传统 Transformer 有一个很少有人质疑的设计假设:序列中的每一个 token,无论其重要性如何,都必须经过完全相同数量的层进行处理。一个简单的"的"字和一个承载核心语义的动词,在计算资源上被一视同仁。这种"计算平均主义"在大模型时代显得尤为奢侈——当参数量飙升至千亿级别,每一个不必要的 FLOP 都在消耗真金白银。
2024 年 4 月,Google DeepMind 的研究团队在论文《Mixture-of-Depths: Dynamically allocating compute in transformer-based language models》中提出了一个反直觉的洞见:transformer 可以学会在序列的不同位置动态分配计算资源,而非对每个 token 施以均等的计算。这种被称为 Mixture-of-Depths (MoD) 的架构,不仅打破了传统 transformer 的计算范式,更在同等计算预算下实现了最高 66% 的推理加速。
条件计算:一条曲折的进化之路
MoD 的思想并非横空出世。让神经网络"学会偷懒"的研究可以追溯到 2013 年 Bengio 等人提出的条件计算(Conditional Computation)概念——核心思想是只在需要时才进行计算,从而减少总计算量。
这条研究线演化出了几个重要分支。早期退出(Early Exit)机制在每个 transformer 层后添加一个分类器,当模型对某个 token 的预测足够自信时,就让该 token 提前退出后续层的计算。DeeBERT 和 FastBERT 是这一方向的代表工作,它们可以在推理时节省高达 40% 的计算时间。但早期退出存在一个根本性缺陷:一旦某个 token 在中间层退出,它就再也无法被后续层的其他 token 通过注意力机制"看到"——这相当于丢失了信息传递的通道。
另一条线是 Universal Transformer,它借鉴了循环神经网络的思想,让 transformer 层共享权重并可以迭代多次。配合自适应计算时间(Adaptive Computation Time, ACT)机制,模型可以学习对每个输入执行不同次数的迭代。但这种动态迭代次数的设计引入了动态计算图,在现代硬件(如 GPU)上难以高效实现——硬件更擅长处理静态、规则的计算图,而非充满分支判断的动态结构。
