假设你在搜索引擎输入框里键入"goog",下拉列表立刻弹出"google"、“google maps”、“google translate"等一系列建议。这些结果是怎么在毫秒级时间内出现的?如果用哈希表存储所有可能的搜索词,每次按键都需要遍历整个哈希表来找出以当前输入为前缀的词——当词库达到百万级别时,这种做法显然不可行。
字典树(Trie)正是为这类问题而生的数据结构。它的核心思想非常朴素:让共享相同前缀的单词共享相同的存储路径。当你输入"goog"时,系统只需要沿着这条路径走到"goog"对应的节点,然后收集该节点下方的所有单词即可——无需任何全量扫描。
从一个直观例子开始
假设我们要存储五个单词:dog、dot、pump、fat、fire。如果用哈希表,每个单词独立存储,没有任何复用。但用字典树,它们的存储方式是这样的:
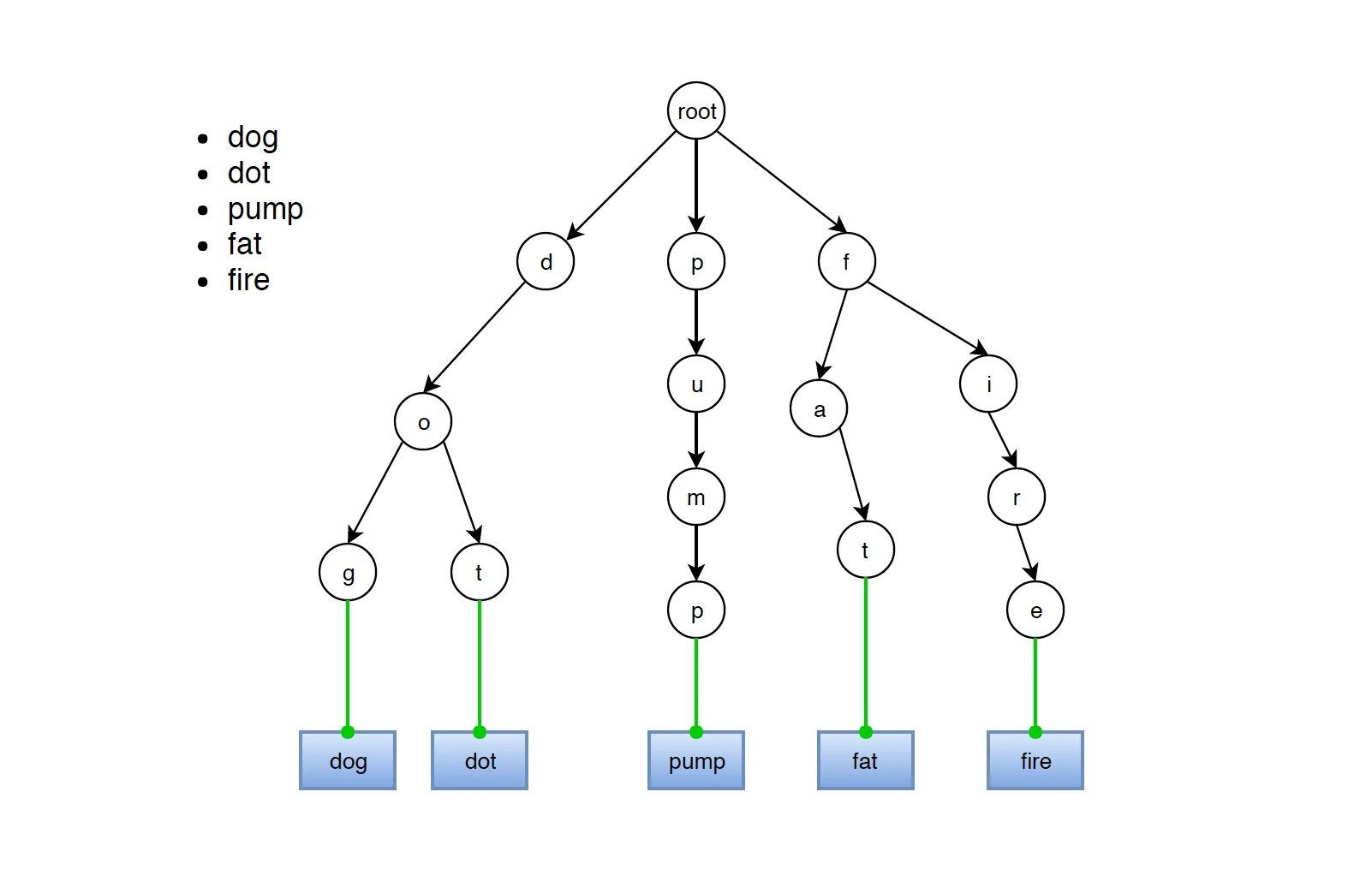
图片来源: jojozhuang.github.io
图中可以清晰看到:dog 和 dot 共享了前缀 do,fat 和 fire 共享了前缀 f。这种共享不是"逻辑上的”,而是"物理上的"——它们在内存中真正共用同一组节点。当词库中存在大量共享前缀的单词时(比如英语词典),字典树能节省可观的存储空间。
更关键的是,无论词库中有多少单词,查询单词的时间复杂度只取决于单词长度,而非词库大小。这是字典树与哈希表、二叉搜索树的根本区别。
字典树的本质:路径即前缀
字典树(Trie),又称前缀树(Prefix Tree),是一种专门为字符串设计的树形数据结构。1960年,麻省理工学院的 Edward Fredkin 在论文《Trie Memory》中首次正式提出这一概念。“Trie"这个名称来源于 “retrieval”(检索),Fredkin 最初的发音意图是 /triː/(与 “tree” 同音),以强调其作为检索树的定位。但随着时间推移,大多数程序员更习惯将其发音为 /traɪ/(与 “try” 同音),以区别于通用的 “tree” 概念。
字典树的每个节点代表一个字符,从根节点到任意节点的路径代表一个字符串前缀。如果一个节点被标记为"单词结尾”,则从根到该节点的路径构成一个完整的单词。
节点结构
字典树节点的设计取决于字符集大小。对于只包含小写字母的场景:
class TrieNode {
TrieNode[] children; // 26个子节点指针
boolean isEnd; // 是否为单词结尾
public TrieNode() {
children = new TrieNode[26];
isEnd = false;
}
}
如果字符集更大或不确定(比如支持Unicode),可以用哈希表替代数组:
class TrieNode {
Map<Character, TrieNode> children;
boolean isEnd;
public TrieNode() {
children = new HashMap<>();
isEnd = false;
}
}
这两种实现各有优劣:数组实现访问速度更快($O(1)$ 直接索引),但空间开销固定为 26 个指针;哈希表实现更灵活、更省空间,但每次访问需要计算哈希值。
核心操作的时间复杂度分析
字典树的核心优势在于其操作的时间复杂度与词库大小无关,只与单词长度相关。
设 $L$ 为单词长度,$N$ 为词库大小:
| 操作 | 字典树 | 哈希表 | 二叉搜索树 |
|---|---|---|---|
| 插入 | $O(L)$ | $O(L)$ 平均 | $O(L \log N)$ |
| 精确查找 | $O(L)$ | $O(L)$ 平均 | $O(L \log N)$ |
| 前缀查找 | $O(L)$ | $O(N \cdot L)$ | 不支持 |
| 字典序遍历 | $O(N \cdot L)$ | $O(N \log N)$ | $O(N)$ |
哈希表虽然精确查找也是 $O(L)$,但它无法高效支持前缀查找——这正是字典树的核心价值所在。对于"找出所有以’goog’开头的单词"这类查询,字典树只需要先定位到"goog"节点,然后遍历其子树即可;而哈希表必须扫描所有键值对。
空间复杂度方面,字典树的最坏情况是 $O(26^L)$(当所有单词没有任何共享前缀时),但实际上,由于自然语言中大量存在共享前缀,实际空间消耗往往远小于理论最坏值。
LeetCode 字典树题目全景
字典树在 LeetCode 上有丰富的应用场景,从基础的实现题到复杂的综合题:
| 题目编号 | 题目名称 | 核心考点 |
|---|---|---|
| 208 | Implement Trie (Prefix Tree) | 基础实现 |
| 211 | Design Add and Search Words | 通配符搜索 |
| 212 | Word Search II | Trie + DFS 回溯 |
| 421 | Maximum XOR of Two Numbers | 位运算 Trie |
| 648 | Replace Words | 前缀替换 |
| 676 | Implement Magic Dictionary | 编辑距离 |
| 677 | Map Sum Pairs | 带权 Trie |
| 720 | Longest Word in Dictionary | 逐步构建 |
| 745 | Prefix and Suffix Search | 双向 Trie |
| 1032 | Stream of Characters | 反向 Trie |
