
大模型是如何被训练出来的?从预训练到对齐的三阶段技术全景
当我们与一个训练完成的大语言模型对话时,它似乎能理解我们的问题、组织连贯的回答、甚至在某些领域展现出接近专家的知识水平。但这个"智能体"并非凭空诞生——在它能说出第一句话之前,背后是一个历时数月、耗资千万美元、涉及万亿级token的复杂训练过程。 ...
当我们与一个训练完成的大语言模型对话时,它似乎能理解我们的问题、组织连贯的回答、甚至在某些领域展现出接近专家的知识水平。但这个"智能体"并非凭空诞生——在它能说出第一句话之前,背后是一个历时数月、耗资千万美元、涉及万亿级token的复杂训练过程。 ...
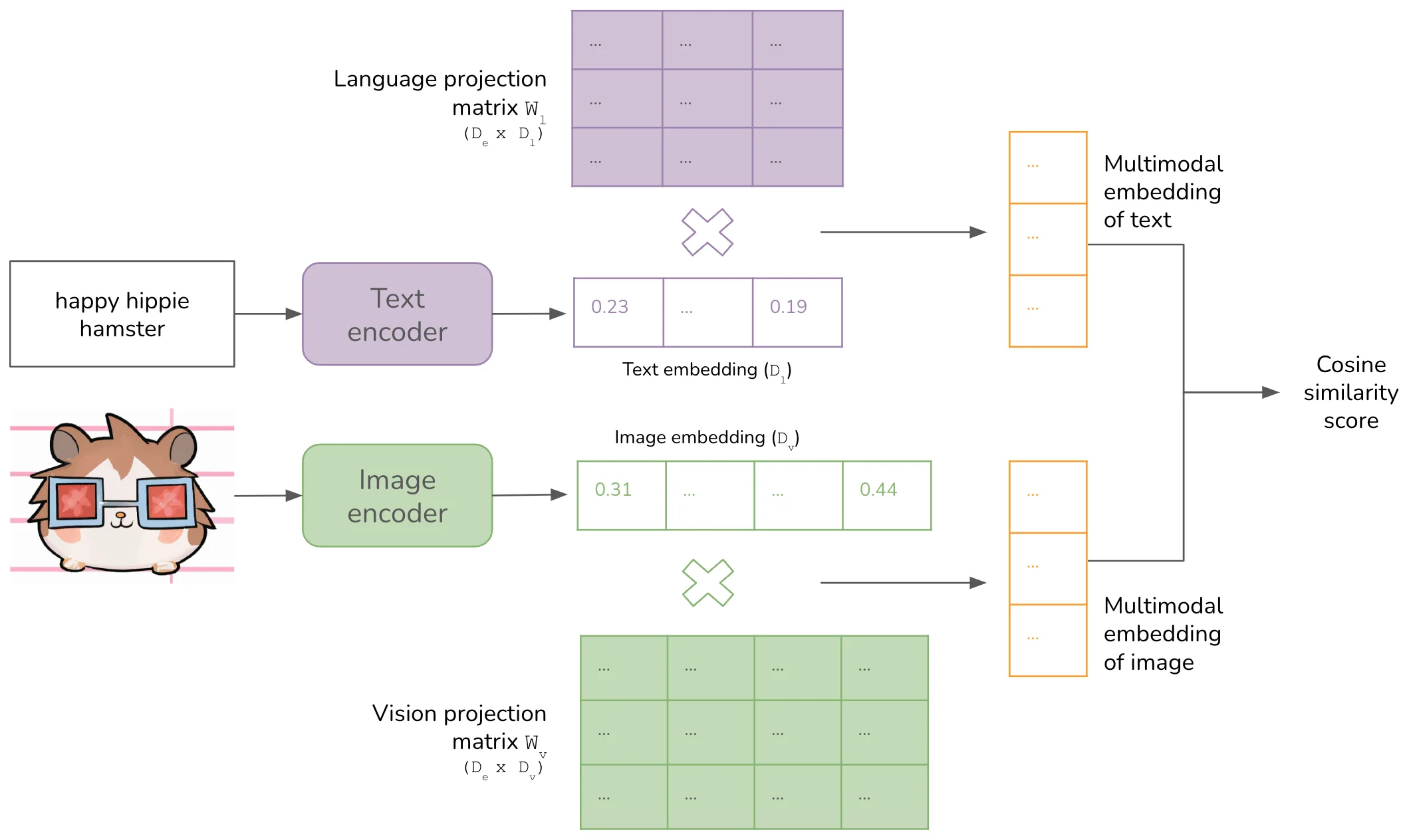
2024年5月,OpenAI发布GPT-4o,这个模型能实时"看"你手机屏幕上的内容并回答问题。对着一张复杂的电路图问"这个电阻的阻值是多少",它能准确定位并读出数值;给它一张手绘的流程图,它能理解逻辑关系并生成代码实现。 ...
2015年,何凯明团队在ImageNet竞赛中提交了一个152层的神经网络模型。这个深度是当时主流模型的8倍,但训练误差却更低——这在当时简直是不可思议的事情。因为在那之前,人们普遍认为网络越深,训练越困难。实际上,研究者们观察到一个反直觉的现象:增加层数反而会让模型性能下降。 ...
2017年,Google Research 团队发表论文《Attention Is All You Need》,提出了一种名为 Transformer 的神经网络架构。论文标题是一个明确的判断——在此之前的神经机器翻译模型依赖于循环神经网络(RNN)和卷积神经网络(CNN)的组合,而 Transformer 仅使用注意力机制就达到了当时的最优性能。 ...
当GPT-3在2020年问世时,其1750亿参数的规模震惊了整个AI界。三年后,LLaMA-70B用更少的参数达到了更好的效果。到了2024年,DeepSeek-V3以6710亿总参数但仅激活370亿参数的MoE架构重新定义了效率边界。这些数字背后隐藏着一套精确的数学逻辑——参数量如何决定计算量,计算量如何影响训练成本,以及如何在有限的算力预算下设计最优模型。 ...
传统 Transformer 有一个很少有人质疑的设计假设:序列中的每一个 token,无论其重要性如何,都必须经过完全相同数量的层进行处理。一个简单的"的"字和一个承载核心语义的动词,在计算资源上被一视同仁。这种"计算平均主义"在大模型时代显得尤为奢侈——当参数量飙升至千亿级别,每一个不必要的 FLOP 都在消耗真金白银。 ...
2023年12月,卡内基梅隆大学的Albert Gu和普林斯顿大学的Tri Dao在arXiv上发表了一篇论文,声称首次实现了"线性时间的Transformer级别性能"。这篇论文的标题很朴素——《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》,但其展示的数据却引发了广泛关注:在百万级token长度上,Mamba的推理吞吐量达到同规模Transformer的5倍。 ...