2025年10月19日,美国东部时间晚上11点48分,AWS DynamoDB在us-east-1区域发生了一次严重的DNS故障。根据AWS官方的事后分析报告,一个隐藏的竞态条件导致DynamoDB的DNS记录被意外清空——所有IP地址都被删除,只留下一个空的DNS条目。
接下来的15个小时里,这场故障像多米诺骨牌一样蔓延:DynamoDB不可达导致EC2实例启动系统崩溃,网络配置传播积压,负载均衡器误判实例健康状态。超过400万用户报告错误,上千家公司受影响,从Snapchat到Venmo,从Reddit到Coinbase——整个互联网都在颤抖。
这不仅仅是一次DNS故障。当DynamoDB恢复后,积压的请求和重试洪流仍然让系统无法正常运作。AWS工程师不得不手动限制请求、重启关键组件,花了数小时才清理完积压的任务队列。这就是重试风暴(Retry Storm)的威力——一个本意是提高可靠性的机制,却成了放大故障的帮凶。
重试的本质:不是简单的"再试一次"
分布式系统的一个基本事实是:网络是不可靠的,服务是会失败的。根据AWS Builder’s Library的统计,大量的故障属于短暂性故障(Transient Failure)——网络抖动、服务过载、临时性的资源竞争。这些故障往往在几秒或几分钟后就会自行恢复。
重试机制的核心价值在于掩盖这些短暂故障,让调用方无需感知底层的瞬时问题。但这个看似简单的机制背后,隐藏着复杂的权衡:
- 重试太少:无法有效覆盖故障窗口期
- 重试太多:浪费资源,甚至拖垮本已脆弱的服务
- 重试太快:没有给服务恢复的喘息时间
- 重试太慢:影响用户体验,增加延迟
更危险的是重试的乘法效应。假设一个调用链有5层服务,每层都配置了最多3次重试。如果最底层的数据库出问题,理论上对数据库的请求可能达到 $3^5 = 243$ 次。这不是理论推演——2016年某电商公司的大促故障,就是因为一个Redis节点的短暂抖动,触发了整个调用链的重试级联,最终导致所有服务不可用。
指数退避:让系统有喘息的机会
指数退避(Exponential Backoff)是重试延迟策略的核心思想:每次重试的等待时间呈指数增长。基本公式如下:
$$\text{backoff} = \min(\text{cap}, \text{base} \times 2^{\text{attempt}})$$其中:
- $\text{base}$ 是初始退避时间(通常为几百毫秒到几秒)
- $\text{attempt}$ 是重试次数(从0开始)
- $\text{cap}$ 是退避时间的上限(通常为几十秒到几分钟)
这个策略的直觉是:如果第一次重试失败了,说明问题可能持续一段时间,应该等更久再试;如果连续多次失败,说明问题可能很严重,更应该耐心等待。
AWS SDK的标准重试配置采用了这一策略。根据AWS Architecture Blog的技术文章,大多数AWS SDK使用的默认参数是:
- 初始退避时间:1秒
- 退避乘数:2
- 最大退避时间:20秒
- 最大重试次数:3-5次(取决于服务)
Google Cloud Storage客户端库的配置略有不同。根据Google Cloud官方文档,Java客户端的默认配置是:
- 初始退避时间:1秒
- 退避乘数:2.0
- 最大退避时间:32秒
- 最大重试次数:6次
- 总超时时间:50秒
# Python示例:指数退避的基本实现
import time
import random
def exponential_backoff(attempt, base=1.0, cap=20.0):
"""计算指数退避时间"""
backoff = min(cap, base * (2 ** attempt))
return backoff
def retry_with_backoff(func, max_attempts=5, base=1.0, cap=20.0):
"""带指数退避的重试封装"""
for attempt in range(max_attempts):
try:
return func()
except Exception as e:
if attempt == max_attempts - 1:
raise
backoff = exponential_backoff(attempt, base, cap)
time.sleep(backoff)
