2012年,Netflix的工程团队做了一个看似疯狂的决定:在生产环境中主动注入故障。他们开发的Chaos Monkey会随机终止生产服务器实例,以此验证系统的容错能力。这个看似激进的实践背后,是一个深刻的认知:分布式系统中,故障不是会不会发生的问题,而是什么时候发生的问题。
熔断器模式(Circuit Breaker Pattern)正是应对这一现实的核心机制。它借鉴了电力系统中的断路器概念:当电流过载时,断路器自动切断电路,防止设备损坏;当故障排除后,断路器可以重新闭合,恢复正常供电。软件系统中的熔断器承担着相同的职责——在依赖服务故障时快速失败,保护系统资源不被耗尽。
熔断器的工作原理
熔断器的核心是一个有限状态机,包含三个正常状态:关闭(Closed)、打开(Open)和半开(Half-Open)。
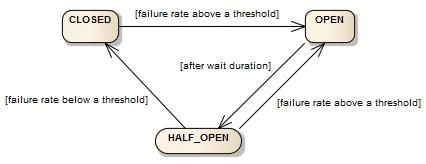
关闭状态是熔断器的初始状态,此时所有请求正常通过。熔断器持续监控请求的成功率和响应时间,当失败率或慢调用比例超过阈值时,熔断器切换到打开状态。
打开状态意味着熔断器已经"跳闸"。此时所有请求都会被直接拒绝,不再调用下游服务。这个状态会持续一段时间(等待持续时间),给下游服务恢复的机会。
半开状态是熔断器尝试恢复的探测阶段。等待持续时间结束后,熔断器允许一定数量的试探请求通过。如果这些请求成功,熔断器回到关闭状态;如果失败,熔断器重新进入打开状态。
为什么需要熔断器
考虑这样一个场景:一个电商系统的订单服务依赖库存服务进行库存校验。库存服务因为数据库连接池耗尽而响应缓慢,每个请求都需要等待30秒超时。订单服务配置了200个工作线程,当流量高峰来临时:
- 每个请求都被阻塞在等待库存服务响应
- 200个线程很快被耗尽
- 新请求无法处理,整个订单服务变得不可用
- 用户请求超时,开始重试,进一步加剧系统负载
- 故障从库存服务蔓延到订单服务,最终影响整个系统
这就是典型的级联故障(Cascading Failure)。熔断器的作用就是打破这个恶性循环:当检测到库存服务持续失败时,熔断器打开,后续请求直接返回错误或执行降级逻辑,释放线程资源处理其他正常请求。
核心配置参数详解
理解熔断器的配置参数是正确使用熔断器的前提。以Resilience4j为例,以下是关键参数的详细解释:
失败率阈值(failureRateThreshold)
失败率阈值决定了何时触发熔断。默认值为50%,意味着当滑动窗口内超过50%的请求失败时,熔断器打开。
resilience4j:
circuitbreaker:
instances:
inventoryService:
failureRateThreshold: 50
阈值的设置需要权衡敏感度和误判风险。阈值过低可能导致偶发性故障触发熔断;阈值过高则可能导致熔断器反应迟钝,无法及时保护系统。
根据Shopify的生产经验,对于关键依赖服务,建议将失败率阈值设置在40%-60%之间,同时配合合理的最小调用次数来降低误判概率。
滑动窗口(Sliding Window)
滑动窗口用于收集和聚合调用结果。Resilience4j支持两种类型的滑动窗口:
基于计数的滑动窗口:统计最近N次调用的结果。例如窗口大小为100,则统计最近100次调用的成功率。
slidingWindowType: COUNT_BASED
slidingWindowSize: 100
基于时间的滑动窗口:统计最近N秒内所有调用的结果。例如窗口大小为10秒,则统计最近10秒内的所有调用。
slidingWindowType: TIME_BASED
slidingWindowSize: 10
两种方式各有优劣。基于计数的滑动窗口更稳定,不受流量波动影响;基于时间的滑动窗口对流量变化更敏感,但在流量低峰期可能因样本量不足而产生统计偏差。
最小调用次数(minimumNumberOfCalls)
这是一个容易被忽视但至关重要的参数。它指定了在计算失败率之前,滑动窗口内必须达到的最小调用次数。
minimumNumberOfCalls: 10
假设最小调用次数设置为10,但滑动窗口内只有5次调用全部失败。此时失败率为100%,但熔断器不会打开——因为还没有收集到足够的样本。这个机制避免了因样本量不足导致的误判。
等待持续时间(waitDurationInOpenState)
熔断器在打开状态下的等待时间,之后自动切换到半开状态进行探测。
waitDurationInOpenState: 60000 # 60秒
这个参数需要根据下游服务的恢复特性来设置。如果下游服务通常需要几分钟才能恢复,设置过短的等待时间会导致无效的探测请求,增加系统负担。
半开状态允许的调用次数(permittedNumberOfCallsInHalfOpenState)
半开状态下允许通过的试探请求数量。
permittedNumberOfCallsInHalfOpenState: 10
这些试探请求用于验证下游服务是否已恢复。如果所有试探请求都成功,熔断器关闭;如果有任何试探请求失败,熔断器重新打开。
慢调用阈值(slowCallDurationThreshold 和 slowCallRateThreshold)
除了失败率,熔断器还支持基于响应时间的熔断策略。当慢调用(响应时间超过阈值)的比例超过设定值时,熔断器同样会打开。
slowCallDurationThreshold: 2000 # 2秒
slowCallRateThreshold: 50 # 50%
