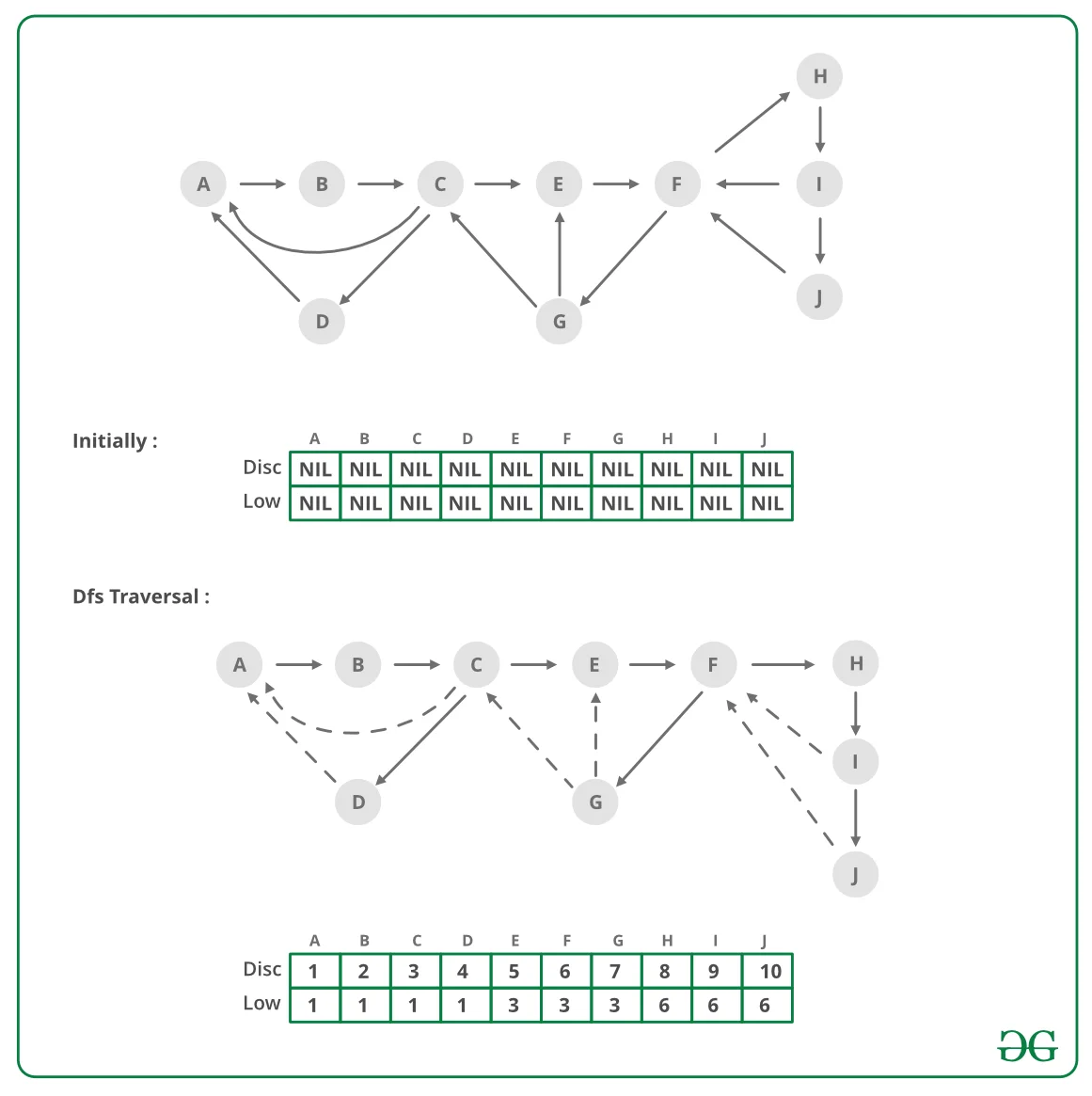
1972年,Robert Tarjan发表了一篇不到五页的论文,提出了一个用单次深度优先搜索求解强连通分量的算法。这个算法不仅解决了有向图的核心问题,其核心思想——发现时间戳与追溯值的配合——后来被证明能够统一解决割点、桥检测、2-SAT可满足性等四大图论难题。Donald Knuth称其为"我最喜欢的实现之一"。
一个算法,四种问题
Tarjan算法的精妙之处在于它定义了两个核心数组:
- disc[u](Discovery Time):节点 $u$ 被访问的时间戳
- low[u](Low-link Value):从 $u$ 出发,通过DFS树边和最多一条回边,能够到达的最早被发现的节点的时间戳
这两个数组的组合,构成了判断强连通分量、割点、桥的统一框架。让我们先看一个简单的有向图:
0 → 1 → 2
↑ ↓ ↓
└── 3 ← 4
当我们从节点0开始DFS,访问顺序为0→1→3→0(回边)、1→2→4→3(横跨边)。此时disc和low值分别为:
| 节点 | disc | low | 说明 |
|---|---|---|---|
| 0 | 1 | 1 | 强连通分量根 |
| 1 | 2 | 1 | 可追溯到0 |
| 2 | 3 | 3 | 单独成分量 |
| 3 | 4 | 1 | 可追溯到0 |
| 4 | 5 | 4 | 可追溯到3 |
当 disc[u] == low[u] 时,节点 $u$ 就是一个强连通分量的根。
强连通分量:Tarjan的核心贡献
算法原理
强连通分量的定义很直观:在有向图中,如果节点 $u$ 和 $v$ 互相可达,它们就属于同一个强连通分量。朴素方法需要对每个节点运行一次DFS或BFS,时间复杂度 $O(V(V+E))$。
Tarjan的突破在于认识到:DFS生成的搜索树中,每个强连通分量都是一棵子树。关键是如何找到这些子树的根。
算法维护一个栈,存储当前DFS路径上可能属于同一强连通分量的节点。当一个节点的所有后继都处理完毕后,如果 disc[u] == low[u],说明从 $u$ 无法到达更早发现的节点,$u$ 就是其所在强连通分量的根。此时弹出栈中所有节点直到 $u$,这些节点构成一个强连通分量。
public class TarjanSCC {
private int time;
private int[] disc, low;
private boolean[] onStack;
