2024年5月,OpenAI发布GPT-4o,这个模型能实时"看"你手机屏幕上的内容并回答问题。对着一张复杂的电路图问"这个电阻的阻值是多少",它能准确定位并读出数值;给它一张手绘的流程图,它能理解逻辑关系并生成代码实现。
但在这些炫酷能力的背后,一个根本性的问题始终困扰着研究者:大语言模型原本是为处理文本而设计的,文本是离散的符号序列,而图像是连续的像素矩阵。让一个"生于文本"的模型去"理解"图像,到底是怎么做到的?
这个问题的答案,藏在过去五年多模态学习的技术演进中。从2021年CLIP的突破,到Flamingo、LLaVA、BLIP-2等模型的架构创新,一条清晰的技术脉络逐渐浮现。
图像与文本:两种本质不同的信息形态
要理解大模型如何"看"图像,首先要理解图像和文本这两种数据形态的根本差异。
文本是由人类创造的符号系统。每个词都是一个离散的token,它们按照语法规则组合成有意义的句子。“猫坐在垫子上"这句话,可以精确地切分为"猫”、“坐”、“在”、“垫子”、“上"这些基本单元,每个单元都有明确的语义边界。
图像则完全不同。一张256×256像素的彩色图像,包含196,608个数值(256×256×3通道)。这些数值本身没有语义——像素值(255, 128, 64)既不代表"猫”,也不代表"垫子"。语义信息隐藏在像素的空间分布中,需要从局部纹理、边缘、形状逐步抽象到物体和场景。
这意味着,如果要让语言模型处理图像,必须找到一个"翻译"机制:将连续的、无语义边界的像素空间,映射到离散的、有明确语义单元的嵌入空间。
这个翻译过程,就是视觉语言模型架构设计的核心挑战。
CLIP:用对比学习建立图文共享空间
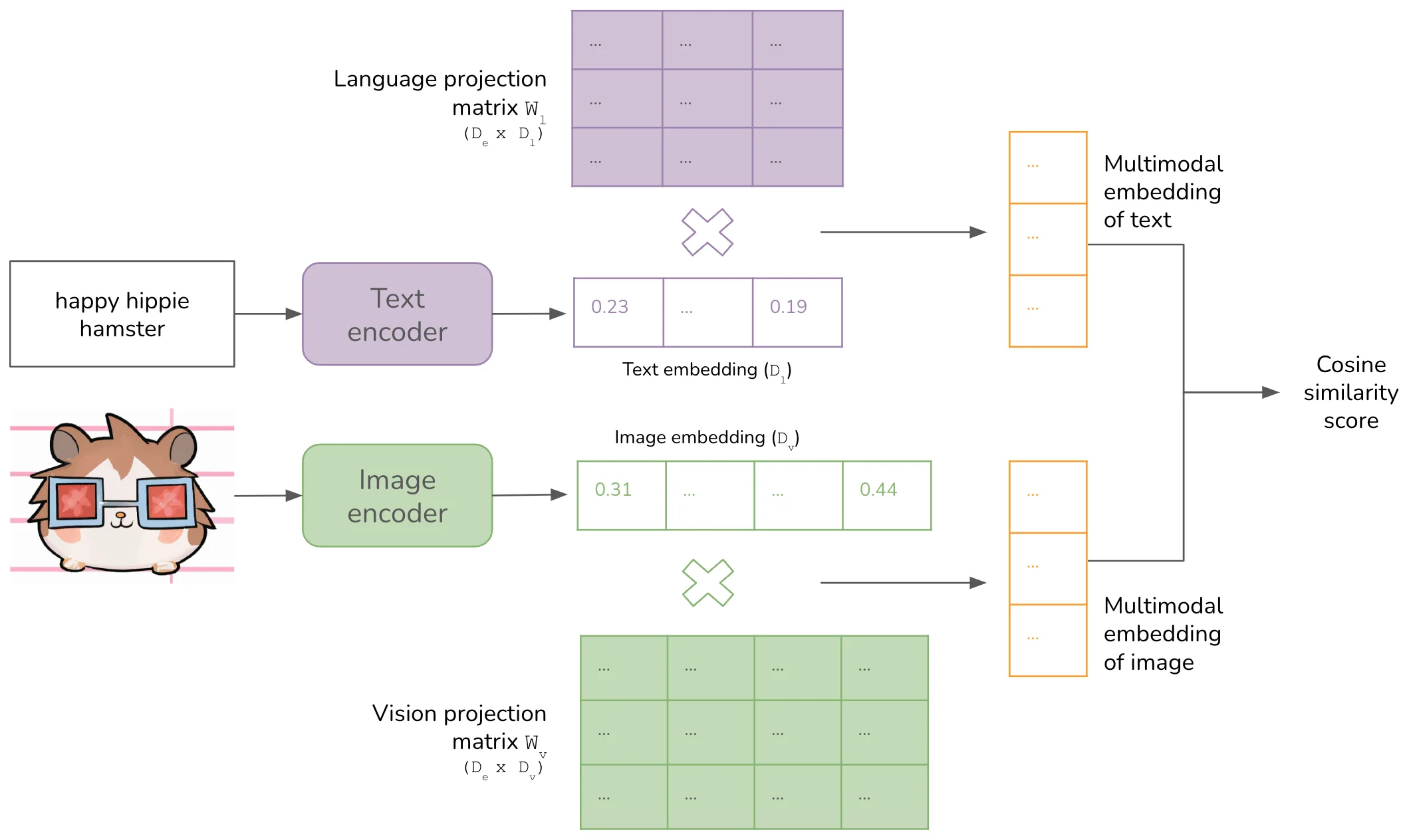
2021年1月,OpenAI发布CLIP(Contrastive Language-Image Pre-training),这个模型成为现代视觉语言模型的基石。它的核心贡献是建立了一个图文共享的嵌入空间——图像和文本在这个空间中被表示为同维度的向量,语义相关的图文对距离更近,无关的对距离更远。
双塔架构的设计哲学
CLIP采用了简洁的双塔架构:一个图像编码器,一个文本编码器。图像编码器可以是ResNet或Vision Transformer(ViT),文本编码器是一个小型的Transformer。两个编码器独立工作,分别将图像和文本映射到同一维度的嵌入空间。
