给定一个长度为100万的数组,需要回答10万次查询——每次查询要求计算某个区间的元素之和。最直观的做法是:对每个查询,遍历从左端点到右端点的所有元素进行累加。假设平均区间长度为50万,总操作次数约为500亿次,在现代CPU上需要运行数秒甚至更久。
但如果换一种思路:先花100万次操作计算出每个位置的"累计和",之后每次查询只需要两次数组访问和一次减法——总操作次数降至100万加10万次,效率提升约5000倍。
这就是前缀和算法的核心价值:用一次$O(n)$的预处理,换取后续所有区间查询的$O(1)$时间复杂度。
前缀和的本质:空间换时间的经典范例
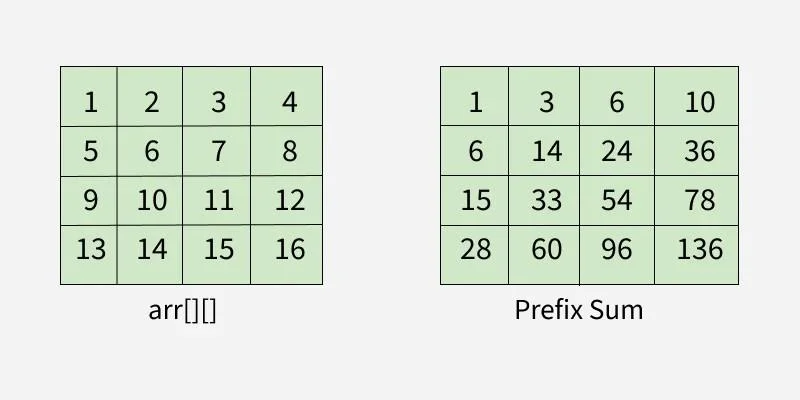
前缀和(Prefix Sum),又称累积和或部分和,是一种通过预处理将重复计算"摊销"的技术。给定原数组nums,前缀和数组prefix的定义为:
换句话说,prefix[i]存储的是原数组从第0个元素到第i个元素的总和。有了这个预处理数组,任意区间[left, right]的元素之和就可以通过一次减法得到:
当left为0时,直接返回prefix[right]。为了统一处理边界情况,实践中通常使用长度为n+1的前缀和数组,其中prefix[0] = 0,prefix[i+1] = prefix[i] + nums[i]。这样区间和的计算公式变为:
// 一维前缀和的标准实现
class PrefixSum {
private int[] prefix;
public PrefixSum(int[] nums) {
int n = nums.length;
prefix = new int[n + 1];
for (int i = 0; i < n; i++) {
prefix[i + 1] = prefix[i] + nums[i];
}
}
// 查询区间[left, right]的元素和
public int sumRange(int left, int right) {
return prefix[right + 1] - prefix[left];
}
}
前缀和的思想可以追溯到数学中的部分和概念,在计算机科学领域最早被应用于数据库查询优化和并行计算。1990年代,前缀和成为并行算法设计的核心组件——在多处理器环境下,前缀和可以通过$O(\log n)$的并行时间完成,这为大规模数据处理提供了理论基础。
一维前缀和:LeetCode入门题精讲
LeetCode 303. Range Sum Query - Immutable
这是前缀和最基础的应用场景,直接考察区间和查询的实现。
题目描述:给定一个整数数组nums,处理多次查询,每次查询要求计算nums在索引left和right之间的元素之和(包含left和right)。
解题思路:在构造函数中预处理前缀和数组,查询时直接返回差值。
class NumArray {
private int[] prefix;
public NumArray(int[] nums) {
int n = nums.length;
prefix = new int[n + 1];
for (int i = 0; i < n; i++) {
prefix[i + 1] = prefix[i] + nums[i];
}
}
public int sumRange(int left, int right) {
return prefix[right + 1] - prefix[left];
}
}
复杂度分析:预处理时间$O(n)$,单次查询时间$O(1)$,空间复杂度$O(n)$。
LeetCode 724. Find Pivot Index
题目描述:寻找数组的"中心索引",使得该索引左侧所有元素之和等于右侧所有元素之和。
解题思路:利用前缀和,中心索引i满足:prefix[i] == prefix[n] - prefix[i+1],即左侧和等于总和减去左侧和再减去当前元素。
class Solution {
public int pivotIndex(int[] nums) {
int n = nums.length;
int totalSum = 0;
for (int num : nums) {
totalSum += num;
}
int leftSum = 0;
for (int i = 0; i < n; i++) {
// 右侧和 = 总和 - 左侧和 - 当前元素
if (leftSum == totalSum - leftSum - nums[i]) {
return i;
}
leftSum += nums[i];
}
return -1;
}
}
LeetCode 238. Product of Array Except Self
虽然题目要求计算乘积,但核心思想与前缀和相同——使用"前缀积"和"后缀积"两个辅助数组。
