假设你正在开发一个社交网络应用,需要实时回答"用户A和用户B是否在同一个社交圈内"这类查询——用户之间可以通过好友关系不断形成更大的圈子。每添加一个好友关系,圈子就可能合并;每查询一次,就需要判断两个用户是否已经连通。如果用传统的图遍历方法,每次查询都可能需要遍历整个图,当用户量达到百万级别时,系统会变得极其缓慢。
并查集(Disjoint Set Union,简称DSU)正是为这类"动态连通性"问题而生的数据结构。它用近乎常数时间 $O(\alpha(n))$ 完成合并和查询操作,其中 $\alpha(n)$ 是增长极慢的反阿克曼函数——对于现实中可能出现的任何 $n$ 值,$\alpha(n)$ 都不会超过4。
并查集的核心思想:用树表示集合
并查集将每个集合表示为一棵树,树的根节点作为集合的"代表"。两个元素属于同一集合,当且仅当它们的根节点相同。
初始时,每个元素自成一体,既是根节点也是自己的父节点。当需要合并两个集合时,只需将一棵树的根节点指向另一棵树的根节点。查询时,沿着父指针一直向上找,直到到达根节点。
这个朴素实现存在一个致命问题:树可能退化成链表。如果总是将较大的集合挂在较小的集合下面,树的深度会线性增长,导致 find 操作退化为 $O(n)$。
两种优化:路径压缩与按秩合并
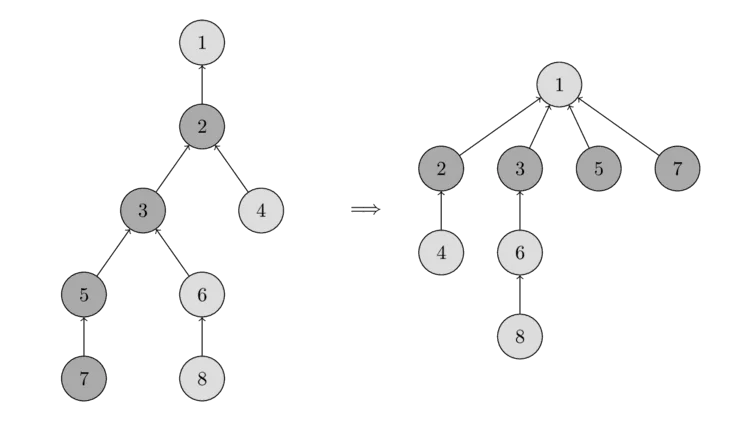
路径压缩:扁平化查询路径
路径压缩的核心思想是:在执行 find(x) 时,顺便将查询路径上的所有节点直接连向根节点。这样下次查询这些节点时,只需一步就能到达根节点。
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 递归压缩
}
return parent[x];
}
单用路径压缩,最坏时间复杂度为 $O(m \log n)$,其中 $m$ 是操作次数,$n$ 是元素个数。但结合按秩合并后,时间复杂度将进一步优化。
按秩合并:控制树的高度
按秩合并(Union by Rank)在合并两个集合时,总是将较矮的树挂在较高的树下面。“秩”(rank)是树高度的上界,初始为0。合并时:
- 如果两棵树的秩不同,秩小的挂在秩大的下面,秩不变
- 如果秩相同,任意选择一棵挂在另一棵下面,新根的秩加1
public boolean union(int x, int y) {
int px = find(x), py = find(y);
if (px == py) return false; // 已经在同一集合
// 按秩合并
if (rank[px] < rank[py]) {
int temp = px; px = py; py = temp;
}
parent[py] = px;
if (rank[px] == rank[py]) {
rank[px]++;
}
return true;
}
单独使用按秩合并,find 操作的最坏时间复杂度为 $O(\log n)$。
两种优化结合:近乎常数时间
当路径压缩与按秩合并结合时,时间复杂度达到理论最优:$O(m \cdot \alpha(n))$,其中 $\alpha(n)$ 是反阿克曼函数。
阿克曼函数 $A(m, n)$ 增长极快,其反函数 $\alpha(n)$ 增长极慢:
- $\alpha(1) = 1$
- $\alpha(10) = 2$
- $\alpha(100) = 3$
- $\alpha(10^{80}) = 4$(宇宙原子数量级)
这意味着在实际应用中,每个操作都可以视为常数时间。
完整Java实现模板
class UnionFind {
private int[] parent;
private int[] rank;
private int components;
public UnionFind(int n) {
parent = new int[n];
rank = new int[n];
components = n;
for (int i = 0; i < n; i++) {
parent[i] = i; // 初始时每个元素自成一派
}
}
// 查找根节点,带路径压缩
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
// 合并两个集合,带按秩合并
public boolean union(int x, int y) {
int px = find(x), py = find(y);
if (px == py) return false;
if (rank[px] < rank[py]) {
int temp = px; px = py; py = temp;
}
parent[py] = px;
if (rank[px] == rank[py]) {
rank[px]++;
}
components--;
return true;
}
// 判断两个元素是否连通
public boolean connected(int x, int y) {
return find(x) == find(y);
}
// 获取连通分量数量
public int countComponents() {
return components;
}
}
时间复杂度的直观理解
为何两种优化结合能达到近乎 $O(1)$?关键在于"摊还分析"的思想。
考虑一个节点,每次被压缩后,它的父节点秩至少增加1。由于秩最多为 $\log n$,一个节点被压缩的次数有限。所有节点的压缩次数加起来,分摊到 $m$ 次操作上,每次操作的平均代价就是 $O(\alpha(n))$。
更直观的理解:随着操作进行,树变得越来越扁平,越来越多的节点直接连向根节点。最终,几乎所有 find 操作都是常数时间。
LeetCode并查集题目分类
| 类别 | 题目编号 | 难度 | 核心技巧 |
|---|---|---|---|
| 连通分量计数 | 547, 1319 | Medium | 统计根节点数量 |
| 环检测 | 684, 685 | Medium/Hard | union返回false即发现环 |
| 账户合并 | 721 | Medium | 邮箱→账户映射 |
| 等式/不等式 | 990, 737 | Medium | 先处理等式,再验证不等式 |
| 交换操作 | 1202, 1722 | Medium/Hard | 连通分量内排序 |
| 网格问题 | 765, 947, 803 | Hard | 坐标映射到节点 |