这种设计的关键在于独立性。图像编码器不需要理解文本语法,文本编码器也不需要处理像素。它们各司其职,最后的对齐发生在嵌入空间层面。这比早期尝试将图像直接编码为文本token的方法更高效——CLIP作者发现,对比学习方法比生成式方法(如预测图像的文本描述)效率高出4-12倍。
对比学习的数学本质
CLIP的训练目标可以用一个简单的例子理解。假设一个训练批次包含N对图文,比如:
- (猫的图片, “a photo of a cat”)
- (狗的图片, “a photo of a dog”)
- (汽车的图片, “a photo of a car”)
- …
图像编码器产生N个图像嵌入 $V_1, V_2, ..., V_N$,文本编码器产生N个文本嵌入 $L_1, L_2, ..., L_N$。模型计算所有 $N^2$ 种图文组合的相似度,形成一个N×N的相似度矩阵。
训练目标是让对角线上的N个正确配对相似度最大化,同时让其他 $N^2-N$ 个错误配对的相似度最小化。数学上,这等价于两个对称的分类任务:
- 对于每个图像,从N个文本中找出正确的那个
- 对于每个文本,从N个图像中找出正确的那个
损失函数的形式如下:
$$\mathcal{L} = -\frac{1}{N}\sum_{i=1}^{N}\left[\log\frac{\exp(V_i^T L_i / \tau)}{\sum_{j=1}^{N}\exp(V_i^T L_j / \tau)} + \log\frac{\exp(L_i^T V_i / \tau)}{\sum_{j=1}^{N}\exp(L_j^T V_i / \tau)}\right]$$其中 $\tau$ 是一个可学习的温度参数,控制分布的平滑程度。
CLIP使用 $N=32,768$ 的批次大小。这意味着每个训练步骤,模型要在超过10亿种图文组合中学习区分正确与错误的配对。这种大规模对比学习的成功,证明了"让相似的对更近、不相似的对更远"这一简单原则的强大威力。
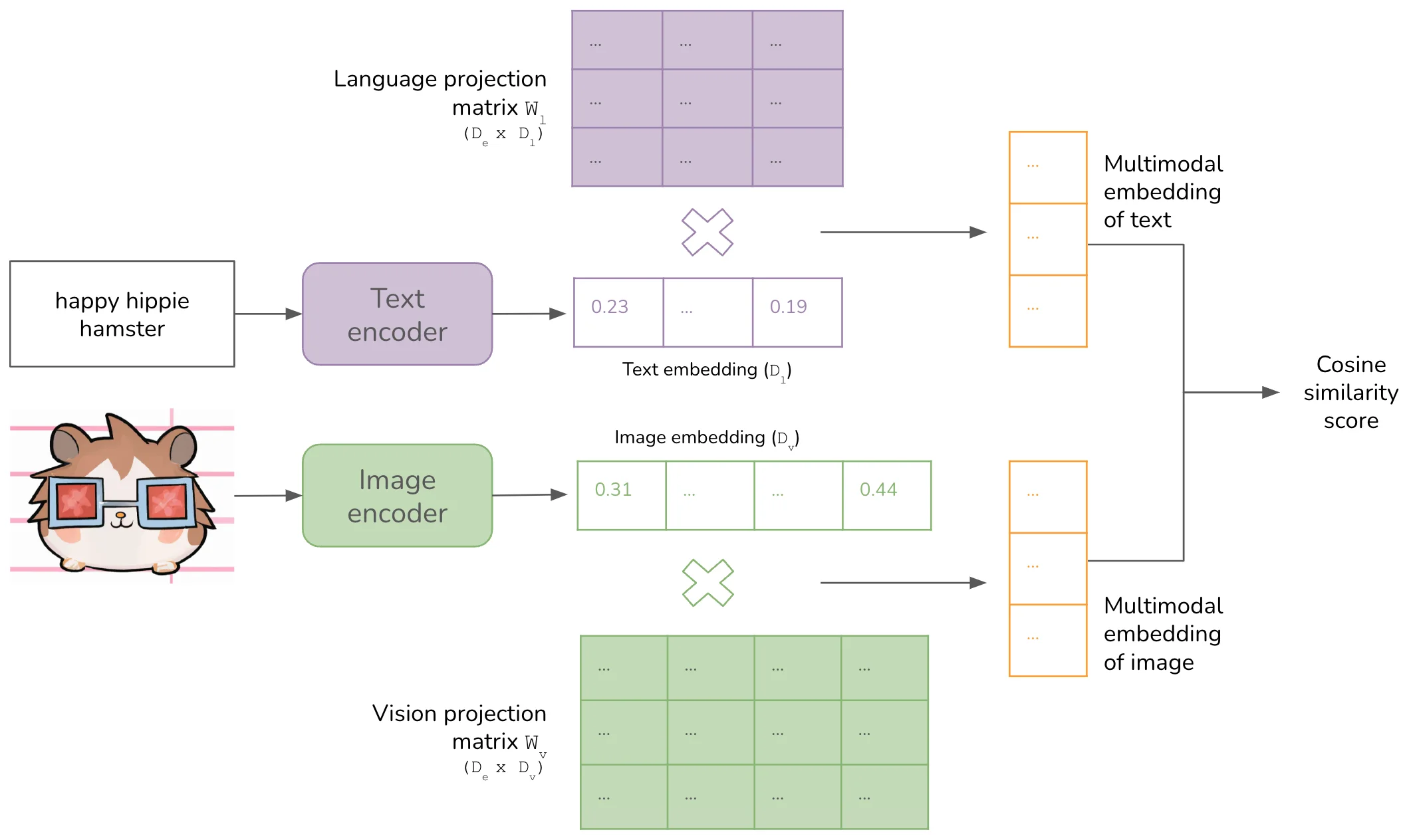
CLIP的双塔架构:图像编码器和文本编码器独立工作,通过对比学习在共享嵌入空间中对齐图文表示。图片来源: Chip Huyen