题目描述:给定数组nums,返回数组answer,使得answer[i]等于nums中除nums[i]外其余各元素的乘积。
class Solution {
public int[] productExceptSelf(int[] nums) {
int n = nums.length;
int[] answer = new int[n];
// 计算前缀积
answer[0] = 1;
for (int i = 1; i < n; i++) {
answer[i] = answer[i - 1] * nums[i - 1];
}
// 计算后缀积并直接乘入答案
int rightProduct = 1;
for (int i = n - 1; i >= 0; i--) {
answer[i] *= rightProduct;
rightProduct *= nums[i];
}
return answer;
}
}
优化亮点:通过从右向左遍历计算后缀积,直接复用answer数组,将空间复杂度从$O(n)$优化到$O(1)$(不计输出数组)。
二维前缀和:矩阵区间查询的利器
当问题从一维数组扩展到二维矩阵时,前缀和的思想依然适用,但计算公式需要借助容斥原理(Inclusion-Exclusion Principle)。
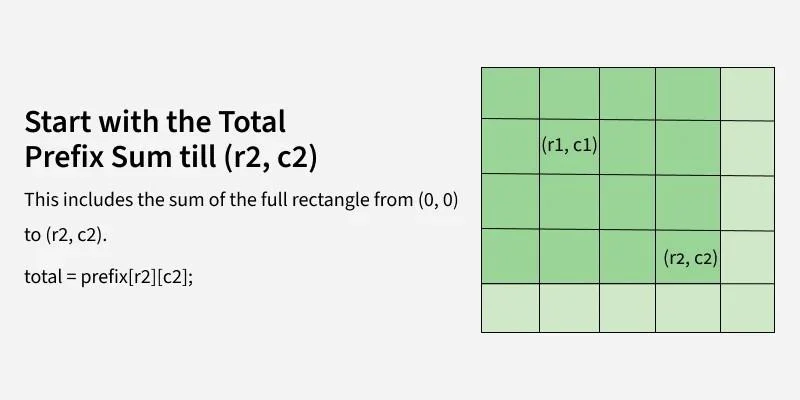
对于矩阵matrix,定义二维前缀和矩阵prefix,其中prefix[i][j]表示从左上角(0,0)到(i-1,j-1)这个矩形区域内所有元素的和。构建公式为:
查询任意子矩阵(r1,c1)到(r2,c2)的和时,使用容斥原理:
LeetCode 304. Range Sum Query 2D - Immutable
题目描述:给定二维矩阵,处理多次查询,每次查询要求计算子矩阵内所有元素的和。
class NumMatrix {
private int[][] prefix;
public NumMatrix(int[][] matrix) {
if (matrix.length == 0 || matrix[0].length == 0) return;
int m = matrix.length, n = matrix[0].length;
prefix = new int[m + 1][n + 1];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
prefix[i + 1][j + 1] = matrix[i][j]
+ prefix[i][j + 1]
+ prefix[i + 1][j]
- prefix[i][j];
}
}
}
public int sumRegion(int row1, int col1, int row2, int col2) {
return prefix[row2 + 1][col2 + 1]
- prefix[row1][col2 + 1]
- prefix[row2 + 1][col1]
+ prefix[row1][col1];
}
}
复杂度分析:预处理时间$O(m \times n)$,单次查询时间$O(1)$,空间复杂度$O(m \times n)$。
前缀和与哈希表:子数组计数问题的终极解法
前缀和真正的威力在于与哈希表结合后,能够高效解决子数组计数类问题。核心思想是:如果prefix[j] - prefix[i] = k,那么子数组nums[i+1...j]的和为k。
LeetCode 560. Subarray Sum Equals K
这是前缀和+哈希表模式的经典题目,也是面试中的高频考题。
题目描述:给定整数数组nums和整数k,统计数组中和为k的连续子数组的个数。
解题思路:遍历数组时,维护当前前缀和sum。对于每个位置,如果存在某个之前的前缀和等于sum - k,那么从那个位置到当前位置的子数组和为k。用哈希表记录每个前缀和出现的次数。
class Solution {
public int subarraySum(int[] nums, int k) {
Map<Integer, Integer> count = new HashMap<>();
count.put(0, 1); // 前缀和为0出现1次(空子数组)
int sum = 0;
int result = 0;
for (int num : nums) {
sum += num;
// 如果存在前缀和为sum-k,则子数组和为k
result += count.getOrDefault(sum - k, 0);
// 更新当前前缀和的出现次数
count.put(sum, count.getOrDefault(sum, 0) + 1);
}
return result;
}
}
关键点:
- 初始化时