MoD 的突破在于它找到了一个优雅的平衡点:保持静态计算图的同时实现动态计算分配。通过预设一个固定的"容量"(capacity),每一层最多只处理固定数量的 token,而具体是哪些 token 则由网络自己学习决定。这种设计既满足了硬件对静态图的需求,又赋予了模型动态分配计算的能力。
核心机制:让 Token 选择自己的深度
MoD 的核心架构可以用一个简洁的公式概括。假设第 $l$ 层的输入 token 嵌入为 $x_i^l$,路由网络首先通过一个线性变换计算出一个标量权重:
$$r_i^l = w_\theta^T x_i^l$$这个权重表示第 $i$ 个 token 的"计算优先级"。接下来,MoD 执行一个 top-k 选择操作:从当前序列中选出权重最大的 $k$ 个 token 参与完整的自注意力和 MLP 计算,而其余的 token 则直接通过残差连接跳过这一层。
具体地,令 $\beta$ 分位数 $P_\beta(R^l)$ 为路由权重的阈值,其中 $\beta = 1 - C/S$,$C$ 是预设的容量,$S$ 是序列长度。一个 token 的输出为:
$$x_i^{l+1} = \begin{cases} r_i^l \cdot f_i(\tilde{X}^l) + x_i^l, & \text{if } r_i^l > P_\beta(R^l) \\ x_i^l, & \text{otherwise} \end{cases}$$其中 $f_i$ 包含自注意力和前馈神经网络,$\tilde{X}^l$ 是所有被选中参与计算的 token 集合。
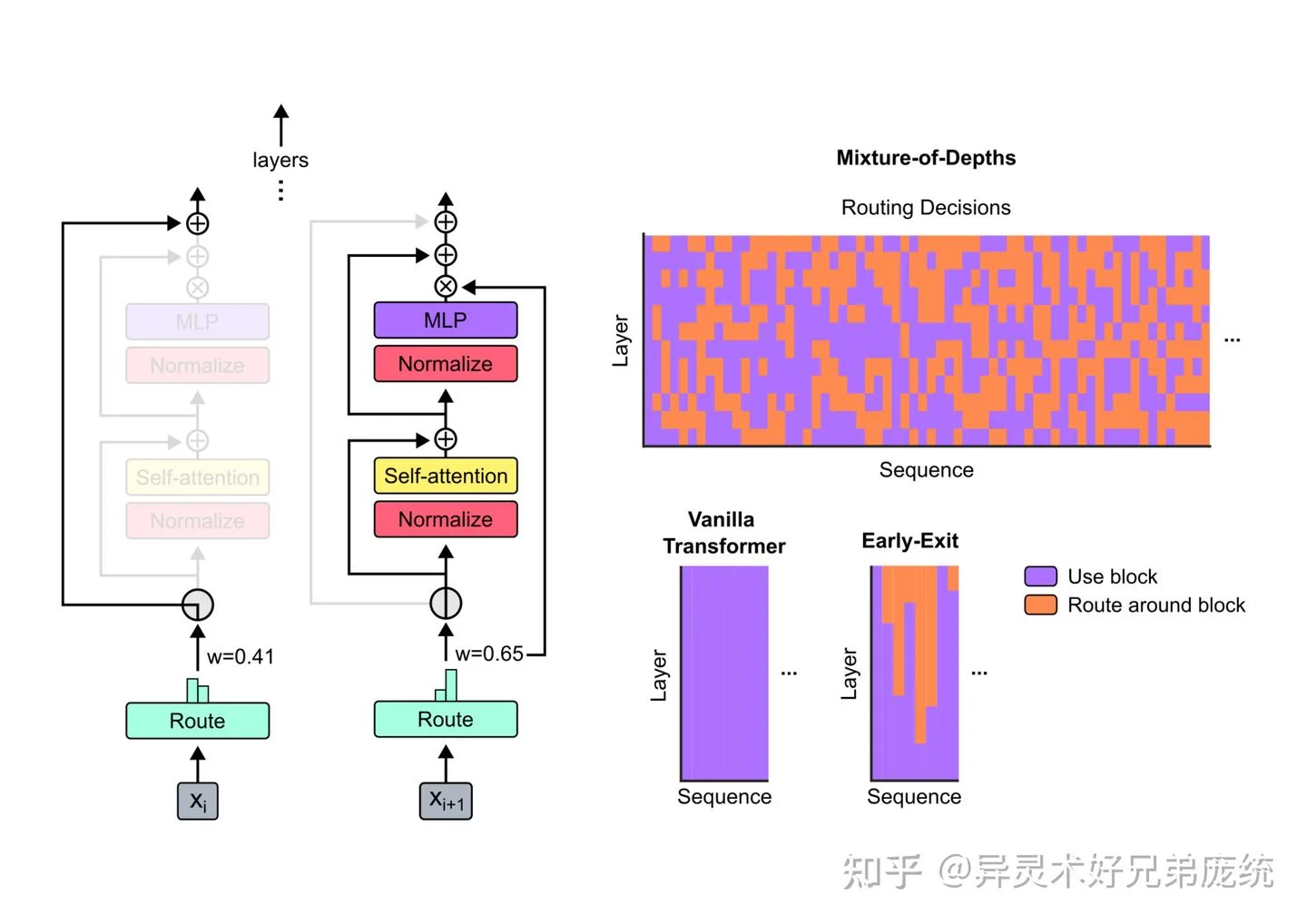
图片来源: 知乎专栏 - Mixture of Depths论文解读 - MoD 架构与标准 Transformer 和 Early Exit 的对比
这种设计带来了两个关键优势。首先,由于每一层只处理 $k$ 个 token 而非全部 $S$ 个,自注意力的计算复杂度从 $O(S^2)$ 降至 $O(k^2)$,MLP 的计算量也从 $O(S)$ 降至 $O(k)$。其次,跳过计算的 token 并不是"消失"了——它们仍然存在于序列中,只是没有被当前层的自注意力更新,后续层仍然可以"看到"它们。这与早期退出机制形成了鲜明对比。