自然语言监督:突破标注瓶颈
CLIP的另一个创新是使用自然语言作为监督信号。传统视觉模型需要在人工标注的数据集上训练,比如ImageNet需要标注1400万张图片的类别。这种方式不仅昂贵,而且只能学到预定义的有限类别。
CLIP的做法更聪明:它从互联网收集了4亿对图文数据。这些数据本来就在那里——用户上传图片时会写描述文字,网页的图片有alt标签。CLIP只需要收集这些自然产生的图文配对,就能学到极其丰富的视觉概念。
这种"自然语言监督"的方式带来了零样本迁移能力。给定一个新任务,比如分类"猫"和"狗",只需要构造文本提示"a photo of a cat"和"a photo of a dog",用CLIP计算图像与这两个文本的相似度,就能完成分类——完全不需要在目标任务上训练。这种能力在ImageNet上达到了与ResNet-50相当的效果,却从未看过ImageNet的训练数据。
CLIP的视觉编码器因此成为后续视觉语言模型的标配组件。Flamingo、LLaVA、Qwen-VL等模型,都使用CLIP或类似方法预训练的视觉编码器来提取图像特征。
从对齐到生成:视觉语言模型的架构演进
CLIP解决了图文表示的对齐问题,但它本身不能生成文本回复。一个完整的视觉语言模型(Vision Language Model, VLM),需要在CLIP的视觉编码器基础上,接入一个语言模型来生成回复。
这个"接入"过程,催生了两种主流架构。
架构一:统一嵌入解码器(Unified Embedding Decoder)
这是最直观的方法:将图像编码为一系列token,与文本token拼接后,一起输入语言模型。语言模型本身的结构不需要任何修改,它只是"看到"了更多的输入token——这些token有些来自文本分词,有些来自图像编码。
具体实现上,视觉编码器将图像转换为一组特征向量。比如一张224×224的图像,通过ViT编码后可能得到256个向量,每个向量维度为768。但这些向量不能直接输入语言模型,因为语言模型的嵌入维度可能是4096。
这就需要一个投影层(Projector),通常是一个简单的线性层或两层MLP,将图像特征映射到与文本嵌入相同的维度。投影后的图像token与文本token拼接,形成统一的输入序列。
LLaVA是这个架构的代表。它的设计极其简洁:
- 使用CLIP的视觉编码器提取图像特征