count.put(0, 1)处理从数组开头开始的子数组 - 先更新答案,再更新哈希表,避免子数组为空的情况
- 时间复杂度$O(n)$,空间复杂度$O(n)$
LeetCode 974. Subarray Sums Divisible by K
题目描述:统计和可被k整除的连续子数组的个数。
解题思路:如果两个前缀和对k取模的余数相同,那么它们的差(即中间子数组的和)一定能被k整除。
class Solution {
public int subarraysDivByK(int[] nums, int k) {
int[] count = new int[k];
count[0] = 1; // 余数为0表示本身可被整除
int sum = 0;
int result = 0;
for (int num : nums) {
sum += num;
// 处理负数:Java的%运算可能返回负数
int remainder = ((sum % k) + k) % k;
result += count[remainder];
count[remainder]++;
}
return result;
}
}
易错点:Java中的取模运算在处理负数时可能返回负值,需要通过((sum % k) + k) % k确保余数在[0, k-1]范围内。
LeetCode 523. Continuous Subarray Sum
题目描述:检查是否存在长度至少为2的子数组,其和是k的倍数。
解题思路:与LeetCode 974类似,但需要额外记录每个余数最早出现的位置,以判断子数组长度是否满足条件。
class Solution {
public boolean checkSubarraySum(int[] nums, int k) {
Map<Integer, Integer> firstIndex = new HashMap<>();
firstIndex.put(0, -1); // 余数0在索引-1处出现
int sum = 0;
for (int i = 0; i < nums.length; i++) {
sum += nums[i];
int remainder = sum % k;
// 处理负数情况
if (remainder < 0) remainder += k;
if (firstIndex.containsKey(remainder)) {
if (i - firstIndex.get(remainder) >= 2) {
return true;
}
} else {
firstIndex.put(remainder, i);
}
}
return false;
}
}
关键点:只在余数首次出现时记录索引,这样可以找到最长的满足条件的子数组。
LeetCode 1248. Count Number of Nice Subarrays
题目描述:统计恰好包含k个奇数的连续子数组的个数。
解题思路:将数组转换为只包含奇偶信息(奇数记为1,偶数记为0),问题转化为"和为k的子数组个数",与LeetCode 560完全相同。
class Solution {
public int numberOfSubarrays(int[] nums, int k) {
Map<Integer, Integer> count = new HashMap<>();
count.put(0, 1);
int oddCount = 0;
int result = 0;
for (int num : nums) {
if (num % 2 == 1) {
oddCount++;
}
result += count.getOrDefault(oddCount - k, 0);
count.put(oddCount, count.getOrDefault(oddCount, 0) + 1);
}
return result;
}
}
树形结构中的前缀和
前缀和不仅适用于线性数组,还可以扩展到树形结构。核心思想是在深度优先搜索过程中维护"路径前缀和"。
LeetCode 437. Path Sum III
题目描述:给定二叉树和目标值targetSum,统计路径和等于targetSum的路径数量。路径不需要从根节点开始,也不需要在叶子节点结束,但必须向下延伸。
class Solution {
private int result = 0;
private Map<Long, Integer> prefixCount = new HashMap<>();
private int targetSum;
public int pathSum(TreeNode root, int targetSum) {
this.targetSum = targetSum;
prefixCount.put(0L, 1); // 前缀和为0出现1次