路由机制的设计抉择:Token-Choice vs Expert-Choice
MoD 的路由机制借鉴了 Mixture-of-Experts (MoE) 架构,但在具体实现上做出了关键调整。MoE 通常采用两种路由策略之一:
Token-Choice 路由:每个 token 根据路由网络输出的概率分布,选择最"偏好"的计算路径。问题在于,这种方式无法保证负载均衡——可能所有 token 都涌向同一条路径,导致某些路径过载而另一些路径闲置。MoE 通常需要引入额外的负载均衡损失来缓解这个问题。
Expert-Choice 路由:反转了主动权,让每条计算路径(或专家)主动选择要处理的 token。具体地,每条路径根据路由权重选择 top-k 个 token,确保每个专家都能获得恰好 $k$ 个输入。这种方式天然实现了完美负载均衡,但可能导致某些 token 被多个专家同时选中,或被所有专家忽略。
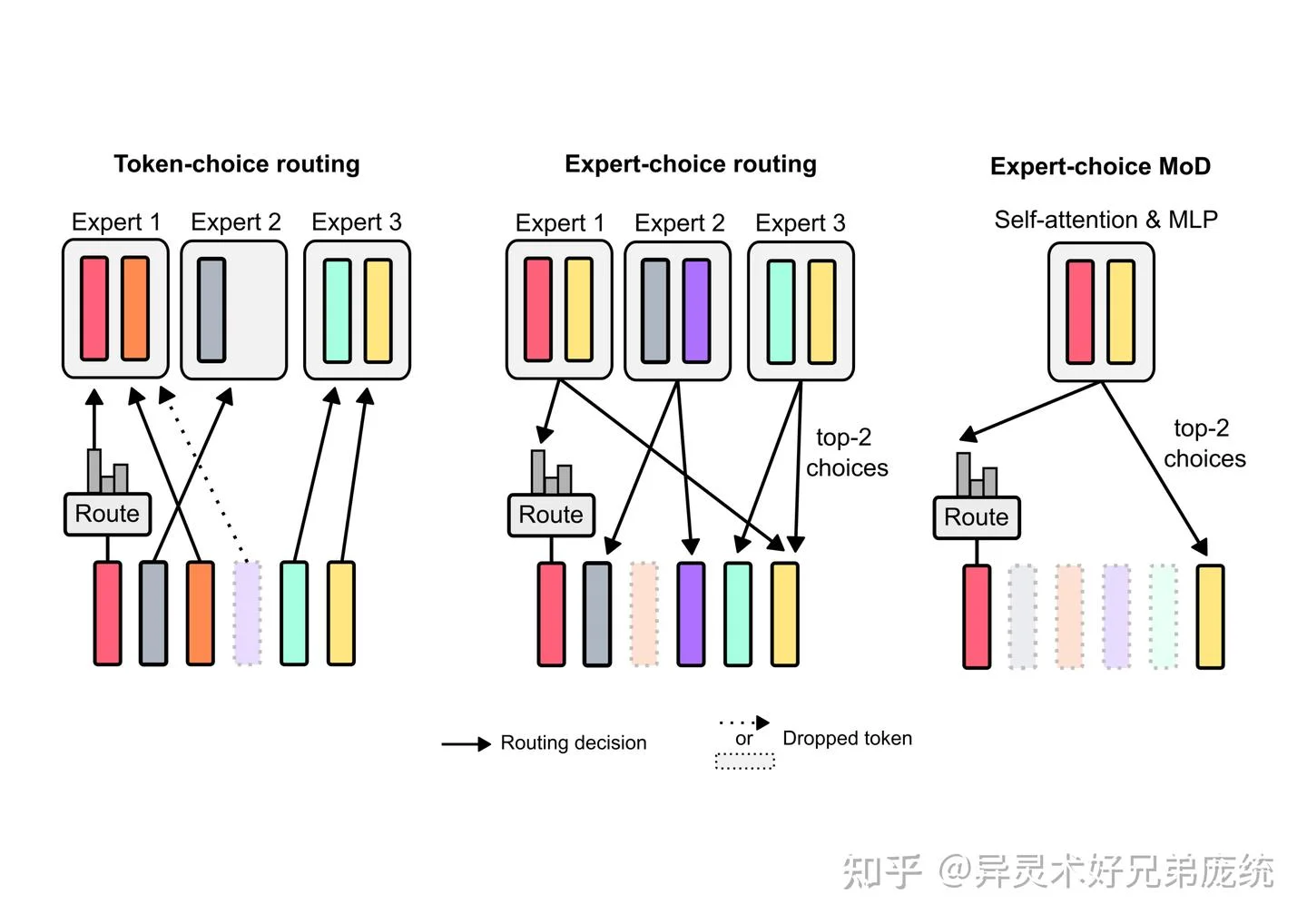
图片来源: 知乎专栏 - Mixture of Depths论文解读 - 三种路由机制对比:Token-Choice、Expert-Choice 和 MoD
MoD 选择了 Expert-Choice 路由,但做了一个重要简化:只有两条路径——完整计算或残差连接。在二元选择场景下,一个 top-k 操作就能将 token 完美分为两组,既避免了负载不均衡问题,也不会出现 token 被重复处理或遗漏的情况。
路由权重的处理还有一个精妙的细节:被选中的 token 在输出时会乘以路由权重 $r_i^l$。这看似微不足道,实则至关重要——它将路由权重置于梯度路径上,使路由网络能够通过反向传播学习"哪些 token 更需要计算"。如果某个 token 在被处理后对模型性能有积极贡献,其路由权重会在训练中逐渐增大,使得该 token 在未来更有可能被选中;反之亦然。
自回归采样的因果性困境
MoD 的路由机制在训练阶段表现出色,但在自回归推理时遇到了一个棘手问题:top-k 操作是非因果的。
理解这个问题需要区分训练和推理两种场景。在训练时,模型可以看到完整的序列,因此可以基于所有 token 的路由权重计算全局的 top-k。但在自回归生成时,模型只能看到当前及之前的 token,无法获知未来 token 的路由权重——而 top-k 的阈值恰恰依赖于所有 token 的权重分布。