- 用一个线性投影层将图像特征映射到语言模型的嵌入空间
- 将投影后的图像token与文本token拼接
- 输入一个预训练的语言模型(如Vicuna)
LLaVA的关键创新在训练数据上。研究者用GPT-4自动生成了大量"视觉对话"数据:给定一张图像,让GPT-4扮演用户和助手,生成关于这张图像的多轮对话。这些数据用于微调语言模型,使其学会"讨论"图像内容。
这种架构的优势在于简单。不需要修改语言模型的内部结构,只需要训练投影层(以及在指令微调阶段可能微调语言模型)。缺点是计算开销较大——图像token会占用语言模型的上下文窗口,影响它能处理的文本长度。
架构二:跨模态注意力(Cross-Modality Attention)
另一种方法不需要将图像token放入语言模型的输入序列,而是在语言模型内部添加专门的跨模态注意力层。
这种方法借鉴了原始Transformer的encoder-decoder架构。在decoder中,每个注意力层除了处理文本自身的自注意力,还额外处理来自图像特征的交叉注意力。查询(Query)来自文本,键(Key)和值(Value)来自图像特征。
Flamingo是这个架构的开创者。它的设计包含几个关键组件:
-
视觉编码器:从头训练一个类似CLIP的视觉编码器,但在后续使用时只保留图像编码部分,文本编码器被丢弃。
-
Perceiver Resampler:视觉编码器输出的特征数量可能不固定(图像分辨率变化或视频的多个帧),Perceiver Resampler将其转换为固定数量的视觉token(Flamingo使用64个)。
-
门控交叉注意力层:在语言模型的每个Transformer层中,插入一个额外的交叉注意力模块,让文本token能够"看到"视觉token。
Flamingo使用Chinchilla作为基础语言模型,但保持语言模型的原始参数冻结,只训练新添加的跨模态组件。这种设计的好处是保留了语言模型的文本能力——它仍然是一个优秀的文本生成器,只是额外获得了"看图说话"的能力。
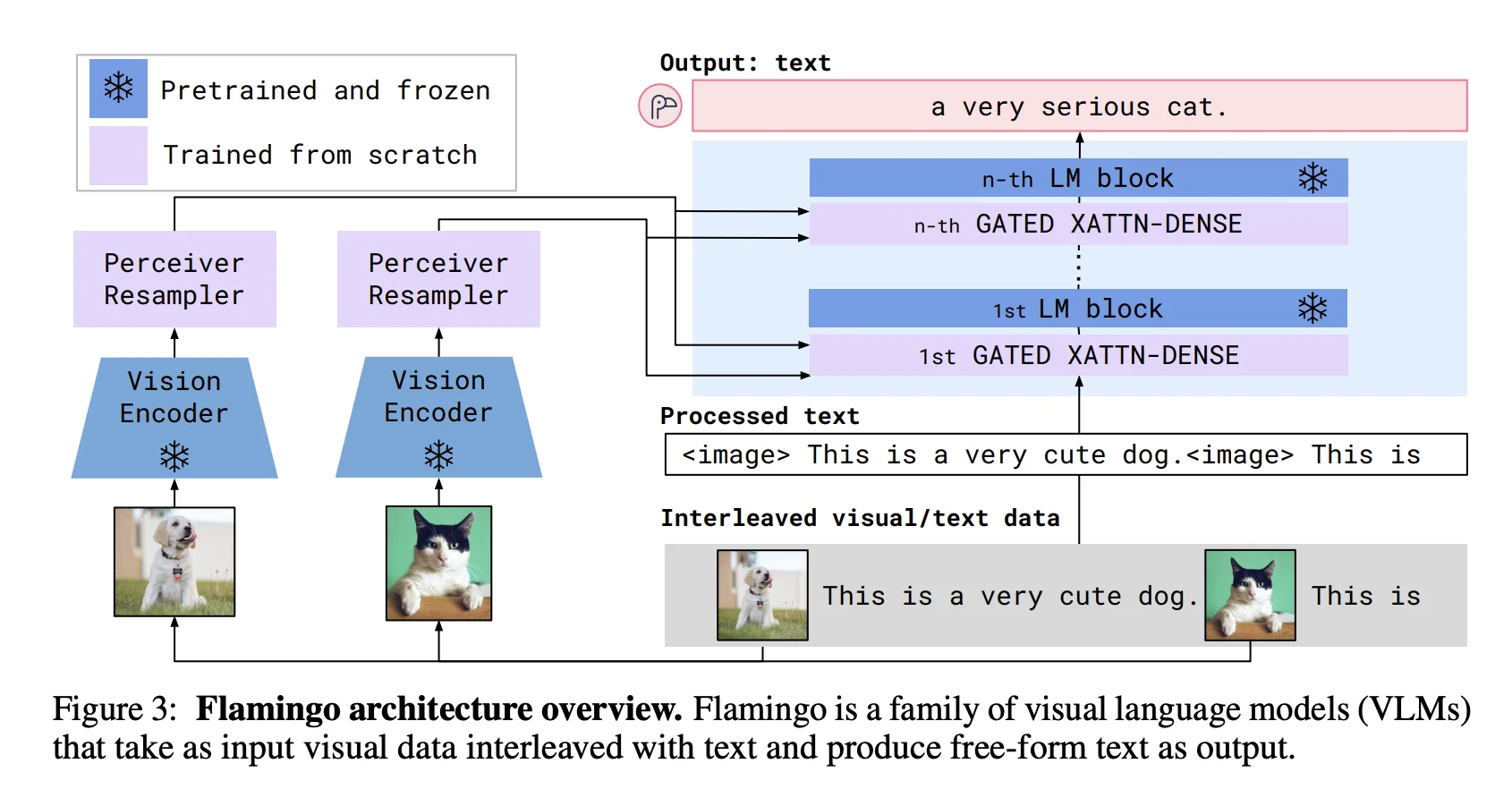
Flamingo架构:视觉特征通过Perceiver Resampler后,在跨模态注意力层中与语言模型交互。图片来源: Chip Huyen
BLIP-2:用Q-Former桥接模态鸿沟
