假设你需要为$n$个城市铺设光缆,每两个城市之间的铺设成本各不相同。如何用最低的总成本让所有城市互联互通?这看似是一个复杂的优化问题,实际上可以抽象为图论中的经典问题——最小生成树(Minimum Spanning Tree,简称MST)。
有趣的是,解决这个问题的两种主流算法——Prim算法和Kruskal算法——采用了截然相反的策略:一个从"点"出发逐个扩展,一个从"边"出发逐条选择。更令人惊讶的是,这两种看似对立的方法都能保证得到最优解。这背后的数学原理是什么?在实际应用中又该如何选择?
什么是生成树与最小生成树
在深入算法之前,需要先理解几个核心概念。
生成树(Spanning Tree)是连通无向图的一个子图,它满足三个条件:包含图中所有顶点、是一棵树(无环)、边数恰好为$n-1$($n$为顶点数)。想象一棵树要"伸展开"覆盖图中的每个顶点,这就是"生成树"名称的由来。
最小生成树则是在所有可能的生成树中,边权总和最小的那棵。需要注意的是,最小生成树不一定唯一——当图中存在权重相等的边时,可能存在多棵权重相同的最小生成树。但如果所有边的权重互不相同,最小生成树就是唯一的。
最小生成树有一个重要性质:它也是最小瓶颈生成树。这意味着在最小生成树中,任意两个顶点之间路径上的最大边权,是所有可能路径中最小的。这个性质在网络设计中有重要应用——比如设计通信网络时,我们希望任何两点之间传输延迟的最大值尽可能小。
切分定理:贪心策略的理论基石
Prim和Kruskal算法之所以都采用贪心策略且都能得到最优解,根本原因在于它们都基于同一个数学定理——切分定理(Cut Property)。
切分定理的表述非常简洁:将图的顶点集任意划分为两个非空子集$S$和$V-S$(这称为一个"切分"),所有跨越这个切分的边中,权重最小的那条边一定属于某棵最小生成树。
理解这个定理需要从反证法入手。假设跨越切分的最小权边$e$不属于任何最小生成树。任取一棵最小生成树$T$,将$e$加入$T$后必然形成一个环。这个环必定包含另一条跨越切分的边$e'$(因为$T$必须连接$S$和$V-S$两个子集)。由于$e$是跨越切分的最小权边,有$w(e) \leq w(e')$。用$e$替换$e'$得到的新树$T'$权重不大于$T$,因此$T'$也是最小生成树,且包含$e$——与假设矛盾。
切分定理揭示了一个深刻的事实:最小生成树的构建可以"局部"进行。每次选择跨越当前已构建部分与未构建部分的最小权边,就能保证最终结果是最优的。这正是Prim算法的核心思想;而Kruskal算法虽然策略不同,但其正确性同样依赖于切分定理的一个推论——环性质(Cycle Property):在图的任意环中,权重最大的边不属于任何最小生成树。
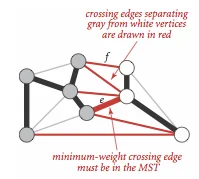
图片来源: Princeton Algorithms 4th Edition - Minimum Spanning Trees
Kruskal算法:从边出发的贪心策略
Kruskal算法由Joseph Kruskal在1956年提出,其核心思想异常直观:将所有边按权重排序,从小到大依次选择,只要不形成环就加入生成树。
这个算法的优雅之处在于它对"不形成环"的处理。判断两个顶点是否属于同一连通分量,恰好是并查集(Union-Find)数据结构的专长。这正是前文详细介绍的并查集的经典应用场景。
算法步骤
- 将所有边按权重升序排序
- 初始化并查集,每个顶点独立成集
- 遍历排序后的边,若边的两个端点不在同一集合,则合并集合并将边加入生成树
- 当已选边数达到$n-1$时停止
时间复杂度分析
Kruskal算法的时间复杂度主要由两部分组成:
- 边排序:$O(E \log E)$
- 并查集操作:$O(E \cdot \alpha(V))$,其中$\alpha$是反阿克曼函数,实际可视为常数
总时间复杂度为$O(E \log E)$。由于$\log E \leq 2\log V$(完全图时取等),也可以写成$O(E \log V)$。
Java实现
class Solution {
public int minimumCost(int n, int[][] connections) {
// 按成本排序
Arrays.sort(connections, (a, b) -> a[2] - b[2]);
UnionFind uf = new UnionFind(n);
int totalCost = 0;
int edgesUsed = 0;
for (int[] conn : connections) {
int u = conn[0] - 1; // 转换为0-based索引
int v = conn[1] - 1;
int cost = conn[2];
if (uf.union(u, v)) {
totalCost += cost;
edgesUsed++;
if (edgesUsed == n - 1) break;
}
}
return edgesUsed == n - 1 ? totalCost : -1;
}
}
class UnionFind {
private int[] parent;
private int[] rank;
public UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
public boolean union(int x, int y) {