这个机制特别适用于处理"活死"状态的服务——服务没有完全宕机,但响应时间异常缓慢。在这种情况下,即使请求最终成功,过长的等待时间也会严重影响系统吞吐量。
降级策略设计
熔断器打开后,请求被拒绝,但系统不能简单地返回错误。降级策略决定了在故障情况下如何优雅地处理请求,保证核心功能可用。
静态默认值降级
最简单的降级方式是返回预定义的默认值。
@CircuitBreaker(name = "inventoryService", fallbackMethod = "fallback")
public InventoryInfo getInventory(String productId) {
return inventoryClient.query(productId);
}
public InventoryInfo fallback(String productId, Exception e) {
return new InventoryInfo(productId, 0, false);
}
这种方式适用于非关键数据。例如商品详情页的推荐模块故障时,可以返回空列表或热门商品,而不是导致整个页面无法加载。
缓存降级
当实时数据不可用时,返回之前缓存的数据,即使数据可能已经过时。
public InventoryInfo fallback(String productId, Exception e) {
InventoryInfo cached = cache.get(productId);
if (cached != null) {
cached.setStale(true); // 标记数据可能过时
return cached;
}
return new InventoryInfo(productId, 0, false);
}
缓存降级是一种"宁可显示过时数据,也不要完全失败"的策略。对于商品库存这类时效性数据,可以在前端显示"数据可能不是最新"的提示,同时允许用户继续浏览。
服务降级分层
在实际系统中,不同功能的降级策略应该有所区分。可以按照以下层次设计降级方案:
| 功能层级 | 降级策略 | 示例 |
|---|---|---|
| 核心功能 | 缓存降级、异步重试 | 支付失败后进入异步重试队列 |
| 重要功能 | 默认值降级 | 推荐服务故障时返回热门商品 |
| 增强功能 | 直接禁用 | 评论功能故障时不显示评论区 |
| 非必要功能 | 完全跳过 | 数据统计服务故障时不影响主流程 |
生产环境配置实践
Shopify工程团队分享过一个极具价值的案例:他们为Rails工作线程配置熔断器保护42个Redis实例,初始配置下,当所有Redis实例故障时,系统需要额外263%的资源利用率——这实际上意味着系统完全不可用。
问题分析
初始配置如下:
| 参数 | 值 |
|---|---|
| error_threshold | 3 |
| error_timeout | 2秒 |
| half_open_resource_timeout | 0.25秒 |
| failing_instances | 42 |
当所有Redis实例故障时,每个实例需要3次超时才能打开熔断器。42个实例 × 3次超时 × 0.25秒 = 31.5秒的阻塞时间。此外,熔断器每2秒进入半开状态尝试探测,每次探测又有42 × 0.25秒的阻塞。
优化方案
根据生产监控数据,99%的Redis请求响应时间低于50毫秒。基于此,调整配置如下:
| 参数 | 调整后 | 理由 |
|---|---|---|
| half_open_resource_timeout | 50毫秒 | 大部分正常请求在此时间内完成 |
| error_timeout | 30秒 | 减少探测频率,降低资源浪费 |
调整后,额外资源利用率从263%降至4%,系统在极端故障情况下仍能保持核心功能可用。
配置公式
Shopify团队总结了一个实用的熔断器配置公式,用于估算稳态故障场景下的额外资源利用率:
$$\text{Additional Utilization} = \frac{\text{failing\_services} \times \text{half\_open\_timeout}}{\text{error\_timeout} + \text{failing\_services} \times \text{half\_open\_timeout}} \times 100\%$$这个公式帮助工程师在配置熔断器时量化权衡,避免直觉式的参数设置导致意外问题。
自适应熔断:TCP Vegas算法
传统的熔断器依赖预配置的阈值,这种静态配置难以适应动态变化的负载和故障模式。Uber开发的Cinnamon系统引入了自适应并发限制,基于TCP Vegas算法动态调整并发上限。
TCP Vegas核心思想
TCP Vegas是一种拥塞控制算法,其核心思想是比较实际吞吐量与预期吞吐量的差异来判断网络拥塞程度。将这个思想应用到服务限流:
- 如果当前请求延迟接近历史最优值,说明系统有余力处理更多请求
- 如果当前请求延迟明显增加,说明系统接近过载,应该降低并发限制
伪代码实现
func updateLimit(sample, targetLatency, currentLimit):
ratio = targetLatency / sample
if ratio > 1.05:
// 延迟比目标低,可以增加并发
currentLimit += log2(currentLimit) * (ratio - 1)