private Stack<Integer> stack;
private List<List<Integer>> sccs;
private List<List<Integer>> graph;
public List<List<Integer>> findSCCs(int n, int[][] edges) {
// 构建邻接表
graph = new ArrayList<>();
for (int i = 0; i < n; i++) graph.add(new ArrayList<>());
for (int[] e : edges) graph.get(e[0]).add(e[1]);
// 初始化
disc = new int[n];
low = new int[n];
onStack = new boolean[n];
stack = new Stack<>();
sccs = new ArrayList<>();
time = 0;
Arrays.fill(disc, -1);
// 对每个未访问节点运行DFS
for (int i = 0; i < n; i++) {
if (disc[i] == -1) dfs(i);
}
return sccs;
}
private void dfs(int u) {
disc[u] = low[u] = ++time;
stack.push(u);
onStack[u] = true;
for (int v : graph.get(u)) {
if (disc[v] == -1) {
// 树边:递归访问
dfs(v);
low[u] = Math.min(low[u], low[v]);
} else if (onStack[v]) {
// 回边:更新low值
low[u] = Math.min(low[u], disc[v]);
}
// 如果v不在栈中,说明v已经属于另一个强连通分量,忽略
}
// 如果u是强连通分量的根,弹出整个分量
if (low[u] == disc[u]) {
List<Integer> scc = new ArrayList<>();
int v;
do {
v = stack.pop();
onStack[v] = false;
scc.add(v);
} while (v != u);
sccs.add(scc);
}
}
}
为什么不用 low[v] 而用 disc[v] 更新回边?