2023年1月,Salesforce提出BLIP-2,引入了Q-Former这个创新组件,在效率和性能上取得了突破。
Q-Former的核心思想是"查询":用一组可学习的查询向量,从冻结的视觉编码器中"提取"与文本相关的视觉信息。这比Flamingo的Perceiver Resampler更进一步——它不仅压缩视觉特征,还主动"挑选"与当前文本任务相关的视觉信息。
Q-Former包含两个子模块:
- 图像-文本匹配(ITM)头:判断图像和文本是否匹配
- 图像-文本对比(ITC)头:计算图文相似度
- 语言建模头:生成文本token
训练分两阶段:
- 第一阶段:用图像-文本对比学习和图像-文本匹配任务训练Q-Former,让它学会提取与文本语义相关的视觉特征。
- 第二阶段:将Q-Former连接到冻结的语言模型,用生成式任务训练,让Q-Former的输出能被语言模型理解。
BLIP-2的效果惊人:在零样本VQAv2任务上,比Flamingo-80B高出8.7%,但可训练参数只有后者的1/54。
Vision Transformer:图像如何变成Token
无论采用哪种架构,视觉语言模型都面临同一个问题:图像要如何编码成token?这涉及到Vision Transformer(ViT)的工作原理。
Patch Embedding:将图像切分为小块
ViT的思路是将图像当作"序列"来处理。它将一张图像切成固定大小的小块(patch),比如16×16像素,然后将每个patch当作一个token。
具体过程:
- 将224×224的RGB图像切成196个16×16的patch($224/16 \times 224/16 = 14 \times 14 = 196$)
- 将每个patch展平成一个768维的向量($16 \times 16 \times 3 = 768$)
- 通过一个线性投影层,将768维映射到模型嵌入维度(比如768或1024)
- 添加位置编码,让模型知道每个patch的空间位置
- 添加一个可学习的[CLS]token,用于聚合全局信息
这些patch embedding就构成了Vision Transformer的输入序列,后续的处理与标准Transformer完全相同:多层自注意力 + 前馈网络。
为什么是Patch?为什么不是像素?