else if ratio < 0.95:
// 延迟比目标高,需要降低并发
currentLimit -= log2(currentLimit) * (1 - ratio)
return currentLimit
生产环境挑战与解决方案
Uber团队在将TCP Vegas应用于生产环境时遇到了多个挑战:
问题一:负载变化导致的参考延迟漂移
在长时间过载期间,如果周期性地将目标延迟重置为最新观测值,会导致目标延迟持续上升,最终失去保护作用。
解决方案:使用协方差判断延迟与吞吐量的相关性。当协方差为负时(延迟上升但吞吐量下降),说明系统已经过载,此时不再更新目标延迟。
问题二:正常情况下的无界增长
当服务正常运行时,由于实际延迟接近目标延迟,算法会不断增加并发限制,导致故障发生时需要很长时间才能降到安全水平。
解决方案:设置并发上限为实际观测并发数的10倍,确保在故障发生时能够快速降低并发。
熔断器与其他可靠性模式的组合
熔断器通常不单独使用,而是与重试、限流、隔板(Bulkhead)等模式组合使用,构建完整的可靠性防护体系。
熔断器 + 重试
熔断器和重试是互补的模式。重试用于处理瞬时故障,熔断器用于处理持续性故障。
// 错误示例:重试包裹熔断器
Retry.decorateSupplier(
CircuitBreaker.decorateSupplier(circuitBreaker, () -> service.call())
);
// 正确示例:熔断器包裹重试
CircuitBreaker.decorateSupplier(
circuitBreaker,
Retry.decorateSupplier(retry, () -> service.call())
);
正确的顺序是:先执行重试逻辑,当重试都失败后,熔断器记录失败。这样可以避免将重试过程中的多次失败都计入熔断器的失败计数。
熔断器 + 隔板
隔板模式通过限制并发访问数来隔离故障。与熔断器的区别在于:
- 熔断器:基于失败率决定是否熔断
- 隔板:基于并发数决定是否接受请求
两者组合使用可以提供双重保护:
resilience4j:
circuitbreaker:
instances:
paymentService:
failureRateThreshold: 50
bulkhead:
instances:
paymentService:
maxConcurrentCalls: 10
当支付服务响应缓慢但尚未达到熔断阈值时,隔板可以防止过多线程被阻塞。
监控与可观测性
熔断器的有效性高度依赖于正确的监控和告警。以下是关键的监控指标:
核心指标
| 指标 | 说明 | 告警建议 |
|---|---|---|
| 熔断器状态 | 当前处于哪种状态 | Open状态持续超过预期时间 |
| 失败率 | 滑动窗口内的请求失败率 | 接近阈值时预警 |
| 慢调用率 | 响应时间超过阈值的请求比例 | 趋势性上升 |
| 拒绝请求数 | 因熔断器打开被拒绝的请求数 | 突然增加 |
Prometheus指标示例
Resilience4j自动暴露以下Prometheus指标:
# 熔断器状态
resilience4j_circuitbreaker_state{name="inventoryService",} 1.0
# 失败率
resilience4j_circuitbreaker_failure_rate{name="inventoryService",} 25.0
# 慢调用率
resilience4j_circuitbreaker_slow_call_rate{name="inventoryService",} 10.0
# 熔断器打开次数
resilience4j_circuitbreaker_opened{name="inventoryService",} 5.0
事件监听
除了指标,熔断器还应该输出事件日志,用于故障诊断:
circuitBreaker.getEventPublisher()
.onStateTransition(event ->
log.warn("CircuitBreaker {} transitioned from {} to {}",
event.getCircuitBreakerName(),
event.getStateTransition().getFromState(),
event.getStateTransition().getToState()))
.onError(event ->
log.error("CircuitBreaker {} recorded error: {}",
event.getCircuitBreakerName(),
event.getThrowable().getMessage()));
常见陷阱与最佳实践
陷阱一:熔断器粒度过粗
为所有依赖配置同一个熔断器是一个常见错误。如果一个应用同时调用多个下游服务,应该为每个服务配置独立的熔断器,避免一个服务的故障导致所有依赖都被熔断。
// 错误示例:所有依赖共享一个熔断器
@CircuitBreaker(name = "defaultCircuitBreaker")
public Order createOrder(OrderRequest request) {
inventoryService.check(request);
paymentService.charge(request);