但纯粹的指数退避有一个致命缺陷:同步化问题(Lockstep Problem)。
抖动:打破同步化的关键
想象一个场景:100个客户端同时发起请求,服务端返回503错误。如果所有客户端都使用相同的指数退避策略,它们会在1秒后同时重试,然后2秒后又同时重试,4秒后又同时重试……这些"集群"般的重试请求会让刚刚开始恢复的服务再次崩溃。
这就是AWS在2015年发表的论文《Exponential Backoff And Jitter》中揭示的核心问题。论文作者通过模拟实验发现,在100个竞争客户端的场景下,无抖动的指数退避几乎和立即重试一样糟糕——请求数量只减少了一点点,而完成时间却大大增加。
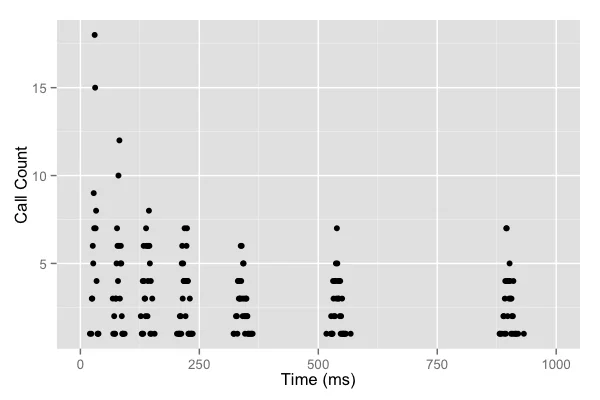
图片来源: AWS Architecture Blog - Exponential Backoff And Jitter
上图清楚地展示了问题:即使使用了指数退避,请求仍然呈现明显的"集群"模式,有大量空白时段完全没有请求。
三种抖动策略对比
AWS论文提出了三种抖动策略,它们在处理延迟的随机性上有本质区别:
1. Full Jitter(完全抖动)
$$\text{sleep} = \text{random}(0, \min(\text{cap}, \text{base} \times 2^{\text{attempt}}))$$这是最激进的策略:在0到退避时间之间完全随机选择。模拟结果显示,在100个客户端竞争的场景下,Full Jitter将总请求数减少了一半以上,同时显著缩短了完成时间。
def full_jitter_backoff(attempt, base=1.0, cap=20.0):
"""Full Jitter:完全随机抖动"""
backoff = min(cap, base * (2 ** attempt))
return random.uniform(0, backoff)
2. Equal Jitter(等分抖动)
$$\text{sleep} = \frac{\text{backoff}}{2} + \text{random}(0, \frac{\text{backoff}}{2})$$这个策略保留了一半的退避时间作为"确定性"部分,只在另一半上随机。设计理念是避免过短的等待——至少等待退避时间的一半。
def equal_jitter_backoff(attempt, base=1.0, cap=20.0):
"""Equal Jitter:保留一半退避时间"""
backoff = min(cap, base * (2 ** attempt))
return backoff / 2 + random.uniform(0, backoff / 2)
3. Decorrelated Jitter(去相关抖动)
$$\text{sleep} = \min(\text{cap}, \text{random}(\text{base}, \text{prev\_sleep} \times 3))$$这个策略与前一次的等待时间相关,但打破了与重试次数的直接关联。每次的等待时间基于上一次的值乘以一个随机因子。
def decorrelated_jitter_backoff(prev_sleep, base=1.0, cap=20.0):
"""Decorrelated Jitter:与前次退避相关"""
sleep = min(cap, random.uniform(base, prev_sleep * 3))
return sleep
性能对比
AWS的模拟实验给出了清晰的结论:
| 策略 | 总请求数 | 完成时间 | 特点 |
|---|---|---|---|
| 无抖动指数退避 | 最高 | 最长 | 集群化明显 |
| Equal Jitter | 中等 | 中等 | 避免过短等待 |
| Full Jitter | 最低 | 较短 | 最均匀分布 |
| Decorrelated Jitter | 中等 | 最短 | 快速完成 |
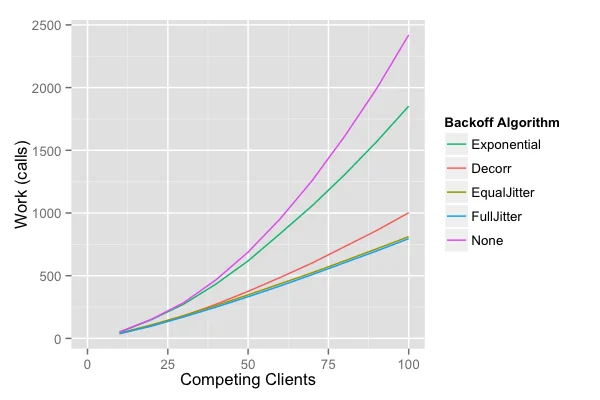
图片来源: AWS Architecture Blog - Exponential Backoff And Jitter