| 离线查询 | 1697, 1724, 2503 | Medium/Hard | 按限制排序后处理 |
| 公因数分组 | 952 | Hard | 质因数分解后连接 |
| 最小生成树相关 | 1584, 1579 | Medium | Kruskal算法 |
经典题目详解
LeetCode 547. Number of Provinces(省份数量)
题目描述:给定 $n$ 个城市组成的矩阵 isConnected,其中 isConnected[i][j]=1 表示城市 $i$ 和 $j$ 直接相连。省份是一组直接或间接相连的城市。返回省份数量。
解题思路:这是一道标准的连通分量计数问题。遍历矩阵,将相连的城市合并。最终连通分量数量即为省份数。
class Solution {
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionFind uf = new UnionFind(n);
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (isConnected[i][j] == 1) {
uf.union(i, j);
}
}
}
return uf.countComponents();
}
}
复杂度分析:时间复杂度 $O(n^2 \cdot \alpha(n))$,空间复杂度 $O(n)$。
LeetCode 684. Redundant Connection(冗余连接)
题目描述:在原本是一棵树的无向图中添加一条边,找出可以删除的边,使剩余图成为一棵树。如果有多个答案,返回最后出现的边。
解题思路:依次处理每条边,尝试合并两个端点。如果某条边的两个端点已经在同一集合中,说明这条边会形成环——这就是要删除的边。
class Solution {
public int[] findRedundantConnection(int[][] edges) {
int n = edges.length;
UnionFind uf = new UnionFind(n + 1);
for (int[] edge : edges) {
if (!uf.union(edge[0], edge[1])) {
return edge; // union失败说明形成环
}
}
return new int[0];
}
}
关键洞察:union 方法返回 false 时,意味着两个节点已经在同一连通分量中,新边必然形成环。
LeetCode 721. Accounts Merge(账户合并)
题目描述:给定多个账户,每个账户包含一个名字和若干邮箱。如果两个账户有共同邮箱,则它们属于同一个人。合并后返回每个用户的所有邮箱(按字典序排列)。
解题思路:建立邮箱到账户索引的映射。遇到已存在的邮箱时,合并两个账户。最后收集每个连通分量的邮箱。
class Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
int n = accounts.size();
UnionFind uf = new UnionFind(n);
Map<String, Integer> emailToIndex = new HashMap<>();
// 建立邮箱->账户索引的映射,并合并账户
for (int i = 0; i < n; i++) {
List<String> account = accounts.get(i);
for (int j = 1; j < account.size(); j++) {
String email = account.get(j);
if (emailToIndex.containsKey(email)) {
uf.union(i, emailToIndex.get(email));
} else {
emailToIndex.put(email, i);
}
}
}
// 收集每个连通分量的邮箱
Map<Integer, TreeSet<String>> merged = new HashMap<>();
for (int i = 0; i < n; i++) {
int root = uf.find(i);
merged.computeIfAbsent(root, k -> new TreeSet<>());
for (int j = 1; j < accounts.get(i).size(); j++) {
merged.get(root).add(accounts.get(i).get(j));
}
}
// 构建结果
List<List<String>> result = new ArrayList<>();
for (Map.Entry<Integer, TreeSet<String>> entry : merged.entrySet()) {
List<String> account = new ArrayList<>();
account.add(accounts.get(entry.getKey()).get(0)); // 名字
account.addAll(entry.getValue()); // 邮箱
result.add(account);
}
return result;
}
}
技巧:使用 TreeSet 自动排序并去重。
LeetCode 990. Satisfiability of Equality Equations(等式方程的可满足性)
题目描述:给定一系列等式和不等式方程(如 "a==b", "b!=c"),判断是否所有方程都能同时满足。
解题思路:第一遍处理所有等式,将相等的字母合并。第二遍检查所有不等式,如果两个字母在同一集合中,则矛盾。
class Solution {
public boolean equationsPossible(String[] equations) {
UnionFind uf = new UnionFind(26);
// 第一遍:处理等式
for (String eq : equations) {
if (eq.charAt(1) == '=') {
int x = eq.charAt(0) - 'a';
int y = eq.charAt(3) - 'a';
uf.union(x, y);
}
}
// 第二遍:验证不等式
for (String eq : equations) {
if (eq.charAt(1) == '!') {
int x = eq.charAt(0) - 'a';
int y = eq.charAt(3) - 'a';