| 1268 | Search Suggestions System | 自动补全 |
LeetCode 208. Implement Trie (Prefix Tree)
这是字典树最基础的实现题目,要求实现 insert、search 和 startsWith 三个方法。
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEnd = true;
}
public boolean search(String word) {
TrieNode node = searchPrefix(word);
return node != null && node.isEnd;
}
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private TrieNode searchPrefix(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
return null;
}
node = node.children[idx];
}
return node;
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isEnd = false;
}
复杂度分析:插入和查找的时间复杂度均为 $O(L)$,其中 $L$ 是单词长度。空间复杂度为 $O(26 \times L \times N)$,其中 $N$ 是单词总数。
LeetCode 211. Design Add and Search Words Data Structure
这道题引入了通配符 . 的概念,. 可以匹配任意字母。
class WordDictionary {
private TrieNode root;
public WordDictionary() {
root = new TrieNode();
}
public void addWord(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEnd = true;
}
public boolean search(String word) {
return searchInNode(word, 0, root);
}
private boolean searchInNode(String word, int index, TrieNode node) {
if (index == word.length()) {
return node.isEnd;
}
char c = word.charAt(index);
if (c == '.') {
// 通配符:尝试所有可能的子节点
for (TrieNode child : node.children) {
if (child != null && searchInNode(word, index + 1, child)) {
return true;
}
}
return false;
} else {
int idx = c - 'a';
if (node.children[idx] == null) {
return false;
}
return searchInNode(word, index + 1, node.children[idx]);
}
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isEnd = false;
}
核心思路:遇到通配符时,需要递归尝试所有非空子节点。这种回溯搜索使得最坏时间复杂度上升到 $O(26^L)$,但对于正常的搜索词,效率仍然是 $O(L)$。
LeetCode 212. Word Search II
这道题将字典树与二维网格搜索结合,是字典树应用的经典案例。
题目描述:给定一个二维字符网格和一个单词列表,找出网格中所有能够构成的单词。单词必须按字母顺序通过相邻单元格构成,每个单元格最多使用一次。
解题思路:将所有单词构建成字典树,然后从网格的每个位置出发进行 DFS 搜索。当搜索路径匹配字典树中的某个节点时,检查是否构成完整单词。
class Solution {
private static final int[][] DIRS = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
public List<String> findWords(char[][] board, String[] words) {
List<String> result = new ArrayList<>();
TrieNode root = buildTrie(words);
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[0].length; j++) {
dfs(board, i, j, root, result);
}
}
return result;
}
private void dfs(char[][] board, int i, int j, TrieNode node, List<String> result) {
char c = board[i][j];
if (c == '#' || node.children[c - 'a'] == null) return;
node = node.children[c - 'a'];
if (node.word != null) {
result.add(node.word);