从图中可以看出,Full Jitter和Decorrelated Jitter都显著减少了总请求数。在完成时间上,Decorrelated Jitter略胜一筹,但Full Jitter的工作量更少。
业界推荐:AWS论文最终推荐Full Jitter作为默认选择,因为它简单、有效、易于实现。gRPC官方实现采用的就是Full Jitter,默认在退避时间上添加±20%的随机波动。
幂等性:让重试变得安全
退避和抖动解决了"什么时候重试"的问题,但没有解决"能不能重试"的问题。
考虑一个支付场景:用户点击"支付"按钮,请求发送到支付服务。支付服务执行了扣款操作,但在返回结果时网络超时。客户端没有收到响应,于是重试。如果支付服务没有正确处理,用户可能被扣款两次。
这就是幂等性(Idempotency)的核心问题:一个操作执行多次,是否产生相同的结果?根据AWS Builder’s Library的定义,幂等操作必须满足:
- 对同一资源的多次调用产生相同的最终状态
- 操作只成功一次
- 不会产生额外的可观察副作用
幂等性键模式
AWS在多个API中采用了ClientToken模式来保证幂等性。客户端生成一个唯一的请求标识符(通常是UUID),随请求一起发送。服务端维护一个幂等性会话表,记录每个ClientToken的处理状态。
sequenceDiagram
participant Client
participant API Server
participant Idempotency Store
participant Database
Client->>API Server: POST /orders<br/>ClientToken: abc-123
API Server->>Idempotency Store: Check if abc-123 exists
Idempotency Store-->>API Server: Not found
API Server->>Database: Create order
API Server->>Idempotency Store: Store abc-123 → order_id
API Server-->>Client: 201 Created
Note over Client,Database: 网络超时,客户端重试
Client->>API Server: POST /orders<br/>ClientToken: abc-123
API Server->>Idempotency Store: Check if abc-123 exists
Idempotency Store-->>API Server: Found! order_id = 456
API Server-->>Client: 200 OK (语义等价响应)
服务端返回语义等价响应(Semantically Equivalent Response)是关键。这意味着重试请求得到的响应与原始成功请求的响应在语义上是等价的——客户端不需要区分这是首次请求还是重试请求。
幂等性的条件判断
Google Cloud Storage API将操作分为三类幂等性:
| 类型 | 说明 | 示例 |
|---|---|---|
| 始终幂等 | 任何情况下都可安全重试 | GET请求、列出操作 |
| 条件幂等 | 需要特定参数才幂等 | 带generation参数的PUT |
| 永不幂等 | 重试会产生副作用 | 创建通知、追加写入 |
条件幂等是一个实用的设计模式。例如,Google Cloud Storage的对象上传操作,只有当请求中包含ifGenerationMatch参数时才幂等。这个参数指定了对象的版本号,只有当版本匹配时才会执行写入——这天然防止了重复写入。
// Java示例:带条件幂等的对象上传
Storage storage = StorageOptions.getDefaultInstance().getService();
BlobId blobId = BlobId.of("bucket", "object");
BlobInfo blobInfo = BlobInfo.newBuilder(blobId).build();
// 只有当对象不存在时才创建(generation=0表示不存在)
storage.create(blobInfo, content,
Storage.BlobTargetOption.generationMatch(0L));