这是一个常见的困惑点。当遇到一条回边 $u \to v$ 时,我们使用 disc[v] 而非 low[v] 来更新 low[u]。原因是:回边只能代表当前节点与某个祖先节点的关系,不能跨越强连通分量边界。
考虑以下场景:节点 $v$ 的 low[v] 可能很小(因为 $v$ 可以到达更早的节点),但如果 $v$ 已经不在栈中,说明 $v$ 属于另一个已识别的强连通分量。此时 $u$ 不能通过 $v$ 到达那个更早的节点。
与Kosaraju算法的对比
两种算法都能在 $O(V+E)$ 时间内求解强连通分量,但各有特点:
| 特性 | Tarjan | Kosaraju |
|---|---|---|
| DFS次数 | 1次 | 2次 |
| 空间需求 | 不需要转置图 | 需要存储转置图 |
| 实现复杂度 | 中等(需理解low值) | 简单直观 |
| 常数因子 | 更小 | 较大 |
| 扩展性 | 可统一解决割点、桥 | 仅适用于强连通分量 |
Tarjan算法的优势在于其统一框架——同样的 disc 和 low 概念可以扩展到无向图的割点和桥检测。
割点:无向图的脆弱节点
定义与直觉
割点(Articulation Point,也称割顶)是指无向图中删除该节点后连通分量增加的节点。换句话说,割点是图的"咽喉要道"。
在上图中,如果删除节点1,图就会分裂成多个连通分量。
判断条件
无向图中,节点 $u$ 是割点的条件有两个:
- $u$ 是DFS树的根:如果 $u$ 有两个或更多子树,则 $u$ 是割点
- $u$ 不是根:如果存在一个子节点 $v$,满足
low[v] >= disc[u],则 $u$ 是割点
第二个条件的含义是:子节点 $v$ 的子树中没有任何节点能够回到 $u$ 的祖先。如果删除 $u$,$v$ 的子树就会与图的其他部分断开。
public class ArticulationPoint {
private int time;
private int[] disc, low, parent;
private boolean[] visited, isAP;
private List<List<Integer>> graph;
public List<Integer> findArticulationPoints(int n, int[][] edges) {
// 构建无向图邻接表
graph = new ArrayList<>();
for (int i = 0; i < n; i++) graph.add(new ArrayList<>());
for (int[] e : edges) {
graph.get(e[0]).add(e[1]);
graph.get(e[1]).add(e[0]);
}
disc = new int[n];
low = new int[n];
parent = new int[n];
visited = new boolean[n];
isAP = new boolean[n];
time = 0;
Arrays.fill(parent, -1);
for (int i = 0; i < n; i++) {
if (!visited[i]) dfs(i);
}
List<Integer> result = new ArrayList<>();
for (int i = 0; i < n; i++) {
if (isAP[i]) result.add(i);
}
return result;
}
private void dfs(int u) {
visited[u] = true;
disc[u] = low[u] = ++time;
int children = 0;
for (int v : graph.get(u)) {
if (!visited[v]) {
children++;
parent[v] = u;
dfs(v);
low[u] = Math.min(low[u], low[v]);
// u是根且有多个子节点,或u不是根但low[v] >= disc[u]
if ((parent[u] == -1 && children > 1) ||
(parent[u] != -1 && low[v] >= disc[u])) {
isAP[u] = true;
}
} else if (v != parent[u]) {
// 回边
low[u] = Math.min(low[u], disc[v]);
}
}
}
}
根节点的特殊处理
根节点需要特殊处理的原因是:low[v] >= disc[root] 对根节点总是成立(因为 disc[root] = 1 是最小值)。所以对于根节点,我们直接检查它的子树数量。如果根节点只有一个子树,删除它并不会增加连通分量数量。
桥:删除就会断开的边
定义与判断条件
桥(Bridge)是指无向图中删除该边后连通分量增加的边。与割点类似,桥的判断也基于 low 和 disc 值。
边 $(u, v)$ 是桥的条件:low[v] > disc[u](注意是严格大于)
这个条件的含义是:从 $v$ 出发,无法通过任何其他路径回到 $u$ 或 $u$ 的祖先。因此,删除边 $(u, v)$ 会导致 $v$ 的子树与图的其他部分断开。