int px = find(x), py = find(y);
if (px == py) return false; // 已在同一集合
// 按秩合并
if (rank[px] < rank[py]) {
parent[px] = py;
} else if (rank[px] > rank[py]) {
parent[py] = px;
} else {
parent[py] = px;
rank[px]++;
}
return true;
}
}
Kruskal算法的正确性证明
Kruskal算法的正确性可以通过归纳法结合环性质证明。
设$F$为算法过程中已选边的集合。初始时$F = \emptyset$,显然是某棵最小生成树的子集。
假设在某一步之前,$F$是某棵最小生成树$T$的子集。考虑当前处理的边$e = (u, v)$:
情况一:$u$和$v$已在同一连通分量。加入$e$会形成环。由环性质,环中权重最大的边不会出现在最小生成树中。由于边按权重升序处理,$e$是环中最后加入的边,权重必然大于或等于环中已有的边,因此$e$可以安全舍弃。
情况二:$u$和$v$在不同连通分量。此时$e$是跨越这两个连通分量切分的候选边中最小的(因为边已排序),由切分定理,$e$属于某棵最小生成树。将$e$加入$F$后,$F \cup \{e\}$仍是某棵最小生成树的子集。
由归纳法,算法终止时得到的边集构成一棵最小生成树。
Prim算法:从顶点出发的生长策略
Prim算法由Vojtěch Jarník在1930年提出,后由Robert C. Prim于1957年独立发现并推广。它与Kruskal算法的策略形成鲜明对比:从一个起点出发,每次选择连接"已建树"和"未建树"的最小权边,逐步扩展生成树。
Prim算法可以看作是对切分定理的直接应用:在任意时刻,已选顶点集$S$和未选顶点集$V-S$构成一个切分,算法选择跨越这个切分的最小权边。
算法步骤
- 任选一个起点加入生成树
- 维护每个未选顶点到生成树的最小距离
- 每次选择距离最小的未选顶点加入生成树
- 更新与新加入顶点相邻的未选顶点的距离
- 重复直到所有顶点都被选中
时间复杂度分析
Prim算法的时间复杂度取决于所用的数据结构:
朴素实现(邻接矩阵):每次选择最小距离顶点需要$O(V)$,共$V$次;每次更新距离需要$O(V)$,共更新$E$次。总复杂度$O(V^2)$。适合稠密图。
优先队列实现:使用最小堆维护距离。每次提取最小值$O(\log V)$,共$V$次;每次更新(插入新值)$O(\log V)$,共$E$次。总复杂度$O(E \log V)$。适合稀疏图。
值得注意的是,当使用优先队列时,Java的标准库PriorityQueue不支持高效的"减少键值"操作。通常的做法是直接插入新值,取出时跳过已访问顶点。这会增加堆中元素数量,但复杂度仍是$O(E \log V)$。
Java实现(优先队列优化版)
class Solution {
public int minCostConnectPoints(int[][] points) {
int n = points.length;
boolean[] visited = new boolean[n];
int[] minDist = new int[n];
Arrays.fill(minDist, Integer.MAX_VALUE);
// 优先队列:[距离, 顶点索引]
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
pq.offer(new int[]{0, 0}); // 从顶点0开始
minDist[0] = 0;
int totalCost = 0;
int edgesUsed = 0;
while (!pq.isEmpty() && edgesUsed < n) {
int[] curr = pq.poll();
int dist = curr[0];
int u = curr[1];
if (visited[u]) continue; // 跳过已访问顶点
visited[u] = true;
totalCost += dist;
edgesUsed++;
// 更新相邻顶点的距离
for (int v = 0; v < n; v++) {
if (!visited[v]) {
int newDist = Math.abs(points[u][0] - points[v][0])
+ Math.abs(points[u][1] - points[v][1]);
if (newDist < minDist[v]) {
minDist[v] = newDist;
pq.offer(new int[]{newDist, v});
}
}
}
}
return totalCost;
}
}
Prim算法的正确性证明
Prim算法的正确性证明可以直接从切分定理得出。
设在某一步,已构建的顶点集为$S$,未构建的为$V-S$。算法选择跨越切分$(S, V-S)$的最小权边$e$。根据切分定理,$e$属于某棵最小生成树。