断路器:重试的最后一道防线
即使有了退避、抖动和幂等性,持续的重试仍然可能成为问题。当后端服务长时间不可用时,重试只是徒劳地消耗资源。
断路器模式(Circuit Breaker Pattern)提供了一种"快速失败"机制。它基于一个有限状态机工作:
stateDiagram-v2
[*] --> Closed
Closed --> Open: 失败率超过阈值
Open --> HalfOpen: 等待时间到期
HalfOpen --> Closed: 试探请求成功
HalfOpen --> Open: 试探请求失败
三种状态的职责
Closed(关闭状态):正常状态,所有请求正常转发。同时,断路器持续监控请求的成功/失败率。
Open(打开状态):熔断状态,所有请求直接失败,不转发到后端。持续一段时间后,进入Half-Open状态。
Half-Open(半开状态):试探状态,允许有限数量的请求通过。如果这些请求成功,说明服务已恢复,切换回Closed;如果失败,回到Open。
Resilience4j是Java生态中最成熟的断路器实现。其核心配置参数包括:
| 参数 | 默认值 | 说明 |
|---|---|---|
| failureRateThreshold | 50% | 触发熔断的失败率阈值 |
| slowCallRateThreshold | 100% | 触发熔断的慢调用率阈值 |
| slowCallDurationThreshold | 60秒 | 判定为慢调用的时间阈值 |
| permittedNumberOfCallsInHalfOpenState | 10 | 半开状态允许的试探请求数 |
| waitDurationInOpenState | 60秒 | 熔断持续时长 |
| slidingWindowSize | 100 | 滑动窗口大小 |
Google SRE的自适应限流
传统断路器的"一刀切"策略过于刚性。Google SRE提出了一种更优雅的客户端自适应限流算法,它不是完全拒绝请求,而是按概率丢弃:
$$p = \max\left(0, \frac{\text{requests} - K \times \text{accepts}}{\text{requests} + 1}\right)$$其中:
- $\text{requests}$ 是客户端请求总量
- $\text{accepts}$ 是服务端成功处理的请求数
- $K$ 是敏感度系数(通常取2)
当后端正常时,$\text{requests} \approx \text{accepts}$,丢弃概率为0。当后端开始失败时,$\text{accepts}$ 减少,丢弃概率上升。这种渐进式的限流比硬性熔断更温和,给服务恢复留出了空间。
重试预算:限制重试的总开销
即使单个客户端的重试是合理的,大量客户端的重试累积起来仍然可能压垮服务。AWS在2016年引入了重试预算(Retry Budget)机制,其核心思想是使用令牌桶限制重试的总次数。
class RetryBudget:
"""重试预算管理器"""
def __init__(self, max_tokens=10, token_ratio=0.1):
self.max_tokens = max_tokens
self.token_ratio = token_ratio
self.tokens = max_tokens
def on_success(self):
"""成功请求:增加令牌"""
self.tokens = min(self.max_tokens,
self.tokens + self.token_ratio)
def on_failure(self):
"""失败请求:消耗令牌"""
self.tokens -= 1
def can_retry(self):
"""判断是否允许重试"""
# 当令牌低于最大值的一半时,暂停重试
return self.tokens > self.max_tokens / 2
gRPC内置了类似的重试节流机制。当服务端返回失败响应时,令牌数减1;成功时增加tokenRatio。如果令牌数降至maxTokens的一半以下,客户端会暂停重试,直到令牌恢复。
{
"retryThrottling": {
"maxTokens": 10,
"tokenRatio": 0.1
}
}
哪些错误应该重试?
