2012年,微软Azure Storage团队面临一个严峻的选择:存储数据量正以每两天1PB的速度增长,按照传统的三副本策略,这意味着每两天需要采购3PB的存储设备。更糟糕的是,数据中心的电力、制冷和运维成本也随之水涨船高。团队需要一种能在保证数据可靠性的前提下大幅降低存储成本的方案。他们最终选择了纠删码——这项源自1960年代通信领域的技术,在存储系统中找到了新的生命。
一张图理解纠删码的本质
纠删码的核心思想可以用一个简单的数学问题来概括:给定k个数据块,如何生成m个冗余块,使得这k+m个块中任意k个都能还原原始数据?
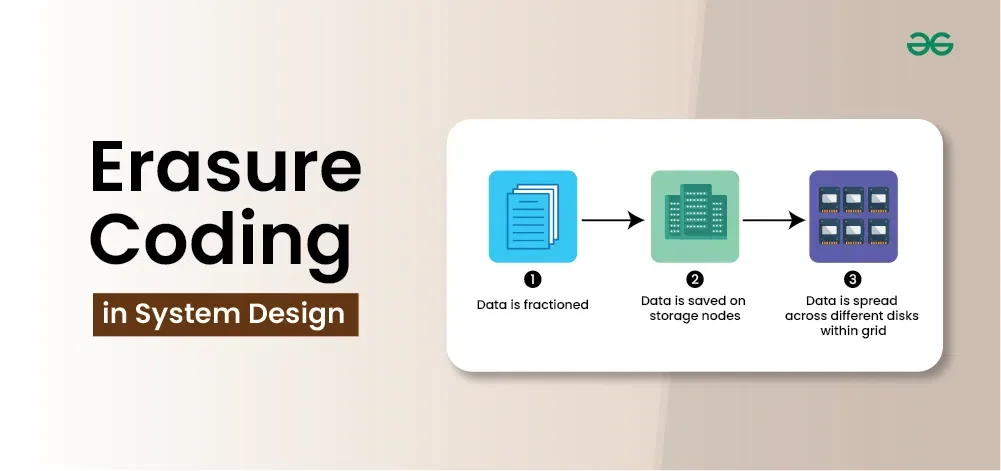
图中展示了一个典型的纠删码配置:原始数据被切分为k个数据块,通过编码算法生成m个校验块。这k+m个块被分散存储在不同节点上。当部分节点发生故障时,只要存活的块数量不少于k,就能完整恢复原始数据。
与三副本策略相比,纠删码的优势显而易见。假设采用RS(6,3)配置(6个数据块+3个校验块),存储开销为 $(6+3)/6 = 1.5$ 倍,即50%的额外存储。而三副本的开销是3倍,即200%的额外存储。在同等存储成本下,纠删码能存储三副本策略两倍的数据量。
Reed-Solomon码:从数学原理到工程实现
最广泛使用的纠删码算法是Reed-Solomon码(简称RS码),由Irving Reed和Gustave Solomon于1960年在MIT林肯实验室提出。他们的论文发表在《工业与应用数学学会杂志》上,最初的目的是解决卫星通信中的数据传输错误问题。
有限域:RS码的数学基础
理解RS码需要先理解有限域(Finite Field)的概念。有限域又称伽罗瓦域(Galois Field),是包含有限个元素的代数结构,满足特定的运算规则。
在计算机存储系统中,最常用的是 $GF(2^8)$ 域。这个域恰好包含256个元素,每个元素可以用一个字节表示。$GF(2^8)$ 上的加法等同于异或(XOR)运算,而乘法需要借助原根和生成多项式来定义。
GF(2^8) 加法示例:
0x57 ⊕ 0x83 = 0xD4
GF(2^8) 乘法(使用生成多项式 x^8 + x^4 + x^3 + x + 1):
0x57 × 0x83 需要通过查表或多项式乘法计算
为什么选择 $GF(2^8)$ 而不是普通的整数运算?关键在于有限域的封闭性:有限域上的加法和乘法结果仍在该域内,不会发生溢出。这保证了编解码过程的一致性和可逆性。
多项式插值与编码过程
RS码的核心思想源于多项式插值:一个 $k-1$ 次多项式可以由其上任意 $k$ 个不同的点唯一确定。
具体编码过程如下:
步骤一:将原始数据划分为 $k$ 个数据块,记为 $d_0, d_1, ..., d_{k-1}$。
步骤二:构造多项式 $P(x) = d_0 + d_1 x + d_2 x^2 + ... + d_{k-1} x^{k-1}$,其中系数来自有限域。
步骤三:选择 $n = k + m$ 个不同的值 $x_0, x_1, ..., x_{n-1}$(通常选择 $0, 1, 2, ..., n-1$),计算多项式在这些点上的值:
$$c_i = P(x_i), \quad i = 0, 1, ..., n-1$$步骤四:前 $k$ 个值就是原始数据块(系统码形式),后 $m$ 个值是校验块。
解码时,如果丢失了部分块,可以用剩余的 $k$ 个块通过拉格朗日插值重建多项式 $P(x)$,从而恢复原始数据。
拉格朗日插值公式为:
$$P(x) = \sum_{i=1}^{k} y_i \prod_{j \neq i} \frac{x - x_j}{x_i - x_j}$$其中 $y_i$ 是已知点的函数值,$x_i$ 是对应的自变量值。
MDS性质:最优的存储效率
RS码具有一个重要性质——最大距离可分离(Maximum Distance Separable, MDS)。根据Singleton界限,对于任意 $(n, k)$ 线性分组码,其最小距离 $d$ 满足:
$$d \leq n - k + 1$$MDS码是达到这个上限的码,意味着在给定的冗余度下具有最大的纠错能力。对于RS $(n, k)$ 码,它可以容忍任意 $n - k$ 个块的丢失,这是理论上能达到的最优值。
| 配置 | 数据块(k) | 校验块(m) | 总块数(n) | 容错能力 | 存储开销 |
|---|---|---|---|---|---|
| 三副本 | 1 | 2 | 3 | 2块 | 300% |
| RS(6,3) | 6 | 3 | 9 | 3块 | 150% |
| RS(10,4) | 10 | 4 | 14 | 4块 | 140% |
| RS(12,4) | 12 | 4 | 16 | 4块 | 133% |
从表格可以看出,RS(12,4)配置仅用33%的额外存储就能容忍4块数据的丢失,存储效率是三副本的2.25倍。
修复代价:纠删码的阿喀琉斯之踵
尽管RS码在存储效率上无可挑剔,但它有一个致命的弱点:高昂的修复代价。
单块修复的带宽放大
当使用RS码存储数据时,如果一个节点发生故障,恢复该节点上的数据块需要从其他节点读取 $k$ 个块。这就是所谓的"修复带宽放大"问题。
以RS(10,4)为例,恢复一个丢失的数据块需要读取10个块,带宽放大倍数为10。对于RS(12,4),放大倍数达到12。在网络带宽成为瓶颈的分布式系统中,这个问题尤为严重。
微软Azure Storage团队在他们的论文中报告了一个关键数据:超过90%的数据中心故障是瞬态故障(如节点重启、网络抖动),持续时间从几秒到几分钟不等。在这些场景下,快速重建数据块对用户体验至关重要。
修复时间的数学分析
设每个数据块的大小为 $B$,网络带宽为 $W$,则使用RS码修复单个数据块的时间为:
$$T_{repair} = \frac{k \times B}{W}$$而三副本策略只需要从另一个副本读取数据:
$$T_{replica} = \frac{B}{W}$$修复时间是三副本策略的 $k$ 倍。在大规模集群中,这意味着故障恢复期间系统处于降级状态的时间更长,数据丢失风险更高。
LRC:局部可修复码的工程智慧
2012年,微软Azure Storage团队在USENIX ATC会议上发表了一篇里程碑式的论文,提出了局部可修复码(Local Reconstruction Codes, LRC)。这是纠删码从理论走向工程实践的关键一步。
LRC的核心思想
LRC的设计哲学很简单:不是所有校验块都需要参与所有数据块的计算。将数据块分组,每组计算一个"局部"校验块,同时再计算几个"全局"校验块覆盖所有数据。

图片来源: MinIO - Erasure Coding
以Azure Storage使用的LRC(12,2,2)为例:
- 12个数据块被分成两组,每组6个
- 每组计算一个局部校验块(共2个局部校验块 $p_x, p_y$)
- 所有12个数据块计算2个全局校验块($p_0, p_1$)
- 总共16个块:12数据 + 2局部校验 + 2全局校验
当单个数据块丢失时,可以用同组的另外5个数据块加上局部校验块恢复,只需读取6个块,而不是传统RS码需要的12个块。修复带宽减少50%。
LRC的容错能力分析
LRC通过牺牲部分存储效率换取更低的修复代价。LRC(12,2,2)的存储开销是 $16/12 = 1.33$ 倍,比RS(12,4)的1.33倍相同,但单块修复只需6个块而不是12个块。
LRC能容忍的故障模式更复杂:
- 任意3个块丢失:100%可恢复
- 4个块丢失:86%的故障模式可恢复(比RS(12,4)的100%略低)
Azure Storage的可靠性分析显示,LRC(12,2,2)的平均故障间隔时间(MTTF)为 $2.6 \times 10^{12}$ 年,远高于三副本的 $3.5 \times 10^9$ 年。
再生码:修复带宽的理论极限
在LRC之后,学术界提出了另一类优化方案:再生码(Regenerating Codes)。2010年,Dimakis等人在IEEE Transactions on Information Theory上发表了奠基性论文,证明了修复带宽和存储开销之间的根本权衡。