论文提出了两种解决方案:
辅助损失法:引入一个二元交叉熵损失,鼓励路由网络输出"极端化"的权重(接近 0 或 1)。具体地,以 top-k 选择的结果作为监督信号(被选中的 token 标签为 1,否则为 0),训练路由网络使其输出能够独立预测自己是否应该被选中。这样,在推理时只需设定一个固定阈值(如 0.5)即可做出决策,无需依赖未来 token 的信息。实验表明,这种方法对主任务的损失函数影响约为 0.3%,是一个可接受的代价。
辅助预测器法:引入一个独立的小型 MLP 预测器,它接收与路由网络相同的输入(带 stop gradient),但专门预测当前 token 是否会被 top-k 选中。这个预测器不影响主任务的训练,因此在推理时可以直接使用其输出作为路由决策依据。实验显示这个预测任务很快就能达到 97% 以上的准确率。
实验结果:效率与性能的帕累托前沿
MoD 的实验结果令人印象深刻。研究团队在 $6 \times 10^{18}$、$2 \times 10^{19}$ 和 $1 \times 10^{20}$ 三种 FLOP 预算下进行了 isoFLOP 分析,模型规模从 60M 到 3B 参数不等。
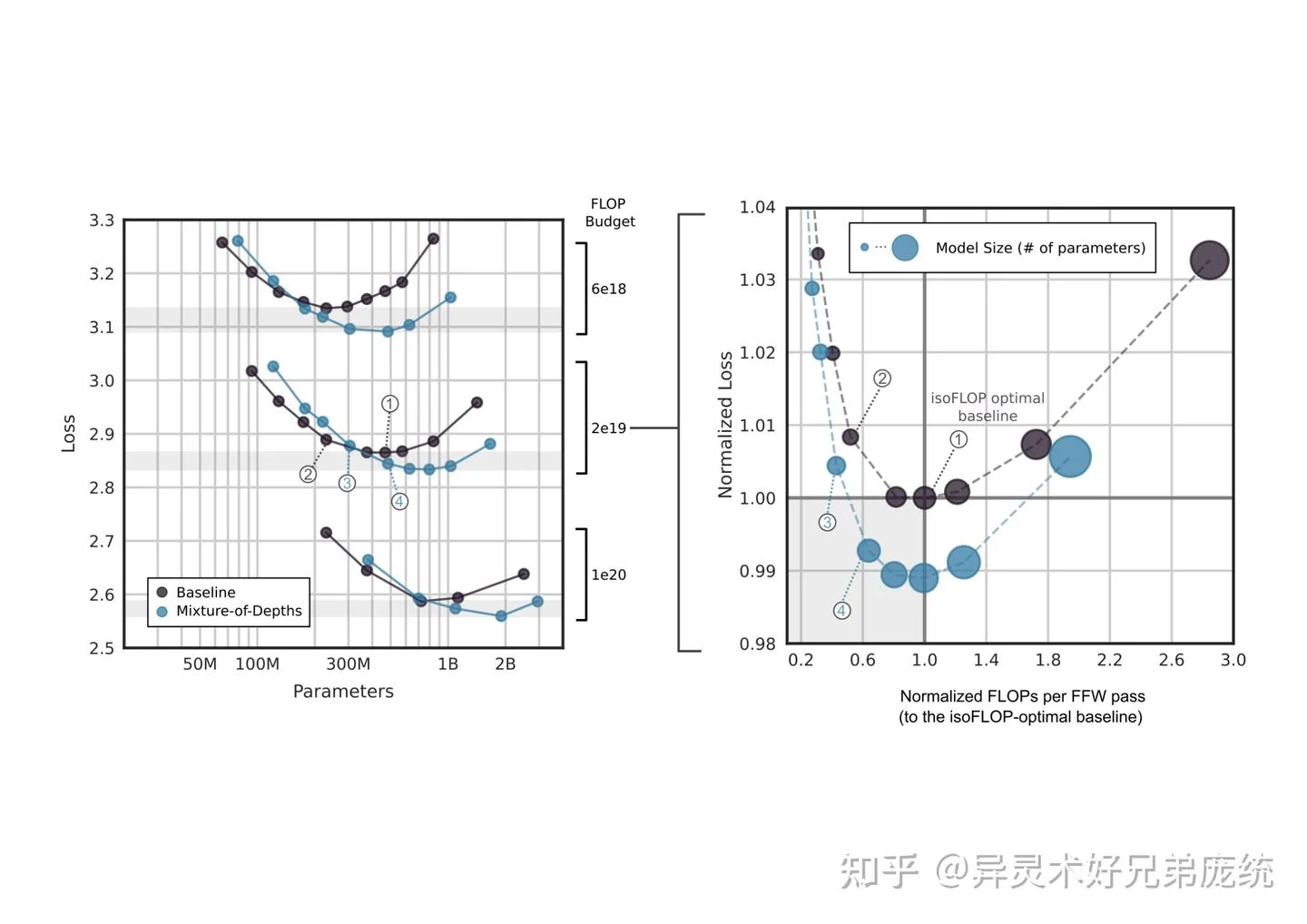
图片来源: 知乎专栏 - Mixture of Depths论文解读 - 不同计算预算下的 isoFLOP 分析
关键发现如下:
-
性能等价下的速度提升:一个 220M 参数的 MoD 变体可以达到与 isoFLOP 最优基线相当的性能,但推理速度提升高达 66%。这是因为 MoD 每次前向传播所需的 FLOP 更少。
-
计算等价下的性能提升:在相同的训练 FLOP 预算下,最优 MoD 模型可以比最优基线模型低约 1.5% 的损失。MoD 模型倾向于"更大但更稀疏"——在相同计算预算下可以容纳更多参数,因为每步的计算量减少了。
-
最优配置:实验发现最佳配置是 12.5% 容量(即每层只处理 12.5% 的 token),并每隔一层应用路由机制。这个配置在激进地减少计算量的同时,仍然保持了足够的"全容量"层来维持模型的表达能力。
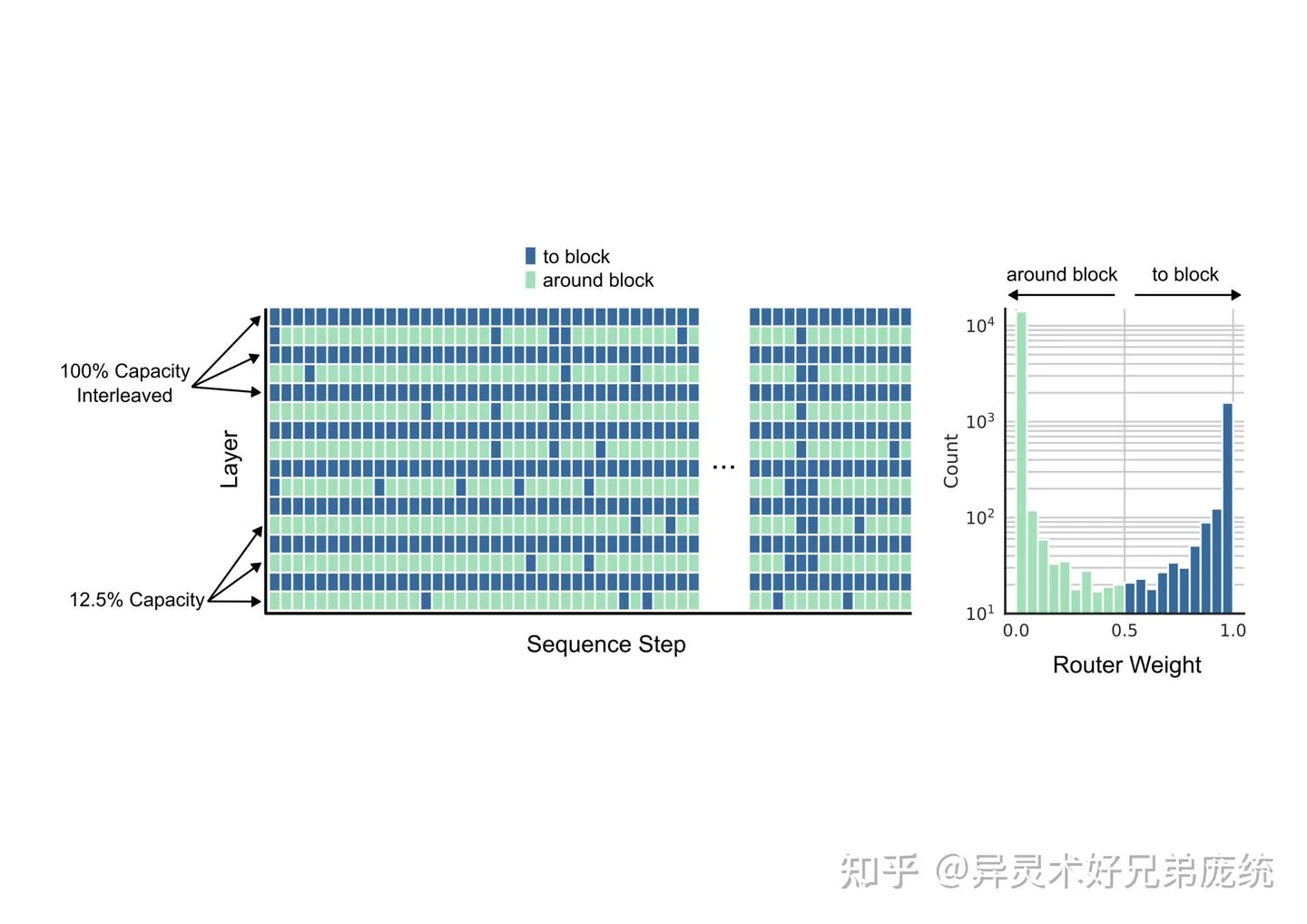