进一步地,可以用交换论证证明:设Prim算法输出的树为$T$,任意最小生成树为$T^*$。若$T \neq T^*$,设$e_k$是Prim算法第$k$步选择的不在$T^*$中的第一条边。$T^*$中必有另一条边$e'$跨越同样的切分(否则$T^*$无法连通$S$和$V-S$)。由于Prim算法选择的是最小权边,有$w(e_k) \leq w(e')$。将$T^*$中的$e'$替换为$e_k$,得到的新树权重不增,因此仍是MST。重复此过程可将任意MST转化为Prim算法的输出。
graph TB
subgraph Prim算法执行过程
A[从顶点0开始] --> B[选择最小权边0-1]
B --> C[已选集合: 0,1]
C --> D[选择最小权边1-2]
D --> E[已选集合: 0,1,2]
E --> F[继续扩展直到覆盖所有顶点]
end
两种算法的对比与选择
理解了两种算法的原理后,关键问题是:在实际应用中如何选择?
| 维度 | Kruskal算法 | Prim算法 |
|---|---|---|
| 核心策略 | 选边:全局排序后贪心选边 | 选点:从起点逐步扩展 |
| 核心数据结构 | 并查集 | 优先队列(最小堆) |
| 时间复杂度 | $O(E \log E)$ | $O(E \log V)$ 或 $O(V^2)$ |
| 空间复杂度 | $O(V + E)$ | $O(V)$ 或 $O(V^2)$ |
| 适合图类型 | 稀疏图($E$较小) | 稠密图($E$较大) |
| 实现难度 | 较简单(排序+并查集) | 中等(优先队列维护) |
| 在线能力 | 不支持(需预知所有边) | 支持增量式构建 |
稀疏图 vs 稠密图
当$E \approx V$(稀疏图)时,两种算法的时间复杂度都是$O(V \log V)$,相差不大。但当$E \approx V^2$(稠密图,如完全图)时:
- Kruskal:$O(V^2 \log V)$(边排序主导)
- Prim(朴素):$O(V^2)$(邻接矩阵更优)
因此在稠密图场景下,朴素Prim算法更优;在稀疏图场景下,两种算法相当,Kruskal实现更简洁。
现实世界的考量
除了理论复杂度,实际应用中还需考虑:
- 内存访问模式:Prim算法局部性更好,缓存友好
- 并行化:Kruskal的排序可并行,但并查集操作有依赖;Prim较难并行
- 增量更新:Prim支持动态添加顶点,Kruskal需要重新排序
LeetCode经典题目详解
LeetCode 1135. Connecting Cities With Minimum Cost
题目描述:有$n$个城市,给出若干城市之间建路的成本,求连接所有城市的最小成本。无法连接则返回-1。
分析:这是最直接的MST问题。输入已经是边的列表形式,使用Kruskal算法最为自然。
class Solution {
public int minimumCost(int n, int[][] connections) {
Arrays.sort(connections, (a, b) -> a[2] - b[2]);
int[] parent = new int[n + 1];
int[] rank = new int[n + 1];
for (int i = 1; i <= n; i++) parent[i] = i;
int totalCost = 0, edges = 0;
for (int[] conn : connections) {
int u = conn[0], v = conn[1], cost = conn[2];
if (find(parent, u) != find(parent, v)) {
union(parent, rank, u, v);
totalCost += cost;
edges++;
}
}
return edges == n - 1 ? totalCost : -1;
}
private int find(int[] parent, int x) {
if (parent[x] != x) parent[x] = find(parent, parent[x]);
return parent[x];
}
private void union(int[] parent, int[] rank, int x, int y) {
int px = find(parent, x), py = find(parent, y);
if (rank[px] < rank[py]) parent[px] = py;
else if (rank[px] > rank[py]) parent[py] = px;
else { parent[py] = px; rank[px]++; }
}
}
LeetCode 1584. Min Cost to Connect All Points
题目描述:给定平面上的若干点,两点之间的连接成本为曼哈顿距离,求连接所有点的最小成本。
分析:这是一道完全图的MST问题,任意两点之间都存在边。如果显式构建所有$O(V^2)$条边再用Kruskal,空间和时间都可能超限。更优的方法是使用Prim算法,隐式计算边的权重。
class Solution {
public int minCostConnectPoints(int[][] points) {
int n = points.length;
int[] minDist = new int[n];
boolean[] visited = new boolean[n];
Arrays.fill(minDist, Integer.MAX_VALUE);