notificationService.send(request);
}
// 正确示例:每个依赖独立熔断
public Order createOrder(OrderRequest request) {
inventoryCircuitBreaker.executeRunnable(() ->
inventoryService.check(request));
paymentCircuitBreaker.executeRunnable(() ->
paymentService.charge(request));
notificationCircuitBreaker.executeRunnable(() ->
notificationService.send(request));
}
陷阱二:忽略半开状态的并发问题
当熔断器进入半开状态时,如果有大量请求同时到达,可能导致试探请求数量远超预期。
解决方案:使用原子操作控制半开状态下的许可发放,确保试探请求数量严格受控。
陷阱三:降级逻辑过于复杂
降级逻辑应该是简单可靠的。如果降级逻辑本身依赖其他服务,可能引入新的故障点。
// 危险示例:降级逻辑依赖另一个服务
public InventoryInfo fallback(String productId, Exception e) {
return backupService.query(productId); // backupService也可能故障
}
// 安全示例:降级逻辑完全自包含
public InventoryInfo fallback(String productId, Exception e) {
return cache.getWithDefault(productId, DEFAULT_INVENTORY);
}
陷阱四:熔断器替代了正确的错误处理
熔断器是保护机制,不是错误处理的替代品。业务逻辑仍然需要正确处理各种异常情况。
最佳实践总结
- 为每个依赖配置独立的熔断器,使用语义化的命名
- 根据依赖的重要性设置不同的熔断参数,核心服务更激进地熔断
- 设置合理的最小调用次数,避免样本量不足导致的误判
- 设计自包含的降级逻辑,避免引入新的依赖
- 监控熔断器状态变化,及时发现问题
- 定期进行混沌工程测试,验证熔断器的有效性
- 在非关键依赖上优先使用熔断器,积累经验后再推广到核心依赖
从Hystrix到Resilience4j
Netflix于2018年宣布Hystrix进入维护模式,不再积极开发。Resilience4j成为主流的替代方案。
Hystrix被弃用的原因
Hystrix的设计基于2011年左右的架构理念,存在一些局限性:
- 强制使用HystrixCommand包装器,侵入性较强
- 依赖线程池隔离,开销较大
- 配置不够灵活,部分参数无法动态调整
- 项目不再活跃维护
Resilience4j的优势
Resilience4j采用了更现代化的设计:
- 基于函数式接口,支持Lambda表达式
- 模块化设计,可以只引入需要的功能
- 支持多种隔离策略(线程池、信号量)
- 配置更加灵活,支持动态调整
- 活跃的社区维护
迁移要点
从Hystrix迁移到Resilience4j时,需要注意以下对应关系:
| Hystrix配置 | Resilience4j配置 |
|---|---|
| circuitBreaker.requestVolumeThreshold | slidingWindowSize |
| circuitBreaker.errorThresholdPercentage | failureRateThreshold |
| circuitBreaker.sleepWindowInMilliseconds | waitDurationInOpenState |
| metrics.rollingStats.timeInMilliseconds | slidingWindowSize (TIME_BASED) |
结语
熔断器是分布式系统容错设计的基石,但它不是万能药。正确使用熔断器需要深入理解其工作原理,根据具体场景调整配置参数,设计合理的降级策略,并建立完善的监控体系。
在实践中,建议从非关键依赖开始引入熔断器,逐步积累经验和信心。通过混沌工程测试验证熔断器的有效性,确保在真正的故障发生时,系统能够如预期般优雅地降级,而不是完全崩溃。
参考资料
- Martin Fowler, “Circuit Breaker”, 2014
- Resilience4j Documentation, CircuitBreaker Module
- Uber Engineering Blog, “Cinnamon Auto-Tuner: Adaptive Concurrency in the Wild”, 2023
- Shopify Engineering, “Your Circuit Breaker is Misconfigured”, 2020
- Microsoft Azure Architecture Center, “Circuit Breaker Pattern”
- Netflix Tech Blog, “Introducing Hystrix for Resilience Engineering”, 2012
- Michael Nygard, “Release It!: Design and Deploy Production-Ready Software”, 2007