理论上,可以将图像的每个像素当作一个token。但这样做会导致序列过长:一张224×224的图像有50,176个像素,计算复杂度为 $O(n^2)$,这是无法承受的。
Patch是一种空间下采样策略。16×16的patch将序列长度压缩了256倍,同时保留了足够的局部细节。这种设计借鉴了CNN的感受野概念——局部区域先聚合,再进行全局交互。
但patch切分也带来了问题:它破坏了像素级的空间连续性。一个物体的边缘可能被切到两个不同的patch中,模型需要学会跨patch整合信息。这是ViT在处理需要精细定位的任务时的一个弱点。
位置编码的必要性
自注意力机制本身是置换不变的——打乱输入序列的顺序,输出的语义关系不变。但对于图像,patch的空间位置至关重要。
ViT使用可学习的位置编码,每个patch位置有一个独特的向量加到patch embedding上。这种方式让模型能够学习空间关系的表示。但可学习的位置编码有一个问题:它不能很好地泛化到训练时未见过的图像尺寸或patch数量。
一些后续工作尝试改进这一点。比如DeiT使用相对位置编码,Qwen-VL使用2D-RoPE(旋转位置编码),可以更好地处理不同分辨率的图像。
投影层设计:连接视觉与语言的桥梁
在统一嵌入解码器架构中,投影层是连接视觉编码器和语言模型的唯一桥梁。它的设计直接影响模型的效果和效率。
线性投影:最简单的选择
LLaVA最初版本使用单个线性层作为投影层。视觉编码器输出的每个patch特征(维度为$D_v$),通过一个$D_v \times D_l$的矩阵映射到语言模型的嵌入维度$D_l$。
这种方式极其简单,参数量也很少。但它假设视觉特征可以直接线性变换到语言空间,这可能过于乐观。CLIP的视觉特征是为了图文匹配训练的,而不是为了生成文本。
多层MLP:更强的表达能力
LLaVA-1.5将投影层从单层线性升级为两层MLP。第一层将视觉特征映射到更高的维度,第二层再映射到语言模型的嵌入维度。这种"先升维再降维"的设计增加了投影层的表达能力。
MLP投影层的效果明显优于线性投影。在多个视觉问答基准上,LLaVA-1.5比LLaVA-1.0有显著提升。
Q-Former:主动选择视觉信息
BLIP-2的Q-Former代表了一种不同的思路:不是简单地将视觉特征"翻译"到语言空间,而是主动"选择"与当前任务相关的视觉信息。
Q-Former包含一组可学习的查询向量,每个查询通过注意力机制从视觉特征中提取信息。这些查询向量就像"探测器",专门寻找与文本相关的视觉区域。比如,当文本问题是"这只猫是什么颜色",查询向量会倾向于关注图像中猫的区域。
分辨率与Token数量的权衡
投影层的另一个重要考量是输出token的数量。视觉编码器输出的token数量取决于图像分辨率和patch大小。一张336×336的图像,用14×14的patch,会产生576个patch token($336/14 \times 336/14 = 24 \times 24$)。
这些视觉token会占用语言模型的上下文窗口。如果语言模型的最大上下文长度是4096,576个视觉token就占用了14%。对于高分辨率图像,这个比例会更高。
因此,很多模型选择在投影层后降采样。LLaVA在投影后使用一个pooling操作,将视觉token数量减少到576个(从原始的576或更多)。Flamingo的Perceiver Resampler将任意数量的视觉特征压缩为固定的64个token。
压缩的代价是信息损失。如何在压缩的同时保留关键视觉信息,是一个需要仔细权衡的设计决策。
训练策略:从预训练到指令微调
视觉语言模型的训练通常分为两个阶段:预训练和对齐/指令微调。
阶段一:预训练(Pretraining)
预训练阶段的目标是让模型学会理解图像内容,建立视觉特征与语言表示的对应关系。
最常见的数据形式是图像-文本对。大规模数据集包括:
- LAION-5B:58.5亿对网络爬取的图文对,是当前最大的开放图文数据集
- COCO Captions:约12万张图像,每张有5条人工标注的描述
- CC3M/CC12M:从网页自动收集的图文对
预训练的数据配比很重要。Flamingo使用了四个数据集:交织图文网页数据(M3W)、图文对(ALIGN、LTIP)、视频文本对(VTP)。不同数据集有不同的权重,找到最优配比需要大量实验。
训练时,语言模型通常保持冻结(或只训练最后几层),只训练视觉编码器和投影层。这是为了保留语言模型的文本能力。LLaVA和BLIP-2都采用这种策略。