图片来源: 知乎专栏 - Mixture of Depths论文解读 - 路由决策可视化分析
路由决策的可视化分析揭示了 MoD 学到的有趣模式:某些 token 几乎被所有层选中参与计算(可能是语义核心词),而另一些 token 则频繁被跳过(可能是功能词)。更重要的是,token 的处理深度并非基于位置,而是基于语义重要性——一个出现在序列后半部分的 token 仍然可能被前半部分的层选中处理。
与 MoE 的本质差异
Mixture-of-Experts (MoE) 是近年来大模型效率优化的重要方向,Mixtral、DeepSeek-MoE 等模型都采用了这一架构。理解 MoD 与 MoE 的差异,有助于厘清两种技术路线各自的适用场景。
MoE 的核心思想是在每一层设置多个"专家"(独立的 MLP 网络),由路由网络决定每个 token 应该由哪些专家处理。典型的 MoE 配置是:8 个专家,每个 token 被路由到其中 2 个。MoE 的目标是增加模型容量而不成比例地增加计算量——模型总参数量可以很大,但每次推理只激活其中一小部分。
MoD 的目标则不同:减少每个 token 的计算量而不损失性能。MoD 没有多个专家,只有一条计算路径和一个"跳过"选项。当 token 被路由到"跳过"路径时,它不做任何计算直接通过。
两者的差异可以类比如下:
| 特性 | MoE | MoD |
|---|---|---|
| 计算分配维度 | 宽度(专家选择) | 深度(层数选择) |
| 目标 | 增加模型容量 | 减少计算冗余 |
| 参数效率 | 总参数多,激活参数少 | 参数量不变,计算量减少 |
| 自注意力处理 | 不影响 | 可以跳过自注意力 |
MoD 的一个独特优势是它对自注意力的影响。当 token 跳过某层时,它不仅跳过了 MLP 计算,也跳过了自注意力计算——这意味着该 token 不会被更新,同时也不会被该层的其他 token 注意到。这种"选择性可见性"可能是一种特性而非缺陷:不重要的 token 不参与注意力计算,反而可能减少噪音、提升关注质量。
MoD + MoE = MoDE:双重效率增益
MoD 的设计天然可以与 MoE 结合,形成 Mixture-of-Depths-and-Experts (MoDE) 架构。论文探索了两种融合方式:
Staged MoDE:先应用 MoD 路由,被选中的 token 再进入 MoE 路由。这种设计的优势是可以让 token 完全跳过自注意力计算,实现更大的计算节省。
Integrated MoDE:在 MoE 的专家池中添加一个"无操作"专家(No-Op expert),token 被路由到这个专家时等同于跳过计算。这种设计简化了路由机制,只需一次路由决策。
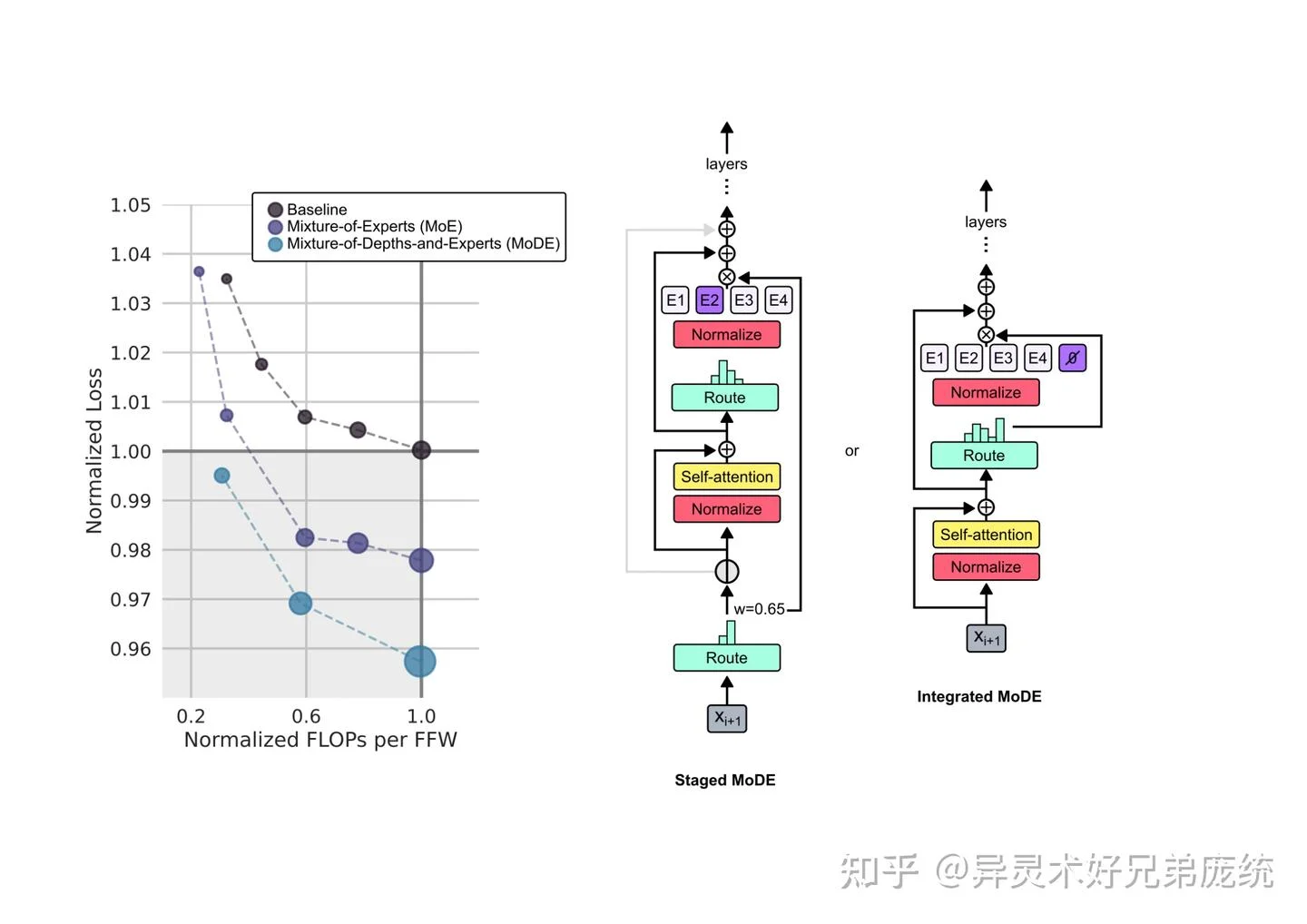
图片来源: 知乎专栏 - Mixture of Depths论文解读 - MoDE 架构示意图
实验结果表明,MoDE 的性能提升是叠加的:MoD 带来的效率增益与 MoE 的容量增益可以同时获得。这为未来的大模型设计提供了一个有前景的方向。
后续改进:从 MoD 到 MoDification
原始 MoD 论文存在一个实际落地的障碍:需要从头训练。对于已经在海量数据上训练好的大模型,重新训练一个 MoD 版本的成本难以承受。
2025 年 NAACL 的一篇论文《MoDification: Mixture of Depths Made Easy》解决了这个问题。研究团队发现,原始 MoD 的 top-k 操作器存在两个问题:计算开销较大(top-k 本身需要排序);强制保留固定数量的 token,可能过度保留或过度跳过。
MoDification 的核心改进是用 threshold-p 操作器替代 top-k 操作器:设置一个阈值 $p$,路由权重大于 $p$ 的 token 参与计算,否则跳过。这种设计更灵活——每层可以有不同的"参与率",由路由网络自主学习决定。
更重要的是,MoDification 证明了只需 约 100 亿 token 的高质量、多样化数据,就足以将现有的 LLM 转换为 MoD 版本。实验显示,MoDification 在长上下文场景下可以实现 1.2 倍的延迟加速和 1.8 倍的内存减少,同时保持可接受的性能下降。
另一个值得一提的后续工作是 2024 年底的《Attention Is All You Need For Mixture-of-Depths Routing》,它提出了一种无参数的路由机制 A-MoD:直接利用前一层的注意力图作为路由依据,完全不需要额外的路由网络。这种设计不仅减少了参数量,还使路由决策更具可解释性。
技术权衡与适用场景