node.word = null; // 避免重复添加
}
board[i][j] = '#'; // 标记已访问
for (int[] dir : DIRS) {
int ni = i + dir[0], nj = j + dir[1];
if (ni >= 0 && ni < board.length && nj >= 0 && nj < board[0].length) {
dfs(board, ni, nj, node, result);
}
}
board[i][j] = c; // 恢复
}
private TrieNode buildTrie(String[] words) {
TrieNode root = new TrieNode();
for (String word : words) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.word = word; // 在节点存储完整单词
}
return root;
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
String word; // 如果是单词结尾,存储完整单词
}
复杂度分析:假设网格大小为 $M \times N$,单词平均长度为 $L$,单词总数为 $K$。构建字典树 $O(K \cdot L)$,DFS 搜索最坏 $O(M \cdot N \cdot 4^L)$,但由于字典树的剪枝作用,实际效率远优于暴力解法。
LeetCode 421. Maximum XOR of Two Numbers in an Array
这道题展示了字典树在非字符串场景的应用。
题目描述:给定整数数组,找出其中两个数的异或值最大。
解题思路:将每个数的二进制表示存入字典树(高位在前)。对于每个数,尽可能选择与当前位不同的分支,这样异或结果该位为 1。
class Solution {
private static class TrieNode {
TrieNode[] children = new TrieNode[2];
}
public int findMaximumXOR(int[] nums) {
int maxNum = 0;
for (int num : nums) maxNum = Math.max(maxNum, num);
if (maxNum == 0) return 0;
int maxBit = 31 - Integer.numberOfLeadingZeros(maxNum);
TrieNode root = new TrieNode();
// 构建字典树
for (int num : nums) {
TrieNode node = root;
for (int i = maxBit; i >= 0; i--) {
int bit = (num >> i) & 1;
if (node.children[bit] == null) {
node.children[bit] = new TrieNode();
}
node = node.children[bit];
}
}
// 计算最大异或值
int maxXOR = 0;
for (int num : nums) {
TrieNode node = root;
int curXOR = 0;
for (int i = maxBit; i >= 0; i--) {
int bit = (num >> i) & 1;
int toggleBit = 1 - bit; // 期望的相反位
if (node.children[toggleBit] != null) {
curXOR |= (1 << i);
node = node.children[toggleBit];
} else {
node = node.children[bit];
}
}
maxXOR = Math.max(maxXOR, curXOR);
}
return maxXOR;
}
}
核心洞察:异或运算的特性是"相同为0,不同为1"。要使异或值最大,应尽量让高位为1。字典树天然支持"贪心选择"——在每一层选择与当前位相反的分支。
LeetCode 648. Replace Words
题目描述:给定词根词典和一个句子,将句子中每个单词替换为其最短词根(如果存在词根)。
class Solution {
public String replaceWords(List<String> dictionary, String sentence) {
TrieNode root = new TrieNode();
// 构建字典树
for (String word : dictionary) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEnd = true;
}
// 替换单词
String[] words = sentence.split(" ");
StringBuilder result = new StringBuilder();
for (int i = 0; i < words.length; i++) {
if (i > 0) result.append(" ");
result.append(findRoot(words[i], root));
}
return result.toString();
}
private String findRoot(String word, TrieNode root) {
TrieNode node = root;