阶段二:视觉指令微调(Visual Instruction Tuning)
预训练后的模型能理解图像内容,但可能不会以对话的形式回答问题。指令微调阶段的目标是让模型学会"听人话、说人话"。
LLaVA首创了用GPT-4生成视觉指令数据的方法。给定一张图像和其描述,让GPT-4生成:
- 对话数据:用户提问、助手回答的多轮对话
- 详细描述:对图像内容的详细说明
- 复杂推理:需要多步推理的问题
这些数据让模型学会在视觉理解的基础上进行复杂的推理和对话。
指令微调阶段通常会解冻语言模型,进行全参数微调。这样可以让模型更好地适应视觉对话的任务分布,但需要注意不要破坏语言模型的原始能力。
数据质量的重要性
视觉语言模型对训练数据的质量极其敏感。早期研究表明,数据质量比数量更重要。
BLIP团队发现,网络爬取的图文数据存在大量噪声——文本可能不准确,图像可能不相关。他们提出了一种".captioner"策略:用预训练的视觉语言模型过滤和重写低质量的图文对,显著提升了训练效果。
另一项研究显示,图文对的"具体性"(concreteness)很重要。高度抽象的文本描述(如"一张美丽的风景照")对视觉学习的帮助有限,而具体描述(如"一个穿着红裙子的女孩站在蓝色自行车旁边")更有价值。
两种架构的权衡:效率与效果的博弈
统一嵌入解码器和跨模态注意力两种架构各有优劣,选择取决于具体需求。
统一嵌入解码器的优势
实现简单:不需要修改语言模型的内部结构,只需要添加投影层和修改输入预处理。这使得它可以快速应用于任何预训练的语言模型。
效果上限高:视觉token直接参与语言模型的自注意力计算,理论上可以获得最细粒度的视觉-语言交互。对于需要精确视觉定位的任务(如OCR、图表理解),这种架构通常表现更好。
生态兼容性好:由于不修改语言模型结构,可以复用现有的推理框架和优化技术(如KV Cache、Flash Attention)。
跨模态注意力的优势
计算效率高:视觉token不占用语言模型的输入窗口,可以处理更高的图像分辨率而不影响文本上下文长度。
保留文本能力:语言模型的原始参数可以保持冻结,确保文本生成能力不受影响。这对于需要同时处理纯文本和多模态输入的场景很重要。
解耦训练:视觉相关组件和语言模型可以独立训练,便于迁移和扩展。
NVLM的发现:融合两种思路
2024年9月,NVIDIA的NVLM论文对两种架构进行了系统对比。他们提出了一个有趣的发现:
- 对于高分辨率图像,跨模态注意力架构(NVLM-X)效率优势明显
- 对于需要精细视觉理解的任务(如OCR),统一嵌入架构(NVLM-D)效果更好
- 最优方案是混合架构(NVLM-H):用低分辨率的缩略图作为统一嵌入,同时用跨模态注意力处理高分辨率的细节patch
这个发现表明,两种架构并非互斥,而是可以互补。
最新进展:原生多模态与动态分辨率
2024年,视觉语言模型的发展呈现两个重要趋势。
原生多模态:从外接到融合
GPT-4o代表了"原生多模态"的方向。与GPT-4V需要单独的视觉编码器不同,GPT-4o将文本、图像、音频三种模态统一到一个模型中处理。所有输入都通过相同的注意力机制,不再有模态边界。
这种设计的优势是效率:不同模态之间的信息传递不需要通过投影层,避免了信息损失。但它的训练成本极高,需要从头训练而不是在预训练语言模型基础上扩展。
Meta的Llama 3.2提供了另一个思路:保持语言模型冻结,只训练视觉编码器和投影层。这种方式虽然效果可能不如原生多模态,但极大降低了训练成本,也让模型保留了原有的文本能力。
动态分辨率:适应不同大小的图像
传统视觉语言模型通常将所有图像缩放到固定分辨率(如224×224或336×336)。这会导致两个问题:
- 高分辨率图像丢失细节,难以识别小物体或文字
- 低分辨率图像被不必要地放大,浪费计算资源
Qwen2-VL引入了"原生动态分辨率"机制:图像以其原始分辨率输入,patch数量根据图像大小动态变化。位置编码使用2D-RoPE,能够适应任意的patch网格。
Pixtral 12B采用了类似的策略。它用从头训练的视觉编码器支持可变分辨率,而不是使用固定分辨率的预训练编码器。
动态分辨率的代价是计算量增加——高分辨率图像会产生更多token。这需要配合更高效的注意力机制(如Flash Attention)和推理优化技术。
从原理到实践:构建视觉语言模型的关键决策
如果要从零构建一个视觉语言模型,需要做出哪些关键决策?