MoD 并非万能药,它带来效率提升的同时也存在一些权衡:
训练复杂度:路由网络引入了额外的训练动态,需要仔细调整学习率和正则化策略。不恰当的配置可能导致路由坍缩——所有 token 都涌向同一条路径。
硬件适配:虽然 MoD 保持了静态计算图,但稀疏的计算模式可能无法充分利用 GPU 的并行能力。在长序列场景下收益更明显,但在短序列或批处理场景下优势有限。
可解释性:路由决策是端到端学习的,难以直观解释为什么某个 token 被跳过。这对于需要可解释性的应用(如医疗诊断)可能是一个考量因素。
MoD 最适合的场景是长上下文处理:文档摘要、长文档问答、代码分析等任务中,大量 token 是"背景信息",只有少数 token 承载关键语义。在这些场景下,MoD 的选择性计算能够显著降低计算成本,同时保持模型性能。
结语
Mixture-of-Depths 代表了大模型效率优化的一个重要思想转变:从"对所有输入一视同仁"到"让模型学会区分轻重"。这种计算分配的精细化,与人类认知的"选择性注意"不谋而合——我们会自动忽略大部分无关信息,只对关键内容投入认知资源。
MoD 的意义不仅在于具体的效率提升数字,更在于它揭示了一个事实:传统 transformer 的计算存在大量冗余。当模型学会只对重要的 token 投入计算时,它不仅更快,甚至可能更好——因为专注于关键信息可能反而减少了噪音干扰。
随着 MoDification 降低了落地门槛,以及 A-MoD、MoR 等后续改进不断涌现,动态计算深度正在成为大模型架构演进的重要方向。在未来,我们可能会看到更多"选择性计算"的设计——不仅是选择深度,还可能选择精度、选择注意力范围、选择激活路径。让模型学会"偷懒",或许是通往更高效 AI 的关键一步。
参考文献
-
Raposo, D., Ritter, S., Richards, B., Lillicrap, T., Humphreys, P. C., & Santoro, A. (2024). Mixture-of-Depths: Dynamically allocating compute in transformer-based language models. arXiv preprint arXiv:2404.02258.
-
Zhang, C., Zhong, M., Wang, Q., Lu, X., Ye, Z., Lu, C., … & Song, D. (2025). MoDification: Mixture of Depths Made Easy. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 5137-5149).
-
Majumdar, S. K., et al. (2024). Attention Is All You Need For Mixture-of-Depths Routing. arXiv preprint arXiv:2412.20875.
-
Bae, S., et al. (2025). Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation. arXiv preprint arXiv:2507.10524.
-
Xin, J., Tang, R., Lee, J., Yu, Y., & Lin, J. (2020). DeeBERT: Dynamic early exiting for accelerating BERT inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 2246-2251).
-
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., & Kaiser, Ł. (2018). Universal transformers. In International Conference on Learning Representations.
-
Graves, A. (2016). Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983.
-
Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120), 1-39.
-
Shazeer, N., et al. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In International Conference on Learning Representations.