public class BridgeFinder {
private int time;
private int[] disc, low, parent;
private boolean[] visited;
private List<List<Integer>> bridges;
private List<List<Integer>> graph;
public List<List<Integer>> findBridges(int n, int[][] edges) {
graph = new ArrayList<>();
for (int i = 0; i < n; i++) graph.add(new ArrayList<>());
for (int[] e : edges) {
graph.get(e[0]).add(e[1]);
graph.get(e[1]).add(e[0]);
}
disc = new int[n];
low = new int[n];
parent = new int[n];
visited = new boolean[n];
bridges = new ArrayList<>();
time = 0;
Arrays.fill(parent, -1);
for (int i = 0; i < n; i++) {
if (!visited[i]) dfs(i);
}
return bridges;
}
private void dfs(int u) {
visited[u] = true;
disc[u] = low[u] = ++time;
for (int v : graph.get(u)) {
if (!visited[v]) {
parent[v] = u;
dfs(v);
low[u] = Math.min(low[u], low[v]);
// 桥的判断条件:low[v] > disc[u]
if (low[v] > disc[u]) {
bridges.add(Arrays.asList(u, v));
}
} else if (v != parent[u]) {
low[u] = Math.min(low[u], disc[v]);
}
}
}
}
割点与桥的关系
一个重要的事实:割点和桥之间存在密切关系,但不完全等价:
- 如果边 $(u, v)$ 是桥,则 $u$ 或 $v$ 中至少有一个是割点(除非它们都是度为1的叶子节点)
- 割点连接的边不一定是桥(割点可能通过多条边连接同一子树)
LeetCode 1192:网络中的关键连接
题目描述
给定一个由 $n$ 个服务器和它们之间的连接组成的网络,找出所有"关键连接"。关键连接是指删除后会使某些服务器无法到达其他服务器的连接。
这正是无向图中桥的定义。
完整Java解法
class Solution {
private int time;
private int[] disc, low;
private List<Integer>[] graph;
private List<List<Integer>> result;
public List<List<Integer>> criticalConnections(int n, List<List<Integer>> connections) {
// 构建邻接表
graph = new ArrayList[n];
for (int i = 0; i < n; i++) graph[i] = new ArrayList<>();
for (List<Integer> conn : connections) {
int u = conn.get(0), v = conn.get(1);
graph[u].add(v);
graph[v].add(u);
}
disc = new int[n];
low = new int[n];
result = new ArrayList<>();
time = 0;
Arrays.fill(disc, -1);
dfs(0, -1);
return result;
}
private void dfs(int u, int parent) {
disc[u] = low[u] = ++time;
for (int v : graph[u]) {
if (v == parent) continue; // 跳过父节点
if (disc[v] == -1) {
// 未访问的子节点
dfs(v, u);
low[u] = Math.min(low[u], low[v]);
// 关键判断:low[v] > disc[u]
if (low[v] > disc[u]) {
result.add(Arrays.asList(u, v));
}
} else {
// 已访问节点(回边)
low[u] = Math.min(low[u], disc[v]);
}
}
}
}
复杂度分析
- 时间复杂度:$O(V + E)$,每个节点和边只访问一次
- 空间复杂度:$O(V)$,用于存储