存储与带宽的权衡曲线
对于容忍 $m$ 个故障的系统,存在一个存储开销 $\alpha$(每节点存储量)和修复带宽 $\gamma$ 之间的权衡:
$$\gamma \geq \frac{2m \cdot B}{2m - k + 1}$$这条权衡曲线上有两个特殊点:
最小存储再生点(MSR):存储开销等于RS码(最优存储),但修复带宽仍然可以比RS码低。
最小带宽再生点(MBR):修复带宽达到理论最小值,但存储开销略高。
Clay Code:从理论到实现
2018年,USENIX FAST会议上提出的Clay Code实现了首个实用的MSR码。它的核心创新是"分层编码"(Coded Locality),将MSR码的构造问题转化为对现有MDS码的"塑造"过程。
Clay Code的一个关键优势是它与现有RS编码库兼容,可以通过简单的前后处理步骤将RS码转换为MSR码,无需重写整个编码器。
生产系统中的纠删码实践
AWS S3:11个9的持久性承诺
Amazon S3承诺99.999999999%(11个9)的数据持久性。这意味着如果你在S3上存储100亿个对象,预期每10000年才会丢失一个对象。
S3实现这一目标的核心技术就是纠删码。根据AWS的公开信息,S3对不同存储层采用不同的冗余策略:
- Standard存储:跨至少3个可用区的纠删码
- Glacier存储:更高冗余度的纠删码配置
- S3 One Zone-IA:单可用区内的纠删码
S3的纠删码实现结合了纠删码和复制:数据先进行纠删编码,然后将编码后的块跨可用区复制。这种"纠删码+复制"的混合策略提供了极高的数据持久性。
HDFS:从三副本到纠删码的转变
Apache Hadoop 3.0引入了纠删码作为HDFS的可选功能。Facebook的报告显示,他们在HDFS上部署纠删码后,存储效率提升了约50%。
HDFS支持多种纠删码策略:
- RS-6-3-1024k:6个数据块+3个校验块,每个块1MB
- RS-10-4-1024k:10个数据块+4个校验块,每个块1MB
- RS-LEGACY-6-3-1024k:兼容旧版本的策略
HDFS的纠删码采用条带化布局:每个文件被切分为固定大小的单元格(cell),多个单元格组成一个条带(stripe),每个条带独立进行纠删编码。
MinIO:高性能对象存储的纠删码实现
MinIO是高性能对象存储系统的代表,其纠删码实现具有以下特点:
读写仲裁机制:对于EC:M配置(M个校验块),读取操作需要至少 $N - M$ 个块可用($N$ 为总块数),写入操作需要至少 $\lceil N/2 \rceil + 1$ 个块可用(防止脑裂)。
在线修复:MinIO可以在后台持续检查数据完整性,一旦发现块损坏就自动触发修复。
SIMD加速:MinIO使用Intel ISA-L库进行纠删码计算,通过AVX指令集实现数GB/s的编码吞吐量。
纠删码选择指南
在实际项目中,如何选择合适的纠删码配置?以下是一些经验法则:
热数据 vs 冷数据
热数据(频繁访问):优先考虑三副本或低k值的纠删码(如RS-3-2),降低读取延迟。
冷数据(归档存储):使用高k值的纠删码(如RS-12-4或LRC-12-2-2),最大化存储效率。
集群规模
纠删码要求集群至少有 $k + m$ 个节点(或故障域)。对于小型集群(少于10个节点),RS-6-3是一个合理的选择。对于大型集群,可以考虑RS-10-4或LRC配置。
故障模式
如果系统经常发生单节点故障,LRC的局部修复优势明显。如果故障模式多样(如机架级故障),RS码的全局修复能力更稳健。
性能需求
高吞吐量场景(如视频流媒体)需要考虑纠删码的CPU开销。使用ISA-L等加速库可以将编码性能提升5-10倍。
| 场景 | 推荐配置 | 存储效率 | 修复代价 |
|---|---|---|---|
| 小型集群(<10节点) | RS-6-3 | 67% | 中等 |