StringBuilder sb = new StringBuilder();
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
return word; // 没有词根,返回原词
}
sb.append(c);
node = node.children[idx];
if (node.isEnd) {
return sb.toString(); // 找到最短词根
}
}
return word;
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isEnd = false;
}
关键点:查找时一旦遇到词根结尾就立即返回,保证返回的是最短词根。
LeetCode 677. Map Sum Pairs
题目描述:实现一个带权字典树,支持插入键值对和前缀求和。
class MapSum {
private TrieNode root;
private Map<String, Integer> map; // 存储键值对,用于更新
public MapSum() {
root = new TrieNode();
map = new HashMap<>();
}
public void insert(String key, int val) {
int delta = val - map.getOrDefault(key, 0);
map.put(key, val);
TrieNode node = root;
for (char c : key.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
node.sum += delta; // 更新路径上所有节点的sum
}
}
public int sum(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
return 0;
}
node = node.children[idx];
}
return node.sum; // 返回该节点的sum
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
int sum = 0; // 以该节点为前缀的所有单词的值之和
}
技巧:每个节点存储 sum,表示以该节点对应前缀的所有单词的值之和。插入时更新路径上所有节点的 sum,查询时直接返回目标节点的 sum。
LeetCode 720. Longest Word in Dictionary
题目描述:找出词典中最长的单词,要求该单词可以逐字母构建(即每个前缀都存在于词典中)。
class Solution {
private String result = "";
public String longestWord(String[] words) {
TrieNode root = new TrieNode();
// 构建字典树
for (String word : words) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEnd = true;
}
// DFS查找最长单词
dfs(root, new StringBuilder());
return result;
}
private void dfs(TrieNode node, StringBuilder path) {
for (int i = 0; i < 26; i++) {
if (node.children[i] != null && node.children[i].isEnd) {
// 只有当前缀也是完整单词时才继续
path.append((char) ('a' + i));
if (path.length() > result.length() ||
(path.length() == result.length() && path.toString().compareTo(result) < 0)) {
result = path.toString();
}
dfs(node.children[i], path);
path.deleteCharAt(path.length() - 1);
}
}
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isEnd = false;
}
核心逻辑:DFS 遍历字典树,只有当子节点对应的前缀是完整单词时才继续深入。这确保了最终找到的单词可以逐字母构建。
LeetCode 1268. Search Suggestions System
题目描述:模拟搜索建议系统,每输入一个字符返回最多三个匹配建议。
class Solution {
public List<List<String>> suggestedProducts(String[] products, String searchWord) {
Arrays.sort(products); // 排序保证字典序
TrieNode root = new TrieNode();
// 构建字典树,每个节点存储最多3个建议
for (String product : products) {
TrieNode node = root;
for (char c : product.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
if (node.suggestions.size() < 3) {