并非所有失败都值得重试。根据HTTP语义,错误码可以分为三类:
可重试的错误:
408 Request Timeout:请求超时,可能是临时性网络问题429 Too Many Requests:被限流,等待后可能恢复500 Internal Server Error:服务端内部错误502 Bad Gateway:网关错误503 Service Unavailable:服务暂时不可用504 Gateway Timeout:网关超时
不可重试的错误:
400 Bad Request:请求本身有问题401 Unauthorized:认证失败403 Forbidden:权限不足404 Not Found:资源不存在4xx(其他):客户端错误
需要谨慎处理的错误:
- 连接超时:可能是网络问题,也可能是服务端过载
- DNS解析失败:可能是配置问题,也可能是DNS服务故障
Google Cloud SDK的实现提供了一个参考模板:它会重试HTTP 408、429、5xx,以及特定的连接错误(如connection reset by peer、connection refused)。但对于DNS解析失败等底层错误,通常不自动重试。
超时传递:避免无效的重试
在多层调用链中,每个服务都有自己的超时配置。如果超时设置不当,可能导致一种尴尬情况:上游已经超时放弃了,下游还在继续处理——这些处理都是无效的。
超时传递(Timeout Propagation)机制解决了这个问题。每个服务在收到请求时,根据剩余时间调整自己的超时设置:
// Go示例:基于Context的超时传递
func HandleRequest(ctx context.Context) {
// 从context中获取剩余超时时间
deadline, ok := ctx.Deadline()
if ok {
remaining := time.Until(deadline)
// 使用剩余时间和配置超时中的较小值
timeout := min(remaining, config.Timeout)
ctx, cancel := context.WithTimeout(ctx, timeout)
defer cancel()
}
// ... 继续处理
}
gRPC天然支持超时传递。每次RPC调用都会在header中携带超时信息,下游服务会自动调整超时时间。这避免了"请求已经无意义,处理仍在进行"的资源浪费。
实战配置参考
不同场景下的重试配置建议:
场景一:用户请求(前端→后端)
用户对延迟敏感,但容忍偶尔的失败:
- 最大重试次数:2-3次
- 初始退避:100-500毫秒
- 最大退避:5-10秒
- 总超时:5-15秒
- 策略:Full Jitter
场景二:服务间调用(后端→后端)
需要平衡可靠性和资源消耗:
- 最大重试次数:3-5次
- 初始退避:1秒
- 最大退避:30秒
- 总超时:60秒
- 策略:Full Jitter + 断路器
场景三:后台任务(异步处理)
容忍较高延迟,追求高成功率:
- 最大重试次数:5-10次
- 初始退避:5秒
- 最大退避:5分钟
- 总超时:无限制(或数小时)
- 策略:Decorrelated Jitter + 重试预算
场景四:对冲请求(低延迟要求)
对延迟极度敏感,可以容忍额外的资源消耗:
- 对冲次数:2-3次
- 对冲间隔:10-50毫秒
- 策略:同时发送多个请求,取最快响应
gRPC支持对冲(Hedging)作为重试的替代方案:
{
"hedgingPolicy": {
"maxAttempts": 3,
"hedgingDelay": "50ms",
"nonFatalStatusCodes": ["UNAVAILABLE", "DEADLINE_EXCEEDED"]
}
}
避免这些反模式
根据Google Cloud Storage文档和AWS的最佳实践,以下反模式需要避免:
1. 不退避地重试
立即重试或以极短间隔重试,是最危险的错误。它会在瞬间放大负载,导致级联故障。
2. 无条件重试非幂等操作
非幂等操作的重试可能导致数据重复或状态不一致。如果必须重试,必须设计幂等性保障机制。
3. 重试不可重试的错误
对401、403、404等错误进行重试毫无意义,只会浪费资源。
4. 忽略重试限制
无限重试可能导致应用挂起或资源耗尽。必须设置最大重试次数和总超时时间。
5. 不必要的分层重试
如果底层SDK已经实现了重试,应用层再叠加重试会导致请求量指数级放大。
写在最后
重试机制是分布式系统容错能力的基石,但它不是银弹。一个设计不当的重试机制,可能成为系统崩溃的导火索。
从AWS 2025年的中断事件中,我们可以学到:重试是一种自私的行为——客户端通过重试来提高自己的成功率,代价是增加服务端的负载。只有当这种"自私"被合理约束时,系统才能在故障面前保持韧性。
三个核心原则值得记住:
- 给服务喘息的机会:指数退避 + 抖动,让请求在时间上分散开
- 让重试变得安全:幂等性设计,避免重复执行的副作用
- 知道何时放弃:断路器 + 重试预算,避免无效的重试
当这三个原则协同工作时,重试才能真正成为系统可靠性的保障,而不是隐患。
参考文献
- AWS Architecture Blog. (2015). Exponential Backoff And Jitter
- AWS Builder’s Library. Timeouts, retries, and backoff with jitter
- AWS Builder’s Library. Making retries safe with idempotent APIs
- Google Cloud. Cloud Storage Retry Strategy
- gRPC Documentation. Retry
- Resilience4j. CircuitBreaker
- Google SRE Book. Client-side throttling
- Panto.ai. AWS Outage 2025: How a Retry Storm Took Down the Internet