int totalCost = 0;
minDist[0] = 0; // 从点0开始
for (int i = 0; i < n; i++) {
// 找到距离最小的未访问点
int u = -1;
for (int j = 0; j < n; j++) {
if (!visited[j] && (u == -1 || minDist[j] < minDist[u])) {
u = j;
}
}
visited[u] = true;
totalCost += minDist[u];
// 更新其他点的距离
for (int v = 0; v < n; v++) {
if (!visited[v]) {
int dist = Math.abs(points[u][0] - points[v][0])
+ Math.abs(points[u][1] - points[v][1]);
minDist[v] = Math.min(minDist[v], dist);
}
}
}
return totalCost;
}
}
这道题使用朴素Prim($O(V^2)$)比优先队列版本($O(V^2 \log V)$)更快,因为完全图是典型的稠密图。
LeetCode 1489. Find Critical and Pseudo-Critical Edges in MST
题目描述:找出图中所有的"关键边"(必须在所有MST中出现的边)和"伪关键边"(在至少一棵MST中出现但非关键的边)。
分析:这是一道MST的进阶题目,需要深入理解边的性质。
关键边:删除该边后,MST的权重增加(或图不连通)。判断方法是:计算原图MST权重$W$,删除该边后重新计算MST权重$W'$,若$W' > W$或图不连通,则为关键边。
伪关键边:不是关键边,但存在于某棵MST中。判断方法是:强制先选该边,再按Kruskal继续,若最终权重等于$W$,则为伪关键边。
class Solution {
public List<List<Integer>> findCriticalAndPseudoCriticalEdges(int n, int[][] edges) {
int m = edges.length;
int[][] edgesWithIndex = new int[m][4];
for (int i = 0; i < m; i++) {
edgesWithIndex[i][0] = edges[i][0];
edgesWithIndex[i][1] = edges[i][1];
edgesWithIndex[i][2] = edges[i][2];
edgesWithIndex[i][3] = i; // 保存原始索引
}
Arrays.sort(edgesWithIndex, (a, b) -> a[2] - b[2]);
int mstWeight = kruskal(n, edgesWithIndex, -1, -1);
List<Integer> critical = new ArrayList<>();
List<Integer> pseudoCritical = new ArrayList<>();
for (int i = 0; i < m; i++) {
int idx = edgesWithIndex[i][3];
// 删除该边后计算MST
if (kruskal(n, edgesWithIndex, i, -1) > mstWeight) {
critical.add(idx);
} else if (kruskal(n, edgesWithIndex, -1, i) == mstWeight) {
pseudoCritical.add(idx);
}
}
return Arrays.asList(critical, pseudoCritical);
}
private int kruskal(int n, int[][] edges, int skipEdge, int mustInclude) {
UnionFind uf = new UnionFind(n);
int weight = 0;
if (mustInclude != -1) {
weight += edges[mustInclude][2];
uf.union(edges[mustInclude][0], edges[mustInclude][1]);
}
for (int i = 0; i < edges.length; i++) {
if (i == skipEdge || i == mustInclude) continue;
if (uf.union(edges[i][0], edges[i][1])) {
weight += edges[i][2];
}
}
return uf.count == 1 ? weight : Integer.MAX_VALUE;
}
}
LeetCode 1579. Remove Max Number of Edges to Keep Graph Fully Traversable
题目描述:图中有三种类型的边:Alice独占、Bob独占、两人共用。求最多能删除多少条边,使得删除后Alice和Bob各自都能遍历全图。
分析:这道题将MST问题与"两个人的图"结合。核心思路是:
- 优先处理共用边(类型3),因为它们对两人都有用
- 分别为Alice和Bob构建MST,统计需要保留的边