dfs(root, 0L);
return result;
}
private void dfs(TreeNode node, long currentSum) {
if (node == null) return;
currentSum += node.val;
// 查找是否存在前缀和为currentSum - targetSum
result += prefixCount.getOrDefault(currentSum - targetSum, 0);
// 更新前缀和计数
prefixCount.put(currentSum, prefixCount.getOrDefault(currentSum, 0) + 1);
// 递归处理子节点
dfs(node.left, currentSum);
dfs(node.right, currentSum);
// 回溯:移除当前前缀和
prefixCount.put(currentSum, prefixCount.get(currentSum) - 1);
}
}
关键点:
- 使用
long类型避免整数溢出 - 递归返回时需要"回溯",将当前前缀和的计数减1
- 这确保了哈希表中只存储当前路径上的前缀和
差分数组:前缀和的逆运算
差分数组是前缀和的"逆运算"。如果说前缀和用于"区间查询",差分数组则用于"区间修改"。
定义差分数组diff,使得diff[i] = nums[i] - nums[i-1](diff[0] = nums[0])。那么:
- 对区间
[l, r]统一加上val,只需要diff[l] += val,diff[r+1] -= val - 对差分数组求前缀和,即可还原修改后的原数组
LeetCode 370. Range Addition
题目描述:对一个长度为length的初始全0数组执行updates次操作,每次操作对区间[start, end]加上inc。返回最终数组。
class Solution {
public int[] getModifiedArray(int length, int[][] updates) {
int[] diff = new int[length];
// 构建差分数组
for (int[] update : updates) {
int start = update[0], end = update[1], inc = update[2];
diff[start] += inc;
if (end + 1 < length) {
diff[end + 1] -= inc;
}
}
// 对差分数组求前缀和得到结果
for (int i = 1; i < length; i++) {
diff[i] += diff[i - 1];
}
return diff;
}
}
复杂度分析:时间复杂度$O(n + m)$,其中n为数组长度,m为操作次数。空间复杂度$O(1)$额外空间。
前缀和题目分类与刷题建议
根据题目特点,前缀和相关问题可以分为以下几类:
| 类型 | 核心技巧 | 代表题目 |
|---|---|---|
| 区间和查询 | 预处理前缀和数组 | 303, 304 |
| 子数组和计数 | 前缀和 + 哈希表 | 560, 974, 523, 1248 |
| 树形路径求和 | DFS + 前缀和 + 回溯 | 437 |
| 区间修改 | 差分数组 | 370, 1109 |
| 前缀和变体 | 前缀积、前缀异或 | 238, 1310 |
刷题顺序建议:
- 先掌握基础:303 → 724 → 238
- 理解哈希表结合:560 → 974 → 523
- 进阶应用:437 → 304 → 1248
- 学习差分数组:370 → 1109
实战技巧与常见陷阱
技巧一:前缀和数组长度设为n+1
使用prefix[0] = 0作为哨兵节点,可以统一处理left = 0的边界情况,避免特殊判断。
技巧二:处理负数取模
Java的%运算在处理负数时返回负值,需要使用((sum % k) + k) % k标准化到[0, k-1]范围。
技巧三:前缀和溢出
当数组元素较大或数组较长时,前缀和可能超过int范围。使用long类型存储前缀和是安全的做法。
技巧四:哈希表更新顺序
在子数组计数问题中,应该先更新答案(查询sum - k),再更新哈希表(添加当前sum)。这个顺序确保了子数组非空。
技巧五:树形问题的回溯
在树形结构中使用前缀和时,递归返回前必须将当前前缀和从哈希表中移除,否则会影响其他分支的计数。
前缀和作为一种"以空间换时间"的预处理技术,其核心价值在于将重复的区间计算转化为常数时间的查询。掌握前缀和与哈希表的结合模式,能够解决大量子数组计数问题,这是算法面试中的高频考点。从一维到二维,从数组到树形结构,前缀和的思想贯穿始终,体现了算法设计中"预处理 + 快速查询"的经典范式。