disc、low数组和递归栈
2-SAT问题:从强连通分量到可满足性
问题定义
2-SAT(2-Satisfiability)是布尔可满足性问题的一个特例:给定一个合取范式(CNF),其中每个子句恰好包含两个文字,判断是否存在一组变量赋值使整个公式为真。
例如,判断以下公式是否可满足:
$$(a \lor \neg b) \land (\neg a \lor b) \land (\neg a \lor \neg b) \land (a \lor \neg c)$$蕴涵图与强连通分量
2-SAT的关键洞察是:每个子句 $(x \lor y)$ 等价于两个蕴涵:$\neg x \Rightarrow y$ 和 $\neg y \Rightarrow x$。我们可以构建一个蕴涵图:
- 每个变量 $x$ 对应两个节点:$x$ 和 $\neg x$
- 每个子句添加两条有向边
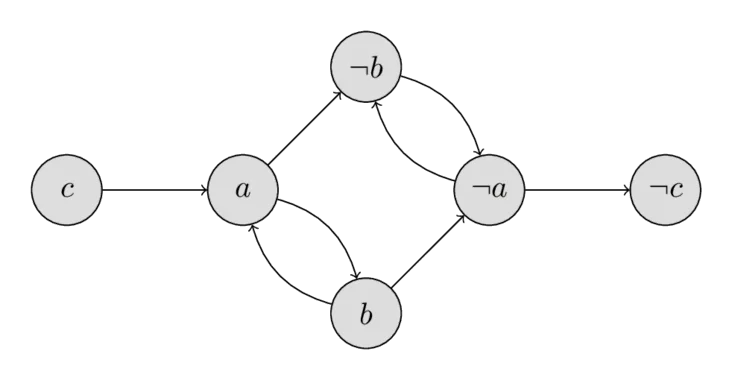
图片来源: CP-Algorithms - 2-SAT
关键定理:2-SAT问题有解,当且仅当蕴涵图中没有变量 $x$ 使得 $x$ 和 $\neg x$ 属于同一个强连通分量。
直觉:如果 $x$ 和 $\neg x$ 在同一个强连通分量中,意味着 $x \Rightarrow \neg x$ 且 $\neg x \Rightarrow x$,导致矛盾。
求解算法
public class TwoSAT {
private int[] comp;
private List<List<Integer>> graph, revGraph;
public boolean solve(int n, int[][] clauses) {
// clauses[i] = {a, b} 表示 (a OR b)
// 变量编号:正数表示x_i,负数表示¬x_i
// 节点编号:2k表示x_k,2k+1表示¬x_k
int totalNodes = 2 * n;
graph = new ArrayList<>();
revGraph = new ArrayList<>();
for (int i = 0; i < totalNodes; i++) {
graph.add(new ArrayList<>());
revGraph.add(new ArrayList<>());
}
// 构建蕴涵图
for (int[] clause : clauses) {
int a = clause[0], b = clause[1];
// (a OR b) 等价于 (¬a → b) AND (¬b → a)
addImplication(negate(a), normalize(b, n));
addImplication(negate(b), normalize(a, n));
}
// 使用Kosaraju找强连通分量
comp = new int[totalNodes];
boolean[] visited = new boolean[totalNodes];
List<Integer> order = new ArrayList<>();
// 第一次DFS:获取拓扑序
for (int i = 0; i < totalNodes; i++) {
if (!visited[i]) dfs1(i, visited, order);
}
// 第二次DFS:标记强连通分量
Arrays.fill(visited, false);
int compId = 0;
for (int i = totalNodes - 1; i >= 0; i--) {
int u = order.get(i);
if (!visited[u]) {
dfs2(u, visited, compId++);
}
}
// 检查是否存在x和¬x在同一强连通分量
for (int i = 0; i < n; i++) {
if (comp[2 * i] == comp[2 * i + 1]) return false;
}
return true;
}
private void addImplication(int from, int to) {
graph.get(from).add(to);
revGraph.get(to).add(from);
}
private int normalize(int x, int n) {
return x > 0 ? 2 * (x - 1) : 2 * (-x - 1) + 1;
}
private int negate(int node) {
return node ^ 1;
}
private void dfs1(int u, boolean[] visited, List<Integer> order) {
visited[u] = true;
for (int v : graph.get(u)) {
if (!visited[v]) dfs1(v, visited, order);
}
order.add(u);
}
private void dfs2(int u, boolean[] visited, int compId) {