if (uf.connected(x, y)) {
return false;
}
}
}
return true;
}
}
LeetCode 765. Couples Holding Noses(情侣牵手)
题目描述:$N$ 对情侣坐在 $2N$ 个座位上(排成一排)。座位编号 0, 1 是一对情侣,2, 3 是一对,以此类推。计算最少交换次数使每对情侣坐在一起。
解题思路:对于每对情侣,如果他们没有坐在一起,就用并查集将他们连接。每个连通分量的交换次数为分量大小减1。
class Solution {
public int minSwapsCouples(int[] row) {
int n = row.length / 2;
UnionFind uf = new UnionFind(n);
for (int i = 0; i < n; i++) {
int a = row[2 * i] / 2; // 第一人的情侣编号
int b = row[2 * i + 1] / 2; // 第二人的情侣编号
uf.union(a, b);
}
// 交换次数 = N - 连通分量数
return n - uf.countComponents();
}
}
关键洞察:情侣编号 id = person / 2。每个座位对如果坐的不是一对情侣,就用并查集连接这两对情侣。最终交换次数等于 $N$ 减去连通分量数。
LeetCode 947. Most Stones Removed with Same Row or Column(移除最多的同行或同列石头)
题目描述:在二维平面上放置若干石头,每次可以移除一块石头,条件是该行或该列还有其他石头。求最多能移除多少块石头。
解题思路:同行或同列的石头属于同一连通分量。每个连通分量最终只能留一块石头,所以答案为总石头数减去连通分量数。
class Solution {
public int removeStones(int[][] stones) {
int n = stones.length;
UnionFind uf = new UnionFind(n);
// 按行分组
Map<Integer, Integer> rowMap = new HashMap<>();
// 按列分组
Map<Integer, Integer> colMap = new HashMap<>();
for (int i = 0; i < n; i++) {
int row = stones[i][0];
int col = stones[i][1];
if (rowMap.containsKey(row)) {
uf.union(i, rowMap.get(row));
} else {
rowMap.put(row, i);
}
if (colMap.containsKey(col)) {
uf.union(i, colMap.get(col));
} else {
colMap.put(col, i);
}
}
return n - uf.countComponents();
}
}
LeetCode 952. Largest Component Size by Common Factor(按公因数计算最大连通分量)
题目描述:给定数组,两个数如果有大于1的公因数则连通。求最大连通分量的大小。
解题思路:将每个数与它的所有质因数相连。两个数有公因数等价于它们连向了同一个质因数。
class Solution {
public int largestComponentSize(int[] nums) {
int maxNum = 0;
for (int num : nums) {
maxNum = Math.max(maxNum, num);
}
UnionFind uf = new UnionFind(maxNum + 1);
for (int num : nums) {
// 将num与其所有质因数相连
for (int factor = 2; factor * factor <= num; factor++) {
if (num % factor == 0) {
uf.union(num, factor);
uf.union(num, num / factor);
}
}
}
// 统计每个连通分量的大小
Map<Integer, Integer> count = new HashMap<>();
int maxSize = 0;
for (int num : nums) {
int root = uf.find(num);
count.put(root, count.getOrDefault(root, 0) + 1);
maxSize = Math.max(maxSize, count.get(root));
}
return maxSize;
}
}
LeetCode 1697. Checking Existence of Edge Length Limited Paths(检查边长度限制路径是否存在)
题目描述:给定无向图和若干查询 (u, v, limit),判断是否存在从 $u$ 到 $v$ 的路径,使得路径上所有边权重都小于 limit。
解题思路:离线处理。将边按权重排序,查询按 limit 排序。逐个处理查询,将权重小于 limit 的边加入并查集,然后判断连通性。
class Solution {
public boolean[] distanceLimitedPathsExist(int n, int[][] edgeList, int[][] queries) {
// 查询需要保留原始索引
int m = queries.length;
int[][] indexedQueries = new int[m][4];
for (int i = 0; i < m; i++) {
indexedQueries[i] = new int[]{queries[i][0], queries[i][1], queries[i][2], i};
}
// 按权重/限制排序
Arrays.sort(edgeList, (a, b) -> a[2] - b[2]);
Arrays.sort(indexedQueries, (a, b) -> a[2] - b[2]);
UnionFind uf = new UnionFind(n);
boolean[] result = new boolean[m];
int edgeIdx = 0;