node.suggestions.add(product);
}
}
}
// 收集每个前缀的建议
List<List<String>> result = new ArrayList<>();
TrieNode node = root;
for (char c : searchWord.toCharArray()) {
int idx = c - 'a';
if (node == null || node.children[idx] == null) {
result.add(new ArrayList<>());
node = null;
} else {
node = node.children[idx];
result.add(new ArrayList<>(node.suggestions));
}
}
return result;
}
}
class TrieNode {
TrieNode[] children = new TrieNode[26];
List<String> suggestions = new ArrayList<>();
}
优化思路:预先在每个节点存储最多三个建议,查询时直接返回。这避免了每次查询都要遍历子树的开销。
字典树的实际应用场景
自动补全与搜索建议
这是字典树最常见的应用。当用户在搜索框输入时,系统只需要沿字典树走到当前输入对应的节点,然后收集该节点下方的所有单词(或按某种规则排序后的前N个)。
IP 路由与最长前缀匹配
路由器需要根据数据包的目的IP地址查找路由表,找到匹配的下一跳。由于路由表中的路由可能是不同长度的前缀(如 192.168.0.0/16 和 192.168.1.0/24),路由器需要找到最长匹配的前缀。
字典树天然适合这类问题:将每个路由前缀按位存入字典树,查找时沿着匹配的路径走到底,最后遇到的有效路由就是最长匹配。
拼写检查与纠错
文字处理软件的拼写检查功能可以利用字典树快速判断一个单词是否存在于词典中。更进一步,可以通过字典树找出编辑距离最小的候选词作为纠错建议。
敏感词过滤
在UGC内容审核中,需要检测用户输入是否包含敏感词。将敏感词库构建成字典树后,可以高效地进行多模式匹配——一次遍历文本就能检测出所有敏感词。
字典树的变种与优化
压缩字典树(Radix Tree / Patricia Tree)
标准字典树的主要空间浪费在于"单分支路径"——一条路径上每个节点只有一个子节点。压缩字典树将这种路径压缩成一条边,边标签不再是单个字符,而是一个字符串片段。
压缩字典树的节点数等于单词数(而非字符总数),空间效率大幅提升,但实现复杂度也随之增加。
三叉搜索树(Ternary Search Tree)
三叉搜索树是字典树与二叉搜索树的结合体。每个节点存储一个字符,并有三个子指针:小于、等于、大于。这种结构在字符集较大时(如Unicode)比标准字典树更节省空间。
AC 自动机(Aho-Corasick Automaton)
AC自动机可以看作是字典树的扩展,用于多模式字符串匹配。它在字典树的基础上增加了"失败指针",使得匹配失败时可以跳转到另一个可能匹配的状态,而不需要从头开始。
AC自动机在敏感词过滤、入侵检测等场景有广泛应用,其时间复杂度为 $O(n + m + z)$,其中 $n$ 是文本长度,$m$ 是所有模式串的总长度,$z$ 是匹配总数。
字典树 vs 哈希表:如何选择?
哈希表在精确查找场景下效率极高(平均 $O(1)$),但它有几个局限性:
- 无法高效支持前缀查找:要找出所有以"goog"开头的单词,必须遍历所有键。
- 无法保持有序性:哈希表不维护键的顺序,无法直接按字典序遍历。
- 哈希冲突:虽然现代哈希函数冲突率很低,但在极端情况下仍可能影响性能。
字典树在这些方面都有优势,但它也有明显的劣势:
- 空间开销大:每个字符都需要一个节点,即使大量单词共享前缀,仍然可能有较高的空间消耗。
- 缓存不友好:树的节点分散在内存中,访问模式不如数组连续。
选择建议:如果只需要精确查找,哈希表通常是更好的选择;如果需要前缀查找、字典序遍历或处理大量共享前缀的字符串,字典树更具优势。
总结
字典树是一种以"空间换时间"为核心思想的数据结构。它通过让共享前缀的单词共享存储路径,将字符串检索的时间复杂度从与词库大小相关降低到只与单词长度相关。
掌握字典树的关键在于理解其核心操作——插入时构建路径,查询时沿路径行走。这个朴素的思想衍生出丰富的应用场景:从最基础的单词查找,到复杂的IP路由、敏感词过滤、多模式匹配。
在 LeetCode 刷题时,当遇到以下特征的问题时,应该考虑字典树:
- 涉及字符串的前缀匹配
- 需要高效判断多个字符串的公共前缀
- 需要按字典序处理字符串集合
- 二进制位的贪心匹配(如异或最值问题)
参考资料
- Fredkin, E. (1960). Trie Memory. Communications of the ACM, 3(9), 490-499.
- NIST. trie - Dictionary of Algorithms and Data Structures
- LeetCode. Trie Problems List
- GeeksforGeeks. Trie Data Structure
- Codecademy. Trie Data Structure: Complete Guide to Prefix Trees
- labuladong. Trie 核心原理和实现
- AlgoCademy. Understanding and Implementing Trie Data Structures
- Stanford CS. Tries and Lexicons