class Solution {
public int maxNumEdgesToRemove(int n, int[][] edges) {
// 按类型降序排序,优先处理类型3(共用边)
Arrays.sort(edges, (a, b) -> b[0] - a[0]);
UnionFind alice = new UnionFind(n);
UnionFind bob = new UnionFind(n);
int usedEdges = 0;
for (int[] edge : edges) {
int type = edge[0];
int u = edge[1] - 1, v = edge[2] - 1;
if (type == 3) {
// 共用边:两人都需要
boolean a = alice.union(u, v);
boolean b = bob.union(u, v);
if (a || b) usedEdges++;
} else if (type == 1) {
// Alice独占
if (alice.union(u, v)) usedEdges++;
} else {
// Bob独占
if (bob.union(u, v)) usedEdges++;
}
}
// 检查两人是否都能遍历全图
if (alice.components != 1 || bob.components != 1) {
return -1;
}
return edges.length - usedEdges;
}
}
class UnionFind {
int[] parent, rank;
int components;
UnionFind(int n) {
parent = new int[n];
rank = new int[n];
components = n;
for (int i = 0; i < n; i++) parent[i] = i;
}
int find(int x) {
if (parent[x] != x) parent[x] = find(parent[x]);
return parent[x];
}
boolean union(int x, int y) {
int px = find(x), py = find(y);
if (px == py) return false;
if (rank[px] < rank[py]) parent[px] = py;
else if (rank[px] > rank[py]) parent[py] = px;
else { parent[py] = px; rank[px]++; }
components--;
return true;
}
}
从历史看算法演进
最小生成树问题的研究历史本身就是一段有趣的学术故事。
1926年,捷克数学家Otakar Borůvka在研究如何高效地为摩拉维亚地区铺设电网时,提出了第一个MST算法——Borůvka算法。这个算法的思路是:每个顶点初始独立,每轮每个连通分量选择连向其他分量的最小权边,然后合并。时间复杂度$O(E \log V)$,适合并行化。
1930年,捷克数学家Vojtěch Jarník提出了后来被称为Prim算法的方法,但直到1957年才由Robert C. Prim独立重新发现并推广。
1956年,Joseph Kruskal在美国贝尔实验室工作期间提出了Kruskal算法。有趣的是,Kruskal和Prim都在贝尔实验室工作,他们的工作推动了图论在通信网络设计中的应用。
这三种算法虽然策略不同,但都基于贪心思想,且都可以通过切分定理或环性质证明正确性。这体现了数学之美:同一个问题可以有多种优雅的解法,而它们的正确性往往源于同一个本质原理。
参考引用
- Kruskal, J. B. (1956). “On the shortest spanning subtree of a graph and the traveling salesman problem”. Proceedings of the American Mathematical Society. 7: 48–50.
- Prim, R. C. (1957). “Shortest connection networks and some generalizations”. Bell System Technical Journal. 36 (6): 1389–1401.
- Graham, R. L.; Hell, P. (1985). “On the History of the Minimum Spanning Tree Problem”. Annals of the History of Computing. 7 (1): 43–57.
- Sedgewick, R.; Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley. Section 4.3: Minimum Spanning Trees.
- Cormen, T. H.; Leiserson, C. E.; Rivest, R. L.; Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press. Chapter 23: Minimum Spanning Trees.