for (int[] query : indexedQueries) {
int u = query[0], v = query[1], limit = query[2], idx = query[3];
// 加入所有权重小于limit的边
while (edgeIdx < edgeList.length && edgeList[edgeIdx][2] < limit) {
uf.union(edgeList[edgeIdx][0], edgeList[edgeIdx][1]);
edgeIdx++;
}
result[idx] = uf.connected(u, v);
}
return result;
}
}
关键技巧:离线查询是并查集的经典应用场景,将在线问题转化为离线处理。
LeetCode 1202. Smallest String With Swaps(交换字符串中的字符)
题目描述:可以对若干位置对进行无限次交换,求能得到的字典序最小字符串。
解题思路:可以交换的位置对形成连通分量。在每个连通分量内,可以将字符任意排列,因此只需将字符排序后重新分配。
class Solution {
public String smallestStringWithSwaps(String s, List<List<Integer>> pairs) {
int n = s.length();
UnionFind uf = new UnionFind(n);
for (List<Integer> pair : pairs) {
uf.union(pair.get(0), pair.get(1));
}
// 收集每个连通分量的字符
Map<Integer, PriorityQueue<Character>> componentChars = new HashMap<>();
for (int i = 0; i < n; i++) {
int root = uf.find(i);
componentChars.computeIfAbsent(root, k -> new PriorityQueue<>())
.offer(s.charAt(i));
}
// 构建结果
StringBuilder sb = new StringBuilder();
for (int i = 0; i < n; i++) {
sb.append(componentChars.get(uf.find(i)).poll());
}
return sb.toString();
}
}
LeetCode 1319. Number of Operations to Make Network Connected(连通网络的操作次数)
题目描述:给定 $n$ 台计算机和若干连接线,计算最少需要操作几次才能使所有计算机连通(每次操作可以拔掉一根线重新连接)。
解题思路:如果连通线数量小于 $n-1$,则无法连通。否则,最少操作次数为连通分量数减1。
class Solution {
public int makeConnected(int n, int[][] connections) {
if (connections.length < n - 1) {
return -1; // 线不够
}
UnionFind uf = new UnionFind(n);
for (int[] conn : connections) {
uf.union(conn[0], conn[1]);
}
return uf.countComponents() - 1;
}
}
进阶技巧
带权并查集
有时需要在并查集中维护节点到根的"距离"或"权重"。关键是在路径压缩时正确更新权重。
class WeightedUnionFind {
private int[] parent;
private int[] rank;
private int[] weight; // 节点到父节点的权重
public WeightedUnionFind(int n) {
parent = new int[n];
rank = new int[n];
weight = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
public int[] find(int x) {
if (parent[x] != x) {
int[] result = find(parent[x]);
parent[x] = result[0];
weight[x] += result[1]; // 累加权重
}
return new int[]{parent[x], weight[x]};
}
public boolean union(int x, int y, int w) {
int[] px = find(x);
int[] py = find(y);
if (px[0] == py[0]) return false;
parent[py[0]] = px[0];
weight[py[0]] = w + px[1] - py[1];
return true;
}
}
可撤销并查集
某些场景需要撤销之前的 union 操作。这可以通过记录每次操作的变化来实现,但复杂度会增加。
刷题建议
入门顺序:547 → 684 → 990 → 721
进阶挑战:765 → 947 → 1202 → 1319
高难度:952 → 1697 → 803
并查集的魅力在于它的简洁与高效。一个不到20行的数据结构,却能将看似复杂的问题转化为简单的连通性判断。理解其核心思想后,你会发现它能解决的远不止图论问题——从网格岛屿计数到表达式验证,从账户合并到交换操作,并查集的身影无处不在。
参考资料
- Disjoint-set data structure - Wikipedia
- Disjoint Set Union - CP-Algorithms
- Union By Rank and Path Compression - GeeksforGeeks
- Disjoint Set Union (DSU)/Union-Find - A Complete Guide - LeetCode
- Tarjan, R. E. (1975). “Efficiency of a Good But Not Linear Set Union Algorithm”
- Galler, B. A., & Fischer, M. J. (1964). “An Improved Equivalence Algorithm”