深度学习领域协作创新的典范。
图片来源: 知乎专栏
结语
扩散模型的成功不仅仅是技术的胜利,更是一种研究哲学的体现:有时候,把复杂问题分解成大量简单步骤,比试图一步登天更有效。从噪声到图像的1000步渐进恢复,看似笨拙,实则精妙——每一步只需要做一个简单的决定,累积起来却能创造出无限可能。
扩散模型仍在快速演进。更快的采样方法、更强的条件控制、更高效的架构设计,这些都是活跃的研究方向。从U-Net到DiT的转变,预示着扩散模型可能与Transformer更深度地融合。而在视频、3D、音频等领域,扩散模型正在开拓新的疆土。
当我们用Stable Diffusion生成一张图片时,背后是数千次神经网络推理、数百万次浮点运算,以及数年研究积累的智慧结晶。那张从噪声中浮现的图像,不只是算法的输出,更是人类对创造力本质的一次深刻探索。
参考资料
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS.
- Song, J., Meng, C., & Ermon, S. (2020). Denoising Diffusion Implicit Models. ICLR.
- Nichol, A., & Dhariwal, P. (2021). Improved Denoising Diffusion Probabilistic Models. ICML.
- Dhariwal, P., & Nichol, A. (2021). Diffusion Models Beat GANs on Image Synthesis. NeurIPS.
- Ho, J., & Salimans, T. (2022). Classifier-Free Diffusion Guidance. arXiv.
- Rombach, R., et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR.
- Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV.
- Song, Y., & Ermon, S. (2019). Generative Modeling by Estimating Gradients of the Data Distribution. NeurIPS.
- Sohl-Dickstein, J., et al. (2015). Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. ICML.