visited[u] = true;
comp[u] = compId;
for (int v : revGraph.get(u)) {
if (!visited[v]) dfs2(v, visited, compId);
}
}
// 获取解(如果存在)
public boolean[] getAssignment(int n) {
boolean[] assignment = new boolean[n];
for (int i = 0; i < n; i++) {
// 拓扑序较大的分量赋值为true
assignment[i] = comp[2 * i] > comp[2 * i + 1];
}
return assignment;
}
}
变量赋值的确定
当2-SAT有解时,如何确定变量的值?关键观察:强连通分量的拓扑序决定了变量赋值。
对于变量 $x$,如果 $x$ 所在强连通分量的拓扑序大于 $\neg x$ 所在强连通分量,则将 $x$ 赋值为 true;否则赋值为 false。这是因为:
- 拓扑序小的分量"指向"拓扑序大的分量
- 如果 $\neg x$ 指向 $x$($\neg x$ 的拓扑序更小),说明选择 $x$ 为
true不会导致矛盾
Tarjan算法的四种变体对比
| 问题 | 图类型 | 判断条件 | 额外处理 |
|---|---|---|---|
| 强连通分量 | 有向 | low[u] == disc[u] |
使用栈收集分量 |
| 割点 | 无向 | low[v] >= disc[u](非根)或子节点数>1(根) |
根节点特殊处理 |
| 桥 | 无向 | low[v] > disc[u] |
记录边而非节点 |
| 2-SAT | 有向(蕴涵图) | $x$ 和 $\neg x$ 不在同一SCC | 拓扑序决定赋值 |
实战技巧与常见陷阱
1. 重边和自环的处理
对于重边,Tarjan算法天然支持——多条边会被当作不同的边处理。自环通常不影响结果(除非题目特别说明)。
2. 非连通图的处理
务必从每个未访问节点启动DFS,而非假设图是连通的。这是初学者最容易犯的错误。
3. 递归栈溢出
对于超大图($10^5$ 级别节点),递归可能导致栈溢出。解决方案是使用显式栈实现迭代版DFS:
private void dfsIterative(int start) {
Stack<int[]> stack = new Stack<>();
stack.push(new int[]{start, 0}); // {节点, 下一个要访问的邻居索引}
while (!stack.isEmpty()) {
int[] top = stack.peek();
int u = top[0], idx = top[1];
if (idx == 0) {
// 首次访问该节点
disc[u] = low[u] = ++time;
onStack[u] = true;
nodeStack.push(u);
}
if (idx < graph.get(u).size()) {
int v = graph.get(u).get(idx);
top[1]++; // 移动到下一个邻居
if (disc[v] == -1) {
stack.push(new int[]{v, 0});
} else if (onStack[v]) {
low[u] = Math.min(low[u], disc[v]);
}
} else {
// 所有邻居处理完毕
stack.pop();
if (low[u] == disc[u]) {
// 找到强连通分量
// ... 弹出栈中节点
}
if (!stack.isEmpty()) {
int parent = stack.peek()[0];
low[parent] = Math.min(low[parent], low[u]);
}
}
}
}
4. 并查集的配合使用
某些问题需要同时使用并查集和Tarjan算法。例如,求解最近公共祖先(LCA)的Tarjan离线算法就是将两者结合的经典案例。
扩展阅读
Tarjan算法的思想远不止于此。Robert Tarjan还发明了:
- Splay Tree:自调整二叉搜索树
- Fibonacci Heap:用于Dijkstra算法优化
- Union-Find的路径压缩:将并查集操作优化到近乎常数时间
这些数据结构和算法都体现了Tarjan一贯的风格:用最简单的数据结构,达到最优的时间复杂度。
参考资料
- Tarjan, R. E. (1972). “Depth-first search and linear graph algorithms”. SIAM Journal on Computing.
- Knuth, D. E. (1993). The Stanford GraphBase: A Platform for Combinatorial Computing.
- CP-Algorithms: 2-SAT
- GeeksforGeeks: Tarjan’s Algorithm
- Wikipedia: Tarjan’s SCC Algorithm