| 大型集群(>20节点) | LRC-12-2-2 | 75% | 低 |
| 归档存储 | RS-12-4 | 75% | 高 |
| 高性能存储 | RS-3-2 | 60% | 低 |
从太空到云端:一项技术的六十五年旅程
纠删码的故事始于1960年的太空竞赛。Reed和Solomon发明这项技术时,目标是让深空探测器传回的数据能够抵御宇宙射线的干扰。旅行者号探测器至今仍在使用RS码,从太阳系边缘发回数据。
1990年代,RS码被应用到CD和DVD中,让光盘能抵抗划痕和污渍。二维码也使用RS码,这也是为什么二维码即使部分损坏仍能被扫描识别。
2000年代,随着云计算的兴起,RS码进入分布式存储领域。Google、Facebook、微软、亚马逊几乎同时意识到:在EB级数据规模下,三副本策略的存储成本无法承受。纠删码从"锦上添花"变成了"必不可少"。
2010年代,LRC、再生码等优化方案相继提出,解决了纠删码的修复代价问题。这些创新来自微软研究院、CMU、MIT等机构,体现了学术研究与工程实践的深度融合。
今天,纠删码已成为云存储的事实标准。当你上传一张照片到云端,它很可能已经被切分、编码、分散存储在世界各地的服务器上。这项六十五年前为太空通信发明的技术,如今守护着人类产生的海量数据。
参考文献
-
Reed, I. S., & Solomon, G. (1960). Polynomial Codes Over Certain Finite Fields. Journal of the Society for Industrial and Applied Mathematics, 8(2), 300-304.
-
Huang, C., Simitci, H., Xu, Y., et al. (2012). Erasure Coding in Windows Azure Storage. USENIX ATC.
-
Dimakis, A. G., Ramchandran, K., Wu, Y., & Suh, C. (2010). A Survey on Network Codes for Distributed Storage. Proceedings of the IEEE.
-
Ford, D., Labelle, F., Popovici, F. I., et al. (2010). Availability in Globally Distributed Storage Systems. USENIX OSDI.
-
Sathiamoorthy, M., Asteris, M., Papailiopoulos, D., et al. (2013). XORing Elephants: Novel Erasure Codes for Big Data. VLDB Endowment.
-
Vajha, M., Ramkumar, V., Puranik, B., et al. (2018). Clay Codes: Moulding MDS Codes to Yield an MSR Code. USENIX FAST.
-
Plank, J. S., & Xu, L. (2006). Optimizing Cauchy Reed-Solomon Codes for Fault-Tolerant Network Storage Applications. IEEE NCA.
-
Apache Hadoop. (2023). HDFS Erasure Coding. Apache Hadoop Documentation.
-
MinIO. (2024). Erasure Coding. MinIO Documentation.
-
Cheng, K., et al. (2024). A Survey of the Past, Present, and Future of Erasure Coding for Storage Systems. ACM Computing Surveys.