视觉编码器的选择
预训练编码器 vs 从头训练:使用CLIP、SigLIP等预训练编码器是最常见的选择,它们已经学会了丰富的视觉-语言对齐。但预训练编码器可能不适合特定领域(如医学图像),这时从头训练可能更好。
分辨率选择:标准分辨率(224×224或336×336)适合大多数场景。如果需要精细视觉理解(如文档OCR、医学影像),考虑使用更高分辨率或动态分辨率。
架构选择:ViT是目前的主流选择,但传统CNN(如ConvNeXt)在某些任务上仍有优势。混合架构(如ViT+CNN)也在被探索。
语言模型的选择
参数规模:7B规模适合研究和实验,70B+规模追求最佳效果。注意视觉语言模型的总参数 = 语言模型参数 + 视觉编码器参数 + 投影层参数。
训练阶段:基础模型 vs 指令微调模型。使用已经过指令微调的语言模型作为基础,可以减少后续的视觉指令微调工作量。
架构特点:某些语言模型(如Qwen2)对多模态扩展有更好的支持,比如支持更长的上下文、更高效的注意力机制。
投影层的设计
简单投影 vs 复杂连接器:线性层或两层MLP适合快速实验。如果追求更好效果,考虑Q-Former或类似的"主动选择"机制。
Token数量:通常在64-1024之间。太少会丢失视觉细节,太多会占用上下文窗口。需要根据任务需求权衡。
训练策略
数据配比:图文对数据、交织图文数据、视觉指令数据的比例需要调优。LLaVA的经验是,视觉指令数据的质量比数量更重要。
训练阶段划分:典型的两阶段训练(预训练+指令微调)效果稳定。如果想节省计算,可以考虑只训练投影层,保持视觉编码器和语言模型冻结。
学习率调优:不同组件通常需要不同的学习率。视觉编码器的学习率通常比语言模型小,投影层可以更大。
写在最后
从CLIP的对比学习到现代视觉语言模型的复杂架构,让大模型"看"图像的技术已经走过了一条清晰而曲折的道路。
核心思想其实很简单:建立一个共享的嵌入空间,让图像和文本在这个空间中对齐;然后,用一个投影层或注意力机制,将对齐后的视觉信息"注入"到语言模型中。
但每个设计决策背后都涉及权衡:计算效率与效果的平衡,信息保留与压缩的平衡,通用性与领域特化的平衡。没有完美的方案,只有在特定场景下最优的选择。
今天的视觉语言模型已经能做很多令人惊叹的事情——看图写代码、分析医学影像、理解复杂的图表和文档。但它们仍然面临挑战:如何更好地处理高分辨率图像,如何在多轮对话中保持视觉一致性,如何避免视觉幻觉(看到不存在的物体)。
这些问题正在被研究者们积极攻克。可以预见,视觉语言模型将继续向着更高效、更智能、更可靠的方向发展。而理解其底层原理,是把握这一发展脉络的基础。
参考资料
- Radford, A., et al. “Learning Transferable Visual Models From Natural Language Supervision.” ICML 2021.
- Alayrac, J.-B., et al. “Flamingo: a Visual Language Model for Few-Shot Learning.” NeurIPS 2022.
- Liu, H., et al. “Visual Instruction Tuning.” NeurIPS 2023.
- Li, J., et al. “BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models.” ICML 2023.
- Dosovitskiy, A., et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ICLR 2021.
- Wang, P., et al. “Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.” arXiv 2024.
- Team, M. “The Llama 3 Herd of Models.” arXiv 2024.
- Bai, J., et al. “Qwen Technical Report.” arXiv 2023.
- Zhu, D., et al. “MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models.” arXiv 2023.
- Chen, X., et al. “PaliGemma: A versatile 3B VLM for transfer.” Technical Report 2024.
- Schuhmann, C., et al. “LAION-5B: An open large-scale dataset for training next generation image-text models.” NeurIPS 2022.
- Huyen, C. “Multimodality and Large Multimodal Models (LMMs).” Blog post, 2023.
- Raschka, S. “Understanding Multimodal LLMs.” Magazine article, 2024.
- NVIDIA. “NVLM: Open Frontier-Class Multimodal LLMs.” arXiv 2024.
- Mistral AI. “Pixtral 12B.” Technical Report, 2024.